

Моделирование данных при помощи кривыхдля восстановления пробелов в таблицах
А.А.Россиев
Институт вычислительного моделирования СО РАН
660036, Красноярск-36, ивм со ран,
E-mail: alexross@cc.krascience.rssi.ru
Предложен и реализован метод последовательного моделирования набора данных одномерными многообразиями (кривыми). Метод интерпретируется как построение конвейера нейронов для обработки данных с пробелами. Другая возможная интерпретация – итерационный метод главных компонент и нелинейный факторный анализ для данных с пробелами.
1. Общая схема метода
Для заполнения пробелов в данных в общем случае обычные уравнения регрессии практически неприменимы из-за большого разнообразия возможного расположения пропущенных данных – 2n-1 вариантов дляn-мерного вектора данных. Более перспективным представляется моделирование множества данных многообразиямиMмалой размерности. Вектор данныхxсkпробелами представляется какk-мерное линейное многообразиеLx, параллельноеkкоординатным осям, которые соответствуют пропущенным данным. При наличии априорных ограничений на пропущенные значения местоLxзанимает прямоугольный параллелепипедPxLx. Особую роль во всем дальнейшем рассмотрении играют две точки:
PrM(x) – ближайшая кx(соответственно кLxилиPx) точкаM,
и для некомплектных данных – ImM(x) – ближайшая кMточкаLx(или, соответственно,Px).
С использованием этого многообразия Mпроизводятся следующие операции:
заполнениепробелов – заменаxна ImM(x),
ремонт данных(замещение данных моделью) – заменаxна PrM(x).
Регрессионная зависимостьодной части данных от другой определяется через заполнение пробелов, соответствующих зависимым переменным, по известным значениям независимых.
Итерационный процесс моделирования данных состоит в том, что для исходных данных строится наилучшая (в определенном точном смысле) модель – многообразие Mмалой размерности. Далее из данныхx(соответственноLxилиPx) вычитаются проекции PrM(x). Получаем уклонения от первой модели. Для этого множества уклонений снова строится простая модель и т.д., пока все уклонения не станут достаточно близки к нулю. В следующем разделе описаны простейшие линейные модели данных, которые могут интерпретироваться как сингулярные разложения таблиц с пробелами. Далее с использованием линейных моделей строятся простейшие нелинейные.
2. Итерационный метод главных компонент для данных с пропусками
Пусть задана прямоугольная таблица, клетки которой либо заполнены действительными числами или значком @, означающим отсутствие данных. Требуется правдоподобным образом восстановить отсутствующие данные. При более детальном рассмотрении возникают три задачи:
заполнить пропуски в таблице;
отредактировать таблицу– изменить значения известных данных таким образом, чтобы наилучшим образом работали модели, используемые при восстановлении пропущенных данных;
построить по таблице вычислитель, заполняющий пробелы в приходящей для анализа строке данных с пробелами (в предположении, что данные в этой строке связаны теми же соотношениями, что и в строках таблицы).
Для решения этих задач предлагается использовать метод последовательного приближения множества векторов данных (строк таблицы) прямыми.
Основная процедура – поиск наилучшего приближения таблицы с пропусками матрицей видаxiyj+bj.
Пусть задана таблица с пропусками A=(aij). Ставится задача поиска наилучшего приближенияA матрицей видаxiyj+bj методом наименьших квадратов:
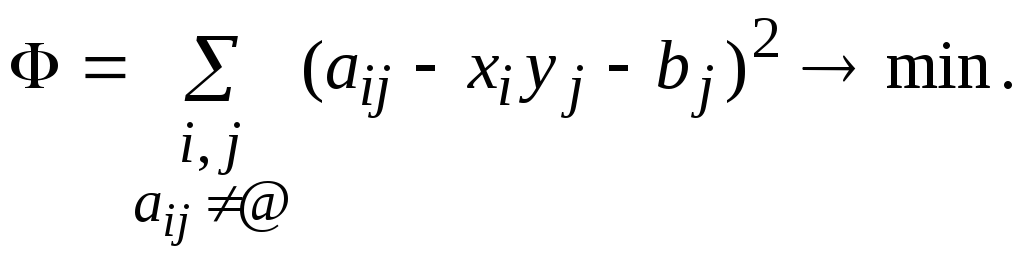 (1)
(1)
Если фиксированы два из трех векторов xi, yj иbj, то третий легко находится по явным формулам. Задаваясь практически произвольными начальными приближениями для двух из них, ищем значение третьего, далее, объявляем неизвестным другой вектор из трех, находим его значение, наконец, находим третий и т.д. (по кругу) – эти простые итерации, очевидно, сходятся. Более того, по фиксированномуxi, можно сразу по явным формулам посчитать значенияyjиbj– таким образом расщепление производится не на три, а на две составляющие.
При фиксированных векторах yjиbjзначенияxi, доставляющие минимум форме (1), определяются из равенствxi=0 следующим образом:
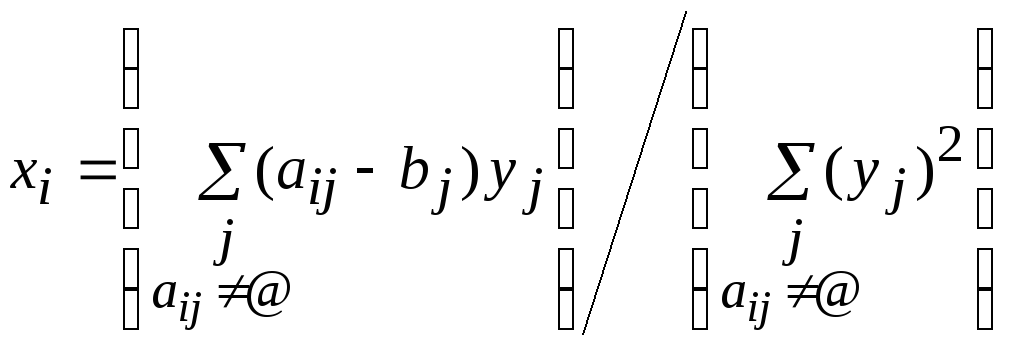 .
.
При фиксированном векторе xi значенияyjиbj, доставляющие минимум форме (1), определяются из двух равенствyj=0 и bj=0 следующим образом:
Для каждого j имеем систему из двух уравнений относительноyj иbj:
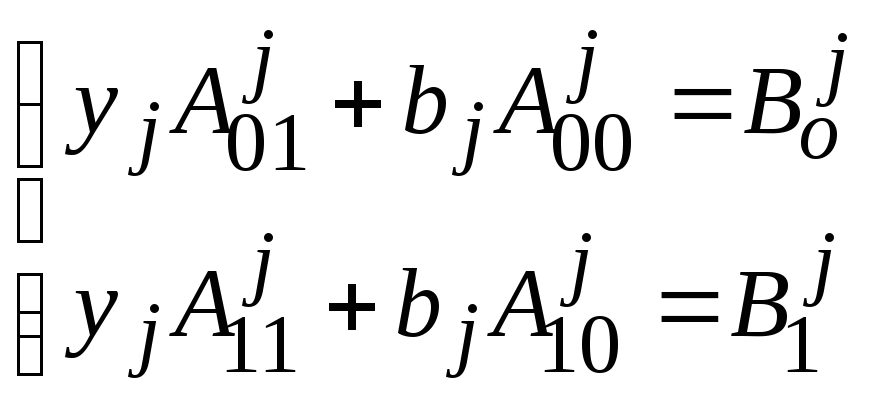 ,
где
,
где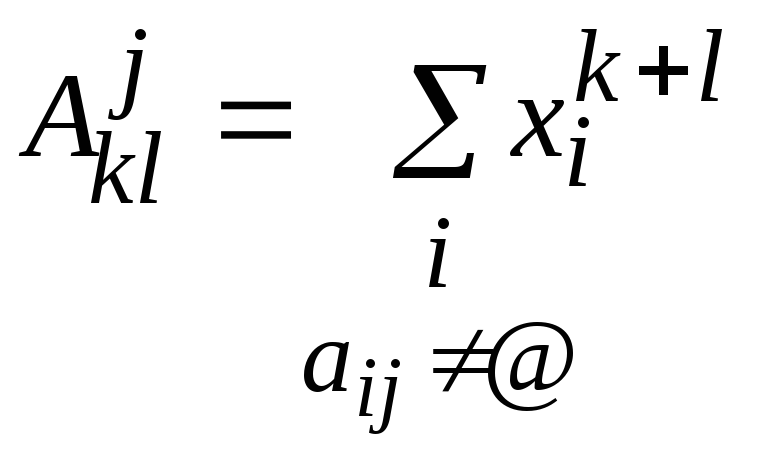 ,
,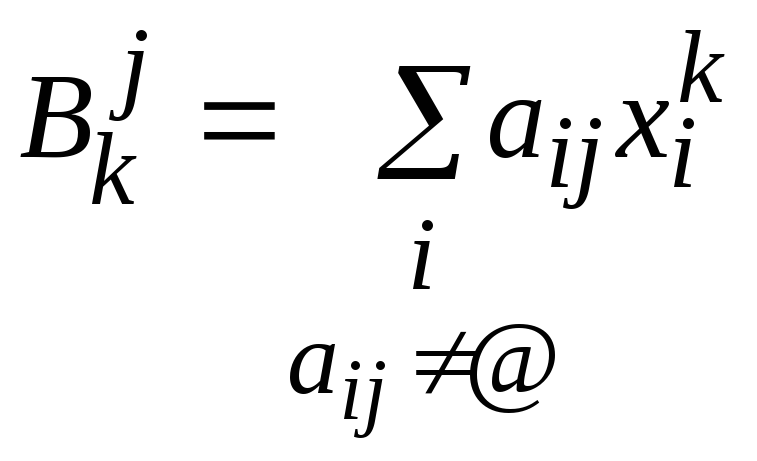 ,k=0..1, l=0..1.
,k=0..1, l=0..1.
Выражая из первого уравнения bjи подставляя полученное значение во второе, получим:
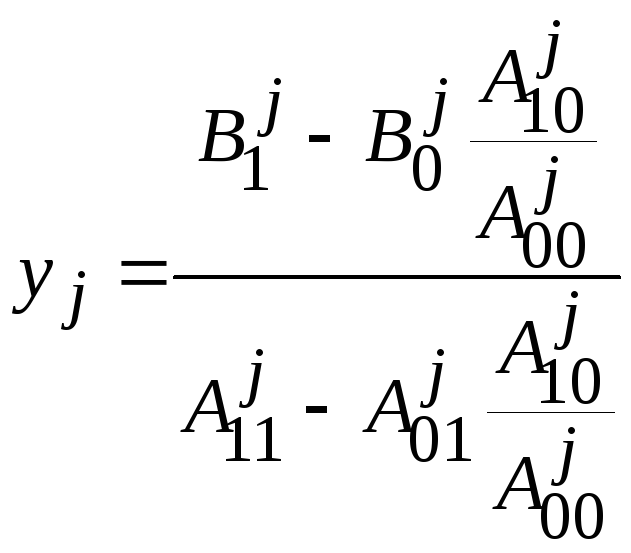 ,
, .
.
Начальные значения:
y – случайный, нормирован
на 1 (т.е.![]() )
)
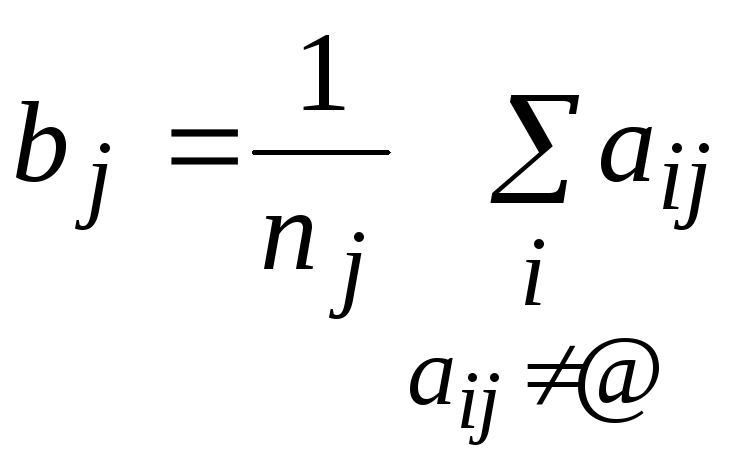 ,
где
,
где (число известных данных вj-ом
столбце), т.е.bj
определяется как среднее значение
в столбце.
(число известных данных вj-ом
столбце), т.е.bj
определяется как среднее значение
в столбце.
Критерий остановки – малость относительно улучшения /, где– полученное за цикл уменьшение значения, а– само текущее значение. Второй критерий – малость самого значения. Окончательно: процедура останавливается, еслиили для некоторых, 0.
Последовательное исчерпание матрицы A.
Для данной матрицы A ищем наилучшее приближение матрицейP1 видаxiyj+bj. Далее, дляA-P1ищем наилучшее приближение этого же видаP2 и т.д. Контроль ведется, например, по остаточной дисперсии столбцов.
Q-факторное заполнение пропусков есть их определение из суммыQполученных матриц видаxiyj+bj,
Q-факторный “ремонт” таблицы – замена ее на суммуQполученных матриц видаxiyj+bj.
Пусть в результате описанного процесса
построена последовательность матриц
Pq
видаxiyj+bj
(![]() ),
исчерпывающая исходную матрицуA
с заданной точностью. Опишем операцию
восстановления данных в поступающей
на обработку строкеaj
с пробелами(некоторыеaj=@).
Для каждогоq
по заданной строке определим числоxq(a)
и вектор
),
исчерпывающая исходную матрицуA
с заданной точностью. Опишем операцию
восстановления данных в поступающей
на обработку строкеaj
с пробелами(некоторыеaj=@).
Для каждогоq
по заданной строке определим числоxq(a)
и вектор![]() :
:
![]()
![]() ;
;
 ;
;
![]()
![]() ;
;
…………….. (2)
 ;
;
![]()
![]() ;
;
……………..
Здесь многообразие M – прямая, координаты точек наM задаются параметрическим уравнениемzj=tyj+bj, а проекцияPrM(a) определяется согласно (2):
Pr(a)=t(a)yj+bj;
 . (3)
. (3)
Для Q-факторного восстановления данных полагаем:
![]() ,
,![]() . (4)
. (4)
Если пробелы отсутствуют, то описанный
метод приводит к обычным главным
компонентам – сингулярному разложению
исходной таблицы данных. В этом случае,
начиная с q=2,
![]() (b=0).
В общем случае это не так и центрирование
к данным с пробелами неприменимо.
(b=0).
В общем случае это не так и центрирование
к данным с пробелами неприменимо.
Также следует учесть, что при отсутствии пробелов, полученные прямые будут ортогональны, то есть получим ортогональную систему факторов (прямых). Исходя из этого, при неполных данных возможен процесс ортогонализации полученной системы факторов, который заключается в том, что исходная таблица восстанавливается при помощи полученной системы, после чего эта система пересчитывается заново, но уже на полных данных.