

Лекция для заочников
.pdfН е л и н е й н а я р е г р е с с и я
Спозиции использования МНК различают следующие виды зависимостей:
1)функции, нелинейные по факторам, например:
y=b0 +b1 x2 или y=b0 +b1 ln x ;
2) функции, нелинейные по параметрам, например:
y= ea0 +a1x или y = aKα L1−α
3)функции, не приводимые к линейному виду.
y= a b+c x
П р о б л е м ы п р а к т и ч е с к о г о п р и м е н е н и я р е г р е с с и о н н о г о а н а л и з а
1.Мультиколлинеарность высокая взаимная коррелированность объясняющих переменных.
2.Гетероскедастичность - непостоянство дисперсий отклонений.
3.Автокорреляция - это корреляционная зависимость между последовательными (соседними) значениями уровней временного ряда y1 и y2, y2 и y3, y3 и y4 и т. д.
М у л ь т и к о л л и н е а р н о с т ь
Последствия мультиколлинеарности :
1.Резко падает точность оценок параметров, получаемых с помощью МНК. Ошибки некоторых параметров уравнения могут стать очень большими.
2.Выборочные характеристики регрессионной модели становятся крайне неустойчивыми. При добавлении (исключении ) некоторого количества наблюдений или факторов к массиву исходной информации может произойти резкое изменение оценок параметров.
3.Изза неустойчивости модели резко сокращаются возможности содержательной интерпретации модели, а также прогноза значений зависимой переменной y в точках, существенно удалённых от значений объясняющих переменных в выборке в виду ненадёжности получаемых результатов.
О б н а р у ж е н и е м у л ь т и к о л л и н е а р н о с т и
Одним из методов обнаружения мультиколлинеарности является анализ корреляционной матрицы между объясняющими переменными X1, X2, ..., Xp и выявление пары переменных, имеющие высокий коэффициент корреляции(обычно больше 0,7). Если такие переменные существуют, то говорят о мультиколлинеарности между ними.
Пример.
Y ← X 1 , X 2 , X 3 , X 4 , X 5
|
|
|
|
|
|
|
|
|
|
X1 |
|
X2 |
|
X3 |
X4 |
X5 |
Y |
X1 |
1,00 |
|
0,85 |
|
0,98 |
0,11 |
0,34 |
0,42 |
X2 |
|
|
1,00 |
|
0,88 |
0,03 |
0,46 |
0,34 |
X3 |
|
|
|
|
1,00 |
0,03 |
0,28 |
0,40 |
X4 |
|
|
|
|
|
1,00 |
0,57 |
0,56 |
X5 |
|
|
|
|
|
|
1,00 |
0,29 |
|
|
X 1 X 2 , |
X 1 X 3 , X 2 X 3 |
|
||||
М е т о д ы у с т р а н е н и я м у л ь т и к о л л и н е а р н о с т и
1.Переход от исходных объясняющих переменных X1, X2, ..., Xk, связанных между собой достаточно тесной корреляционной зависимостью, к новым переменным,представляющим линейную комбинацию исходных.
2.Отбор наиболее существенных объясняющих переменных. Производится, чаще всего в пошаговом режиме. На первом шаге рассматривается лишь объясняющая переменная, имеющая с зависимой переменной Y наибольший коэффициент детерминации. На следующем шаге включается в регрессию новая объясняющая переменная, которая вместе с первоначальной переменной дает наибольший (скорректированный) коэффициент детерминации. Процедура введения новых переменных продолжается до тех пор, пока будет увеличиваться соответствующий (скорректированный) коэффициент детерминации.

Г е т е р о с к е д а с т и ч н о с т ь
Гетероскедастичность ( D(ε)≠const ) является нарушением предпосылки МНК.
Последствия гетероскедастичности.
1.Оценки коэффициентов по-прежнему остаются несмещенными и линейными.
2.Оценки не будут эффективными (т. е. они не будут иметь наименьшую дисперсию по сравнению с другими оценками данного параметра).
3.Дисперсии оценок будут рассчитываться со смещением, т. к. дисперсия отклонений
n
∑e2i
S2= i=1
n− p−1 является смещенной.
4. Все выводы, получаемые на основе соответствующих T- и F-статистик, а также интервальные оценки будут ненадежными. Следовательно, статистические выводы, получаемые при стандартных проверках качества оценок, могут быть ошибочными и приводить к неверным заключениям по построенной модели.
О б н а р у ж е н и е г е т е р о с к е д а с т и ч н о с т и
Для обнаружения гетероскедастичности существует достаточно большое число тестов:
1.Графический анализ остатков.
2.Тест Голдфельда-Квандта.
3.Тест ранговой корреляции Спирмена.
4.Тест Парка.
5.Тест Глейзера.
и т.д.
Все эти тесты основаны на том, что о дисперсии теоретических отклонений ε судят по величине расчётных отклонений (остатков) e= y− y . Для этого с помощью обычного МНК
строится уравнение регрессии |
y=b0 b1 x1 ... bp x p или |
y=b0 b1 x и вычисляются отклонения |
||||
e= y− y |
или квадраты отклонений |
2 |
2 |
. |
|
|
|
e |
= y− y |
|
|||
|
|
|
|
|||
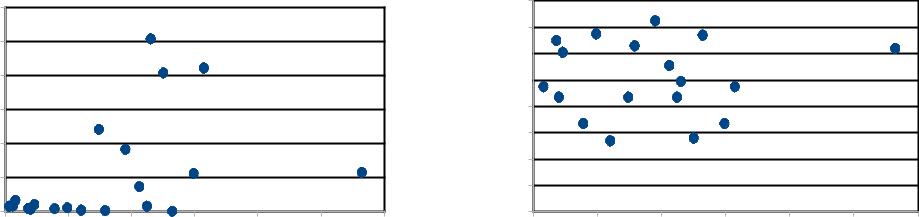
Г р а ф и ч е с к и й а н а л и з о с т а т к о в
e^2
1200
1000
800
600
400
200
0
0 |
50 |
100 |
150 |
200 |
250 |
300 |
x
Рис. 1. Гетероскедастичность
присутствует
e^2
160
140
120 

100 
80
60
40
20
0
0 |
50 |
100 |
150 |
200 |
250 |
300 |
x
Рис. 2. Гетероскедастичность
отсутствует

|
Т е с т Го л д ф е л ь д а - К в а н д т а |
Тест |
ГолдфельдаКвандта предполагает, что отклонения εi имеют нормальное |
распределение.
Весь ряд квадратов остатков ( e2i ), упорядоченный по величине X , разбивается на три
подвыборки размера m. Величина m обычно выбирается исходя из условия |
m≈ n |
, где n – |
|
|
|
3 |
|
объем всей выборки. |
|
|
|
|
m |
|
|
Вычисляются суммы квадратов отклонений первых m наблюдений |
S12=∑ ei2 и последних |
||
|
i=1 |
|
|
n |
|
|
|
m наблюдений S32= ∑ ei2 и вычисляется критерий Фишера, |
как отношение |
большей |
|
i=n−m +1
суммы квадратов отклонений к меньшей.
Если F = S 2 > F (α уровень значимости, S2 и S2 большее и меньшее
б
расч S 2 α ; m− p−1 ; m− p−1 б м
м
значения дисперсий S21 и S23 , p – количество объясняющих переменных в уравнении регрессии), то в выборке присутствует гетероскедастичность.
В р е м е н н ы е р я д ы
Временным рядом называют последовательность наблюдений yt , обычно упорядоченную во времени.
Используемые виды моделей:
yt=β0+β1 t +ε
yt=β0+β1 xt +ε
yt=β0+β1 xt 1+β2 xt 2 +...+βp xt p +ε
Коэффициенты моделей оцениваются с помощью МНК Прогнозирование осуществляется аналогично пространственным моделям.