

Раздел II. Объяснение юридических явлений и процессов.
ГЛАВА 1.
Изучение законов и закономерностей
юридических процессов
§1. Фундаментальный закон (аксиома) всеобщего детерминизма.
§2. Изучение законов юридических процессов или, что то же самое функциональный анализ юридических процессов.
§3. Дифференциальные уравнения юридических процессов.
§4. Параметрический корреляционный и регрессионный анализ юридических процессов или, что то же самое, изучение закономерностей юридических процессов.
§5. Особенности изучения юридических закономерностей по временным рядам.
§6. Эластичность (elasticity) юридических процессов.
§7. Непараметрический корреляционный анализ юридических процессов.
§8. Множественный регрессионный (multiple regression) и корреляционный анализ юридических процессов.
§9. Использование фиктивных (искусственных) переменных (dummy variables) при проведении корреляционного и регрессионного анализа юридических процессов, а также модели двоичного выбора.
§10. Использование лаговых переменных в анализе юридических и связанных с ними процессов.
§11. Модели двоичного выбора при изучении юридических процессов.
§12. Системы одновременных уравнений (simultaneous equations), объясняющие «поведение» криминологических и других юридических процессов.
Аксиома
(фундаментальный закон) всеобщего
детерминизма
(general
determinism
axiom)
утверждает – у
всякого следствия есть причина:
все многообразие управляющих факторов
уместно свести к действию трех групп
сил:
![]() ,
где
,
где![]() – вектор поведения конкретного индивида,
социальной группы или человечества;
– вектор поведения конкретного индивида,
социальной группы или человечества;![]() – группа сил космо-теллурической среды,
в частности, солнечная радиация,
температура, атмосферное давление,
влажность и прочее;
– группа сил космо-теллурической среды,
в частности, солнечная радиация,
температура, атмосферное давление,
влажность и прочее;![]() – совокупность безусловных биологических
сил (дыхание, питание, размножение и
т.п.),
– совокупность безусловных биологических
сил (дыхание, питание, размножение и
т.п.),![]() – совокупность социальных факторов,
включая влияние конкретной культуры,
моральных и правовых норм, идеалов и
иных ценностей, эффект совести – прежней
дрессировки, государственного принуждения
и общественного насилия;f
– правило (закон – для функциональной
связи или закономерность – для
корреляционной), устанавливающее связь
между левой и правой частями уравнения,
если так-то меняются управляющие
переменные, то так-то меняется управляемая
переменная.
– совокупность социальных факторов,
включая влияние конкретной культуры,
моральных и правовых норм, идеалов и
иных ценностей, эффект совести – прежней
дрессировки, государственного принуждения
и общественного насилия;f
– правило (закон – для функциональной
связи или закономерность – для
корреляционной), устанавливающее связь
между левой и правой частями уравнения,
если так-то меняются управляющие
переменные, то так-то меняется управляемая
переменная.
Бисериальный (biserial) коэффициент корреляции вычисляется по формуле:
![]() ,
где
,
где
![]() -
среднее по элементам переменной Y,
которым соответствуют значения единицы
(признак единица) по переменной X,
-
среднее по элементам переменной Y,
которым соответствуют значения единицы
(признак единица) по переменной X,
![]() -
среднее по элементам переменной Y,
которым соответствуют значения нуль
(признак нуль) по переменной X,
n1
– количество единиц по переменной X,
n0
– количество нулей по переменной X,
N=
n0+
n1
– число наблюдений по переменной X,
sy
– стандартное отклонение по переменной
Y:
-
среднее по элементам переменной Y,
которым соответствуют значения нуль
(признак нуль) по переменной X,
n1
– количество единиц по переменной X,
n0
– количество нулей по переменной X,
N=
n0+
n1
– число наблюдений по переменной X,
sy
– стандартное отклонение по переменной
Y:
![]() .
.
Гомоскедастичность
(homoscedasticity)
и гетероскедастичность (heteroscedasticity)
– при проведении параметрического
регрессионного и корреляционного
анализа важно, чтобы вероятность
наступления величины ε
(случайный
член), была одинаковой для всех наблюдений.
Это условие называется гомоскедастичностью
(«одинаковый разброс»). При
гетероскедастичности это условие не
выполняется, и оценки могут быть
смещенными. При нарушении гомоскедастичности
имеет место неравенство:
![]() .
При гомоскедастичности, напротив, имеет
место равенство дисперсий остатков.
.
При гомоскедастичности, напротив, имеет
место равенство дисперсий остатков.
Детерминации коэффициент (R2) (coefficient of determination) в парной регрессии (двумерные данные) – линейный коэффициент корреляции, возведенный в квадрат. Один из показателей объяснительной силы модели. Показывает, какой процент вариации зависимой переменной вероятно вызван вариацией независимой переменной.
Детерминации коэффициент (R2) (coefficient of determination) в множественной регрессии – показатель вариации зависимой переменной от совместной вариации факторных переменных, отвечает на вопрос, какой процент вариации Y вероятно можно объяснить влиянием независимых переменных.
Дифференциальное уравнение (differential equation) – уравнение, содержащее независимую переменную, неизвестную первообразную функцию и её известные производные различных порядков.
Корреляция (correlation) – статистико-вероятностный показатель силы и направления связи между двумя и более переменными.
Корреляционное отношение Пирсона (Pearson’s correlation ratio) вычисляется по одной из равнозначных формул:
 (1.1)
(1.1)
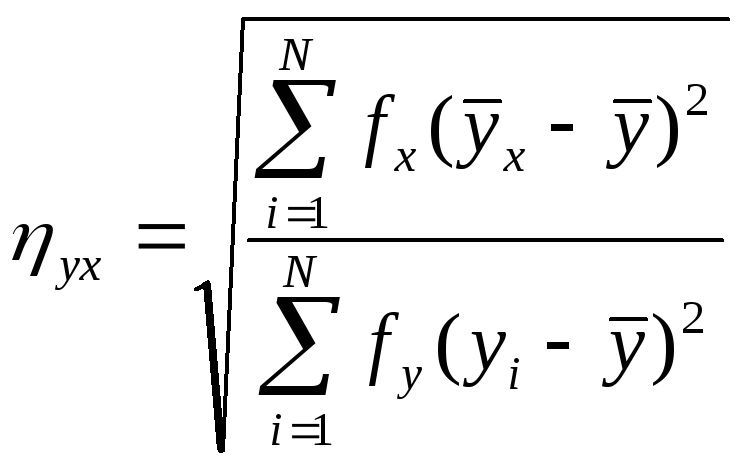 (1.2),
где
(1.2),
где
![]() и
и
![]() -
средние арифметические по переменным
х
и y
соответственно;
-
средние арифметические по переменным
х
и y
соответственно;![]() и
и
![]() -
групповые средние арифметические;
-
групповые средние арифметические;
![]() и
и
![]() -
частоты в рядах Х
и Y.
-
частоты в рядах Х
и Y.
Коэффициент ассоциации (association’s coefficient) вычисляется по формуле:
![]() ,
где a,
b,
c,
d
– значения в ячейках четырехпольной
таблицы.
,
где a,
b,
c,
d
– значения в ячейках четырехпольной
таблицы.
Коэффициент взаимной сопряженности Чупрова-Пирсона вычисляется по одной из нижеследующих формул:
![]() (1.1)
или
(1.1)
или
 (1.2),
где φ2
– показатель взаимной сопряженности;
K1
– число групп первого признака (число
строк за исключением итоговой); K2
– число
групп второго признака (число столбцов
за исключением итогового).
(1.2),
где φ2
– показатель взаимной сопряженности;
K1
– число групп первого признака (число
строк за исключением итоговой); K2
– число
групп второго признака (число столбцов
за исключением итогового).
Коэффициент контингенции (contingency coefficient) вычисляется по формуле:
![]() ,
где a,
b,
c,
d
– значения в ячейках четырехпольной
таблицы.
,
где a,
b,
c,
d
– значения в ячейках четырехпольной
таблицы.
Коэффициент частной множественной корреляции (partial multiple correlation coefficient) – показатель корреляции между двумя переменными при устранении влияния других независимых переменных модели (делаем нестрогое допущение, что влияние других переменных постоянно).
Коэффициент Фехнера (Fechner’s coefficient) вычисляется по формуле:
![]() ,
где С – совпадения, Н – несовпадения.
,
где С – совпадения, Н – несовпадения.
Лаговая переменная (lagged variable) – переменная, взятая с запаздыванием на определенную величину, например, один, два…периода.
Лаговая структура (lagged structure) – спецификация запаздываний применительно к переменным модели. Например, наказание (х) должно оказывать влияние на частоты преступлений (y) не сразу, а с определенным сдвигом во времени, скажем, на один, два, три года (периода) и т.д. Поэтому число преступлений мы можем брать по текущим годам, а в соответствие им ставить число наказанных лиц со сдвинутым временем (допустим на год раньше).
Линейность
(linearity)
указывает на то, что зависимость является
прямо пропорциональной (положительная
пропорциональность) или обратно
пропорциональной (отрицательная
пропорциональность). Коэффициент
пропорциональности (k)
в любой линейной зависимости всегда
константа (постоянная величина): k=const,
k=![]() (соотносятся
абсолютные приросты по икс и по игрек),
тангенс угла наклона, он определяет
крутизну наклона линии – чем больше
коэффициент пропорциональности, тем
круче наклон линии, выше скорость
изменения функции.
(соотносятся
абсолютные приросты по икс и по игрек),
тангенс угла наклона, он определяет
крутизну наклона линии – чем больше
коэффициент пропорциональности, тем
круче наклон линии, выше скорость
изменения функции.
Линейная вероятностная модель двоичного выбора состоит в том, что зависимая переменная являет собой вероятность, линейно зависящую от объясняющей переменной. То есть в данном случае зависимая переменная напоминает фиктивную переменную.
Метод наименьших квадратов (МНК) (ordinary least squares) (OLS) – при соблюдении определенных условий дает несмещенные и эффективные оценки параметров регрессионного уравнения, реализован во многих ППП.
Множественный коэффициент ранговой корреляции (МКРК) или коэффициент конкордации (coefficient of concordance), обычно обозначаемый английской буквой W, применяется для измерения силы связи между произвольным числом переменных модели, вычисляется по формуле:
![]() ,
где m
– число переменных модели, N
–
число наблюдений (строк), G
– отклонение суммы квадратов рангов
от средней квадрата рангов:
,
где m
– число переменных модели, N
–
число наблюдений (строк), G
– отклонение суммы квадратов рангов
от средней квадрата рангов:
 ,
где Rxi
–
ранжированные значения по переменной
икс; аналогично и по переменным Y,
Z
и т.д., в зависимости от числа переменных
включенных в модель.
,
где Rxi
–
ранжированные значения по переменной
икс; аналогично и по переменным Y,
Z
и т.д., в зависимости от числа переменных
включенных в модель.
Множественный
регрессионный
(multiple
regression)
и корреляционный
(correlation)
анализ
юридических процессов –
строим модели вида:![]() .
Они могут быть как линейными, так и
нелинейными, что зависит от правила ( f
), связывающего
левую и правую части уравнения.
.
Они могут быть как линейными, так и
нелинейными, что зависит от правила ( f
), связывающего
левую и правую части уравнения.
Мультиколлинеарность (multicollinearity) – коррелированность между независимыми переменными, которая может приводить к несостоятельным оценкам. Особенно ярко проблема мультиколлинеарности проявляет себя при построении регрессий на основе временных рядов, то есть когда зависимая и независимые переменные взяты во временном развитии, например, за ряд лет, кварталов, месяцев и т.д.
Нелинейность
(nonlinearity)
указывает, что зависимость не является
строго пропорциональной: kconst.
Следовательно, здесь имеется ускорение:
![]() 0,
а ускорение согласно второму закону
Ньютона – показатель действия силы
(сил):
0,
а ускорение согласно второму закону
Ньютона – показатель действия силы
(сил):
![]() или
или![]() .
Согласно первому закону Ньютона, если
процесс не взаимодействует с другими
процессами или, что то же самое на процесс
не осуществляется силового воздействия,
то он движется равномерно и прямолинейно.
Напротив, действие силы приводит к
колебаниям траектории линии процесса.
.
Согласно первому закону Ньютона, если
процесс не взаимодействует с другими
процессами или, что то же самое на процесс
не осуществляется силового воздействия,
то он движется равномерно и прямолинейно.
Напротив, действие силы приводит к
колебаниям траектории линии процесса.
Нормированный
R-квадрат
(иногда обозначают
![]() или
adjusted
или
adjusted
![]() )
приведенный в таблице «итоги
регрессионной статистики» (в литературе
называют также: скорректированный или
исправленный
)
приведенный в таблице «итоги
регрессионной статистики» (в литературе
называют также: скорректированный или
исправленный
![]() )
используется для уточнения коэффициента
детерминации при включении в модель
дополнительных независимых переменных
(x).
Это обусловлено тем, что добавление
новой независимой переменной к уравнению
регрессии повышает значение коэффициента
детерминации R2.
)
используется для уточнения коэффициента
детерминации при включении в модель
дополнительных независимых переменных
(x).
Это обусловлено тем, что добавление
новой независимой переменной к уравнению
регрессии повышает значение коэффициента
детерминации R2.
Остатков
автокорреляция
(autocorrelation
of
the
residual)
– корреляция между остатками текущих
(εi)
и предыдущих значений (εi-1):
![]() .
При построении регрессионных моделей
с использованием МНК (метод наименьших
квадратов) весьма важным условием
является отсутствие автокорреляции
остатков.
.
При построении регрессионных моделей
с использованием МНК (метод наименьших
квадратов) весьма важным условием
является отсутствие автокорреляции
остатков.
Параметры уравнения (parameters of the equation) – входящие в него константы, определяющие конкретный вид функции из многообразия возможных функций. Так параметрами линейного уравнения являются свободный член (сдвиг) и коэффициент наклона, в регрессионном анализе называемый коэффициентом регрессии.
Рангово-бисериальный коэффициент корреляции (rank biserial correlation coefficient) используется в тех случаях, когда переменная игрек измерена по ранговой шкале. В данном случае расчет производится по формуле:
![]() ,
где
,
где
![]() -
средний ранг по элементам переменной
Y,
которым соответствуют значения единицы
(признак единица) по переменной X,
-
средний ранг по элементам переменной
Y,
которым соответствуют значения единицы
(признак единица) по переменной X,
![]() -
средний ранг по элементам переменной
Y,
которым соответствуют значения нуль
(признак нуль) по переменной X,
N
– число наблюдений по переменной X.
-
средний ранг по элементам переменной
Y,
которым соответствуют значения нуль
(признак нуль) по переменной X,
N
– число наблюдений по переменной X.
Ранговый коэффициент корреляции Кендалла (Kendall’s rank coefficient correlation) вычисляется по одной из равнозначных формул:

![]()
![]()
![]() ,
где S=P+Q.
,
где S=P+Q.
Ранговый коэффициент корреляции Спирмена (Spearman’s rank correlation coefficient) вычисляется по формуле:
 ,
где d2
– квадрат разности рангов, N
– число
наблюдений.
,
где d2
– квадрат разности рангов, N
– число
наблюдений.
Регрессионный анализ или просто регрессия (regression) – подбор уравнения (линейного или нелинейного) для каких-то количественных эмпирических данных.
P-значение (p-value) – вероятность наступления гипотезы H0, доверительная вероятность (один из совокупности диагностических показателей) – результат проверки статистической гипотезы H0, показывающий вероятность того, что данные соответствуют нулевой гипотезе. Следовательно, чем меньше р-значение, тем ниже вероятность гипотезы H0 и выше вероятность альтернативной гипотезы H1.
Свойства линейного коэффициента корреляции Пирсона:
 .
. -
связь носит функциональный характер.
-
связь носит функциональный характер.
![]() -
линейная связь между переменными
отсутствует.
-
линейная связь между переменными
отсутствует.
Система независимых уравнений – в данном случае каждая зависимая переменная (у1, y2,..yn) рассматривается как следствие какого-либо набора факторов (x1, x2,..xm). Теоретически полный набор факторных переменных может либо входить в каждое уравнение или варьировать, различаться от уравнения к уравнению, образуя какие-то комбинации. В данном случае каждое отдельное уравнение самостоятельно и не связано с другими. Нахождение параметров таких уравнений проводится обычным методом наименьших квадратов.
Система рекурсивных последовательных уравнений – в данном случае между уравнениями появляется определенная связь – зависимая переменная из предыдущего уравнения входит в качестве независимой в последующее.
Система совместных (одновременных) уравнений (equation joint system) – называется совместной или одновременной, поскольку зависимые переменные в одних уравнениях перекрестно входят как независимые в другие наряду с переменными x.
Случайная функция (random function) – это функция, которая в результате опыта может принять тот или иной вид, который до наступления результата мы не можем однозначно предсказать, как правило, в силу сложности изучаемого процесса.
Спецификация регрессионной модели (specification of the regression model) – это формулирование гипотезы о связи между конкретными переменными, выбор зависимой и независимых (независимой) переменных, подбор правила (параметров линейного или нелинейного уравнения), связывающего переменные.
Средняя ошибка аппроксимации (mean approximation error):
![]() или
или
 .
.
Стандартная
ошибка оценки
(![]() )
(standard
error)
– приведена в таблице регрессионной
статистики под нормированным R-квадратом
и в данном случае названа: «стандартная
ошибка». Может интерпретироваться как
стандартное
отклонение оценки
в предположении, что ошибки предсказания
распределяются по закону Гаусса-Лапласа
(закон нормального распределения).
Стандартное отклонение оценки
демонстрирует среднюю величину ошибки,
которая допускается при замене
эмпирических значений (уi)
их оценками (
)
(standard
error)
– приведена в таблице регрессионной
статистики под нормированным R-квадратом
и в данном случае названа: «стандартная
ошибка». Может интерпретироваться как
стандартное
отклонение оценки
в предположении, что ошибки предсказания
распределяются по закону Гаусса-Лапласа
(закон нормального распределения).
Стандартное отклонение оценки
демонстрирует среднюю величину ошибки,
которая допускается при замене
эмпирических значений (уi)
их оценками (![]() ).
).
Структурные уравнения (structural equations) – уравнения, составляющие исходную модель (делятся на две группы: 1) поведенческие уравнения, описывающие эмпирические взаимосвязи между переменными; 2) уравнения тождества. Используются при оценивании систем одновременных уравнений.
Тест Гольдфельда-Квандта (Goldfeld-Quandt test for heteroscedasticity) – применяется для выявления гетероскедастичности при сравнительно небольшом числе наблюдений.
Фиктивная (искусственная) переменная (dummy variables) – переменная, полученная в результате квантификации качественных данных (принимает значение нулей и единиц).
Функцией
f
(function
f),
заданной
на некотором множестве Х,
называется правило, по которому каждому
элементу х![]() Х
ставится в соответствие один и только
один элемент y
Х
ставится в соответствие один и только
один элемент y![]() Y.
Множество Х
называется областью определения функции,
а Y
– областью её значений. То есть функция
это правило, связывающее две и более
переменные: у=f(x1,x2,…xn),
из которых одна является зависимой, а
другая или другие – независимыми.
Переменную в левой части уравнения
называют зависимой, объясняемой,
управляемой, эндогенной (внутренней)
переменной или просто функцией, а
переменную (переменные) в правой части
– независимой, управляющей, объясняющей,
экзогенной (внешней) переменной,
предиктором или аргументом функции.
Y.
Множество Х
называется областью определения функции,
а Y
– областью её значений. То есть функция
это правило, связывающее две и более
переменные: у=f(x1,x2,…xn),
из которых одна является зависимой, а
другая или другие – независимыми.
Переменную в левой части уравнения
называют зависимой, объясняемой,
управляемой, эндогенной (внутренней)
переменной или просто функцией, а
переменную (переменные) в правой части
– независимой, управляющей, объясняющей,
экзогенной (внешней) переменной,
предиктором или аргументом функции.
Эластичность (elasticity) переменной игрек по переменной икс – это показатель того, на сколько процентов изменяется игрек при изменении икс на 1%. Всегда измеряется в относительных величинах (процентах), что позволяет проводить сравнение вне зависимости от того, в каких единицах измеряются исходные переменные икс и игрек.