

metoda_2013
.pdfБАЗЫ ДАННЫХ.
3. Семантическое моделирование данных. ER-диаграммы.
Моделирование структуры базы данных при помощи алгоритма нормализации имеет серьезные недостатки:
Первоначальное размещение всех атрибутов в одном отношении является очень неестественной операцией. Интуитивно разработчик сразу проектирует несколько отношений в соответствии с обнаруженными сущностями. Даже если совершить насилие над собой и создать одно или несколько отношений, включив в них все предполагаемые атрибуты, то совершенно неясен смысл полученного отношения.
Невозможно сразу определить полный список атрибутов. Пользователи имеют привычку называть разными именами одни и те же вещи или наоборот, называть одними именами разные вещи.
Для проведения процедуры нормализации необходимо выделить зависимости атрибутов, что тоже очень нелегко, т.к.
необходимо явно выписать все зависимости, даже те, которые являются очевидными.
Вреальном проектировании структуры базы данных применяются другой метод - так называемое, семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь
(ER - Entity-Relationship).
Определение 1. Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная".
40

БАЗЫ ДАННЫХ.
Каждая сущность в модели изображается в виде прямоугольника с наименованием:
Сотрудник
Определение 2. Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Иванов".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Определение 3. Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность:
Сотрудник
Табельный
номер
Фамилия
Имя
Отчество
Должность
Зарплата
Определение 4. Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Неизбыточность заключается в том, что удаление любого атрибута из ключа нарушается его уникальность.
Сущность может иметь несколько различных ключей. Ключевые атрибуты изображаются на диаграмме подчеркиванием:
Сотрудник
Табельный
номер
Фамилия
Имя
41
БАЗЫ ДАННЫХ.
Отчество
Должность
Зарплата
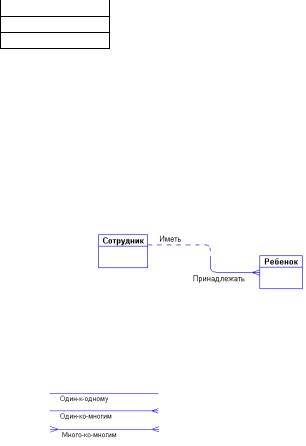
Определение 5. Связь - это некоторая ассоциация между двумя сущностями. Одна сущность может быть связана с другой сущностью или сама с собою.
Связи позволяют по одной сущности находить другие сущности, связанные с нею.
Например, связи между сущностями могут выражаться следующими фразами - "СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности:
Каждая связь имеет два конца и одно или два наименования. Наименование обычно выражается в неопределенной глагольной форме: "иметь", "принадлежать" и т.п. Каждое из наименований относится к своему концу связи. Иногда наименования не пишутся ввиду их очевидности. Каждая связь может иметь один из следующих типов связи:
Связь типа один-к-одному означает, что один экземпляр первой сущности (левой) связан с одним экземпляром второй сущности (правой). Связь один-к-одному чаще всего свидетельствует о том, что на самом деле мы имеем всего одну сущность, неправильно разделенную на две.
Связь типа один-ко-многим означает, что один экземпляр первой сущности (левой) связан с несколькими экземплярами второй сущности (правой). Это наиболее часто используемый тип связи. Левая сущность (со стороны "один") называется
родительской, правая (со стороны "много") - дочерней.
Характерный пример такой связи приведен на Рис. 4. Связь типа много-ко-многим означает, что каждый
экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и каждый экземпляр второй сущности может быть связан с несколькими экземплярами первой
42
БАЗЫ ДАННЫХ.
сущности. Тип связи много-ко-многим является временным типом связи, допустимым на ранних этапах разработки модели. В дальнейшем этот тип связи должен быть заменен двумя связями типа один-ко-многим путем создания промежуточной сущности.
Каждая связь может иметь одну из двух модальностей связи:
Модальность "может" означает, что экземпляр одной сущности может быть связан с одним или несколькими экземплярами другой сущности, а может быть и не связан ни с одним экземпляром.
Модальность "должен" означает, что экземпляр одной сущности обязан быть связан не менее чем с одним
экземпляром другой сущности.
Связь может иметь разную модальность с разных концов (как на Рис. 4).
Описанный графический синтаксис позволяет однозначно читать диаграммы, пользуясь следующей схемой построения фраз:
<Каждый экземпляр СУЩНОСТИ 1> <МОДАЛЬНОСТЬ СВЯЗИ> <НАИМЕНОВАНИЕ СВЯЗИ> <ТИП СВЯЗИ> <экземпляр СУЩНОСТИ 2>.
Каждая связь может быть прочитана как слева направо, так и справа налево. Связь на Рис. 4 читается так:
Слева направо: "каждый сотрудник может иметь несколько детей".
Справа налево: "Каждый ребенок обязан принадлежать ровно одному сотруднику".
Различают концептуальные и физические ER-диаграммы.
Концептуальные диаграммы не учитывают особенностей конкретных СУБД. Физические диаграммы строятся по концептуальным и представляют собой прообраз конкретной базы данных. Сущности, определенные в концептуальной диаграмме становятся таблицами, атрибуты становятся колонками таблиц (при этом учитываются допустимые для данной СУБД типы данных и наименования столбцов), связи реализуются путем миграции ключевых атрибутов родительских сущностей и создания внешних ключей.
При правильном определении сущностей, полученные таблицы будут сразу находиться в 3НФ. Основное достоинство
43
БАЗЫ ДАННЫХ.
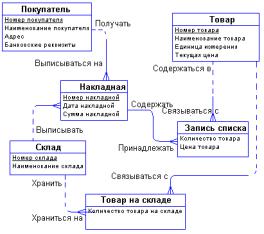
метода состоит в том, модель строится методом последовательных уточнений первоначальных диаграмм. Пример концептуальной ER-диаграммы:
4.Оператор SELECT языка SQL. Запросы на чтение из одной таблицы. Виды условий поиска.
Оператор SELECT является фактически самым важным для пользователя и самым сложным оператором SQL. Он предназначен для выборки данных из таблиц, т.е. он, собственно, и реализует одно их основных назначение базы данных - предоставлять информацию пользователю.
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных и его результатом всегда является таблица.
Синтаксис оператора выборки
Оператор выборки ::= Табличное выражение
[ORDER BY
{{Имя столбца-результата [ASC | DESC]} | {Положительное целое
[ASC | DESC]}}.,..];
Табличное выражение ::= Select-выражение
[
{UNION | INTERSECT | EXCEPT} [ALL]
{Select-выражение | TABLE Имя таблицы | Конструктор значений
44
БАЗЫ ДАННЫХ.
таблицы}
]
Select-выражение ::=
SELECT [ALL | DISTINCT]
{{{Скалярное выражение | Функция агрегирования | Selectвыражение} [AS Имя столбца]}.,..}
| {{Имя таблицы|Имя корреляции}.*}
| *
FROM {
{Имя таблицы [AS] [Имя корреляции] [(Имя столбца.,..)]}
| {Select-выражение [AS] Имя корреляции [(Имя столбца.,..)]} | Соединенная таблица }.,..
[WHERE Условное выражение]
[GROUP BY {[{Имя таблицы|Имя корреляции}.]Имя столбца}.,..] [HAVING Условное выражение]
Select-выражение в разделе SELECT, используемое в качестве значения для отбираемого столбца, должно возвращать таблицу, состоящую из одной строки и одного столбца, т.е. скалярное выражение.
Условное выражение в разделе WHERE должно вычисляться для каждой строки, являющейся кандидатом в результатирующее множество строк. В этом условном выражении можно использовать подзапросы. Синтаксис условных выражений, допустимых в разделе WHERE рассматривается ниже.
Раздел HAVING содержит условное выражение, вычисляемое для каждой группы, определяемой списком группировки в разделе GROUP BY. Это условное выражение может содержать функции агрегирования, вычисляемые для каждой группы. Условное выражение, сформулированное в разделе WHERE, может быть перенесено в раздел HAVING. Перенос условий из раздела HAVING в раздел WHERE невозможен, если условное выражение содержит агрегатные функции. Перенос условий из раздела WHERE в раздел HAVING является плохим стилем программирования - эти разделы предназначены для различных по смыслу условий (условия для строк и условия для групп строк).
Если в разделе SELECT присутствуют агрегатные функции, то они вычисляются по-разному в зависимости от наличия раздела GROUP BY. Если раздел GROUP BY отсутствует, то результат запроса возвращает не более одной строки. Агрегатные функции вычисляются по всем строкам, удовлетворяющим условному выражению в разделе WHERE. Если раздел GROUP BY
45

БАЗЫ ДАННЫХ.
присутствует, то агрегатные функции вычисляются по отдельности для каждой группы, определенной в разделе GROUP
BY.
Скалярное выражение - в качестве скалярных выражений в разделе SELECT могут выступать либо имена столбцов таблиц, входящих в раздел FROM, либо простые функции, возвращающие скалярные значения.
Выборка из одной таблицы:
Простейший вид оператора SELECT для выборки данных из одной таблицы:
SELECT [DISTINCT] <список полей> FROM <таблица>
WHERE <условие>
Пример 1. Выбрать все данные из таблицы поставщиков (ключевые слова SELECT… FROM…):
SELECT * FROM P;
Пример 2. Выбрать все строки из таблицы поставщиков, удовлетворяющих некоторому условию:
SELECT * FROM P WHERE P.PNUM > 2;
Пример 3. Выбрать некоторые колонки из исходной таблицы:
SELECT P.NAME FROM P;
Пример 4. Выбрать некоторые колонки из исходной таблицы, удалив из результата повторяющиеся строки:
SELECT DISTINCT P.NAME FROM P;
Пример 5. Использование скалярных выражений и переименований колонок в запросах:
SELECT TOVAR.TNAME, TOVAR.KOL, TOVAR.PRICE, "=" AS EQU, TOVAR.KOL * TOVAR.PRICE AS SUMMA FROM TOVAR;
В результате получим таблицу с колонками, которых не было в исходной таблице TOVAR:
TNAME KOL PRICE EQU SUMMA
Болт |
10 |
100 |
= |
1000 |
|
|
|
|
|
Гайка |
20 |
200 |
= |
4000 |
Пример 6. Упорядочение результатов запроса (ORDER BY): SELECT PD.PNUM, PD.DNUM, PD.VOLUME FROM PD ORDER BY DNUM;
46
БАЗЫ ДАННЫХ.
В результате получим следующую таблицу, упорядоченную по полю DNUM:
PNUM |
DNUM |
VOLUME |
|
|
|
1 |
1 |
100 |
|
|
|
2 |
1 |
150 |
|
|
|
2 |
2 |
250 |
|
|
|
1 |
3 |
300 |
|
|
|
Виды условий поиска
Выражение разделе WHERE оператора SELECT может содержать следующие предикаты:
Предикат сравнения
Пример. Сравнение поля таблицы и скалярного значения:
POSTAV.VOLUME > 100
Предикат between
Конструктор значений строки [NOT] BETWEEN Конструктор значений строки AND Конструктор значений строки
Пример: PD.VOLUME BETWEEN 10 AND 100
Предикат in
Конструктор значений строки [NOT] IN {(Select-выражение) | (Выражение для вычисления значения.,..)}
Пример: P.NUM IN (1, 2, 3)
Предикат like
Выражение для вычисления значения строки-поиска
[NOT] LIKE
Выражение для вычисления значения строки-шаблона
[ESCAPE Символ]
Предикат LIKE производит поиск строки-поиска в строкешаблоне.
Предикат null
Конструктор значений строки IS [NOT] NULL
Предикат NULL применяется специально для проверки, не равно ли проверяемое выражение null-значению.
Предикат количественного сравнения
Конструктор значений строки {= | < | > | <= | >= | <>}
{ANY | SOME | ALL} (Select-выражение)
Предикат exist
EXIST (Select-выражение)
47
БАЗЫ ДАННЫХ.
Предикат EXIST возвращает значение TRUE, если результат подзапроса (select-выражения) не пуст.
Предикат unique
UNIQUE (Select-выражение)
Предикат UNIQUE возвращает TRUE, если в результате подзапроса (select-выражения) нет совпадающих строк.
Предикат match
Конструктор значений строки MATCH [UNIQUE] [PARTIAL | FULL] (Select-выражение)
Предикат MATCH проверяет, будет ли значение, определенное в конструкторе строки совпадать со значением любой строки, полученной в результате подзапроса.
Предикат overlaps
Конструктор значений строки OVERLAPS Конструктор значений строки
Предикат OVERLAPS, является специализированным предикатом, позволяющем определить, будет ли указанный период времени перекрывать другой период времени.
5. Многотабличные запросы SQL. Внутренние соединения.
Запросы могут выбирать данные из нескольких таблиц. Эти таблицы должны быть перечислены после слова FROM. Если таблицы не связаны между собой, то результатом запроса будут всевозможные комбинации (декартово произведение) записей отдельных таблиц, что не имеет практического смысла.
Пример: Рассмотрим отношения по поставщикам S (S# , Sn, Scity), изделиям P (P#, Pn, Pcity, W) и поставкам SP (S#, P#, Q).
Здесь S# - номер поставщика, Sn – его имя, Scity – место проживания, P# - номер изделия, Pn – его наименование, Pcity – место хранения, W – вес, Q – объем поставки.
Пусть требуется получить список поставок поставщиков из Москвы с указанием имени поставщика. Запрос
SELECT S.S#, Sn, P#, Q FROM S, SP WHERE Scity
=’Москва’ присоединит к каждому поставщику из Москвы все поставки из
таблицы SP независимо от места проживания поставщика, что, очевидно, не соответствует заданию. Правильным решением является запрос
SELECT S.S#, Sn, P#, Q FROM S, SP WHERE Scity =’Москва’ AND S.S#=SP.S#
Условие S.S#=SP.S# обеспечивает связь таблиц S и SP, что соответствует операции соединения реляционной алгебры. Если
48
БАЗЫ ДАННЫХ.
атрибут присутстствует более чем в одной таблице, сначала указывается имя таблицы, а затем после точки имя атрибута.
Как и в реляционной алгебре, возможно и θ-соединение таблиц, где θ задает знак операции сравнения (‘<’, ’>’ и т. п.), но такой вариант соединения редко применяется на практике. Для соединений таблиц имеются и другие синтаксические конструкции, которые будут описаны ниже. Рассмотрим еще два примера.
Примеры:
1. Найти список поставщиков из Казани, поставляющих изделие с номером P2
SELECT Sname FROM S, SP WHERE S.S#=SP.S# AND Scity
=’Казань’ AND P# = P1
Здесь выбирается поле Sname из таблицы S, но в качестве источника данных указывается и таблица SP, поскольку условия выборки и связи используют поля этой таблицы.
2. Получить список поставок объема более 100 единиц с указанием имен поставщиков и наименований деталей
SELECT Sname, Pname, Q FROM S, P, SP WHERE S.S#=SP.S# AND P.P#=SP.P# AND
Q > 100
Соединение таблиц может быть и по нескольким атрибутам. Например, деталь в разных таблицах может идентифицироваться двумя атрибутами совместно: номером изделия и номером детали в изделии.
Таблица может соединяться и сама с собой. Рассмотрим для примера таблицу сотрудников и их непосредственных руководителей S (S#, Sname, Shef#), где S# - номер сотрудника, Sname – его имя, Shef# - номер руководителя. Пусть требуется дать полный список имен сотрудников и их руководителей.
Если бы существовали две копии этой таблицы S1 и S2, то решением был бы запрос
SELECT S1.Sname, S2.Sname FROM S1, S2 WHERE S1.Shef# = S2.S#
А как обойтись без копирования содержимого таблицы S?
Для подобных случаев в SQL введены локальные псевдонимы или алиасы таблиц. Псевдоним действует в пределах запроса и позволяет обращаться к одной и той же таблице, как к двум разным таблицам. При использовании псевдонимов S1 и S2 в нашем случае вид запроса почти не изменится
SELECT S1.Sname, S2.Sname FROM S S1, S S2 WHERE S1.Shef# = S2.S#
49