

metoda_2013
.pdfТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
Концевые (висячие) узлы синтаксического дерева – это узлы, не имеющего подчиненного куста. При чтении слева направо концевые узлы образуют цепочку, вывод которой представлен деревом. Таким образом, после третьего непосредственного вывода в (1) цепочка концевых узлов – суть <цифра> <цифра> (см. рис.2а).
Концевой куст – это куст, все узлы которого концевые. На рис. 1б один концевой куст; его узлы <чс> и <цифра>. На рис.2в два концевых куста с узлами 2 и 2.
Когда речь идет о деревьях, часто используется следующая терминология. Пусть N – узел дерева. Сыновьями N называются узлы куста, подчиненного N. N - их отец. Сыновья называются братьями, самым младшим считается самый левый из них. На рис.2 б <чс> является единственным сыном узла <число>. Тот же самый <чс> имеет двух сыновей: <чс> и <цифра>. Отцом узла 2 является <цифра>.
Поддерево синтаксического дерева состоит из узла дерева
(называемого корнем поддерева) вместе с той частью дерева (если она имеется), которая исходит от него. Поддеревья тесно связаны с фразами; концевые узлы образуют фразу для корня данного поддерева. Проследим это более подробно. Если U – корень поддерева и если u – цепочка из концевых узлов поддерева, то U + u. Пусть x- цепочка концевых узлов слева от u, а y- цепочка концевых узлов справа от u, то есть xuyсентенциальная форма, заданная деревом. Тогда Z *xUy, а это означает, что u есть фраза для U в xuy.
Построение вывода по дереву.
Можно восстановить вывод по синтаксическому дереву при помощи обратного процесса. Из рис. 2 с видно, что концевые узлы образуют цепочку 22. Самый правый концевой куст указывает непосредственный вывод: 2 <цифра> 22.
Чтобы пройти по синтаксическому дереву до 2 <цифра>, мы отсекаем куст от дерева – удаляем его. Например, отсекание этого куста (на рис. 2 с) дает нам дерево на рис. 2 б. Этот процесс часто называют непосредственной редукцией.
Рассматривая рис.2 б, можно видеть, что последним здесь должен быть вывод <цифра> <цифра> 2<цифра>. Это нам дает <цифра> <цифра> 2<цифра> 22.
Продолжаем процесс, всегда восстанавливая последний непосредственный вывод, на который указывает концевой куст синтаксического дерева, и затем отсекая этот куст.
Подводя итог, сформулируем следующие положения о синтаксических деревьях:
230
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
для каждого синтаксического дерева существует по крайней мере один вывод;
для каждого вывода есть соответствующее синтаксическое дерево (но несколько разных выводов могут иметь одно и тоже дерево);
куст дерева указывает на непосредственный вывод, в котором имя куста заменяется узлами куста.
Следовательно, в грамматике существует правило левой частью
которого является имя куста, а правой частью – цепочка из узлов куста;
концевые узлы дерева образуют выводимую сентенциальную форму;
пусть U – корень поддерева для сентенциальной формы w=xuy, где u образует цепочку концевых узлов этого поддерева. Тогда u - фраза сентенциальной формы w для U. Она является простой фразой, если поддерево представлено единственным кустом.
|
S |
|
|
|
|
||
T |
|
|
|
|
|
S |
|
|
|
|
|
|
|||
|
|
|
|
||||
|
+ |
|
|
|
|
|
|
a |
|
|
T |
|
|
|
S |
|
|
|
|
|
|||
|
|
|
|
||||
|
|
|
|
|
|
||
|
|
|
+ |
|
|||
|
|
|
|
|
|||
|
|
|
|
|
|
|
T |
|
|
|
|
|
|
|
|
|
|
|
b |
|
|
||
|
|
|
|
|
|
||
a
Неоднозначность.
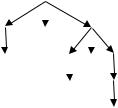
Определение. Предложение грамматики неоднозначно, если для его вывода существуют два синтаксических дерева. Грамматика неоднозначна, если она допускает неоднозначные предложения, в противном случае она однозначна. Если сентенциальная форма неоднозначна, то она имеет более чем одно синтаксическое дерево и поэтому более чем одну основу. Покажем это на примере, который в тоже время предоставит нам очень полезную грамматику для арифметических выражений. Рассмотрим следующую грамматику арифметических выражений, в которой множество терминальных символов представляют: единственный операнд- i(в качестве идентификатора), круглые скобки и бинарные операторы + и * : <Е> ::= <Е> + <Е> | <Е>*<Е> | (<Е>) | i.
Сентенциальная форма <Е> + <Е> * <Е> имеет два синтаксических дерева (рис.3) и две основы : <Е> + <Е> и <Е> * <Е>. Так как грамматика неоднозначна, разбор сентенциальной формы можно начать с любой из основ. Таким образом, мы не можем сказать, что выполняется раньше: умножение или
231
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
сложение.
Рис. 3. Два синтаксического дерева для <Е> + <Е> * <Е>. Рассмотрим теперь грамматику , состоящую из следующих правил:
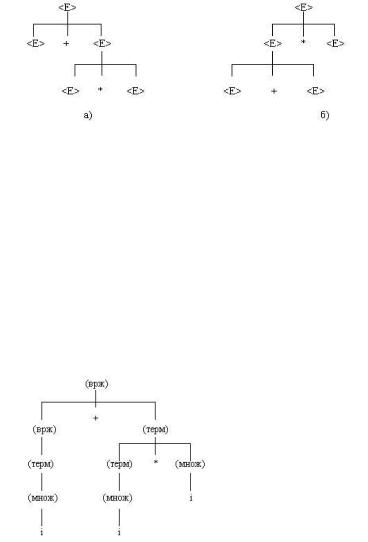
<врж> :: = <терм> | <врж> + <терм> | <врж> - <терм> <терм> :: = <множ> | <терм> * <множ> | <терм> / <множ> <множ> :: = (<врж>) | i
Единственное дерево для выражения i + i * i показано ниже (рис.4), и, таким образом, в соответствии с этой грамматикой предложение однозначно. В действительности все предложения G3 однозначны. Теперь определим, согласно G3, что в выражении i + i * i должно выполняться раньше: умножение или сложение. Операндами для +, согласно дереву, являются <врж>, из которого получается i, и <терм>, из которого в свою очередь получается i * i. Это означает, что умножение должно быть выполнено первым для того, чтобы образовать <терм> для сложения, следовательно, умножение предшествует сложению.
Рис.4. Дерево для выражения i + i * i.
Задача синтаксического разбора.
Синтаксический разбор имеет дело с предложениями языка программирования или с сентенциальной формой.
Разбор сентенциальной формы означает построение вывода, и, возможно, синтаксического дерева для нее. Программу разбора
232
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
называют также распознавателем, так как она распознает только предложения рассм. грамматики.
Все алгоритмы разбора, которые здесь рассматриваются, называются алгоритмами разбора слева направо ввиду того, что они обрабатывают сначала самые левые символы рассматриваемой цепочки и продвигаются по цепочке только тогда, когда это необходимо.
Различают две категории алгоритмов разбора: нисходящий (сверху вниз) и восходящий (снизу вверх). Эти термины соответствуют способу построения синтаксических деревьев. При нисходящем разборе дерево строится от корня (начального символа) вниз к концевым узлам.
Основой всякой сентенциальной формы называется самая левая простая фраза.
Определение. Непосредственный вывод xUy ->x u y называется каноническим и записывается xUy->x u y, если y содержит только терминалы. Вывод w->+v называется каноническим и записывается w->+v, если каждый непосредственный вывод в нем является каноническим.
Каждое предложение, но не каждая сентенциальная форма имеет канонический вывод.
Пример. Рассмотрим в качестве примера сентенциальную форму 3 D грамматики (1). Ее единственным выводом является <число> ->N D ->D D ->3 D. И второй, и третий непосредственные выводы не являются каноническими.
Сентенциальная форма, которая имеет канонический вывод, называется канонической сентенциальной формой.
Рассмотрим пример построения дерева снизу-вверх:
1)Входная цепочка рассматривается слева направо.
2)Если существует правило регулярной грамматики, из которого выводится рассматриваемый символ (последовательность символов) входной цепочки, то данный символ (последовательность символов) заменяется на нетерминал, стоящий в левой части данного правила.
3)Если на каком-то шаге не найдется правила, позволяющего произвести свертку, то данное предложение не принадлежит регулярной грамматике.
Вданном случае цепочка принадлежит заданной грамматике.
233

ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
Рассмотрим пример построения дерева сверху-вниз:
1)Построение дерева начинается с аксиомы S, которая помещается в корень дерева.
2)В грамматике выбирается необходимое правило, помеченное рассматриваемым нетерминальным символом. В данном случае на первом шаге выбираем первое правило, т.к. по второму правилу мы не достигнем второго символа входной цепочки b.
3)Рассматриваемый нетерминал на дереве разбора раскрывается на символы, стоящие в правой части выбранного правила грамматики.
4)Построение продолжается до тех пор, пока все концевые вершины дерева (вершины не имеющие в своем подчинении каких либо вершин) не будут обозначены терминальными символами, в противном случае необходимо вернуться ко второму шагу и продолжить построение по другому правилу.
5)Если для входной цепочки можно построить дерево вывода, то она принадлежит данной регулярной грамматике. Рассматриваемая цепочка a b d не принадлежит грамматике, т.к.
не существует концевой вершины для входного символа d.
234
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
5. Сканер. Принципы построения.
Лексический анализатор (сканер) представляет ту часть компилятора, которая читает литеры первоначальной исходной программы и строит слова, или иначе символы, исходной программы :
идентификаторы, служебные слова, целые числа,
одно - или двулитерные разделители, такие как *, +,**, /* Иногда символы называются атомами или лексемами.
В чистом виде сканер выполняет постой лексический анализ исходной программы, и поэтому сканер называют также
лексическим анализатором.
Результат работы сканера. Сканер строит внутреннее представление для каждого символа. В большинстве случаев это целое число фиксированной длины (байт, полуслово, слово и т.д.). В других частях компилятора гораздо эффективнее обрабатываются эти целые числа, чем цепочки переменной длины, которыми фактически представляются символы.
Во внутреннем представлении некоторый номер обозначает «идентификатор», другой номер – «целое число». Таким образом, во внутреннем представлении все идентификаторы обозначаются одним и тем же числом. Это естественно, поскольку «идентификатор» для синтакического анализатора является терминальным символом, и поэтому безразлично, какой идентификатор встречается в каждом конкретном случае. Однако при семантическом анализе приходится иметь дело с самим идентификатором, поэтому его необходимо сохранить. Вопрос исчерпан, если сканером выдается две величины: первая - внутренне представление, вторая – фактический символ или ссылка на него.
Покажем, как проектируется сканер для небольшого и простого языка. Нас интересуют лишь символы языка, и именно их построение является целью лексического анализа.
Символы исходного языка.
Символами в языке являются:
разделители (/, ",",:=,+, *, (, ), ;, //,/*,*/),
служебные слова (BEGIN, REAL и END),
идентификаторы (которые не могут быть служебными словами) и целые числа.
235
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
По крайней мере, один пробел должен отделять смежные идентификаторы, целые числа и служебные слова. Ни одного пробела не должно появляться между литерами в слове.
Идентификаторы имеют вид: буква {буква | цифра} Целые числа имеют вид: цифра {цифра}
В добавлении ко всему сканер должен распознавать и исключать комментарий. Комментарий начинается с двулитерного символа /* и заканчивается при первом появлении двулитерного символа
*/.
Внутреннее |
Символ |
Представление |
представление |
|
|
0 |
не определен |
|
1 |
идентификатор |
|
2 |
целое |
|
|
|
|
3 |
BEGIN |
|
|
|
|
4 |
REAL |
|
5 |
END |
|
|
|
|
6 |
/ |
|
|
|
|
7 |
+ |
|
|
|
|
8 |
, |
|
9 |
* |
|
|
|
|
10 |
( |
|
|
|
|
11 |
) |
|
12 |
// |
|
13 |
:= |
|
|
|
|
14 |
; |
|
|
|
|
Рис.1. Внутреннее представление символов.
Рассмотрим, например, сегмент программы
BEGIN REAL A,B; A:=B+5/C; /*КОМЕТАРИЙ*/ END //
Сканер передаст вызывающей его программе следующее:
Шаг |
Результат |
Смысл |
|
|
|
1 |
2, “BEGIN” |
BEGIN |
2 |
4, “REAL” |
REAL |
3 |
1, “A” |
идентификатор A |
|
|
|
4 |
8, “,” |
“,” |
|
|
|
5 |
1, “B” |
идентификатор B |
6 |
14, “;” |
|
|
|
|
7 |
1, “A” |
идентификатор A |
|
|
|
236
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
8 |
13, “:=” |
:= |
9 |
1, “B” |
идентификатор B |
|
|
|
10 |
7, “+” |
+ |
|
|
|
11 |
2, “5” |
целое |
12 |
1, “C” |
идентификатор C |
|
|
|
13 |
14, “;” |
|
|
|
|
14 |
5, “END” |
END |
|
|
|
15 |
2, “//” |
// |
Второстепенные функции сканера: удаление из текста исходной программы комментариев и не несущих смысловой нагрузки пробелов (табуляций и символов новой строки); согласование сообщений об ошибках компиляции и текста исходной программы.
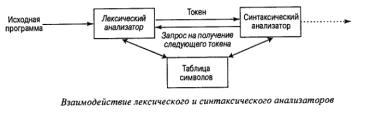
Принцип построения:
Лексический анализатор обычно реализуется в виде подпрограммы синтаксического анализатора или подпрограммы вызываемой им. При получении запроса на следующий токен лексический анализатор считывает входной поток символов до точной идентификации следующего токена.
Часто токены имеют внутреннее представление в виде целых чисел фиксированной длинны. В других частях компилятора гораздо эффективнее обрабатываются эти целые числа, чем цепочки переменной длины.
Термины:
Лексема – последовательность символов исходной программы. Токен – 1) терминальный символ грамматики исходного языка; 2) тип лексемы. Лексемы, соответствующие шаблонам токенов, представляются в исходной программе в виде строки символов, которые рассматриваются вместе как лексическая единица. Шаблон – правило, описывающее набор лексем, которые могут представлять определенный токен в исходной программе. Так,
237
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
шаблон токена const представляет собой строку const, являющуюся ключевым словом.
Токен |
Пример лексем |
Неформальное |
|
|
|
|
описание шаблона |
|
|
const |
const |
const |
|
|
id |
pi, count, d2 |
Буква, за |
которой |
|
|
|
следуют |
буквы |
и |
|
|
цифры |
|
|
num |
3.14, 0, 5, 6E2 |
Любая |
числовая |
|
|
|
константа |
|
|
6. Синтаксический анализ. Нисходящий разбор, рекурсивный
спуск. Проблемы нисходящего разбора.
Нисходящий разбор
Большинство известных методов анализа принадлежат одному из двух классов, один из которых объединяет нисходящие (top-down) алгоритмы, а другой – восходящие (bottom-up) алгоритмы. Происхождение этих терминов связано с тем, каким образом строятся узлы синтаксического дерева: либо от корня (аксиомы грамматики) к листьям (терминальным символам), либо от листьев к корню.
Нисходящие анализаторы строят вывод, начиная от аксиомы грамматики и заканчивая цепочкой терминальных символов. С нисходящими анализаторами связаны так называемые LLграмматики, которые обладают следующими свойствами:
Они могут быть проанализированы без возвратов
Первая буква L означает, что мы просматриваем входную цепочку слева направо (left-to-right scan)
Вторая буква L означает, что строится левый вывод цепочки
(leftmost derivation).
Популярность нисходящих анализаторов связана с тем, эффективный нисходящий анализатор достаточно легко может быть построен вручную, например, методом рекурсивного спуска. Кроме того, LL-грамматики легко обобщаются: грамматики, не являющиеся LL-грамматиками, обычно могут быть проанализированы методом рекурсивного спуска с возвратами.
238
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
Рекурсивный спуск
Основные положения
Процессор грамматического разбора, основанный на методе рекурсивного спуска, состоит из отдельных процедур.
Процедура разбора старается во входном потоке найти подстроку, которая может быть интерпретирована, как правая часть правила для нетерминала, связанного с данной процедурой.
В процессе работы она может вызывать другие подобные процедуры или даже рекурсивно саму себя, для поиска других нетерминальных символов.
Если процедура находит соответствие нетерминальному символу, то она заканчивает свою работу, и передает в вызывающую ее программу признак успешного завершения
и устанавливает указатель текущей лексемы на первый
символ после распознанной подстроки.
Иначе она заканчивается признаком неудачи, или же вызывает процедуру выдачи диагностического сообщения и процедуру восстановления.
Пример:
Рассмотрим процедуру для оператора READ . Грамматика для оператора:
READ:: =
•обнаружили лексему READ
•следующая лексема должна быть (,
•<id-list> вызов процедуры,
•если успешно, то лексема должна быть ),
•должна быть ; ,
•успех. end.
Достоинства
простота и скорость написания транслятора;
соответствие грамматики и анализаторов. Это увеличивает вероятность правильности написания программы.
Недостатки
большое число вызовов процедур, отсюда относительно медленный анализатор;
большой объем полученного анализатора;
данный метод способствует включению в синтаксический анализ процедур семантического анализа и генерации кода. С одной стороны, это хорошо, так как оператор разбирается
239