

metoda_2013
.pdfСТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
Удаление.
1)Если удаляемый узел не имеет сыновей – он может быть удален без дальнейших изменений дерева (напр., вершины
3,11,40 и т.д)
2)Если узел имеет только одно поддерево, то его единственный сын перемешается на его место (Например при удалении вершин
5,25,37)
3)Если узел имеет двух сыновей: сначала на место удаленной вершины помещается один из двух соседних элементов (это может быть 1)меньший ключ самой правой вершины левого поддерева 2)больший ключ самой левой вершины правого поддерева). Найденная вершина имеет не более одного сына, поэтому дальнейшее удаление идет по описанному выше алгоритму.
Например, при удалении вершины 36 из исходного дерева, она может быть заменена вершиной 25 либо 37. При замене вершиной 25, на месте вершины 25 оказывается узел 11 (по правилу 2):
20
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
5. АВЛ-деpевья и их балансиpовка
Трудоемкость поиска по бинарному дереву поиска зависит от структуры дерева. Наболее эффективен поиск по т.н. сбалансированному дереву – дереву, в котором для каждого узла высота его поддеревьев отличается не более, чем на 1. Такие деревья поиска называют АВЛ-деревьями (по имени авторов Адельсон-Вельский и Лендис) hl - высота левого поддерева; hr - высота правого поддерева |hl-hr|=2 - признак нарушения балансировки. Высота пустого дерева= -1 (для удобства)
Чтобы получить сбалансированное дерево, необходимо выполнить некоторую трансформацию данного дерева так, чтобы: 1) прохождение трансформированного дерева в симметрично порядке должно быть таким же, как для первоначального дерева; 2) трансформированное дерево должно быть сбалансированным Преобразование дерева с целью балансировки наз-ся поворотом.
Сущ.4 вида поворотов:LL,RR,LR,RL. Повороты LL,RR– одинарные.LR,RL – двойные.
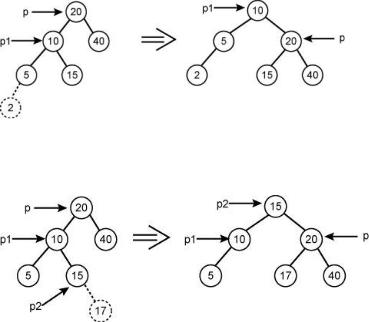
Пример LL-поворота. Пусть в исходное АВЛ дерево включается новый элемент с ключом 2:
Поворот осуществляется в три операции: p1 := p^.left; p^.left := p1^.right; p1^.right := p; RR поворот осуществляется симметрично.
Пример LR поворота. Пусть в исходное АВЛ дерево включается новый элемент с ключом 17:
LR поворот требует шести операций: p1 := p^.left; p2 := p1^.right; p1^.right := p2^.left; p2^.left := p1; p^.left := p2^.right; p2^.right := p
21
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
RL поворот осуществляется симметрично.
При любом включении рассматривается число уровней в левом и правом поддереве для всех вершин на пути от включаемой вершины к корню. При первом же случае нарушения баланса он восстанавливается. При включении достаточно 1 раз восстанавливать баланс.
Исключение из АВЛ дерева происходит как из обычного дерева поиска, далее требуется анализ, есть ли нарушение баланса и соответствующие повороты на пути от исключаемой вершины к корню.
6. Хеширование
Хеширование (иногда хэширование, англ. hashing) — преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования также называются хеш-функциями или функциями свёртки, а их результаты называют хешем, хеш-кодом или дайджестом сообщения (англ. message digest).
Хеширование применяется для сравнения данных: если у двух массивов хеш-коды разные, массивы гарантированно различаются; если одинаковые — массивы, скорее всего, одинаковы. В общем случае однозначного соответствия между исходными данными и хеш-кодом нет в силу того, что количество значений хеш-функций меньше, чем вариантов входного массива; существует множество массивов, дающих одинаковые хеш-коды
— так называемые коллизии. Вероятность возникновения коллизий играет немаловажную роль в оценке качества хешфункций.
22
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
Существует множество алгоритмов хеширования с различными характеристиками (разрядность, вычислительная сложность, криптостойкость и т. п.). Выбор той или иной хеш-функции определяется спецификой решаемой задачи. Простейшими примерами хеш-функций могут служить контрольная сумма или
CRC.
Хеш-таблица — это структура данных, реализующая интерфейс ассоциативного массива, а именно, она позволяет хранить пары (ключ, значение) и выполнять три операции: операцию добавления новой пары, операцию поиска и операцию удаления пары по ключу.
Существует два основных варианта хеш-таблиц: с цепочками и открытой адресацией. Хеш-таблица содержит некоторый массив H, элементы которого есть пары (хеш-таблица с открытой адресацией) или списки пар (хеш-таблица с цепочками).
Выполнение операции в хеш-таблице начинается с вычисления хеш-функции от ключа. Получающееся хеш-значение i = hash(key) играет роль индекса в массиве H. Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива H[i].
Ситуация, когда для различных ключей получается одно и то же хеш-значение, называется коллизией. Такие события не так уж и редки — например, при вставке в хеш-таблицу размером 365 ячеек всего лишь 23-х элементов вероятность коллизии уже превысит 50 % (если каждый элемент может равновероятно попасть в любую ячейку). Поэтому механизм разрешения коллизий — важная составляющая любой хеш-таблицы.
В некоторых специальных случаях удаётся избежать коллизий вообще. Например, если все ключи элементов известны заранее (или очень редко меняются), то для них можно найти некоторую совершенную хеш-функцию, которая распределит их по ячейкам хеш-таблицы без коллизий. Хеш-таблицы, использующие подобные хеш-функции, не нуждаются в механизме разрешения коллизий, и называются хеш-таблицами с прямой адресацией.
Число хранимых элементов, делённое на размер массива H (число возможных значений хеш-функции), называется коэффициентом заполнения хеш-таблицы (load factor) и является важным параметром, от которого зависит среднее время выполнения операций.
23
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
Свойства хеш-таблицы
Важное свойство хеш-таблиц состоит в том, что, при некоторых разумных допущениях, все три операции (поиск, вставка, удаление элементов) в среднем выполняются за время O(1). Но при этом не гарантируется, что время выполнения отдельной операции мало. Это связано с тем, что при достижении некоторого значения коэффициента заполнения необходимо осуществлять перестройку индекса хеш-таблицы: увеличить значение размера массива H и заново добавить в пустую хештаблицу все пары.
Разрешение коллизий
Несмотря на то, что два или более ключей могут хешироваться одинаково, они не могут занимать в хеш-таблице одну и ту же ячейку. Остаётся два пути: либо найти для нового ключа другую позицию в таблице, либо создать для каждого значения хешфункции отдельный список, в котором будут все ключи, отображающиеся при хешировании в это значение. Оба варианта представляют собой две классические стратегии разрешения коллизий – открытую адресацию с линейным перебором и метод цепочек.
Открытая адресация с линейным перебором
Эта методика предполагает, что каждая ячейка таблицы помечена как незанятая. Поэтому при добавлении нового ключа всегда можно определить, занята ли данная ячейка таблицы или нет. Если да, алгоритм осуществляет перебор по кругу, пока не встретится «открытый адрес» (свободное место). Отсюда и название метода. Если размер таблицы велик относительно числа хранимых там ключей, метод работает хорошо, поскольку хеш-функция будет равномерно распределять ключи по всему диапазону и число коллизий будет минимальным. По мере того как коэффициент заполнения таблицы приближается к 1, эффективность процесса заметно падает.
Метод цепочек
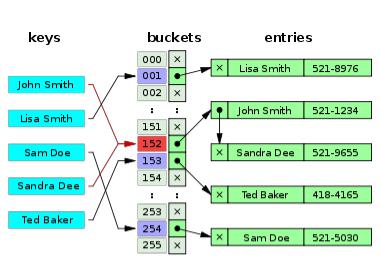
При другом подходе к хешированию таблица рассматривается как массив связанных списков или деревьев. Каждый такой список называется блоком (bucket) и содержит записи, отображаемые хеш-функцией в один и тот же табличный адрес. Эта стратегия разрешения коллизий называется методом цепочек (chaining with separate lists).
24
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
Если таблица является массивом связанных списков, то элемент данных просто вставляется в соответствующий список в качестве нового узла. Чтобы обнаружить элемент данных, нужно применить хеш-функцию для определения нужного связанного списка и выполнить там последовательный поиск.
В общем случае метод цепочек быстрее открытой адресации, так как просматривает только те ключи, которые попадают в один и тот же табличный адрес. Кроме того, открытая адресация предполагает наличие таблицы фиксированного размера, в то время как в методе цепочек элементы таблицы создаются динамически, а длина списка ограничена лишь количеством памяти. Основным недостатком метода цепочек являются дополнительные затраты памяти на поля указателей. В общем случае динамическая структура метода цепочек более предпочтительна для хеширования.
25
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
7. Быстрая сортировка Хоара
часто называемая qsort по имени реализации в стандартной библиотеке языка Си — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром в 1960 году. Один из быстрых известных универсальных алгоритмов сортировки массивов (в среднем O(n log n) обменов при упорядочении n элементов), хотя и имеющий ряд недостатков.
Краткое описание алгоритма
1)выбрать элемент, называемый опорным.
2)сравнить все остальные элементы с опорным, на основании сравнения
разбить множество на три — «меньшие опорного», «равные» и «большие»,
расположить их в порядке меньшие-равные-большие.
3)повторить рекурсивно для «меньших» и «больших».
Оценка эффективности
QuickSort является существенно улучшенным вариантом алгоритма сортировки с помощью прямого обмена (его варианты известны как «Пузырьковая сортировка» и «Шейкерная сортировка»), известного, в том числе, своей низкой эффективностью. Принципиальное отличие состоит в том, что в первую очередь меняются местами наиболее удалённые друг от друга элементы массива. Любопытный факт: улучшение самого неэффективного прямого метода сортировки дало в результате самый эффективный улучшенный метод.
1)Лучший случай. Для этого алгоритма самый лучший случай
— если в каждой итерации каждый из подмассивов делился бы на два равных по величине массива. В результате количество сравнений, делаемых быстрой сортировкой, было бы равно значению рекурсивного выражения CN = 2CN/2+N. Это дало бы наименьшее время сортировки.
2)Среднее. Даёт в среднем O(n lg n) обменов при упорядочении n элементов. В реальности именно такая ситуация обычно имеет место при случайном порядке элементов и выборе опорного элемента из середины
массива либо случайно.
На практике быстрая сортировка значительно быстрее, чем другие алгоритмы с оценкой O(n lg n), по причине того, что
26
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
внутренний цикл алгоритма может быть эффективно реализован почти на любой архитектуре. 2CN/2 покрывает расходы по сортировке двух полученных подмассивов; N — это стоимость обработки каждого элемента, используя один или другой указатель. Известно также, что примерное значение этого выражения равно CN = N lg N.
3) Худший случай. Худшим случаем, очевидно, будет такой, при котором на каждом этапе массив будет разделяться на вырожденный подмассив из одного опорного элемента и на подмассив из всех остальных элементов. Такое может произойти, если в качестве опорного на каждом этапе будет выбран элемент либо наименьший, либо наибольший из всех обрабатываемых.
Худший случай даёт O(n²) обменов, но количество обменов и, соответственно, время работы — это не самый большой его недостаток. Хуже то, что в таком случае глубина рекурсии при выполнении алгоритма достигнет n, что будет означать n-кратное сохранение адреса возврата и локальных переменных процедуры разделения массивов. Для больших значений n худший случай может привести к исчерпанию памяти во время работы алгоритма. Впрочем, на большинстве реальных данных можно найти решения, которые минимизируют вероятность того, что понадобится квадратичное время.
Достоинства
1)Один из самых быстродействующих (на практике) из алгоритмов внутренней сортировки общего назначения.
2)Прост в реализации.
3)Требует лишь O(lgn) дополнительной памяти для своей работы.
4)Хорошо сочетается с механизмами кэширования и виртуальной памяти.
5)Существует эффективная модификация (алгоритм Седжвика) для сортировки строк — сначала сравнение с опорным элементом только по нулевому символу строки, далее применение аналогичной сортировки для «большего» и «меньшего» массивов тоже по нулевому символу, и для «равного» массива по уже первому символу.
Недостатки
1)Сильно деградирует по скорости (до Θ(n2)) при неудачных выборах опорных элементов, что может случиться при неудачных входных данных. Этого можно избежать, используя такие модификации алгоритма, как Introsort, или
27
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
вероятностно, выбирая опорный элемент случайно, а не фиксированным образом.
2)Наивная реализация алгоритма может привести к ошибке переполнения стека, так как ей может потребоваться сделать O(n) вложенных рекурсивных вызовов. В улучшенных реализациях, в которых рекурсивный вызов происходит только для сортировки большей из двух частей массива, глубина рекурсии гарантированно не превысит
O(lgn).
3)Неустойчив — если требуется устойчивость, приходится расширять ключ.
8.Методы внешней сортировки
Внешняя сортировка — сортировка данных, расположенных на периферийных устройствах и не вмещающихся в оперативную память, то есть когда применить одну из внутренних сортировок невозможно. Стоит отметить, что внутренняя сортировка значительно эффективней внешней, так как на обращение к оперативной памяти затрачивается намного меньше времени, чем к магнитным дискам, лентам и т. п.
Наиболее часто внешняя сортировка используется в СУБД. Основным понятием при использовании внешней сортировки является понятие отрезка. Отрезком длины K является последовательность записей Ai, Ai + 1,…,Ai + k, что в ней все записи упорядочены по некоторому ключу. Максимальное количество отрезков в файле N (все элементы не упорядочены). Минимальное количество отрезков 1 (все элементы являются упорядоченными).
Основные методы сортировок
1)Естественная сортировка (метод естественного слияния)
2)Сортировка методом двухпутевого сбалансированного слияния
Сортировка методом n-путевого слияния.
3)Многофазная сортировка
Сортировка слиянием. Слияние означает объединение двух (или более) упорядоченных последовательностей в одну упорядоченную последовательность при помощи циклического выбора элементов, доступных в данный момент. Слияние — намного более простая операция, чем сортировка; она используется в качестве вспомогательной в более сложном
28
СТРУКТУРЫ И ОРГАНИЗАЦИЯ ДАННЫХ В ЭВМ.
процессе последовательной сортировки. Один из методов сортировки слиянием называется простым слиянием.
Метод простого слияния состоит в следующем:
1)Последовательность, а разбивается на две половины b и с.
2)Последовательности b и с сливаются при помощи объединения отдельных элементов в упорядоченные пары.
3)Полученной последовательности присваивается имя а, и повторяются шаги 1 и 2; на этот раз упорядоченные лары сливаются в упорядоченные четверки.
4)Предыдущие шаги повторяются; четверки сливаются в восьмерки, и весь процесс продолжается до тех пор, пока не будет упорядочена вся последовательность, ведь длины сливаемых последовательностей каждый раз удваиваются.
Вкачестве примера рассмотрим последовательность
44 55 12 42 94 18 06 67
На первом шаге разбиение дает последовательности
44 55 12 42
94 18 06 67
Слияние отдельных компонент (которые являются упорядоченными последовательностями длины 1) в упорядоченные пары дает
44 94 ' 18 55 ' 06 12 ' 42 67
Новое разбиение пополам и слияние упорядоченных пар дают
06 12 44 94 ' 18 42 55 67
Третье разбиение и слияние приводят, наконец, к нужному результату.
06 12 18 42 44 55 67 94.
Многофазная сортировка:
1)На первом шаге мы прочитаем S записей и отсортируем их с помощью подходящей внутренней сортировки. Этот набор уже отсортированных записей перепишем в файл А. Затем прочитаем еще S записей, отсортируем их и перепишем в файл В. Этот процесс продолжается, причем отсортированные блоки записей пишутся попеременно то в файл А, то в файл В.
2)После того, как входной файл полностью разбит на отсортированные отрезки, мы готовы перейти ко второму шагу - слиянию этих отрезков. Каждый из файлов А и В
содержит |
некоторую |
последовательность |
29