

Организация дисплейного файла
База данных и дисплейный файл
Рассмотрим место, которое занимают база данных и дисплейный файл в приложениях машинной графики (в соответствии с общей блок-схемой, приведенной на рис. 1.7).
Из материала предыдущих глав следует, что не существует особой организации базы данных, предназначенной только для машинной графики. Сам по себе факт, что база данных может содержать среди прочей информации и графические данные, недостаточен для выбора какого-либо конкретного метода управления файлами. Основную роль здесь играют скорее особенности приложений, которые связаны с машинным проектированием и в которых машинная графика применяется в качестве инструмента. Конечно, иерархическая, реляционная и теоретико-множественная модели данных, как мощные и общие методы, применимы и в этой области, тем более, что с их помощью можно реализовывать все приведенные выше структуры данных. Однако было бы ошибкой предлагать систему управления базой данных, основанную на одной из этих моделей, как стандартную систему для машинной графики.
Мощь и гибкость такой универсальной системы могут оказаться излишними и обременительными для многих приложений, потребности которых полностью удовлетворяются базами данных с более простой организацией. С другой стороны, для организации дисплейного файла можно предложить модельное решение, вытекающее из имеющейся структуры изображения. При оговоренной ранее трехуровневой структуре изображения, мы должны представить в дисплейном файле структуру данных, имеющую вид леса из трехуровневых деревьев. С функциональной точки зрения можно выделить две различные части дисплейного файла.
Первая часть состоит из списка всех команд дисплейного процессора, требуемых для генерации фактического кадра (совокупность всех объектов, изображаемых на экране).
Вторая часть структурирует список команд дисплейного процессора, разбивая его на блоки, представляющие «сегменты», «элементы» и «примитивы».
Просмотр и обработку программы дисплейного процессора нужно выполнять с максимальной скоростью, поскольку от этого зависит частота регенерации. С другой стороны поиск имени элемента и/или сегмента осуществляется, когда вывод на дисплей приостановлен. В этом случае выигрыш или потеря нескольких миллисекунд не играют существенной роли. Можно применить последовательный поиск, тем более что списки, который необходимо просматривать, можно сделать очень маленькими.
Для этого процесс поиска данных разбивается на два этапа:
на первом этапе в списке имен отыскивается имя сегмента,
а затем в найденном сегменте — имя элемента.
При этом, конечно, требуется, чтобы имена сегментов и имена элементов были соответствующим образом помечены. Реализацию этой простой, но очень эффективной схемы мы рассмотрим более подробно.
Дисплейный файл без обращения к подпрограммам
Исходя из приведенных выше соображений, сконструируем дисплейный файл в форме последовательного списка, доступ к которому осуществляется через справочник.
Этот список содержит программу для дисплейного процессора — последовательность команд дисплейного процессора. Мы назовем его списком команд дисплейного процессора. Список команд дисплейного процессора представляет собой одномерный массив длиной L, где L — суммарное число команд.
Справочник — это матрица с двумя столбцами; один столбец содержит указатели, другой — данные. Мы назовем эту матрицу корреляционной таблицей. Ее размерность равна (К, 2), где К — число сегментов + число элементов + число символов (подпрограмм). Следовательно, корреляционная таблица является двумерным массивом, содержащим два элемента для каждого графического объекта. Корреляционная таблица связана с таблицей имен (размерность К), содержащей имена сегментов, символов и элементов. Имя объекта и соответствующий ему элемент корреляционной таблицы могут быть связаны путем приписывания им одного и того же индекса в таблице имен и корреляционной таблице. Эти таблицы можно было бы объединить в один массив размерностью (К, n + 2), где n — число слов, резервируемых для имени. Однако мы рассматриваем их как два различных массива по следующим причинам.
Во-первых, типы данных, хранящихся в таблицах, могут различаться. Корреляционная таблица содержит только целые числа, в то время как таблица имен может содержать строки литер (если в качестве идентификаторов объектов вместо целых чисел можно использовать мнемонические имена).
Во-вторых, внутренним идентификатором для объекта, размещающегося в дисплейном процессоре, может быть номер соответствующего элемента (номер строки) корреляционной таблицы.
Когда создается таблица имен (путем выполнения программного блока, генерирующего сегменты), в нее сначала заносится имя сегмента, а затем имена всех элементов, принадлежащих данному сегменту. Примитивы не имеют индивидуальных имен, но их можно идентифицировать с помощью порядкового номера в соответствующем объекте. Порядок следования элементов в сегменте и примитивов в элементе соответствует тому порядку, в котором они создавались в программе на языке высокого уровня. В этом же порядке они рисуются лучом на экране ЭЛТ.
Два поля, имеющиеся в корреляционной таблице для каждого объекта, содержат в случае сегментов и символов два указателя на список команд дисплейного процессора, которые выделяют блок команд, соответствующий данному сегменту или символу. Мы назовем эти указатели указателем начала и указателем конца. Блоки соответствующие символам, отличаются от блоков, соответствующих сегментам, тем, что указатель начала сегмента представляется положительным числом, а указатель начала символа — отрицательным.
Первое из двух полей, связанных с каждым элементом, содержит указатель начала блока команд, представляющего элемент. Поскольку блоки команд элементов размещаются последовательно в блоке команд сегмента, к которому они относятся, то указатель начала некоторого элемента является одновременно указателем конца его предшественника в сегменте, и поэтому мы можем использовать вторые поля в корреляционной таблице для хранения дополнительной информации о каждом элементе. Эта информация говорит о типе элемента и представляется отрицательным целым числом: например, —1 обозначает прямые линии, —2 —точки, —3 — окружности, —4 — литеры.
Такая схема имеет несколько преимуществ:
1. Сегменты и символы могут храниться в произвольном порядке.
2. Не обязательно наличие фиксированного соответствия между числом примитивов в элементе и числом команд дисплейного процеccopa, необходимых для генерации элемента (такое фиксированное соответствие отсутствует, если в программе дисплейного процеccopa для коротких векторов используются однословные команды, а для длинных векторов — двухсловные).
• Желательно, однако, использовать «короткие векторы» только для символов. Это упрощает генерацию команд и облегчает идентификацию примитивов.
3. Поиск идентификатора сегмента, описываемый ниже, облегчается тем, что в корреляционной таблице только блок, относящийся к сегменту, содержит два положительных целых числа.
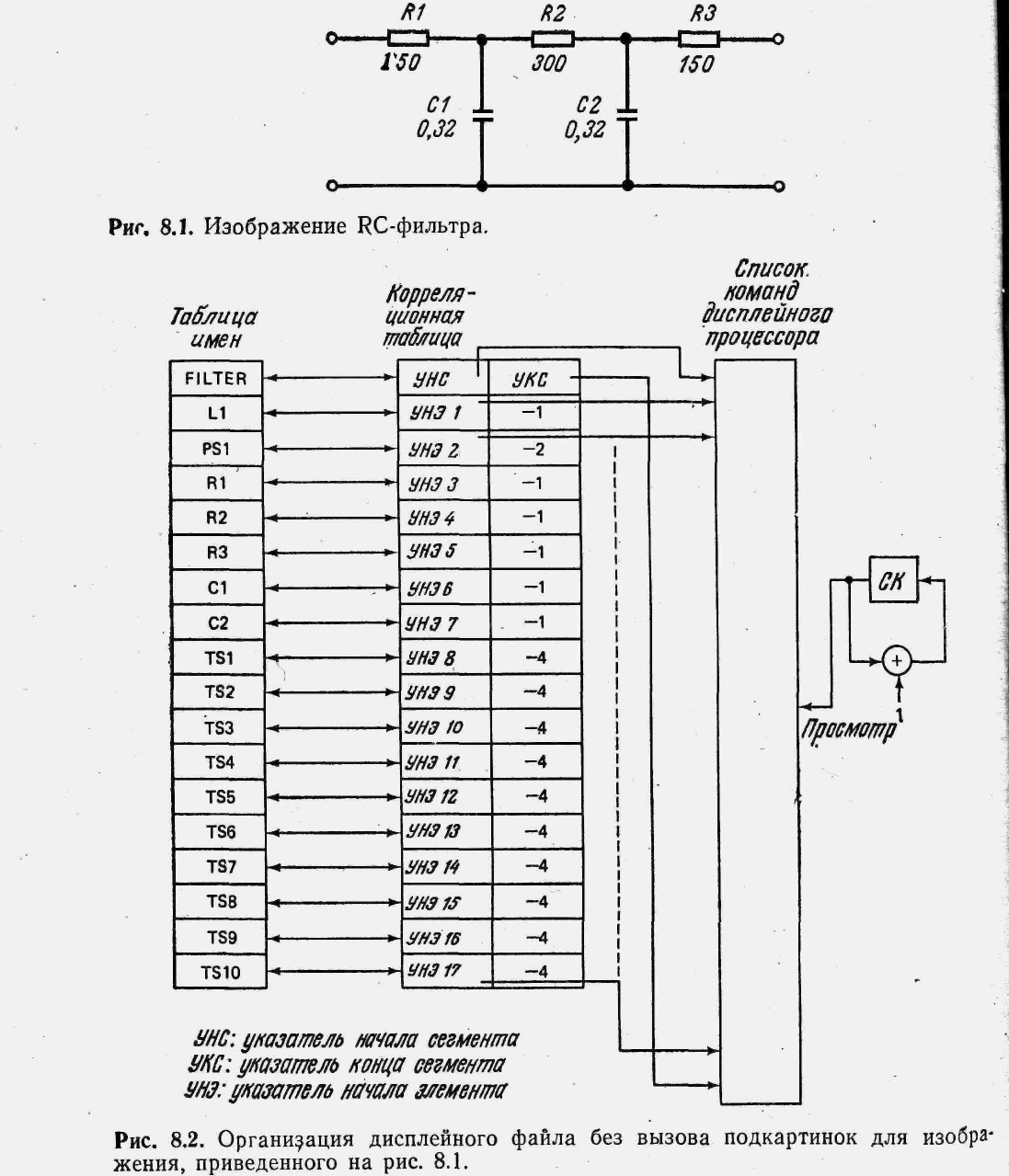
На рис. 8.1 приведен пример сегмента с именем FILTER, состоящего из 17 элементов: Rl, R2, R3, С1, С2, LI, PS1, TS1, ТS2, TS3, TS4, TS5, TS6, TS7, TS8, TS9, TS10. Rl, R2, R3, Cl, С2 — элементы типа «линия», L1 состоит из единственного примитива типа линия; PS1 — элемент типа «точка». TS1, TS2, TS3, TS4, TS5, TS7, TS8, TS9 и TS10 являются текстовыми строками.
Необходимо показать, что такая схема позволяет идентифицировать сегменты, элементы и примитивы при возникновении прерывания от светового пера. Рассмотрим кратко последовательность действий дисплейного процессора в течение цикла регенерации изображения. Во время регенерации изображения список команд дисплейного процессора последовательно просматривается от начала к концу и команды немедленно исполняются дисплейным процессором. При просмотре используется простой счетчик команд (СК), который увеличивается на 1 при каждой выборке команды из списка команд. В конце списка команд имеется команда перехода, которая заносит в СК адрес первой команды списка.
Предположим, что произошло прерывание от светового пера.
В этот момент счетчик команд «замораживается» и его текущее содержимое указывает на команду, следующую за той, которая вызвала генерацию примитива, отмеченного световым пером. Первым шагом является идентификация сегмента, к которому принадлежит отмеченный примитив. Для этого в корреляционной таблице просматриваются пары (УНС— указатель начала сегмента, УКС— указатель конца сегмента) всех сегментов и находится пара, определяющая интервал, в который попадает текущее содержимое СК.
Мы уже говорили, что пары (УНС, УКС) легко выделяются путем проверки знака УКС. Найдя такую пару, что УНС ≤ СОДЕРЖИМОЕ (СК) ≤ УКС, мы тем самым выявим искомый сегмент; он идентифицируется индексом найденной пары в корреляционной таблице. В том случае, когда пользователь хочет идентифицировать также и элемент, содержащий отмеченный примитив, система должна сравнить содержимое счетчика команд с указателями начала элементов. Если выполняется условие УНЭi ≤ СОДЕРЖИМОЕ (СК) < УНЭi+1, то примитив принадлежит i-му элементу.
Порядковый номер примитива не может быть найден простым сравнением, поскольку обычно нет фиксированного соответствия между числом примитивов в элементе и числом команд в блоке команд данного элемента. Одной из причин этого является то, что для генерации коротких векторов достаточно одной команды, в то время как для длинных векторов требуются две команды. Другая причина состоит в том, что для генерации текстовых строк требуется переменное число команд в зависимости от длины строки. Потому для идентификации примитива требуется анализировать блок команд дисплейного процессора, генерирующий соответствующий элемент.
Дисплейный файл с обращением к подпрограммам
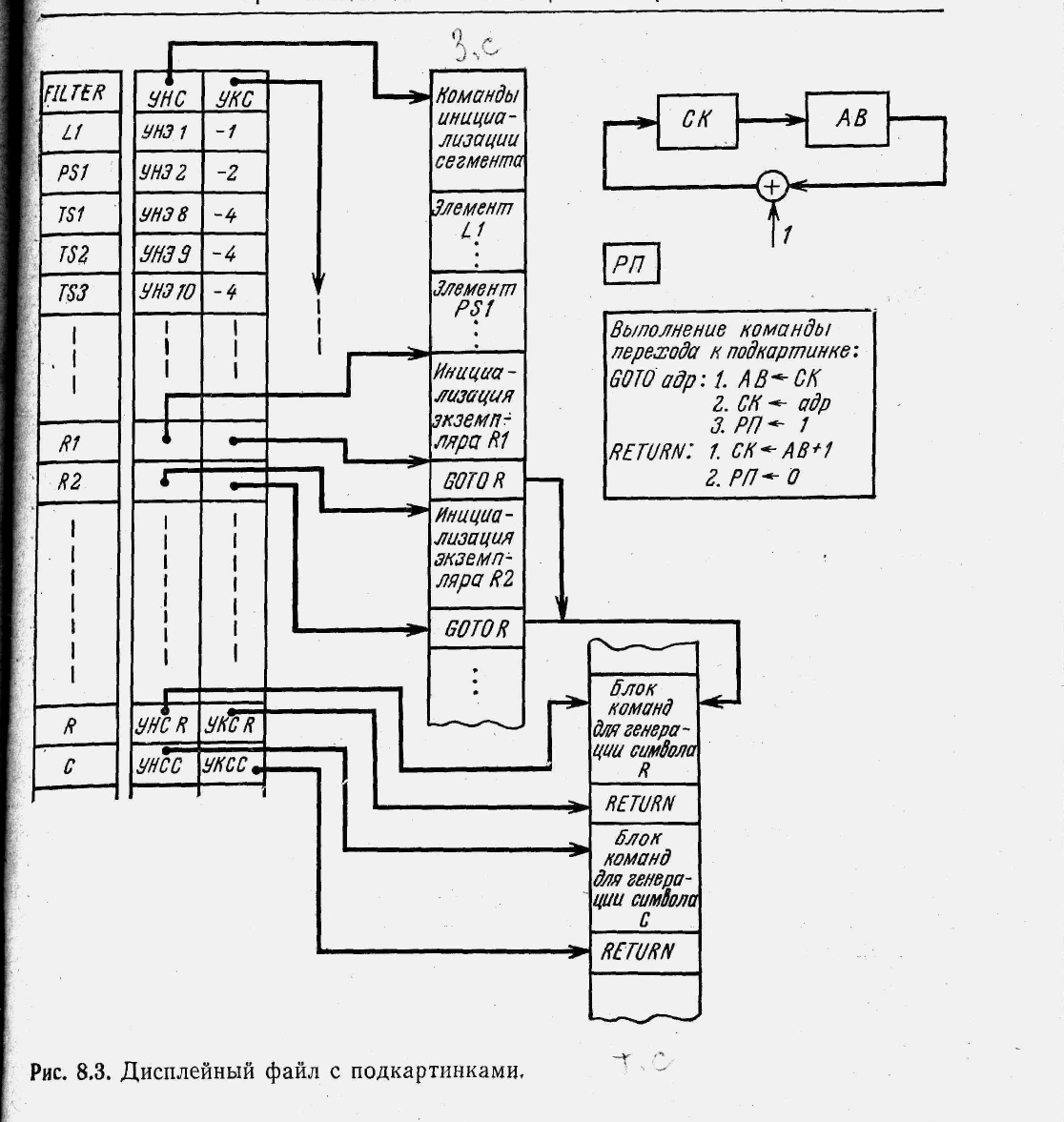
Описанный выше способ организации дисплейного файла несложно модифицировать таким образом, чтобы сделать возможным вызов символов (подкартинок). Вернемся к примеру, приведенному на рис. 8.1, но теперь предположим, что блоки команд, генерирующие резисторы и конденсаторы, хранятся в дисплейном файле в виде символов с именами R и С.
Символы отличаются от сегментов тем, что описывающие их блоки команд дисплейного процессора не содержат каких-либо команд инициализации. Назовем поэтому блок команд, описывающий символ, телом символа.
Команды для инициализации символа образуют отдельный блок, называемый заголовком символа. Тело символа может быть связано с несколькими заголовками, что приведет к появлению нескольких экземпляров символа. Тело символа имеет имя, являющееся именем символа; однако заголовки символа входят в состав блоков, откуда символ вызывается, и собственных имен не имеют. Рис. 8.3 иллюстрирует организацию дисплейного файла с подкартинками для изображения, приведенного на рис. 8.1.
Заголовок символа
Тело символа
Для того чтобы дисплейный процессор мог работать со списком команд, содержащим команды вызова подпрограмм, он снабжается специальным регистром АВ, используемым для хранения адреса возврата из подпрограммы. Когда встречается команда ПЕРЕХОД НА ПОДКАРТИНКУ, текущее содержимое счетчика команд СК запоминается в АВ, в СК заносится адрес, указанный в команде перехода, и дисплейный процессор начинает обрабатывать блок команд, на который указывает новое содержимое СК. Одновременно устанавливается регистр-признак (РП), указывающий, что процессор находится в режиме подпрограммы. Последняя команда тела символа является командой ВОЗВРАТ. Выполняя эту команду, дисплейный процессор пересылает содержимое АВ в СК и сбрасывает регистр-признак. В результате обработка команд возобновляется с того места, где встретилась команда вызова подпрограммы, а процессор возвращается в режим картинки (на что указывает РП).
Регистр-признак необходим для идентификации объекта при прерывании от светового пера. Если в момент прерывания процессор находится в режиме картинки, то идентификация осуществляется так, как было описано выше. Если процессор находится в режиме подпрограммы, то процедура не изменяется, но с указателями, хранящимися в корреляционной таблице, сравнивается содержимое АВ, а не СК. Поскольку АВ указывает на точку возврата в блок, из которого была вызвана подпрограмма, то будет идентифицирован именно этот блок, а не символ, обрабатываемый процессором в данный момент.
Можно реализовать вложенные вызовы символов (вызовы символов из символов), если превратить регистр возврата АВ в дек (очередь с двумя концами). Адреса возврата хранятся как обычно в стеке — помещаются на вершину стека при выполнении команды вызова подпрограммы и снимаются с вершины стека при выполнении команды возврата. Однако при возникновении прерывания от светового пера в процедуре идентификации объекта необходимо использовать адрес, хранящийся в самом нижнем элементе стека, поскольку именно он указывает точку возврата в сегмент, с которого началась цепочка вызовов.
стр.