

diplom25 / suslov_ibragimov_ekonometrika
.pdf42 |
Глава1.Основные понятия |
на экзаменеÈименуется мультииндексом I ( ),равным 2 4,или парой мультииндексов I , J Ñ 24, 13.Второй способ удобен,когда речь идет о группах низких порядков.В данном изложении будет использоваться первый способ индексации.
Группа I ( ) (с мультииндексом I ( ) )является объединением конечных групп
с такими значениями мультииндекса I ,что:а)все те их элементы,которые соот- |
|
ветствуют элементам,не вычеркнутыми из I ( ),совпадают с ними;б)все элемен- |
|
ты,соответствующие вычеркнутым из I ( ) элементам,пробегают все свои зна- |
|
чения.Такую операцию объединения естественно обозначить |
I5( ).Так,например, |
группа 1 4 является объединением групп 114 и 124,а группа 42 Ñобъединением групп 421, 422, 423 и 424.Если I ( ) = J ,объединяются все конечные группы и образуется исходная совокупность,а сам I ( ),равный J ,формально выступает мультииндексом всей совокупности.
Через J обозначается класс групп,образованных подмножеством признаков, не замененных в J звездочками.Так,продолжая пример,А2является классом 1 3,а Б2 Ñклассом 2 .Количество групп в J -классе K J является произведением kj cтакими j ,которые не заменены звездочками в J ;такую операцию произведения естественно обозначить 3.При J = G оно равно количеству ко-
J
нечных групп K ,а при J = J принимается равным1 (исходная совокупностьÑ одна).
Пусть NI Ñчислонаблюдений-объектоввконечнойгруппе I .Тогдачислонаблюдений в группе более низкого порядка I ( ),которое можно обозначить NI ( ), равно % NI ,где операция % выполняется аналогично операции 5 .Эти числа
I ( ) |
I ( ) |
I ( ) |
называются групповыми численностями,все они больше либо равны нулю,в случаеравенстванулюсоответствующаягруппапуста.Если I ( ) = K ,то NI ( ) = N .
Каждому наблюдению-объекту можно также поставить в соответствие муль-
тииндекс порядка n + 1,имеющий структуру I iI ,где |
I |
мультииндекс конечной |
группы,к которой принадлежит данное наблюдение,а |
iI Ñномер данного на- |
|
блюдения в этой группе.Так,в иллюстрационном примере |
3125 Ñмультииндекс |
|
пятой девушки в списке девушек третьей группы,получивших на экзаменеÇудовлетворительноÈ.Исходный линейный индекс i наблюдениясмультииндексом I iI
равен |
I− |
NI ! + iI ,где |
I− Ñзначение мультииндекса конечной группы,предше- |
|
I !% |
1 |
|
|
=I |
|
|
ствующее I в последовательности всех значений мультииндекса.Так,в примере |
|||
значение мультииндекса |
423 предшествует значению 424,а значение 314 Ñ |
||
значению 321. |
|
||
Мультииндекс,в котором (n + 1)-й элемент замещен звездочкой,обозначает все множество наблюденийгруппы.Так, 1 3 мультииндекс списка всех студентов первой группы,получивших на экзаменеÇхорошоÈ.
1.9.Статистические совокупности и группировки |
43 |
Результаты группировки применяются для решения задач3-х типов.
1)Используя информацию о групповых численностях,анализируют распреде-
ление частот или эмпирических вероятностей признаков, теоретическим обобщением которых являются функции распределения вероятностей и плотности вероятностей случайных величин.Потому такие распределения частот иногда называют эмпирическими функциями распределения вероятностей и плотностей вероятностей признаков.Если группиро вка является множественной,то говорят о совместном распределении признаков (группирующих),которое может исполь-
зоваться в анализе зависимостей между этими признаками.В таком случае группирующие признаки делятся на факторные и результирующие.Так,в иллюстрационном примере можно изучать зависимость оценки,полученной на экзамене, от факторовÇстуденческая группаÈиÇполÈ.Приемы построения эмпирических распределений вероятностей и простейшие методы анализа связейс помощью совместных распределений изучаются в этой части книги.
Прирешениизадачэтого типа группирующиепризнакиявляются,какправило, количественными.
2)Все группирующие признаки выступают факторными,и исследуется их влияние на некоторые другиеÑрезультирующие признаки xj , j > n.В этом случае группирующие(факторные)признаки являются обычно качественными,и используются методы дисперсионного анализа,элементарные сведения о котором даются в главе4этой части(более основательно эти методы рассматриваются вIII-й части книги).В иллюстрационном примере при n = 2 признакÇоценкаÈне входит в число группирующих,и если взять его в качестве результирующего,то можно также исследовать влияние факторовÇсту денческая группаÈиÇполÈна оценку. В пункте1)говорилось о других методах изучения этого влияния.
3)Анализируются зависимости между п ризнаками внутри выделенных групп и/или между группами,т.е.внутригруппо вые и/или межгрупповые связи.Во втором случае в анализе используются средние значения признаков в группах.В обоих случаях факторные и результирующие признаки не входят во множество группирующих признаков.Методы регрессионного анализа,используемые для анализа связей,и методы проверки гипотез о существенности различий параметров связей между различными группами изучаются воII-й иIII-й частях книги.В главе4 настоящей части даются общие сведения о некоторых из этих методов.
Особенностьрассмотренныхметодовгруппировкизаключаетсявтом,чтоделение на группы всякий раз проводится по значениям строго одного признака.В одну группу попадают наблюдения-объекты с близкими(илиÑдля качественных признаковÑсовпадающими)значениями признака.Каждый последующий признак лишьÇдробитÈранее выделенные группы .Между тем,существуют методы выделениягруппсразупонесколькимпризнакам.Притакихгруппировкахиспользуются
44 |
Глава1.Основные понятия |
различные меры близости векторов.Наблюдения i и i! попадают в одну группу, если по выбранной мере близки вектора xij и xi!j , j = 1, . . . , n.Методы таких группировок используются в кластерном анализе (кластерÑкласс).Существуют и обратные задачи,когда новое наблюдение-объект надо отнести к какому-то известному классу.Такие задачи решаются методами распознавания образов,они возникают,например,при машинном сканировании текстов или машинном восприятии человеческой речи.
Признаки также образуют совокупности разной степени однородности,понимаемой в этом случае только в качественном смысле.Как и в анализе совокупности объектов можно обозначить через Ij множество объектов,обладающих j -м признаком.Степень однородности совокупностей признаков тем выше,чем больше общее пресечение этих множеств для признаков,входящих в совокупность.Однородные совокупности признаков часто называютсистемами,акцентируя внимание на наличии связей между признаками совокупности.
Совокупности признаков обычно также группируются.Особенностью их группировок является то,что они имеют строго иерархический характер,т.е.последовательность групп признаков разного порядка строго определена.Когда же речь идет о группировках наблюдений-объектов,то их иерархия (последовательность групп от низших порядков к высшим)условна,она всегда может измениться при изменении порядка группирующих признаков.Группы признаков обычно называют классами и подклассами или классами разного уровня(иерархии).
На нулевом уровне иерархии признаков размещается имя всей совокупности признаков,например, Çпоказатели развития промышленных предприятийÈ.Далее следуют классы первого уровня с их именами,например, Çматериальные ресурсыÈ, ÇзатратыÈ, ÇрезультатыÈ, Çфинансовые пассивыÈ, Çфинансовые активыÈ
ит.д.Эти классы детализируются на втор ом уровне:например, Çматериальные ресурсыÈделятся наÇосновной капиталÈ, Çзапасы готовой продукцииÈ, Çпроизводственные запасыÈ, Çнезавершенное производствоÈ.На третьем уровне иерархииÇзапасы готовой продукцииÈ,например,делятся по видам продукции.И так далее.Разные направления иерархии мог ут иметь разное количество уровней детализации(иерархии).Например, Çматериальные ресурсыÈмогут иметь4уровня, аÇфинансовые активыÈ Ñ 3.В исходной матрице наблюдений только признаки низшего уровня иерархии(классов высше го порядка)имеют числовые значения (после группировки признаков и обработки матрицы наблюдений могут быть введеныстолбцысозначениямиитоговыхпоказателейпонекоторымиливсемклассам
иподклассам признаков).
Сама группировкаформально можетбытьпроведена так же,как игруппировка объектов(но с некоторыми отличиями).Разным классам одного уровня,образующим один класс предыдущего уровня, присваиваются различные целые числаранги,т.е.классыÇизмеряютсяÈв номинальной шкале.Как видно, ÇизмерениеÈ
1.10.Задачи |
45 |
классов одного уровня зависит от результатовÇизмеренияÈклассов предыдущего уровня,чего не было при группировке совокупностей объектов.Далее,в матрицу наблюдений вводятся строкиÇклассы пе рвого уровняÈ, Çклассы второго уровняÈ и т.д.с рангами,присвоенными соответст вующим классам,в столбцах признаков. И,наконец,осуществляется перестановка столбцов матрицы наблюдений по возрастанию рангов сначала классов первого уровня,потом второго уровня и т.д. Ранги классов образуют мультииндексы или коды признаков.После завершения группировки введенные строки классов можно убрать.
Обычно эти операции не проводятся,т.к.признаки группируются уже при составлении матрицы наблюдений.
Какисходныемассивыиматрицынаблюдений,такирезультатыихгруппировок или других обработок могут изображаться в виде таблиц и графиков. Таблица Ñ это визуализированный двухмерный массив с общим названием-титулом,назва- ниями строк и названиями столбцов.Первый столбец(столбцы),в котором размещены названия строк,называется подлежащим таблицы,первая строка(строки) с названиями столбцовÑ сказуемым таблицы.Подлежащее и сказуемое часто включаютмультииндексы-коды соответствующих объектов илипризнаков.В титул обычно выносится общее имя совокупности элементов(объектов или признаков) сказуемого и/или подлежащего.
Существует несколько вариантов таблиц для массивов типа {xtij },имеющих 3 размерности:время t,объекты i и признаки j .Если в подлежащемÑвремя, а в сказуемомÑобъекты,то в титул дол жно быть вынесено имя признака;если в подлежащемÑобъекты,в сказуемомÑпризнаки,то в титуле должно быть указано время и т.д.Всего таких вариантовÑ 6.
Если в табулируемой матрице не произведено группировок,то таблица является простой с простыми именами строк и столбцов.Если строки и/или столбцы сгруппированы,то их имена в таблице явля ются составными:кроме индивидуальных имен строк и столбцов они включают и имена их групп и классов.
В случае,когда столбцов таблицы не слишком много,информация может быть представлена(визуализирована) графиком.Ось абсцисс соответствует обычно подлежащему таблицы,а ось ординатÑска зуемому.Сами значения показателейпризнаков изображаются в виде различныхграфических образов,например,в виде ÇстолбиковÈ.Есливподлежащемразмещенымоменты времени,графиквыражает траектории изменения показателей.
1.10.Задачи
1.Определить пункты,которые являются выпадающими из общего ряда.
1.1а)отношений,б)порядковая,в)количественная,г)классификаций; 1.2а)Пуассон,б)Рамсей,в)Бернулли,г)Байес;
46 |
Глава1.Основные понятия |
1.3а)темпы роста,б)относительные,в)производные,г)первичные; 1.4а)Кейнс,б)Байес,в)Синклер,г)Бернулли;
1.5а)фондоемкость,б)материалоемкость,в)трудоемкость,г)срок окупаемости инвестиций;
1.6а)Стивенс,б)Кэмпбел,в)реляционная структура,г)Тарский; 1.7а)капитал,б)население,в)инвестиции,г)внешний долг; 1.8а)Пуассон,б)Рамсей,в)Бернулли,г)Байес; 1.9а)Суппес,б)Стивенс,в)Пуассон,г)Пфанцагль;
1.10а)величина-признак,б)величина-п оказатель,в)показатель-определе- ние,г)показатель-наблюдение;
1.11а)Герман,б)Кетле,в)Моргенштерн,г)Синклер; 1.12а)Тарский,б)операциональная,в)репрезентативная,г)Кэмпбел; 1.13а)Зинес,б)Суппес,в)Моргенштерн,г)Петти; 1.14а)статистика,б) statistics,в)информация,г) statistic;
1.15а)наименований,б)интервальная ,в)ординальная,г)шкалирование; 1.16а)Суппес,б)интервальная,в)Стивенс,г)порядковая; 1.17а)Бернулли,б)субъективная,в)Байес,г)объективная; 1.18а)Пфанцагль,б)Зинес,в)Нейман,г)Кэмпбел;
1.19а)управляемый эксперимент,б)пассивное наблюдение,в)статистика, г)операциональное определение;
1.20а)Кетле,б)Кейнс,в)Петти,г)Герман;
1.21а)производственные мощности,б)выпуск продукции,в)затраты, г)амортизационные отчисления;
1.22а)Пуассон,б)Рамсей,в)Бернулли,г)Байес; 1.23а)кластер,б)класс,в)группа,г)совокупность; 1.24а)абсолютная,б)относительная,в)экстенсивная,г)интенсивная; 1.25а)дискретный,б)непрерывный,в)моментный,г)интервальный; 1.26а)подлежащее,б)предло г,в)сказуемое,г)таблица.
2.Какой типÑзапаса или потокаÑимеют следующие величины:а)инвестиции;б)население;в)основные фонды;г)активы?
3.К какому классу относятся и какую размерность имеют следующие интенсивные величины:а)фондоемкость;б)материалоемкость;в)трудоемкость; г)фондоотдача?
1.10.Задачи |
47 |
Таблица1.2
|
Объем |
Абсолютный |
|
Темп |
Абсолютное |
|
|
Темп роста |
значение |
||||
Год |
производства, |
прирост, |
прироста |
|||
(годовой) |
1% прироста, |
|||||
|
млрд. руб. |
млрд. |
(годовой), % |
|||
|
|
|
|
|
млрд. |
|
|
|
|
|
|
|
|
1 |
2 |
3 |
4 |
5 |
6 |
|
|
|
|
|
|
|
|
1992 |
127 |
|
|
|
|
|
|
|
|
|
|
|
|
1993 |
|
|
1.102 |
|
|
|
|
|
|
|
|
|
|
1994 |
|
|
|
7.1 |
|
|
|
|
|
|
|
|
|
1995 |
164.6 |
|
|
|
|
|
|
|
|
|
|
|
|
1996 |
|
|
|
|
|
|
|
|
|
|
|
|
|
1997 |
|
|
|
9.9 |
1.75 |
|
|
|
|
|
|
|
4.Пусть yt Ñзначение величины в момент времени t.Запишите формулу моментного темпа прироста и непрерывного темпа роста.
5.Имеются данные об объеме производства в отрасли(табл. 1.2). Вычислить и вставить в таблицу недостающие показатели.
6.Была проведена группировка студентов НГУ по трем признакам: 1-й признак:место постоянного жительства(город;село);
2-й признак:средний балл в аттестате(выше 4.5;от 3.5 до 4.5;ниже 3.5);
3-й признак:средний балл за в ступительные экзамены(выше 4.5;от 3.5 до 4.5;ниже 3.5).
Определите:
а)общее число групп и число групп высшего порядка; б)количество классов групп1-го, 2-го и3-го порядка;
в)количество групп в классах 2, 13, |
23; |
г)число конечных групп в каждой группе класса 2, 13, 23. |
|
д)Число элементов конечной группы |
221 равно 5,в остальных конечных |
группах по 2 элемента.Каково значение линейного индекса второго элемента конечной группы 232?
е)Сколько всего элементов в совокупности?

Глава2
Описательная статистика
Исходныймассивнаблюденийможетдостигатьзначительныхразмеров,инепосредственно по его информации трудно делать какие-либо содержательные заключения о свойствах изучаемых совокупностей.Задача описательной статистикиÑ ÇсжатьÈисходныймассив,представить его небольшимнаборомчисловых характеристик,которые концентрированно выражают свойства изучаемых совокупностей. Граница между описательной статистикой,с одной стороны,и математической статистикой,эконометрией,анализом данных,с другой стороны,достаточно расплывчата.Обычновописательнойстатистикедаютсяэлементарныесведения,достаточные для проведения начальных этапов экономико-статистического исследования, которые более углубленно и более строго рассматриваются в других научных дисциплинах статистического ряда(в последующих разделах книги).
2.1.Распределение частот количественного признака
Пусть имеются наблюдения xi , i = 1, . . . , N за некоторой непрерывной количественной величиной-признаком,т.е.матрица наблюдений имеет размерность N × 1.Такую матрицу наблюдений обычно называют рядом наблюдений.В статистике совокупность этих значений иногда называется также вариационным рядом.Пусть проведена группировка совокупности по этому признаку с выделением k групп.Всоответствиисобозначениямипредыдущейглавымультииндексомгруппы является I ,равный i1,где i1 Ñиндекс группы.В этом и ряде последующих

2.1.Распределение частот количественного признака |
49 |
пунктов(при n = 1)в качестве индекса гру ппы будет использоваться не i1,чтобы не путать его с линейным индексом i наблюдения,а l.Соответственно, zl , l = 0, 1, . . . , k Ñ границы полуинтервалов, Nl Ñгрупповые численности,которые в этом случае называютчастотами признака.Следуетиметь в виду,что x Ñ случайная величина,но все z Ñдетерминированы.
Размеры полуинтервалов,
l = zl − zl−1,
обычно берут одинаковыми.При выборе размера полуинтервалов можно использовать одно из следующих правил:
=3 .5sN −1/3 (правило Скотта)
или
=2 I QR N −1/3 (правило ФридменаÑДиакониса),
где s Ñсреднеквадратическое отклонение, I QR = x0.75 −x0.25 Ñмежквартильное расстояние(определение величин s, x0.25 и x0.75 дается ниже).В литературе также часто встречается правило Стёрджесса для количества групп:
k = 1 + log2 N ≈ 1 + 1.44 ln N,
однако было показано,что оно некорректно,поэтому использовать его не рекомендуется.В качестве значения признака на l-м полуинтервале можно принять среднее значение признака на этом полуинтервале:
xøl = |
1 |
!xl |
Nl |
(использовано введенное в предыдущей главе обозначение xl попавших в l-ю группу).Однако,как правило,в качестве этого мается середина полуинтервала:
всех наблюдений, значения прини-
xø |
|
= |
|
1 |
(z + z |
) = z |
l−1 |
+ |
l |
, |
||||
|
2 |
2 |
||||||||||||
|
l |
|
|
l |
l−1 |
|
|
|
|
|
||||
α = |
Nl |
, |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
||||||
|
l |
|
|
N |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|||
Ñ относительные частоты |
признака или оценки вероятностей (эмпиричес- |
|||||||||||||
кие вероятности)попадания значений признака в |
l-й полуинтервал,то есть |
|||||||||||||
α1 = P (z0 ! x ! z1), αl = P (zl−1 < x ! zl ) , l = 2, . . . , k. |
||||||||||||||
|
|
|
|
|
|
fl |
= |
|
αl |
|
|
(2.1) |
||
|
|
|
|
|
|
|
|
|
|
|
||||
l
Ñ плотности относительной частоты или оценки плотности вероятности.
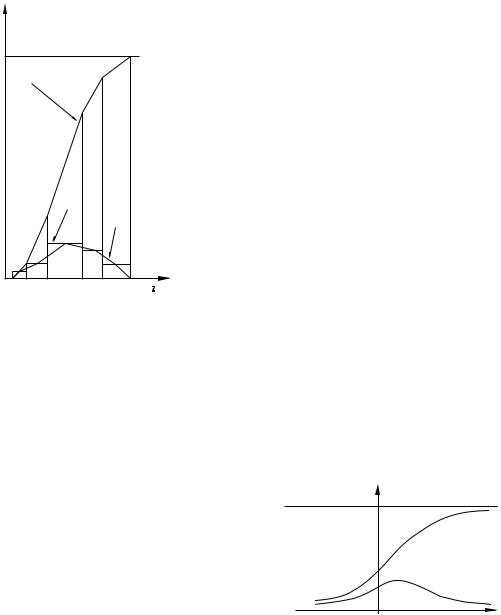
50 |
f, F |
1 |
кумулята |
гистограмма |
полигон |
Рис. 2.1.Графическое изображение |
плотностей частоты |
Глава2.Описательная статистика
Очевидно,что |
|
!fl |
|
|
|
|
Далее: |
!αl = 1, или |
l |
= 1. |
(2.2) |
||
|
|
|
|
|
|
|
|
l |
|
l |
|
|
|
Fl = |
!! |
|
l!! |
|
|
|
αl! |
, или Fl = |
fl! |
l!, |
(2.3) |
||
|
l =1 |
|
=1 |
|
|
|
Ñ накопленные относительные частоты или оценки вероятностей того,что значение признака не превысит zl ,т.е. Fl = P (x ! zl ).
Крайние значения этих величин равны 0 и 1:
F0 = 0, Fk = 1.
Числа αl , fl , Fl (l = 1, . . . , k) характеризуют разные аспекты распределения частот количе-
ственного признака.Понятно,что,если размеры полуинтервалов одинаковы, αl и fl различаются с точностью до общей нормировки и являются одинаковыми характеристиками распределения.
Графическоеизображениеплотностейчастотыназываетсягистограммой,анакопленных частотÑ кумулятой.Поскольку плотности частот неизменны на каждом полуинтервале,гистограмма ступенчатая функция(точнее,график ступенчатой функции).Накопленные частоты линейно растут на каждом полуинтервале, поэтому кумулятаÑкусочно-линейная функция.Вид этих графиков приведен на рисунке2.1.
Еще один графический образ плотностей
частоты называется полигоном.Этот график |
1 |
|
образован отрезками,соединяющими середи- |
||
|
||
ны ступенек гистограммы.При этом первый |
F |
|
отрезок соединяет середину первой ступень- |
|
|
ки с точкой z0 оси абсцисс,последний от- |
|
|
резокÑсередину последней ступеньки с точ- |
|
|
кой zk . |
f |
|
|
Теоретически можно представить ситуацию,когда N и k → ∞,при этом следует допустить,что z0 → −∞, а zk → +∞.В ре-
зультате функции f (z) и F (z),графиками которых были гистограмма и кумулята, станут гладкими(рис. 2.2).В математической статистике их называют,соответ-
ственно, функцией плотности распределения вероятности и функцией распре-
деления вероятностей случайной величины(см.ПриложениеA.3.1).
2.1.Распределение частот количественного признака |
|
51 |
||||
Формулы(2.1Ð2.3)преобразуются,соответственно,в |
|
|
|
|||
|
|
|
+∞ |
z |
|
|
|
|
= f (z) , |
- f (z) dz = 1, F (z) = |
- |
f z! |
dz!. |
|
dz |
|||||
|
dF (z) |
|
−∞ |
−∞ |
0 |
1 |
|
|
|
|
|
|
|
Обычно функции f и F записываются с аргументом,обозначенным символом случайной величины: f (x) и F (x).При этом предполагается,что в такой записи x есть детерминированныйÇобразÈсоответствующей случайной величины(в математической статистике для этого часто используют соответствующие прописные символы: f (X ) и F (X )).Такие функции являются теоретическими и выражают различные законы распределения,к которым лишь приближаются эмпирические распределения.
0
Рис. 2.3
Наиболее распространенным в природе является так называемый закон нормального распределения,плотность которого в простейшем случае(при нулевом математическом ожидании и единичной дисперсии)описывается следующей функцией:
|
|
|
|
|
|
|
1 |
|
x2 |
|||
|
|
|
|
|
|
f (x) = |
√ |
|
e− |
2 |
|
|
|
|
|
|
|
|
2π |
||||||
|
|
|
|
|
|
|
|
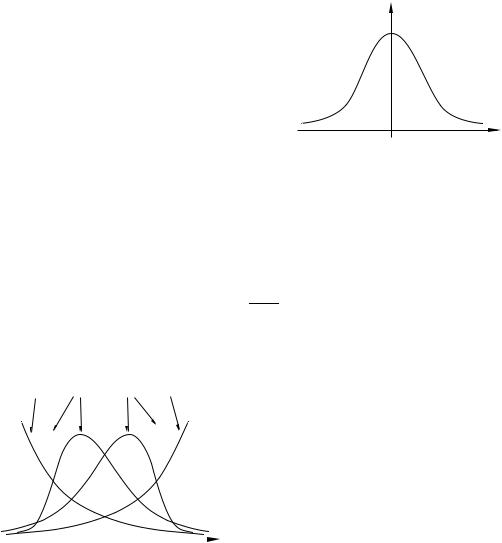
Ее график,часто называемый кривой |
||||
|
|
асимметрия |
|
Гаусса,изображен на рисунке2.3. |
||||||||
идеальная правая |
левая |
идеальная |
|
Наиболее вероятное значение величи- |
||||||||
|
|
|
|
|
|
|
ны,имеющейтакоераспределение, Ñнуль. |
|||||
|
|
|
|
|
|
|
Распределение ее симметрично,и вероят- |
|||||
|
|
|
|
|
|
|
ность быстро падает по мере увеличения ее |
|||||
|
|
|
|
|
|
|
абсолютной величины.Обычно такое рас- |
|||||
|
|
|
|
|
|
|
пределение имеют случайные ошибки изме- |
|||||
|
|
|
|
|
|
|
рения(при разной дисперсии). |
|||||
|
|
|
|
|
|
|
|
Различаютнесколькотипов распределе- |
||||
|
|
|
|
|
|
|
ний признака(случайной величины). |
|||||
|
|
|
|
Рис. 2.4 |
|
|
На рисунке2.4показаны асимметрич- |
|||||
|
|
|
|
|
ные или скошенные распределения:с пра- |
|||||||
|
|
|
|
|
|
|
||||||
вой и левой асимметрией,идеальная правая иидеальная левая асимметрия.При правой(левой)асимметрии распределение скошено в сторону больших(меньших)