

учебник информатика
.pdfГлава 1. Общие сведения об информационных процессах
Вто же время, подобно двоичным файлам, кодировка Unicode мало подходит для непосредственной передачи по сети – байты в тексте вполне могут приходиться на область управляющих символов, поэтому обычно применяются две другие основанные на Unicode кодировки переменной длины, обозначаемые как UTF (Unicode Transformation Format): 7-
битная UTF-7 (последний пересмотр – RFC2152, 1997 г., зарегистрирована
вIANA как UTF-7) и 8-битная UTF-8 (RFC2279, 1998 г., зарегистрирована
вIANA как UTF-8). Обе они в каком-то смысле уже не являются языковыми кодировками, а являются программно распознаваемым кодом относительно исходного Unicode, но зарегистрированы они именно как кодировки, наравне с ISO 8859-5 или KOI8-R. Естественно, обе они не являются специфически «русскими», а пригодны для написания «сколько угодно»- язычного письма.
ВUTF-8 все символы разделены на несколько групп по значению
первых битов. Символы с кодами менее 12810 кодируются одним байтом, первый битом которого равен нулю, а последующие 7 бит в точности соответствуют 128 символам 7-й таблицы ASCII (см. таблицу 1.2), следующие
1920 символов – двумя байтами (Greek, Cyrillic, Coptic, Armenian, Hebrew и Arabic символы). Последующие символы кодируются тремя и четырьмя байтами.
Таблица 1.2. Принцип кодирования символов в UTF-8
Диапазон |
UTF-8 |
|
|
|
|
|
кодов |
|
Notes |
|
|||
(binary) |
|
|
||||
(hexadecimal) |
|
|
|
|
||
|
|
|
|
|
||
|
|
|
||||
000000 - 00007F |
0xxxxxxx |
Первый бит 0, следующие 7 со- |
||||
ответствуют таблице ASCII |
||||||
|
|
|||||
|
|
|
||||
|
|
Первые 3 бита 110 – всего ис- |
||||
000080 - 0007FF |
110xxxxx 10xxxxxx |
пользуется 2 байта, второй байт |
||||
|
|
начинается с 10 |
|
|||
|
1110xxxx 10xxxxxx |
Первые 4 бита 1110 – всего ис- |
||||
000800 - 00FFFF |
пользуется |
3 |
байта, второй и |
|||
10xxxxxx |
||||||
|
третий байты начинаются с 10 |
|||||
|
|
|||||
|
|
|
||||
|
|
Первые 5 бит 11110 – всего ис- |
||||
010000 - 10FFFF |
11110xxx 10xxxxxx |
пользуется |
4 |
байта, |
второй, |
|
10xxxxxx 10xxxxxx |
третий и |
четвертый |
байты |
|||
|
||||||
|
|
начинаются с 10 |
|
|||
|
|
|
|
|
|
|
21

1.2 Кодирование информации
Особняком стоит 7-битная, русская кодировка – транслитерация, или транскириллица, когда русские буквы передаются похожими по зву-
чанию английскими primerno takim obrazom.
В конце 1997 г. Microsoft подвергла ревизии свои |
|
|
кодовые таблицы и включила в них новый символ евро- |
|
|
валюты "Евро" (рисунок 1.11), он помещен в позицию |
Рисунок 1.11. |
|
128 (0x80) большинства таблиц и в позицию 136 (0x88) |
||
Символ "Евро" |
||
русской таблицы CP1251. |
||
|
Таким образом, в настоящее время при работе в Интернете Вы можете встретить следующие кодировки для кириллицы:
CP1251 – Cyrillic Windows – операционной системы Microsoft Windows;
CP866 – Cyrillic DOS – операционной системы MS DOS;
ISO 8859-5 – Cyrillic ISO – 8-ми битная таблица ASCII ;
KOI8-R – операционной системы Linux;
CP10007 – операционной системы компьютеров Macintosh;
UTF-8 – универсальная Unicode кодировка переменной длины.
1.2.2 Кодирование числовой информации
Числовая информация, как и любая другая, хранится и обрабатывается в компьютерах в двоичной системе счисления – числа представляются в виде последовательностей нулей и единиц.
Существуют два вида чисел и два способа их представления: форма с фиксированной точкой и форма с плавающей точкой. Форма с фиксированной точкой применяется для целых чисел, форма с плавающей точкой – для вещественных (действительных) чисел.
Как это ни странно, не все студенты 1 курса вуза могут ответить на вопрос, что такое действительные или вещественные числа. Это рациональные и иррациональные числа, у которых может быть как целая, так и дробная часть, записываемая справа от разделителя целой и дробной части. Как разделитель при работе на компьютере раньше всегда использовалась точка, но в современных системах разделитель – точка или запятая – может настраиваться в соответствии со стандартами страны пользователя или с его привычками.
ЭВМ оперирует с числами, содержащими конечное число двоичных цифр (разрядов). Количество разрядов ограничено длиной разрядной сетки машины. Под разрядной сеткой понимается совокупность двоичных разря-
22

Глава 1. Общие сведения об информационных процессах
дов, предназначенных для хранения и обработки машинных слов (двоичных кодов).
Количество двоичных разрядов и положение запятой в разрядной сетке машины определяют такие важные характеристики ЭВМ, как точность и диапазон представляемых чисел.
Кроме бита и байта, для указания длины формата чисел используется машинное слово, полуслово и двойное слово. Двойное слово и полуслово по-разному определяются для разных систем ЭВМ. Кроме того, может использоваться понятие тетрада – 4 двоичных разряда, которыми может кодироваться, например, одна двоичная цифра.
Двоичные разряды в форматах формируются слева направо (начиная с нулевого разряда).
Кодирование целых чисел
Целые числа в компьютере хранятся в памяти в формате с фиксированной запятой. В этом случае каждому разряду разрядной сетки соответствует всегда один и тот же разряд числа.
Целые числа без знака (положительные) – для их хранения может отводиться последовательность из 8, 16 или 32-х бит памяти. Например, максимальное 8-битное число A2 = 111111112 будет храниться следующим образом (прямой код):
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
Максимальное значение целого неотрицательного числа достигается в случае, когда во всех ячейках хранятся единицы и равно 2N-1, где N – разрядность числа.
Для 8-разрядных целых положительных чисел оно будет равно 28 - 1 = 255, для 16-разрядных 216 - 1 = 65 535, для 32-разрядных 232 - 1 = 4 294 967 295.
Целые числа со знаком (могут быть положительные и отрицательные) – при их хранении используется последовательность из 8, 16 или 32-х бит памяти, причем старший бит (первый слева) обозначает знак числа – 0 - положительное, 1 – отрицательное. При записи чисел используется не прямой, а дополнительный код двоичного числа равный 2N – A, где N – разрядность числа, A – прямой код двоичного числа.
Дополнительным называется код, в котором для положительного числа в знаковом разряде пишется "0", в цифровых – модуль числа, а для отрицательного в знаковом разряде пишется "1", в цифровых – дополнение числа до единицы (инвертирование цифр).
23

1.2 Кодирование информации
Например, число -1 в 8-разрядном двоичном коде выглядит, как
11111111, -2 – как 11111110 и т. д.
Дополнительный код позволяет заменить арифметическую операцию вычитания операцией сложения, что исключает операцию вычитания их набора команд двоичной арифметики процессора.
Таким образом, при использовании 8-ми разрядов для хранения целых чисел со знаком диапазон их изменения составит от – 128 до 127, если использовать 16 разрядов – от -32 768 до 32 767, 32 разряда – от -2 147 483 648 до 2 147 483 647, что следует учитывать при работе с целыми типами данных при программировании и работе с базами данных.
Кодирование вещественных чисел
Для того чтобы представить действительное число X в виде набора целых чисел (двоичных – для представления в компьютерной памяти), его необходимо привести к нормализованной форме:
X = M · NP;
где M – мантисса (дробная часть), N – основание системы счисления, а P – порядок числа.
Для десятичной системы счисления нормальная форма X = M · 10P, для двоичной X = M · 2P.
Например, число 22.2210 в таком виде будет выглядеть, как +0,2222·102 (при записи чисел в памяти ЭВМ ноль и запятая отсутствуют).
Таким образом, действительные число на компьютерах хранится в двоичной системе счисления в виде:
S |
P |
M |
|
|
|
где S – признак знака числа.
Поскольку размер памяти, отводимый под мантиссу и порядок, ограничен, то действительные числа представляются с некоторой погрешностью, определяемой количеством разрядов в мантиссе числа, и имеют определенный диапазон изменения, определяемый количеством разрядов в порядке числа.
Конкретные характеристики различных типов вещественных типов данных для ПК определены в стандарте IEEE-754-1985 (Institute of Electrical and Electronic Engineers - http://www.ieee.org/), согласно которому ис-
пользуются 3 основных формы (см. табл. 1.3).
Особенности арифметики для чисел с плавающей точкой могут существенно влиять на результаты расчётов, вплоть до того, что погреш-
24

Глава 1. Общие сведения об информационных процессах
ность может сделать невозможным получение какого-либо результата вообще, поэтому знание деталей представления в памяти таких чисел и реализации арифметики вещественных чисел является необходимым для программистов.
Таблица 1.3. Данные с плавающей точкой по стандарту IEEE-754-1985
|
|
Диапазон изменения |
Точность, |
|
||
Тип |
Размер, |
чисел |
количество |
Машинное |
||
бит |
максимум |
минимум |
цифр |
|
||
|
||||||
|
|
в числе |
|
|||
|
|
|
|
|
||
single |
32 |
3.4·10-38 |
3.4·1038 |
6 |
1,192·10-7 |
|
double |
64 |
1.7·10-308 |
1.7·10308 |
15 |
2,221·10-16 |
|
long double |
80 |
3.4·10-4932 |
3.4·104932 |
19 |
1,084·10-19 |
|
1.2.3 Кодирование изображений
Изображение – некоторая двумерную область, свойства каждой точки (pixel, пиксель) которой могут быть описаны (координаты, цвет, прозрачность…).
Множество точек называется растром (bit map, dot matrix, raster)
(см. рис. 1.12), а изображение, которое формируется на основе растра, называются растровым. На экране монитора всегда формируется растровое изображение, однако, для хранения может использоваться и векторное представление информация, где изображение представлено в виде набора графических объектов с их координатами и свойствами (линия, овал, прямоугольник, текст и т. п.).
Рис. 1.12. Растровое изображение на экране монитора
25

1.2 Кодирование информации
На мониторе и в растровых изображениях число пикселей по горизонтали и по вертикали называют разрешением (resolution). Наиболее ча-
сто используются 1024×768 или 1280×800, 1280×1024 (для 15, 17 19 ),
720×576 (качество обычных DVD-фильмов), 1920×1080 и 1920×720 (телевидение высокой четкости HDTV – стандарты 1080i и 720p). Каждый пиксель изображения нумеруется, начиная с нуля слева направо и сверху вниз.
Для представления цвета используются цветовые модели. Цветовая модель (color model) – это правило, по которому может быть определен цвет. Самая простая двухцветная модель – битовая. В ней для описания цвета каждого пикселя (чёрного или белого) используется всего один бит.
Для представления полноцветных изображений используются несколько более сложных моделей. Известно, что любой цвет может быть представлен как сумма трёх основных цветов: красного, зелёного и синего. Если интенсивность каждого цвета представить числом, то любой цвет будет выражаться через набор из трёх чисел. Так определяется наиболее известная цветовая RGB-модель (Red-Green-Blue). На каждое число отводится один байт. Так можно представить 224 цвета, то есть примерно 16,7 млн. цветов. Белый цвет в этой модели представляется как (1,1,1), чёрный – (0,0,0), красный (1,0,0), синий (0,0,1). Жёлтый цвет является комбинацией красного и зелёного и потому представляется как (1,1,0).
Цветовая модель RGB была стандартизирована в 1931 г. и впервые использована в цветном телевидении. Модель RGB является аддитивной моделью, то есть цвет получается в результате сложения базовых цветов. Существуют и другие цветовые модели, которые для ряда задач оказываются более предпочтительными, чем RGB-модель. Например, для представления цвета в принтерах используется субтрактивная CMYK-модель (Cyan-Magenta-Yellow-blacK), цвет в которой получается в результате вычитания базовых цветов из белого цвета. Белому цвету в этой модели соответствует (0,0,0,0), чёрному - (0,0,0,1), голубому - (1,0,0,0), сиреневому - (0,1,0,0), жёлтому - (0,0,1,0). В цветовой модели HSV (Hue-Saturation- Value) цвет представляется через цвет, насыщенность и значение, а в модели HLS (Hue-Lightness-Saturation) через оттенок, яркость и насыщенность. Современные графические редакторы, как правило, могут работать с несколькими цветовыми моделями.
Кроме растрового изображения на экране монитора существуют графические форматы файлов, сохраняющие растровую или векторную графическую информацию. С такой информацией работают специальные программы, которые преобразуют векторные изображения в растровые, отображаемые на мониторе.
26
Глава 1. Общие сведения об информационных процессах
1.2.4 Кодирование звуковой информации
Звук можно описать в виде совокупности синусоидальных волн определённых частоты и амплитуды. Частота волны определяет высоту звукового тона, амплитуда – громкость звука. Частота измеряется в герцах (Гц, Hz). Диапазон слышимости для человека составляет от 20 Гц до 17000 Гц (или 17 кГц).
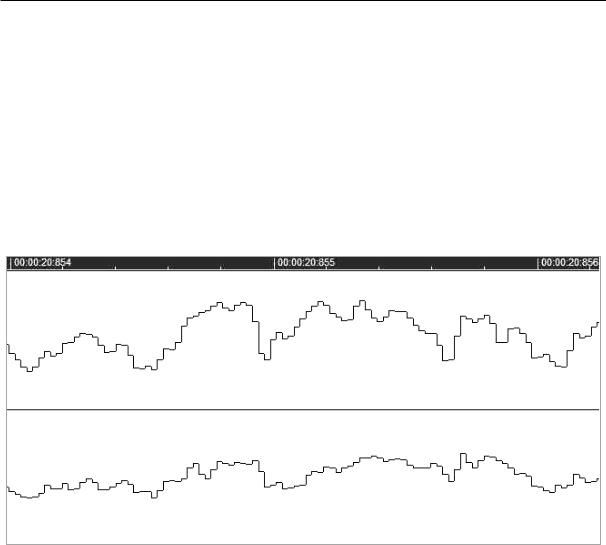
Задача цифрового представления звука сводится измерению интенсивности звука через заданный интервал времени (например, 48 раз за 0,001 секунды). Принцип такого представления изображён на рис. 1.13.
Рис. 1.13 Диаграмма стереозвука в музыкальном редакторе (верхняя ось – время ~ от 20,854 до 20,856 сек., т. е. 0,002 сек.)
Каждому измерению присваивается числовое значение амплитуды. Количество измерений в секунду называется частотой выборки (sampling rate). Количество возможных значений амплитуды называется точностью выборки (sampling size). Таким образом, звуковая волна представляется в виде ступенчатой кривой. Ширина ступеньки тем меньше, чем больше частота выборки, а высота ступеньки тем меньше, чем больше точность выборки.
Возможности наиболее распространённой современной аппаратуры предусматривают работу с частотой выборки до 48 кГц (48 тысяч раз в секунду!), что позволяет правильно описывать звук частотой до 22,05 кГц.
Непрерывная звуковая волна разбивается на отдельные участки по времени, для каждого устанавливается своя величина амплитуды. Каждой
27

1.2 Кодирование информации
ступеньке присваивается свой уровень громкости звука, который можно рассматривать как набор возможных состояний.
Характеристики качества звука
1)Точность выборки или глубина кодирования звука – количество бит на одно измерение величины звукового сигнала.
Современные звуковые карты обеспечивают 16-битную глубину кодирования звука. Количество уровней (градаций амплитуды) можно рассчитать по формуле:
N = 2I = 216 = 65 536 уровней сигнала (градаций амплитуды)
2)Частота выборки или частота дискретизации – это количе-
ство измерений уровня звукового сигнала за 1 секунду.
Одно измерение в 1 секунду соответствует частоте 1 Гц. 1000 измерений в 1 секунду - 1 кГц.
Количество измерений может лежать в диапазоне от 8000 до 48 000
(8 кГц – 48 кГц).
8 кГц соответствует частоте радиотрансляции,
48 кГц – качеству звучания аудио-CD.
Опыт показывает, что точное соответствие цифрового сигнала аналоговому достигается, если частота дискретизации будет вдвое выше максимальной звуковой частоты, то есть составит не менее 40 кГц.
На практике значения частоты дискретизации, применяемые в звуковых системах, равны 44,1 кГц или 48 кГц.
Чем больше частота дискретизации, тем качественнее звук.
3)Для характеристики сжатого звука и видео используется понятие битрейт – количество единиц информации, необходимых для хранения или передачи одной секунды потока данных. Величина измеряется в килобитах в секунду (kbps). Битрейт характеризует как плотность упаковки информации, так и её качество. Например, из двух MP3 файлов сжатых с разным битрейтом, более качественный (близкий к оригиналу) звук будет у файла с большим битрейтом. В тоже время, файл другого формата, при равном битрейте, может дать как лучшее, так и худшее качество звука. Стандартов кодирования двухканальной и многоканальной (5.1 и 7.1) аудиоинформации насчитывается несколько десятков, наименования некоторых из них, используемых в современных методах записи мультимедиаинформации, приведены далее в таблице 1.4.
28

Глава 1. Общие сведения об информационных процессах
1.2.5Кодирование видеоинформации
Видеоинформация – наиболее сложный вид для хранения, обработки
ивоспроизведения. Впервые движущиеся изображения были сохранены на кинопленке в виде большого количества отдельных кадров изображения, заснятых через небольшие промежутки времени (24 кадра в секунду). Позднее на ту же пленку стала записываться и звуковая дорожка (в последующем несколько дорожек для многоканального звука). Далее появилось телевидение с аналоговой записью движущегося изображения на магнитные ленты (системы телевидения PAL и SECAM используют 25 кадров в секунду, система NTSC – 29,97 кадров в секунду). С появлением компьютеров широкое распространение получили цифровые методы записи и кодирования видеоинформации, которые постоянно совершенствуются. В настоящее время каждый может записать видео с использованием мобильных телефонов, цифровых фото- и видеокамер и выполнить монтаж видеофильма на персональных компьютерах, производительности которых достаточно для перекодирования видео высокого разрешения объемом в несколько гигабайт (но продолжительность кодирования может составлять несколько часов).
Компьютерные цифровые методы кодирования видео могут использовать частоту телевизионных стандартов PAL/SECAM или NTSC, т. к. видеозаписи многих цифровых форматов могут воспроизводиться как специальными компьютерными программами, так и бытовыми DVDплеерами, а также путем подключения телевизора к компьютеру (для передачи видео и звука следует использовать порт HDMI).
Качество видеоизображения в цифровых методах постоянно улучшается. Широкое распространение цифрового видео было связано с появление вначале CD-дисков, затем DVD, далее Blu-Ray дисков, на которых, в основном, и распространялись кинофильмы, и емкостью которых ограничивались качественные возможности. В таблице 1.4 приведены характеристики некоторых видеоформатов.
Стандарты кодирования видео разрабатываются группой экспертов в области цифрового видео MPEG (Moving Picture Experts Group) Международной Организацией по Стандартизации (ISO). Первый стандарт MPEG-1 был представлен в 1992 г., последние стандарты в этой области – MPEG-7
иMPEG-21.
Алгоритмы кодирования видео очень сложны, их описания можно найти в специальной литературе или на сайте http://www.mpeg.org.
29

1.2 Кодирование информации
Таблица 1.4. Сравнение форматов записи видео на диски
Формат |
Разрешение, |
Стандарт кодирования |
Совместимость |
||
PAL / NTSC |
|
|
с DVD-плеером |
||
видео |
аудио |
||||
|
|||||
VCD |
352×288 |
MPEG-1 |
MPEG-1 |
всегда |
|
352×240 |
|||||
|
|
|
|
||
SVCD |
480×576 |
MPEG-2 |
MPEG-1 |
иногда |
|
480×480 |
|||||
|
|
|
|
||
DVD |
720×576 |
MPEG-2 |
MPEG-1, AC3 |
всегда |
|
720×480 |
|||||
|
|
|
|
||
XVCD |
720×576 |
MPEG-1 или |
MPEG-1 |
иногда |
|
720×480 |
MPEG-2 |
||||
|
|
|
|||
DivX |
640×480 |
MPEG-4 |
MP3, WMA |
иногда |
|
HDTV |
1280×720 |
MPEG-4 |
MP3, WMA, |
BD-плеер |
|
720p |
H.264 |
AC3 или др. |
|||
|
|
||||
HDTV |
1920×1080 |
MPEG-4 |
MP3, WMA, |
BD-плеер |
|
(i – чересстрочная |
|||||
1080i |
H.264 |
AC3 или др. |
|||
развертка) |
|
||||
|
|
|
|
||
AVCHD |
1280×720 |
MPEG-4 v.10 |
PCM (7.1) или |
нет |
|
(p – прогрессивная |
|||||
720p |
(AVC/H.264) |
AC3 (5.1) |
|||
развертка) |
|
||||
|
|
|
|
||
AVCHD |
1920×1080 |
MPEG-4 v.10 |
PCM (7.1) или |
нет |
|
1080i |
(AVC/H.264) |
AC3 (5.1) |
|||
|
|
||||
Все форматы сжатия семейства MPEG (MPEG-1, MPEG-2, MPEG-4, MPEG-7) используют высокую избыточность информации в изображениях, разделенных малым интервалом времени. Между двумя соседними кадрами обычно изменяется только малая часть сцены – например, происходит плавное смещение небольшого объекта на фоне фиксированного заднего плана. В этом случае полная информация о сцене сохраняется выборочно – только для опорных кадров. Для остальных кадров достаточно передавать разностную информацию: о положении объекта, направлении и величине его смещения, о новых элементах фона, открывающихся за объектом по мере его движения. Причем эти разности можно формировать не только по сравнению с предыдущими изображениями, но и с последующими (поскольку именно в них по мере движения объекта открывается ранее скрытая часть фона).
Алгоритмы MPEG сжимают только опорные кадры – I-кадры (Intra frame – внутренний кадр). В промежутки между ними включаются кадры, содержащие только изменения между двумя соседними I-кадрами – P-
30