

3865
.pdfУчтём, что скрещивание происходит с вероятностью ps , а также то, что даже если позиция разделителя окажется между фиксированными позициями схемы, хромосома S1 может являться представителем схемыH, если данная хромосома была получена скрещиванием двух представителей схемыH. Тогда вероятность ps,l того, что хромосома S1 является представителем схемы H, определяется выражением
d (H ) ps,l =1 - pc * l -1 .
Полагая независимость операций воспроизводства и скрещивания, оценим совокупный эффект от этих операций, т.е. число представителей схемы H в популяции G(t+1):
n(H ,t +1) / n(H,t) * K * |
Fср (GH (t)) |
* (1- p * |
d(h) |
). |
|
|
|||
|
Fср (G(t)) |
c |
l -1 |
|
|
|
|
Так как открытие новых областей поиска в операции скрещивания происходит лишь путём перегруппирования имеющихся в популяции комбинаций символов, то при использовании только этой операции некоторые потенциально оптимальные области могут оставаться не рассмотренными. Для предотвращения подобных ситуаций применяется операция мутации (рис. 2.14).
Рис. 2.14. Операция мутации
Мутация представляет собой процесс случайного изменения значений элементов хромосом. Для этого хромосомы, получившиеся на этапе скрещивания, просматриваются поэлементно, и каждый элемент с заданной вероятностью мутации pмут может мутировать, т.е. изменить значение на любой случай-
но выбранный символ, допустимый для данной позиции. Эта вероятность обычно очень мала, менее 1 %. Операция мутации позволяет находить новые комбинации признаков, увеличивающих ценность хромосом популяции. Допустим, что до мутации хромосомаS1 была представителем схемыH, т.е. S1 ÎUH . Допустим, что хромосома S2 получена из хромосомы S1 в результате мутации. Хромосома S2 будет представителем схемы H в том случае, если ни один из элементов хромосомы, соответствующий фиксированным позициям схемы, не был изменён.
Учитывая, что мутация происходит с вероятностью pмут , вероятность pS 2
того, что хромосома S2 является представителем схемы H, определяется выражением
æ o(H )önH PS1 = 1 - pc *ç ÷ ,
è l ø
где o(H) – число фиксированных позиций схемы H.
81
Полагая независимость операций воспроизводства, скрещивания и мутации, оценим совокупный эффект от этих операций, т.е. число представителей схемы H в популяции G(t+1):
|
|
Fср (GH (t )) |
æ |
|
|
d (h)ö |
|
o(H ) |
|
||||
n(H ,t +1)³ n H( ,t * K) |
* |
|
|
|
*ç1 |
- pc |
* |
|
÷ |
*(1 - p |
мут ) . |
(2.28) |
|
Fср |
(G(t )) |
l -1 |
|||||||||||
|
|
è |
|
|
ø |
|
|
|
|||||
Так |
как |
при |
малых |
|
значенияхm |
приближенно |
можно - счи |
||||||||||
тать pS 2 = (1 - pмут )o(H ) |
|
|
|
|
|
|
|
|
p |
|
|
|
|
|
|
||
= 1 - o(H )* pмут , то выражение (2.28) можно записать в виде |
|||||||||||||||||
|
n(H ,t +1)³ n H( ,t * K) |
|
Fср (GH (t )) |
æ |
|
d(h)ö |
|
(1 - o(H )* pмут ) |
|||||||||
|
* |
|
|
|
|
|
*ç1- pc * |
|
|
÷* |
|||||||
|
|
Fср |
(G(t )) |
|
|
||||||||||||
|
|
|
|
|
|
è |
|
l -1 ø |
|
|
|
||||||
или |
|
|
|
|
|
Fср (GH (t )) æ |
|
|
d(h)ö |
|
|
||||||
|
n(H ,t +1)³ n H( ,t * K) |
|
|
æ |
|
- o(H )* pмут |
ö |
||||||||||
|
* |
|
|
|
|
*ç |
ç1- pc |
* |
|
|
÷ |
÷ . |
|||||
|
F |
|
(G(t )) |
l -1 |
|||||||||||||
|
|
|
|
|
|
|
ç |
è |
|
ø |
|
÷ |
|||||
|
|
|
|
|
|
ср |
|
|
è |
|
|
|
|
|
|
ø |
|
Таким образом, схемы, у которых малы определяющая длина и порядок и для которых соответствующая подпопуляция имеет среднюю ценность, превышающую среднюю ценность популяции, экспоненциально увеличивают число представителей в последующих поколениях.
Очевидно, что эффективность описанной операции скрещивания существенно зависит от способа кодировки хромосом. Это свойство оказывается полезным для задач оптимизации функций, заданных на числовых множествах. Однако, если функция задана на произвольном множестве, например, на множестве комбинаций значений признаков объекта, где все признаки одинаковы по предпочтительности, то описанный выше способ скрещивания оказывается не вполне корректным, так как вероятность сохранения значений для групп признаков зависит от расстояния между элементами группы в кодовой хромосоме, а это нарушает принцип равной предпочтительности признаков. Поэтому для таких задач операцию скрещивания предполагается производить путём обмена не частями хромосом, а отдельными элементами. При этом задаётся некоторое число позиций n p }), которое определяет количество элементов
хромосом, для которых производится обмен значениями. Число позиций n p
может быть задано непосредственно или определяться случайно для каждой пары хромосом. Далее для каждой пары хромосом(S1,S2)i, где i-номер пары, случайно выбираются n p номеров ni, j ( ni, j О {1, 2, …, l}; jО {1, 2, …, n p }). Затем
для хромосом пары (S1,S2)I производится обмен значениями элементов с номерами ni, j , т.е. каждому элементу с номером ni, j хромосомы S1 присваивается
значение элемента с номером ni, j хромосомы S2 , а элементу с номером ni, j хромосомы S2 присваивается значение элемента с номером ni, j хромосомы S1.
Допустим, что до операции скрещивания хромосома S была представителем схемы H, т.е. S ÎU H , а хромосома S1 получена из хромосомы S в результате поэлементного скрещивания. Вероятность pSI того, что хромосома S1 будет
82

представителем схемы H, равна
æ o(H )önH PS1 = 1- pc *ç ÷ ,
è l ø
где o(H) – число фиксированных позиций схемы H.
Совокупный эффект от операций воспроизводства, поэлементного скрещивания и мутации, т.е. число представителей схемы H в популяции G(t+1,) определяется выражением
|
|
Fср (GH (t )) æ |
æ o(H |
)önH ö |
o(H ) |
|||||
n(H ,t +1)³ n H( ,t * K) |
* |
|
|
*ç1- pc |
*ç |
|
÷ |
÷ |
*(1 - pмут ) . |
|
F |
(G(t )) |
1 |
||||||||
|
|
ç |
è |
ø |
÷ |
|
||||
|
|
ср |
|
è |
|
|
|
ø |
|
|
Таким образом, при поэлементном скрещивании скорость увеличения представителей схемы в последующих поколениях зависит от средней ценности схемы и количества фиксированных позиций и не зависит от расстояния между ними, а значит, не зависит от порядка расположения элементов в хромосоме.
В результате данных операций получаемK*N новых хромосом, которые либо полностью формируют новую популяциюG(t+1) (при K=1), заменяя при этом все хромосомы популяции G(t), либо составляют часть популяции G(t+1), заменяя собой K*N наименее ценных хромосом предыдущей популяции.
Как видно из описания алгоритма, закон F0 (w1 , w2 ,...,wn ) вероятности распределения значений целевой функции определяется и корректируется путём использования набора (популяции) хромосом, содержащих наилучшие в смысле значений целевой функции комбинации элементов.
Таким образом, процесс генерации промежуточной популяции, скрещивания и мутации приводит к формированию нового поколения. Шаг алгоритма завершается объявлением нового поколения текущим. Далее все действия повторяются. Такой процесс эволюции может продолжаться до бесконечности.
Критерием останова служит заданное количество поколений или сходимость популяции.
Сходимость - такое состояние популяции, когда все строки популяции почти одинаковы, а значения находятся в области некоторого экстремума. В такой ситуации кроссовер практически никак не изменяет популяции. А вышедшие из этой области за счет мутации особи склонны вымирать, так как чаще имеют меньшую приспособленность, особенно если данный экстремум является глобальным максимумом. Таким образом, сходимость популяции обычно означает, что было найдено лучшее решение.
Блок-схема алгоритма распределения финансовых инвестиций приведена на рис. 2.15.
Блоки 1,12 используются для пуска и остановки процесса распределения финансовых инвестиций.
В блоке 2 реализован ввод исходных данных, таких как количество инвестируемых проектов, общий объем инвестиций; диапазон изменений инвестиций для различных проектов.
83

1
Начало
2
Ввод исходных данных
3
Формирование
M- начальных популяций
4
Расчет приспособленности индивидуума и популяции в целом
5
Выбор индивидуумов
для скрещивания
6
Скрещивание индивидуумов
7
Реализация процедуры мутации
8
Формирование новой
популяции n=n+1; n £ N
Нет
9 Определение
максимума ЦФ
Да
10
Описание реквизитов лучшего индивидуума во всей популяции
11
Вывод результатов
12
Конец
Рис. 2.15. Генетический алгоритм распределения финансовых инвестиций
84
Вблоке 3 формируются множества начальных популяций, каждая из которых состоит из N индивидуумов (по количеству проектов). Данные популяции формируются случайным образом.
С помощью блока 4 производится расчет приспособленности каждого индивидуума (доходность каждого варианта) и популяции в целом(доходность всех вариантов).
Вблоке 5 реализован выбор индивидуумов для скрещивания. Важную роль в организации данного процесса играет модель отбора индивидуумов. Она определяет, каким образом следует строить популяцию следующего поколения. От качества такой модели зависит эффективность(точность и оперативность) генетического алгоритма. В данном алгоритме использована элитарная модель отбора [57]. Использование данной модели позволило ускорить сходимость генетического алгоритма (более оперативно достигнуть экстремума).
Вблоках 6,7 реализованы процедуры скрещивания, мутации и инверсии. Блок 8 реализует формирование новой популяции путем циклического
добавления новых индивидуумов(вариантов инвестирования) в имеющуюся популяцию.
Блок 9 обеспечивает определение максимального значения целевой функции. В случае достижения глобального максимума(максимальной прибыли инвестора) управление передается блоку 10. В противном случае управление передается в блок 4 и осуществляется дальнейшее последовательное выполнение процедур, реализуемых блоками 5,6,7,8.
В блоке 10 раскрывается описание реквизитов лучшего индивидуума во всей популяции.
Блок 11 обеспечивает вывод полученных результатов(рациональный вариант распределения инвестиций по проектам и соответствующее значение прибыли инвестора).
Результаты апробации ГА для настройки ИНС приведены в. пп2.5.2. Анализ полученных результатов показал его более высокую точность по сравнению с алгоритмом имитации отжига, но более низкую оперативность. Для повышения оперативности ГА подвергся 2-этапной процедуре модификации.
Суть первого этапа модификации ранее уже апробировалась[122] и заключалась в следующем.
Рассмотрим постановку решаемой задачи(оптимизацию портфеля инвестиционных проектов) в свете классической задачи о рюкзаке [185].
Имеется рюкзак, который способен выдержать вес, ограниченный некоторой константой P. Существует N предметов, каждый из которых имеет определенный вес pi и стоимость si. Необходимо в рюкзак положить такую совокупность предметов m, m Î N , чтобы их суммарный вес Pm не превысил константу
P ( |
P £ P |
S |
была максимальной |
m |
), а суммарная стоимость этих предметов m |
S m ® max .
85
Обычно данную задачу решают методами прямого перебора и ветвей и границ. Эти методы просты и практически всегда дают точное решение. Их основными недостатками являются экспоненциальная сложность заложенных алгоритмов и соответственно высокая ресурсоемкость, предъявляемая к вычислительным средствам.
Специфика модифицированного генетического алгоритма(МГА), реализующего данную задачу, состояла в следующем.
Кодирование решений реализовывалось следующим образом. Значение j-го гена хромосомы, где j = 1, 2 .. k, равно единице, если i-й предмет положили в рюкзак, и равно нулю, если предмет не положили.
Учитывалось, что ввиду существующего ограниченияP (вместимости рюкзака) не всякая комбинация нулей и единиц в векторе длины n может давать допустимое решение. Комбинация предметов, соответствующая произвольно заданной хромосоме, может превысить допустимый вес. Для решения данной проблемы сначала использовались стандартные операторы одноточечного или равномерного кроссовера, а затем полученная хромосома преобразовывалась в допустимую путем замены в ней некоторых случайно выбранных единиц нулями.
Функция пригодности определяла степень выживаемости индивидуума в популяции. Чем больше значение функции пригодности индивидуума, тем ближе соответствующее ей решение к точному решению задачи о рюкзаке. В качестве функции пригодности конкретного индивидуума использовалась суммарная стоимость предметов, положенных в рюкзак.
Классический метод ветвей и границ, лежащий в основе построения деревьев и оценки перспективности их вершин, нашел своё развитие. Развитие заключалось в том, что строилось не всё дерево решений, а лишь его перспективные поддеревья (первое отличие). Отправной точкой построения поддерева являлась вершина, соответствующая решению, полученному в результате работы ГА. Далее достраивались вышестоящие вершины, которые после проведения соответствующих оценок, в свою очередь, становились корневыми вершинами для новых поддеревьев. Другими словами, использовалась стратегия «снизувверх», в отличие от стратегии классического метода ветвей и границ«сверху - вниз» (второе отличие). Полученная высота построенного дерева (совокупности поддеревьев) получила название «уровень приближения» и была принята в качестве числового параметра, разработанного ГА. Данный параметр определяет протяженность области определения целевой функции, координаты центра которой (области) определены с использованием ГА. В результате проведенных экспериментов было установлено, что точность ГА прямо пропорционально зависит от заданного значения уровня приближения, а зависимость быстродействия носит обратный характер.
86
Для апробации разработанного ГА и сравнения его характеристик с параметрами существующих ГА была реализована клиент-серверная программная система, предоставляющая пользователю следующие возможности:
- проводить загрузку пяти ГА(canonical, simple, genitor, island, МГА)
[162];
-устанавливать параметры ГА (объем популяции, генетические операторы, количество итераций и т.д.), а также изменять эти параметры в ходе работы программы;
-хронометрировать временные режимы работы ГА;
-выводить результаты сравнения ГА в табличной и графической формах. Генетическими алгоритмами обрабатывались популяции размерами50,
100, 500, 1000, 5000 и 10000 индивидуумов. Для сравнения точности (s,% ) работы ГА на начальном этапе данная задача решалась классическим методом ветвей и границ. Результат её решения использовался в качестве эталонного (100%). Результаты сравнительного анализа точности и оперативности(T , c ) работы пяти ГА и модифицированного ГА приведены в табл. 2.6.
Таблица 2.6 Результаты сравнительного анализа функционирования ГА
Вид ГА |
|
|
|
|
|
Число индивидуумов в популяции |
|
|
|
|
|
|||||||
|
50 |
|
100 |
|
500 |
|
1000 |
|
5000 |
|
10000 |
|||||||
|
s,% |
T , c |
s,% |
T , c |
s,% |
T , c |
s,% |
T , c |
s,% |
T , c |
s,% |
T , c |
||||||
Сanonical |
88 |
|
0,01 |
90 |
|
0,09 |
92 |
|
0,11 |
94 |
|
0,15 |
97 |
|
0,2 |
99 |
|
0,25 |
Simple |
70 |
|
0,31 |
78 |
|
0,33 |
82 |
|
0,38 |
86 |
|
0,41 |
93 |
|
0,5 |
95 |
|
0,58 |
Genitor |
72 |
|
0,0015 |
75 |
|
0,0019 |
77 |
|
0,0025 |
81 |
|
0,03 |
88 |
|
0,12 |
90 |
|
0,28 |
Island |
80 |
|
0,29 |
84 |
|
0,33 |
88 |
|
0,47 |
91 |
|
0,77 |
94 |
|
0,89 |
96 |
|
1,65 |
МГА |
95 |
|
0,23 |
99 |
|
0,29 |
100 |
|
0,39 |
100 |
|
0,69 |
100 |
|
0,82 |
100 |
|
1,04 |
Результаты вычислительных экспериментов показали, что наиболее оперативными оказались алгоритмыGenitor и Canonical, им уступают Island и Simple. МГА по быстродействию занимает промежуточное положение. По точности исследованные алгоритмы распределились следующим образом: МГА –
99%; Canonical – 93%; Island – 89%; Simple – 84%; Genitor – 81%. Наиболее точным оказался МГА.
Установлено, что с увеличением количества индивидуумов в популяциях точность решения задачи увеличивается, а оперативность проведения расчетов падает. Проведенные эксперименты позволили выделить МГА как наиболее рациональный по скорости и точности.
Второй этап модификации МГА состоял в применении островной модели параллельных вычислений.
2.5.1. Островная модель параллельных вычислений
Выбор данной модели обусловлен ее распространенностью и простотой реализации. Ее суть заключается в том, что популяция разбивается на одинако-
87

вые по размеру подпопуляции. Каждая подпопуляция обрабатывается отдельным процессором с помощью одной из разновидностей непараллельного ГА. Периодически, через пять поколений, подпопуляции обмениваются несколькими особями. Подобные миграции позволяют подпопуляциям совместно использовать генетический материал. В схематичном виде данный процесс представ-
лен на рис. 2.16 [138].
Рис. 2.16. Схема работы островного генетического алгоритма
Особенности механизма функционирования данной модели рассмотрим на следующем примере. Пусть выполняются 16 независимых генетических алгоритмов, использующие подпопуляции по 1000 особей на каждом процессоре. Если миграций нет, то происходит 16 независимых поисков решения. Все поиски ведутся на различных начальных популяциях и сходятся к определенным особям. Исследования подтверждают, что генетический дрейф склонен приводить подпопуляции к различным доминирующим особям. Это связано с тем, что, во-первых, количество островов, принимающих доминирующих «эмигрантов» с острова, ограничено (2-5 островов). Во-вторых, обмен особями односторонен. Поэтому в большой популяции появятся группы островов с различными доминирующими особями. Если популяция небольшого размера, то возможно быстрое мигрирование ложных доминирующих особей. Например, истинное решение находится только на одном острове, а несколько ложных доминантна других островах. Тогда при миграции количество ложных особей на островах возрастет (на каждый остров миграции происходят с не менее2 островов), генетическим алгоритмом верное решение будет разрушено. Тем самым в маленькой популяции при генетическом дрейфе возможно появление ошибочных доминирующих особей и схождение алгоритма к ложному оптимуму.
Введение миграций в островной модели позволяет находить различные особи - доминанты в подпопуляциях, что способствует поддержанию многообразия в популяции. Каждую подпопуляцию можно принять за остров. Во время миграции подпопуляции обмениваются своим доминирующим генетическим материалом. При частом мигрировании большого количества особей происходит перемешивание генетического материала. Тем самым устраняются локальные различия между островами. Очень редкие миграции не позволяют предот-
88
вратить преждевременную сходимость алгоритма в маленьких подпопуляциях.
В рассматриваемой модели с каждого острова миграции могут происходить лишь на определенное расстояние: 2-5 островов в зависимости от количества подпопуляции. Таким образом, каждый остров оказывается почти изолированным. Количество островов, на которые могут мигрировать особи одной подпопуляции, называют расстоянием изоляции. Следует заметить, что взаимомиграции исключены. Все приведенные варианты ГА в работе моделировались для различных значений параметров ГА.
Данная модель генетического алгоритма обладает следующими свойст-
вами:
-наличием нескольких популяций фиксированного размера;
-фиксированной разрядностью генов;
-комбинированием стратегий отбора и формирования следующего поколения в каждой популяции;
-отсутствием ограничений на тип кроссовера и мутации;
-реализацией обмена особями между "островами" случайным образом. Блок–схема ГА оптимизации инвестиций, реализующего островную модель
параллельных вычислений, приведена на рис. 2.17. Функциональное назначение его блоков аналогично алгоритму, представленному на рис. 2.15. Особенность данного алгоритма состояла в том, что каждая подпопуляция обрабатывалась (блоки 3, 4, 5, 6, 7, 8, 9) на отдельном процессоре (данные блоки в приведенном алгоритме выделены двойными линиями). Между подпопуляциями осуществлялся обмен (1 раз в итерацию общего цикла) индивидуумами посредством миграции.
Врезультате отыскивался лучший индивидуум во всей популяции [57].
Впроцессе обработки информации выделялись две группы операций:
-локальные операции, независимо выполняемые на каждом процессоре, в частности: расчет значений функций приспособленности для каждого индивидуума; выбор индивидуумов; скрещивание; мутации; формирование родительских пар;
-глобальные операции – обмен индивидуумами между процессорами, в частности, операции коммуникации и синхронизации.
Для апробации данного алгоритма в средеDelphi была разработана специальная программа, реализующая интерфейс пользователя, комплекс процедур, описанных выше, и набор инструментальных средств, используемых в интересах получения и анализа его (алгоритма) динамических свойств. В качестве аппаратной платформы использовались два персональных компьютера(сервера) Intel Pentium IV Dual Xeon 2.8 (двухпроцессорные) с объемом оперативной памяти – 1 Gb, объединенных в единую сеть. Это позволило реализовать проведение параллельных вычислений на 1, 2, 3 и 4 процессорах.
На рис. 2.18 приведены зависимости изменения ускорения проведения вычислений от числа используемых процессоров для теоретических и реальных условий. Результаты получены относительно расчетов, проведенных на одном процессоре. Данные зависимости имеют различия.
89
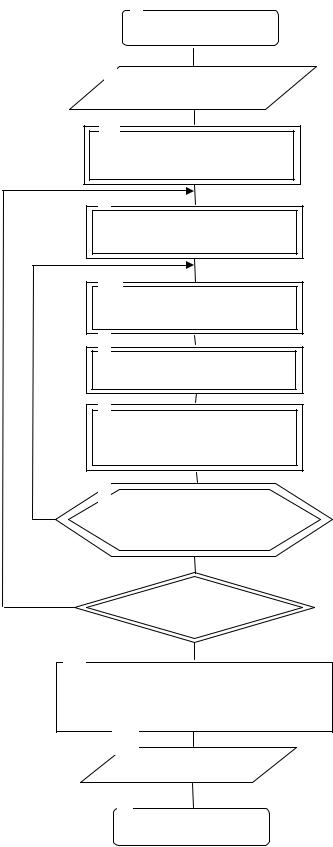
1
Начало
2
Ввод исходных данных
3
Формирование
M- начальных популяций
4
Расчет приспособленности ини-
видуума и популяции в целом
5
Выбор индивидуумов для
скрещивания
6
Скрещивание индивидуумов
7
Реализация процедуры
мутации
8
Формирование новой
популяции n=n+1; n £ N
Нет |
|
|
|
|
|
|
|
9 |
Определение мак- |
||
|
|
|
|
||
|
|
|
|
|
симума ЦФ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
Да |
|
|
|
|
|
|
Анализ результатов параллельных вычислений:
обмен индивидуумами для формирования -ро дительских пар, определение и отбор лучшег индивидуума во всей популяции
11
Вывод результатов
12
Конец
Рис. 2.17. Блок – схема генетического алгоритма, совмещенного с островной моделью параллельных вычислений
90