

3865
.pdf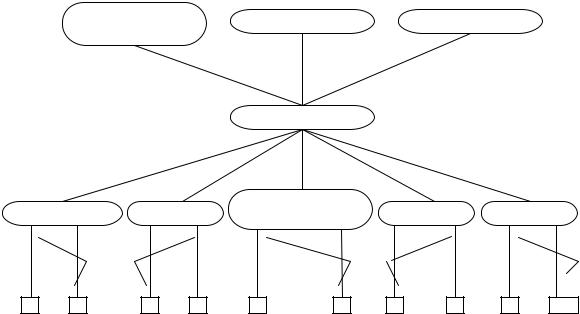
ду собой смыслом. В процессе определения наиболее важных понятий, содержащихся в тексте, необходимо соответствующее ассоциативное множество слов, привести к нормальной форме. Для определения ассоциативного множества слов, целесообразно использовать меры связности графа с аксиоматическими лексемами [111].
На практике, наряду с представлением текста в виде графа, используют семантическую сеть. Она позволяет представлять смысл текста в более естественной форме – в виде совокупности связанных между собой понятий(слов и словосочетаний), несущих основную смысловую нагрузку и наиболее часто, встречающихся в тексте. Она, как и граф, состоит из вершин и рёбер.
Имена, приписываемые вершинам и рёбрам семантической сети, совпадают с именами соответствующих сущностей и отношений используемыми в естественном языке. Ребро и связываемые им вершины образуют подграф -се мантической сети, несущий минимальную информацию - факт наличия связи определённого типа между соответствующими объектами.
Пример фрагмента семантической сети, описывающей кризисные состояния (предкризисное состояние, кризис, рецессия) внешней среды в сфере экономики, представлен на рис. 4.5.
|
Предкризисное |
|
Кризис |
|
Рецессия |
|
|||
|
состояние |
|
|
|
|
|
|
|
|
|
|
|
|
|
имеет |
|
|
|
|
|
|
|
|
Экономика |
|
|
|
|
|
|
|
|
|
|
имеет |
|
|
|
|
Безработица |
Капитал |
|
Внешний |
|
ВВП |
Бюджет |
|||
|
долг |
|
|||||||
|
имеет |
|
|
|
имеет |
|
|
|
имеет |
Р |
С |
О |
П |
Р |
С |
Р |
С |
Д |
Пф |
|
Р - рост С - снижение |
О-отток П-приток |
Д-дефицит |
Пф-профицит |
|||||
|
|
|
Рис. 4.5. Фрагмент семантической сети |
|
|
||||
Пример, представленный на рис. 4.5, может быть проработан на любую глубину. При этом слова, используемые при обозначении объектов в семантической сети, могут быть продублированы в других названиях сколь угодно раз.
Воспользовавшись фрагментом вышеприведенной семантической сети, можно построить структуру «экономические показатели».
СОЗДАТЬ-СТРУКТУРУ (ИМЯ СТРУКТУРЫ = ЭКОНОМИЧЕСКИЕ ПОКАЗАТЕЛИ ЧИСЛО АТРИБУТОВ = 5
163
АТРИБУТ = БЕЗРАБОТИЦА АТРИБУТ = КАПИТАЛ АТРИБУТ = ВНЕШНИЙ ДОЛГ АТРИБУТ = ВВП АТРИБУТ = БЮДЖЕТ).
Для реализации данной структуры целесообразно использовать аппарат фреймов [190]. Известно, что наибольшее распространение находят три типа фреймов: фреймы-структуры, фреймы-роли, фреймы-сценарии [190]. В [64] для построения модели семантического анализа русскоязычных текстов использовались фреймы-сценарии. В данной работе, более перспективным является использование фреймов-структур в силу трех причин. Во–первых, они в максимальной степени соответствуют представлению информации по своему принципу построения. При заполнении их элементов-слотов определёнными значениями, фрейм-структуры превращается в описания конкретных фактов, событий, процессов [72, 233]. Во-вторых, фрейм-структуры обладают объектноориентированными свойствами инкапсуляции, наследования и полиморфизмом объектов [190], что гармонично сочетается с общей технологией разработки СППИР, в частности, использованием объектно-ориентированной среды разработки Delphi 7.0. В-третьих, табличная форма представления фрейм-структур оптимально вписывается в общую концепцию построения БД СППИР(как в рамках хранилища данных, так и витрины данных).
Недостатками фреймового подхода к проведению семантического анализа текста, являются более жёсткое, чем при подходе, основанном на семантической сети, выделение объектов, ситуаций и их свойств, а также возрастание сложности фреймовой модели (появление разнотипных вложенных фреймов) при увеличении в тексте числа иерархически взаимосвязанных разноплановых понятий, терминов, фактов, событий, процессов и др. [199]. Данные недостатки приводят к существенным трудностям формирования терминологических портретов.
Для парирования данных недостатков использовалась гибридная модель семантического анализа, содержащая как семантическую сеть, так и фреймыструктуры. При этом составляющие данной модели использовались избирательно. Так, в интересах семантического анализа газетных статей приоритет в использовании отдавался фреймам.
Поскольку газетные статьи являются одним из источников снижения неопределенности внешней среды для ЛПР, исследование последних актуально. Проведенные исследования показали, что для их семантического анализа целеесообразно применять фреймы. Поскольку первейшей заботой журналиста является быстрая и не загружающая мозг передача информации, то, как правило, все характеристики, требующие применения медленных индуктивных или дедуктивных процессов, для семантического анализа которых необходимы семантические сети, не используются [199]. В данной работе, для обработки газетных подборок использовалась следующая технология. Для обработки заголовка статьи и одногодвух первых предложений вызывался центральный
164
фрейм. Его ячейки заполнялись понятиями, содержащимися в выделенных лексемах. В зависимости от их значимости, некоторые понятия становились термами новых фреймов, ячейки которых заполнялись понятиями из лексем других фрагментов статьи. В процессе заполнения фреймовой структуры, трудности вызывали сложные местоимения. В интересах их устранения, часть сложных местоимений ограничивалась в использовании на основе стоп-словаря [58].
Анализ других источников информации (интернет, электронные журналы и др.), содержащих описание кризисного состояния внешней среды, показал целесообразность использования фреймов в совокупности с семантической сетью. Как оказалось, ещё одним важным достоинством использования фреймов, явилась возможность реализации с их помощью ответов на вопросы. В рамках данной работы развитие этого направления не рассматривалось.
Применительно к описанию кризисного состояния внешней среды, использование гибридной модели синтаксического анализа позволило создать базу знаний (БЗ) в виде набора терминологических портретов, характеризующих различные понятия данной предметной области. На основе созданной БЗ, объекты данной предметной области, идентифицировались и накапливались в соответствующей базе данных.
Ниже приведеныы несколько правил из БЗ:
1. ЕСЛИ ОБЪЕКТ. АТРИБУТ = “ЛИКВИДНОСТЬ“ И ОБЪЕКТ. ЛИКВИДНОСТЬ = “ОТСУТСТВУЕТ”, ТО
ОБЪЕКТ. ИМЯ = “БАНКРОТ”, И ОБЪЕКТ. АТРИБУТ = “ПОТЕНЦИАЛЬНЫЙ”
2. ЕСЛИ ОБЪЕКТ. АТРИБУТ = “ВВП“ И ОБЪЕКТ. ВВП = “НИЗКИЙ” И
ОБЪЕКТ. АТРИБУТ = “ДОЛГ” И ОБЪЕКТ. ДОЛГ = “ВНЕШНИЙ” И
ОБЪЕКТ. ДОЛГ = “ВЫСОКИЙ”, ТО ОБЪЕКТ. ИМЯ = “КРИЗИС” И
ОБЪЕКТ. КРИЗИС = “ФИНАНСОВЫЙ”.
Подобные правила позволили добавлять фреймы, атрибуты во фреймы, менять значения атрибутов и др.
Применение разработанной семантической матричнолексической модели анализа текстов в совокупности с базой знаний, позволили с определенной точностью идентифицировать в текстовой информации определенные понятия, их атрибуты и связи с другими объектами. В результате появилась потенциальная возможность извлечения дополнительных данных(новых знаний), содержащихся в текстах, что обусловило необходимость разработки соответсвующей модели.
4.7. Извлечение новых знаний
Модель извлечения новых знаний (МИНЗ) базируется на определении логических цепочек взаимосвязей терминов в массиве текстовых документов и в случае их наличия, извлечении новых терминов [111].
165

Под новыми знаниями будем понимать новую дополнительную терминологическую информацию, извлекаемую из текста (текстов).
Схема, поясняющая принцип функционирования МИНЗ, приведена на рис. 4.6.
На вход МИНЗ подается набор терминов (Т1, Т2, Т3), для которых необходимо найти дополнительную информацию. Пользователем может быть сформирован набор правил (критериев) отбора новых терминов, содержащихся в БЗ,
БЗ
Т1  Т111
Т111 



 Т111
Т111
Т2 |
g11 |
|
|
БДДИ |
|
Т121 |
Т2121 |
Т121 |
Т2121 |
||
|
|||||
|
|
g12 |
|
|
|
Т3 |
Т131 |
Т3131 |
Т131 |
Т3131 |
|
|
|
g13 |
|
|
|
|
|
Т2 |
|
Т2 |
|
|
|
11 |
|
11 |
|
|
|
Т213 |
|
Т213 |
|
|
|
Т43 |
|
Т43 |
|
|
|
Т313 |
|
Т313 |
Рис. 4.6. Схема, поясняющая принцип функционирования МИНЗ
в виде пороговых значений частот их встречаемости в текстах( g11 , g12 , g13 ). Кроме того, он может задавать синонимы искомых терминов(например, «жаргонизмы»), которые не содержатся в используемом словаре [36].
В результате проведенного семантического анализа установлено, что из множества текстов, принадлежащих заданной предметной области (терминологическому портрету информационной системы), в трех текстах (отмечены прямоугольниками с пунктирными границами) найдены восемь терминов ( Т111 , Т121 , Т131 , Т2121 , Т112 , Т3131 , Т321 , Т331 ), имеющих логические цепочки
166
взаимосвязей (представлены на рисунке прямыми штрих-пунктирными линиями) лишь с одним термином (Т1) из трех, поступивших на вход МИНЗ. Термины внутри цепочек имеют n, m – мерную двухуровневую индексацию (n – число текстов, связанных с данным термином, m – число взаимосвязанных терминов). Верхний n – мерный (в приведенной схеме – двойной) индекс указывает на тот факт, что термин текста за номером левого индекса логически связан с термином текста за номером правого индекса. Верхний одинарный индекс указывает на тот факт, что данный термин логически связан с одним из терминов только этого текста. Нижний m – мерный (в приведенной схеме – двойной) индекс указывает на тот факт, что термин текста за номером левого индекса логически связан с термином за номером правого индекса. В анализируемых текстах могут оказаться одиночные термины, не связанные с терминами других текстов. Для них используются верхние и нижние одиночные индексы. Все выявленные термины (связанные и не связанные) хранятся в базе данных дополнительной информации (БДДИ). К каждому из них, у пользователя имеется доступ.
Для записи каждого термина в БДДИ имеетя три поля : два поля, в которых хранятся верхний и нижний индексы, и текстовое поле в котором хранится определение данного термина. Для хранения дублирующих терминов используется правило: «Если дублизующий термин одиночный (не содержит логических цепочек с другими терминами) и подобный термин уже содержится в БДДИ, то он исключается из БДДИ. В противном случае он записывается в БДДИ».
Хранение верхнего и нижнего индексов терминов позволило -про граммными средствами Delphi реализовать процедуру восстановления межтекстовых терминологических взаимосвязей(логических цепочек). Данная процедура прошла апробацию [87] и показала себя аналогом подсистемы объяснения, используемой в экспертных системах. Однако для ее реализации не потребовалось применение специального математического аппарата (например, логики предикатов первого порядка и др.) и соответствующих высокоуровневых языков программирования (Пролог, ЛИСП и др.).
Вышеописанная технология терминологического поиска в СППИР нашла свою программную реализацию.
4.8.Программная реализация терминологического поиска
Винтересах повышения оперативности терминологического поиска в СППИР, была разработана система виртуального распределенного терминологического поиска (СВРТП), в дальнейшем с целью сокращения – система [150]. Она представляет собой пакет программ, предназначенный для распределенного поиска информации о терминах, вводимых пользователем, и извлечения связанных с ними новых дополнительных сведений в системах поддержки принятия решений, используемых в интересах снижения неопределенности внешней
167
среды. Особенностью данной системы является возможность реализации терминологического поиска на виртуальных машинах(на локальной виртуальной машине и в сети виртуальных машин).
Виртуальная машина представляет собой специальную программу, эмулирующую реальный ПК (BIOS, ЖМД, операционную систему и др.). Она позволяет осуществить обмен данными между локальным ПК, виртуальной машиной и их сетью [30].
Система выступает в роли интеллектуального поискового агента (ИПА). Интеллектуальность поискового агента обусловлена наличием процедур, реализующих механизм весовой генерации запросов, эквивалентный механизму пользовательских предпочтений. Разработанный ИПА обладает следующими важными свойствами:
-автономностью;
-интерактивностью;
-рациональностью;
-проактивностью.
Автономность характеризует тот факт, что ИПА самостоятельно выполняет значительную часть своей работы. Во время выполнения работы ИПА не взаимодействует с пользователем и с другими агентами.
Интерактивность подразумевает умение ИПА взаимодействовать с пользователем [143]. Суть взаимодействия заключается в настройке моделей и механизмов ИПА пользователем, получении заданий от него и предоставлении ему полученных результатов.
Рациональность заключается в выполнении определенных действий для достижения поставленной цели и отсутствии противоположных действий, препятствующих ее достижению.
Проактивность предполагает наряду со сбором основной информации (по введенному термину) также сбор дополнительной информации.
ИПА реализует функции передаточного механизма между потребностями пользователя и стандартными поисковыми системами, такими как [149]: Яндекс, Google, Rambler и др, кроме того, ИПА обладает специфическими функциями, такими как:
-построение терминологического портрета предметной области пользо-
вателя;
-построение терминологического портрета текста;
-селекция основной терминологической информации;
-селекция дополнительных терминов;
-выборка информации по дополнительным терминам;
-ведение терминологической базы данных (БД);
-накопление в базе данных основной и дополнительной терминологической информации;
-формирование инсталляционных пакетов исполнительных поисковых агентов для локальных и виртуальных машин.
168

Структурно-функциональная схема ИПА приведена на рис. 4.7. Интерфейс пользователя предназначен для получения заданий от пользо-
вателя и предоставления ему полученных результатов. На начальном этапе функционирования системы на основе интерфейса формируется терминологический портрет предметной области пользователя путем ввода набора терминов и их распределения по различным уровням иерархии.
Интерфейс
пользователя
Модуль управления
База |
База |
Набор |
Стандартные |
|
исполнительных |
поисковые |
|||
моделей |
данных |
|||
ПА |
системы |
|||
|
|
Рис. 4.7. Структурно-функциональная схема ИПА
Модуль управления занимает центральное место в системе. Он обеспечивает взаимодействие всех элементов системы и координацию их функционирования в соответствии с заданной логикой (моделью). После запуска системы он автоматически переходит в активное состояние и ожидает команды пользователя. Активное состояние модуля управления предполагает выполнение с определенной периодичностью набора ряда процедур, таких как:
-упорядочение записей в распределенной БД в соответствии с иерархией терминологического портрета предметной области;
-индексирование записей в распределенной БД по иерархическим -сег ментам терминологического портрета предметной области;
-очистка БД от информации, невостребованной пользователем в течение заданного временного интервала;
-опрос готовности дежурного исполнительного поискового агента.
По мере поступления команд от пользователя модуль управления выполняет набор следующих процедур:
-прием входного термина или их последовательности;
-идентификация иерархической принадлежности терминов;
-оценка загрузки канала дежурного исполнительного поискового агента;
-формирование пакета инсталляции дополнительных исполнительных поисковых агентов для локального персонального компьютера (ПК);
-формирование пакета инсталляции дополнительных исполнительных поисковых агентов для локальной вычислительной сети;
169

-формирование пакета инсталляции дополнительных исполнительных поисковых агентов для виртуальных машин;
-оценка загрузки каналов дополнительных исполнительных поисковых агентов;
-распределение поисковой терминологической нагрузки среди дополнительных исполнительных поисковых агентов;
-репликация распределенной БД.
В каждом исполнительном ИПА имеется свой модуль управления, реализующий такие функции, как:
-инициализация терминологического портрета предметной области;
-прием последовательности терминов пользователя;
-выбор поисковой системы и генерация запросов;
-построение терминологических портретов текстов;
-идентификация поступивших текстов;
-селекция основных (искомых) терминов и информации по ним;
-селекция дополнительных (сопутствующих) терминов и информации по ним;
-занесение информации по основным и дополнительным терминам в БД. База моделей ИПА обеспечивает требуемую логику его функционирования. Состав базы моделей системы представлен на рис. 4.8.
База моделей системы терминологического поиска
Модель |
|
Модель |
|
Модель |
пользователя |
|
внешней среды |
|
предметной области |
|
|
|
|
|
Рис. 4.8. Состав базы моделей системы
Модель пользователя отражает механизм взаимодействия последнего с базой данных. Наличие данной модели позволяет повысить эффективность поиска и обеспечить реализацию упреждающего поиска (проактивность) информации и мониторинга потоков ее поступления. Кроме того, данная модель отображает постоянные информационные потребности пользователя(информационные запросы по отслеживанию предпочитаемых источников и запросы безотносительно источников). Пользователь имеет возможность корректировать модель.
Модель внешней среды устанавливает порядок взаимодействия пользователя с окружающим информационным пространством. Элементами модели внешней среды являются:
-информационные ресурсы, включающие сектора деловой информации, юридической информации, информации для специалистов, а также массовой, потребительской информации;
-набор правил работы с информационными ресурсами;
-средства добычи информации (поисковые системы, поисковые машины, программы-роботы и др.);
170