

3865
.pdfределение исторического промежутка в N шагов расчета, за который рассматриваются значения доходности rit для каждой ЦБ.
Шаг 2. Определение рыночных доходностей rmt за рассматриваемый пе-
риод времени по выбранному рыночному индексу. |
|
|
|
|
|
2 , |
Шаг 3. Определение величины дисперсии рыночного показателяsm |
||||||
значений ковариаций si,m доходностей каждой ЦБ с доходностью |
рыночного |
|||||
портфеля (выбранным фондовым индексом) и расчет величины b |
|
= |
si ,m |
. |
|
|
i |
|
|
||||
|
|
s |
2 |
|
|
|
|
|
|
|
m |
|
|
Шаг 4. Вычисление ожидаемых доходностей каждой ЦБ Ri (ri ) , доходности рыночного портфеля R p ( r m ) и расчет параметра ai = Ri (ri ) - bRp (rm ) .
Шаг 5. Вычисление дисперсии случайных ошибок ei .
Шаг 6. Подстановка полученных значений в соответствующие уравнения. Определение весов ЦБ с учетом выбранного значения ожидаемой доходности инвестиционного портфеля.
Шаг 7. Построение границы эффективных портфелей и определение оптимального портфеля.
2.3.3. Программная реализация определения долей ценных бумаг в оптимальном портфеле Шарпа
Реализация задачи определения долей ценных бумаг, входящих в оптимальный портфель Шарпа, представлена в виде программного модуля, включенного в состав СППИР [152]. В качестве среды разработки модуля использована объектно–ориентированная среда разработки Delphi 7.0. Обоснование выбора данной среды представлено в [153].
Экранная форма расчета долей ценных бумаг, входящих в оптимальный портфель Шарпа, приведена на рис. 2.7.
Рис. 2.7. Вид экранной формы расчета долей ценных бумаг, входящих в оптимальный портфель Шарпа
71
Верхняя часть экранной формы предназначена для ввода исходных данных для расчета. В левой верхней части экранной формы находится окно со списком ценных бумаг (облигаций), которые могут быть включены в состав портфеля. Рядом находится окно, в котором отображаются выбранные облигации. В средней части экранной формы находится окно«Доходность к погашению». В правой части формы размещены два окна, в которых задаются количество типов ЦБ (облигаций) и количество рассматриваемых временных интервалов соответственно. Они заполняются на начальном этапе работы с программным модулем. Затем осуществляется выбор конкретных ЦБ (облигаций). После выбора необходимой облигации пользователь нажимает правую кнопку мыши. Появляется кнопка «Добавить». Нажатием данной кнопки соответствующая ЦБ перемещается в окно«Выбранные облигации». Далее необходимо ввести требуемые периоды наблюдения за доходностями облигаций. Соответствующие окна ввода размещены снизу окна«Выбранные облигации». Кнопки «Сброс» и «Принять», размещенные справа от этого окна, обеспечивают соответственно удаление или принятие списка выбранных ЦБ. Перечень выбранных
(принятых) ЦБ и их доходность за выбранные периоды отобразится в окне «Доходность к погашению», размещенном в правой верхней части экранной формы. Значения доходности облигаций могут корректироваться и вводиться с клавиатуры.
В нижней части экранной формы отображаются результаты расчета. Они появляются после ввода исходных данных (заполнения верхней части экранной формы) и нажатия кнопки «Расчет». В состав результатов расчета включены доля капитала, вложенная в безрисковые облигации, риск портфеля и процентные соотношения выбранных ЦБ в виде соответствующих весов.
Кроме того, на данной экранной форме имеются кнопки«Справка» и «Выход». Нажатие кнопки «Выход» обеспечивает возврат на главную форму СППИР. При нажатии на кнопку«Справка» появляется соответствующая экранная форма, в которой отражаются основные сведения об используемой модели.
2.4. Нейромодифицированная одноиндексная модель Шарпа
Суть одного из существенных недостатков одноиндексной модели Шарпа заключается в том, что портфель ЦБ, рассчитываемый на основе данной модели, теряет свойства оптимальности в упреждающие моменты времени. В [31] это математически доказано. Потеря оптимальности обусловлена отсутствием в модели механизма учета прогноза. В [31] парировать данный недостаток предложено экспертным путем. В рамках нейромодифированной одноиндексной модели Шарпа (НМШ) [120, 146] в качестве эквивалента экспертных прогнозных оценок предлагается использовать искусственные нейронные сети (ИНС).
Математическое обоснование предлагаемой идеи состоит в следующем. В основу одноиндексной модели Шарпа положена регрессионная зависи-
72
мость (2.22), устанавливающая взаимосвязь между доходностью ЦБ, включаемой в инвестиционный портфель, и доходностью рыночного индекса [3]:
ri (t) = ai + birI (t) +ei (t) , |
(2.22) |
где ri (t) - доходность i-й ЦБ в момент времени t; |
rI (t) - доходность рыноч- |
ного индекса в момент времени t; ai , bi - оцениваемые параметры регрессионной модели; ei (t) - случайная погрешность.
Параметр ai , так называемый сдвиг (смещение), определяет составляющую доходности ЦБ, не зависящую от динамики рынка. Фактически данный параметр является мерой недооценки или переоценки соответствующей ЦБ
рынком. Положительное значение ai |
указывает на переоценку рынком данной |
||||
ЦБ, и наоборот. Он рассчитывается в соответствии с выражением |
|
||||
|
n |
n |
|
||
|
å yi |
β × åxi |
|
||
α = |
i =1 |
- |
i =1 |
, |
(2.23) |
|
|
||||
|
n |
n |
|
||
где yi - доходность рынка в i-й период времени; xi – доходность ЦБ в i-й период времени; n – количество периодов.
Параметр bi представляет собой чувствительность данной ЦБ к изменению рынка. Если b >1, то стоимость ЦБ изменятся быстрее, чем рыночный ин-
декс, и соответственно она является более рискованной, чем рынок в среднем. Если bi <0, то движение ЦБ обратно движению рынка. Оценивается параметр bi путем сопоставления данных о соотношении доходности рассматриваемой ЦБ и доходности рынка (индекса) за определенный период времени. При этом используется метод наименьших квадратов.
Введем в выражение (2.22) дополнительное слагаемое pikti . Тогда выражение (2.22) примет вид
ri (t) = ai + pikti + birI (t) +ei (t) , |
(2.24) |
где p - параметр оценки средней величины скачкообразных изменений ЦБ, kti - дихотомическая переменная.
Дихотомическая переменная kti принимает значение +1 в случае превышения фактической доходностью ЦБ трендового уровня, и значение –1 в противном случае [120]. В символьном виде это записывается следующим образом:
ì+1, |
eti |
³ 0ü |
|
|
|
|
|
(2.25) |
||
, t = 1,T , i =1,n . |
||||||||||
kti = í |
eti |
£ |
ý |
|||||||
î-1, |
0þ |
|
|
|
|
|
|
|||
В соответствии с (2.25) доходность ЦБ зависит от доходности индекса и скачкообразных изменений, которые имеют место в динамике самой ЦБ. Эти скачкообразные изменения можно интерпретировать как «риск – эффекты», ко-
73
торые не имеют объяснения внутри рынка, но которые в каждый момент времени оказывают воздействие на уровень доходности ЦБ, изменяя ее то в одну, то в другую сторону. Средняя величина этих изменений на историческом периоде равна величине оцененного параметра p [31].
Винтересах прогнозирования значений «риск – эффектов» предлагается использовать ИНС, которые способны запоминать значения p для аналогичных условий, имевших место в прошлые периоды времени. По своей сути знания экспертов, на основе которых они оценивают текущую ситуацию, аналогичны.
Только в данной модели в роли эксперта выступает ИНС [131, 140].
Вкачестве ИНС целесообразно использовать многослойный персептрон в совокупности с модифицированным обучающим алгоритмом обратного -рас пространения ошибок. При прочих равных условиях данная ИНС обеспечивает приемлемую точность и достаточно высокую оперативность обучения.
Технология применения НМШ заключается в следующем.
Впроцессе электронных торгов на бирже в различные моменты времени множество ИНС обучается, тестируется и ее параметры заносятся в соответствующую базу данных с целью последующего воспроизведения. Проведение этих действий особенно актуально в период протекания аномальных ситуаций. При наличии достаточно полной базы ИНС параметры текущей ситуации на рынке сравниваются с имеющимися, и для подобных условий из базы извлекается и инициализируется соответствующая ИНС или их множество. Полученные на ее (их) основе прогнозные значения используются при проведении текущей оценки соответствующей ЦБ.
Вслучае, если ИНС при работе на тестовом множестве и с реальными данными несколько раз подряд (более трех) формирует ошибочные результаты, предусмотрено ее отключение, что эквивалентно функционированию обычной одноиндексной модели Шарпа. Последнее важно для практики, поскольку исключает накопление ошибок.
Симбиоз ИНС, реализующей определение и оценку отклонений доходности ЦБ на упреждающем отрезке времени и НМШ, призван повысить точность последней. Если ИНС настроена и работает корректно, то точность модели повышается, в противном случае возможно достижение такого состояния, когда точность получаемых результатов будет соответствовать одноиндексной модели Шарпа без каких-либо модификаций (НМШ не должна работать хуже одноиндексной модели Шарпа).
Винтересах поддержки НМШ разработан специальный программный комплекс нейросетевого прогнозирования временных рядов(ПК НПВР). Его описание приведено в разделе 3.
Возможность обработки информации об инвестициях на основе генетическом алгоритме (ГА), для решения проблем «проклятия размерности» и «холмистости», послужила основанием для его включения в состав инструментов фундаментального инвестиционного анализа.
74

2.5. Модифицированный генетический алгоритм распределения инвестиций
Основные трудности применения большинства методов оптимизации нелинейных унимодальных функций связаны с проблемами«проклятия размерности» и «застревания» в локальных экстремумах [29, 57].
Одним из способов их преодоления является использование генетических алгоритмов (ГА). На основе механизма, представленного на рис. 2.8, они «выращивают» оптимальное решение.
Рис. 2.8. Механизм функционирования генетического алгоритма
ГА представляет собой одну из разновидностей случайного поиска[57], основанную на естественном отборе и размножении. Суть механизма его функционирования состоит в следующем. На первом этапе случайным образом формируется начальная популяция особей. В хромосоме (генотипе) каждой особи закодировано возможное решение задачи(фенотип). Качество каждого решения оценивается функцией приспособленности(фитнес-функцией). На втором
этапе осуществляется выбор особей и их скрещивание на основе оператора кроссовера. В результате формируется потомство, генетическая информация которого является результатом обмена хромосом родительских особей. На следующем этапе из особей вторичного потомства аналогичным образом форми-
75
руется новое поколение. В данном поколении могут встречаться мутанты– особи со случайно измененными генотипами. Последнее реализуется на основе генетического оператора мутации. Эволюция популяции состоит из последовательности таких поколений [27].
Постановка задачи принятия инвестиционных решений в терминах ГА и последовательность ее решения представляется следующим образом.
Пусть задана сложная целевая функция(ЦФ) - суммарный доход инвестора, зависящая от нескольких переменныхобъемов инвестиций в каждый проект. Требуется найти такие значения переменных, при которых ЦФ максимальна. Кроме того, заданы значения минимального и максимального объемов вложений в каждый из проектов, которые задают область изменения каждой из переменных.
Каждый вариант инвестирования (набор значений переменных) представляет собой особь. Его доходность - это приспособленность особи. В процессе эволюции приспособленность особей будет возрастать, что означает появлениие более доходных вариантов инвестирования. После остановки эволюции в некоторый момент времени и выбора наилучшей особи будет получено хорошее решение задачи.
Функционирование ГА, применительно к решаемой задаче, представляет собой следующую последовательность действий.
Работа ГА начинается с формирования начальной популяции [51, 220]:
P = {P , P ,...,P ,...,P |
} |
, |
||
1 2 |
j |
N |
|
|
где j = 0, 1, 2, … – номер генерации ГА; N – размер популяции (количество особей в ней), который не изменяется в течение работы всего алгоритма.
Каждая особь генерируется как случайная L-битная строка, где L — длина кодировки особи, она тоже фиксирована, для всех особей одинакова и состоит из генов:
Pi = {g1, g2 ,...,gn }.
При выборе способа кодирования должно выполняться следующее условие: должна быть возможность закодировать(с допустимой погрешностью) в хромосоме любую точку из пространства поиска. Невыполнение этого условия может привести как к увеличению времени эволюционного поиска, так и к невозможности найти решение поставленной задачи.
Как правило, в хромосоме кодируются численные параметры решения. Для этого возможно использование целочисленного и вещественного кодирования. В данной работе использовались оба метода кодирования информации.
Рассмотрим целочисленное кодирование. Хромосома представляет собой битовую строку, в которой закодированы параметры решения поставленной задачи. На рис. 2.9 показан пример кодирования 4-х 10-разрядных параметров в 40–разрядной хромосоме. Принято считать, что каждому параметру соответствует свой ген. Следовательно, хромосома состоит из 4-х 10-разрядных генов.
76

Рис. 2.9. Пример целочисленного кодирования хромосомы
Несмотря на то, что каждый параметр в хромосоме закодирован целым числом, ему могут быть поставлены в соответствие и вещественные числа. Ниже представлен один из вариантов прямого и обратного преобразования«целочисленный ген - вещественное число».
Если известен диапазон, в пределах которого лежит значение параметра, то этот диапазон разбивают на 2m отрезков, где m - разрядность гена, и каждому отрезку соответствует определенное значение гена. При этом для перевода значений из закодированного значения в дробные применяют следующие формулы:
r = g (xmax - xmin ) + xmin ,
2m -1
g = (r - xmin )(2m -1),
(xmax - xmin )
где r – вещественное (декодированное) значение параметра; g - целочисленное (закодированное) значение параметра; xmax и - максимальное и минимальное допустимое значение декодированного параметра [222, 223].
Вещественное кодирование позволяет исключить операции кодирования/декодирования, используемые в целочисленном кодировании, и увеличить точность найденного решения.
Пример вещественного кодирования хромосомы представлен на рис. 2.10. После того, как сформирована и закодирована популяция, ГА начинает циклическую работу. Каждый его шаг состоит из трех стадий: генерация проме-
жуточной популяции - скрещивание особей - мутация.
Рис. 2.10. Пример вещественного кодирования хромосомы
На рис. 2.11. изображены первые две стадии этого процесса. Промежуточная популяция — это набор особей, которые получили право размножаться. Приспособленные особи записываются несколько раз. «Плохие» особи исключаются из дальнейшего рассмотрения. Генерация промежуточной популяции представляет собой процесс выбораK*N хромосом популяции G(t) для даль-
77
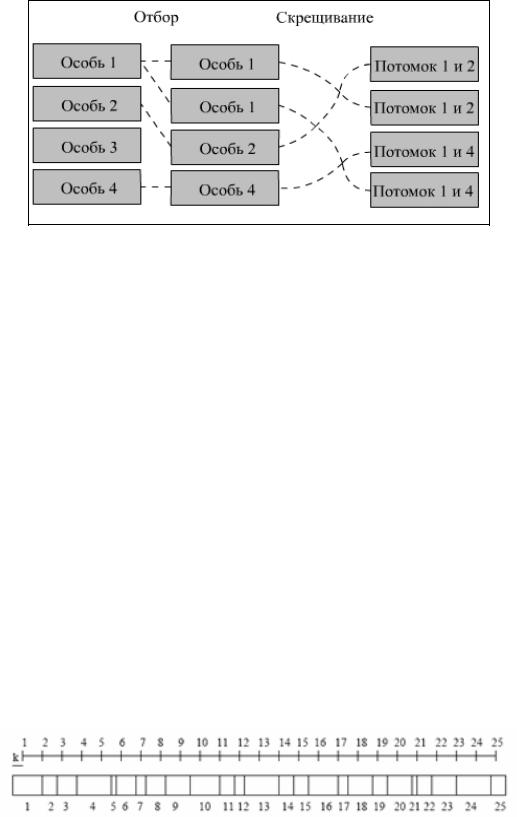
нейших генетических операций. Выбор производится случайным образом. Вероятность выбора S it хромосомы пропорциональна её ценности.
Рис. 2.11. Генерация промежуточной популяции и скрещивание особей популяции
Процесс выбора повторяется K*N раз. Предполагаемое количество экземпляров хромосомы S it в популяции G(t+1) равно
nвыб (Sit )= pвыб (Sit )* K * N .
Вероятность каждой особи попасть в промежуточную популяцию -про порциональна ее приспособленности, что соответствует пропорциональному отбору. Он реализуется несколькими способами.
Суть первого способа заключается в следующем. Пусть особи располагаются на колесе рулетки так, что размер сектора каждой особи пропорционален ее приспособленности. Изначально промежуточная популяция пуста. Запуская рулетку N раз, выберем требуемое количество особей для записи в промежуточную популяцию. Ни одна выбранная особь не удаляется с рулетки. Такой отбор называется стохастическим.
В другом способе отбора[238], который также является пропорциональным (см. рис. 2. 12), для каждой особи вычисляется отношение ее приспособленности к средней приспособленности популяции. Целая часть этого отношения указывает на число требуемых записей особи в промежуточную популяцию, а дробная - на вероятность ее неоднократного попадания. Реализуется данный способ следующим образом. Расположим особи на рулетке, как в первом способе. На рулетке естьN стрелок, отсекающих одинаковые сектора. Один запуск рулетки реализует выборN особей, которые записываются в промежуточную популяцию.
Рис. 2.12. Пример пропорционального отбора
78

Операция воспроизводства увеличивает общую ценность последующей популяции путём увеличения числа наиболее ценных строк.
Пусть в популяции G(t) содержится n(H, t) хромосом, удовлетворяющих схеме H. Тогда в результате воспроизводства количество хромосом, удовлетворяющих схеме H в популяции G(t+1), будет равно n(H, t+1):
n(H ,t ) |
(SiH ,t |
n(H , t = 1) = å(K * N * Pвыб |
|
i =1 |
|
n (H ,t ) |
|
åF (Sit |
|
)=) K * N * i =1 |
|
åN |
F (S tj |
j =1
) (2.26)
.
)
Используя выражения для средней ценности популяцииFср (GH (t)) и подпопуляции Fср GH (t), формулу (2.26) можно записать в виде
|
|
n ( H ,t ) |
|
|
|
|
|
|
n(H , t ) * |
å F (Sit ) |
|
|
|
(2.27) |
|
|
i =1 |
|
|
Fср (GH |
|||
n( H , t + 1) = K * |
|
n( H , t ) |
|
= n( H , t ) * K * |
(t )) |
||
|
|
|
|
. |
|||
N |
|
|
|
||||
|
|
t |
|
|
Fср (G (t )) |
||
|
å F (S j ) |
|
|
|
|
|
|
j =1
N
Средняя ценность подпопуляции, соответствующей схеме H, может быть
представлена в следующем виде:
Fср (GH (t))= Fср (G(t))+ c * Fср (G(t)),
где c – некоторая величина.
Тогда формула (2.27) примет вид
n(H,t +1) = n(H,t)* K *((Fcp (G(t))+ c * Fcp (G(t)))/ Fcp (G(t)))= (1+ c)* n(H , t)* K .
Предположим, что величина c при изменении t не изменяется. Тогда, начиная с t=0, получим
n(H ,t +1) = n(H ,0) * K * (1 + c)t ,
т.е. в этом случае число представителей схемы(хромосом популяции G(t), соответствующих схеме) изменяется в геометрической прогрессии. Следовательно, процесс изменения представителей схемы аппроксимируется геометрической прогрессией.
Таким образом, в результате операции воспроизводства те схемы, для которых соответствующие подпопуляции имеют среднюю ценность выше средней в популяции, увеличивают количество своих представителей.
Воспроизводство оперирует с хромосомами, уже присутствующими в рассматриваемой популяции, и само по себе не способно открывать новые области поиска. Для этой цели используется операция скрещивания.
Скрещивание представляет собой процесс случайного обмена значениями соответствующих элементов для произвольно сформированных пар хромосом. Для этого выбранные на этапе воспроизводства хромосомы случайным образом
79

группируются в пары. Далее каждая пара с заданной вероятностью подвергается скрещиванию. При скрещивании происходит случайный выбор позиции разделителя d (d=1, 2, ..., l-1, где l - длина строки). Затем значения первых d элементов первой хромосомы записываются в соответствующие элементы второй, а значения первых d элементов второй хромосомы– в соответствующие элементы первой. В результате получаем две новые хромосомы, каждая из которых является комбинацией частей двух родительских хромосом [227].
В работе применяется одноточечный оператор кроссовера(1-point crossover): для родительских хромосом (т. е. строк) случайным образом выбирается точка раздела, и они обмениваются отсеченными частями. Пример полученных таким способом двух хромосом, являющихся потомками, представлен на рис. 2.13.
Рис. 2.13. Результат работы оператора кроссовера
Операция скрещивания создаёт новые хромосомы путём некоторой комбинации значений элементов наиболее ценных в популяцииG(t) хромосом. Получившиеся в результате хромосомы могут превосходить по ценности родительские хромосомы.
Рассмотрим схему H, для которой определим порядок o(H) - число фиксированных позиций схемы и определяющую длинуd (H) - расстояние (число позиций) между первой и последней фиксированными позициями. Допустим, что до операции скрещивания хромосомыS была представителем схемы H, т.е S ÎUH . Допустим, что хромосома S1 получена из хромосомыS в результате скрещивания. Хромосома S1 будет представителем схемы H в том случае, если позиция разделителя при скрещивании не располагалась между фиксированными позициями схемы. Вероятность того, что позиция разделителя окажется между фиксированными позициями схемы, равна
pd = d (H ) . l - 1
80