

2444
.pdfРассмотренные алгоритмы предназначены для преобразования изображения, заданного функцией S (x, у). В дальнейшем будем считать, что задана функция яркости f (х, у), область определения которой представляет собой конечное или счетное множество действительных чисел. Рассмотрим основные алгоритмы предварительной обработки изображений, заданных в точках xi , уj дискретной функцией яркости f (х, у). Целью рассматриваемых алгоритмов является фильтрация изображения. Наиболее часто при этом применяют дискретное преобразование Фурье. Идея такого применения заключается в том, что, если характеристики шума известны, шум и полезный сигнал независимы, преобразование Фурье плотности суммарного сигнала равно произведению соответствующих преобразований плотности полезного сигнала и шума.
Дискретное преобразование Фурье функции f (х, у) можно записать в виде [27]
(1.18)
где Skl (u, w) в общем случае является комплексным числом.
В случае, если М = N, записанное двойное преобразование Фурье сводится к двум последовательным преобразованиям
где
69
Существенным недостатком применения дискретного преобразования Фурье является большой объем вычислений. Поэтому иногда с целью его сокращения используют менее точные, но более простые преобразования Адамара и Уолша [27]. Следует отметить важность решения задачи разработки методов предварительной обработки изображений. В современных СТЗ время, затрачиваемое на предварительную обработку, превышает время анализа примерно в 20 раз [23].
На следующем этапе обработки осуществляют сегментацию изображения, под которой принято понимать разбиение изображения на составные части: объекты, их фрагменты или характерные особенности. Этап сегментации является связующим между формированием изображения и его анализом. Для лучшего понимания задачи сегментации рассмотрим ее математическую формулировку [28, 29].
Пусть S (х, у) — функция яркости изображения, определенная на замкнутом множестве D; D = {D1, D2, … Dk }— разбиение D на k непустых связных подмножеств Di (i = 1, 2, ..., k); LP — предикат, определенный на множестве D, принимающий значение И (истина) тогда и только тогда, когда любая пара точек из каждого подмножества Di удовлетворяет некоторому критерию однородности.
Сегментацией изображения S(x, y) по предикату LP называется разбиение D*={ D*1, D*2, …, D*k}, удовлетворяющее условиям:
70
Предикат LP называется предикатом однородности. В частном случае предикат LP можно определить как
где (xm, ym) D*i, m = 1, 2, …, M, где М – число точек в области D*i , или
где (xm, ym), (xl , yl ) — произвольные точки из области D*i; Т — некоторый заданный порог.
Отсюда следует, что формально сегментация представляет собой оператор, задающий преобразование
S (х, у) → G (х, у), где  —имя i-й области, i = 1, 2,
—имя i-й области, i = 1, 2,
..., k.
Известны два подхода к решению задачи сегментации. Первый основан на выделении контура изображений, под которым понимается [25] совокупность видимых на плоском изображении границ между объектами и фоном, между различными объектами или между смежными поверхностями одного и того же объекта. В этом случае предикат LP должен принимать значение «Я» на граничных точках областей и значение «Л» — на остальных точках. Известны три основных метода выделения контура изображения [29].

1.Метод пространственного дифференцирования основан на том, что в точках контура модуль градиента функции S (х, у) принимает максимальные значения. В этом случае в каждой точке (х, у) вычисляется
|
|
|
(1.19) |
|
|
|
|
|
далее по заданному заранее пороговому значению А определяется функция |
|
|
|
|
|
|||
Поскольку на практике вместо функции S (х, у) задается функция яркости F (i, j), реализация метода |
||||||||
пространственного дифференцирования предполагает замену частных производных |
|
S(x, y) |
и |
S(x, y) |
|
|||
|
|
y |
||||||
|
|
|
|
|
x |
|||
дискретными |
оценками |
соответствующих |
производных F (i, j). |
При реализации метода |
||||
пространственного дифференцирования большое значение имеет решение проблемы выбора значения порога А. Обычно это делается на основе анализа гистограммы значений G (т, п).
2.Метод функциональной аппроксимации основан на том, что каждая точка изображения (х', у') Окружается некоторой окрестностью А, и в этой окрестности определяется ступенчатая функция [27]
(1.20)
где с, s, р, d, b — числовые параметры. Качество аппроксимации функции S (х, у) функцией ˆ (х, у, с,
S
s, p, d, b) в окрестности определяется метрикой
(1.21)
Если можно подобрать такие параметры с, s, р, d, b функции ˆ , что заданное качество
S
аппроксимации [величина d (S, ˆ ) ] обеспечивается, точка (х, у) лежит на контуре изображения. В
S 72
противном случае считается, что анализируемая точка не принадлежит контуру. Для определения параметров функции S используется так называемый оператор Хюккеля [27], основанный на разложении
функций S (х, у), ˆ (х, у, с, s, p, d, b) в ряд Фурье.
S
3. Метод высокочастотной фильтрации основан на том, что информацию о контуре объекта несут высокочастотные составляющие спектра изображений S (х, у). В этом случае необходимо получить преобразование Фурье функции S (х, у) и выделить его высокочастотную составляющую. Далее следует перейти в пространственную область и, используя сравнение с пороговым значением, получить бинарное контурное изображение.
Если F (p, q) — преобразование Фурье функции S (х, у), Н (р, q) — передаточная характеристика высокочастотного фильтра, FR-1 (F (p, q), H (p, q)) — оператор обратного преобразования Фурье, то изображение с резкими перепадами на краях определяется из соотношения С' (х, у) = FR-1 (Р(р, q), H (p, q)). Для перехода от С' (х, у) к контурному изображению следует воспользоваться сравнением с пороговым значением.
Рассмотренные методы выделения контура изображения реализуются на ЭВМ поразному. Реализация метода пространственной фильтрации приводит к большому объѐму вычислений. Наиболее часто на практике применяют метод пространственного дифференуирования.
Второй подход к решению задачи сегментации основан на концепции однородности точек изображения, лежащих в некоторой области, ограниченной контуром. Основными здесь являются методы пороговой обработки, наращивания областей и релаксационной разметки.
1.Метод пороговой обработки в простейшем его варианте основан на преобразовании S(х, у) → G (х, у), где
где k —число областей сегментации; λ0, ..., λk-1 — метки сегментированных областей; A0, ..., Ak-1 — упорядоченные значения порогов A0 < А731 < ... < Ak-1. Эти значения определяются на практике также по гистограмме значений G (m, n).
2. Метод наращивания областей предполагает выбор на плоскости изображения некоторого числа стартовых точек, размещенных определенным образом. Затем

производится анализ соседних точек. Если при этом выполняется некоторое условие
однородности, соседняя точка получает ту же |
метку, что |
и исходная. Потом |
рассматриваются соседи соседей и т. д. После |
того как каждая |
точка изображения |
получает соответствующую метку, процесс заканчивается. Этот метод удобно применять в тех случаях, когда заранее известны число сегментируемых областей и положение стартовых точек, отстоящих на достаточном расстоянии от границ областей. При этом должен использоваться относительно простой критерий однородности. Следовательно, успешное применение метода возможно лишь в случае достаточно простых изображений.
3. Метод релаксационной разметки является итерационным вероятностным методом. Суть его заключается в следующем. Если имеется некоторое множество объектов В = {Bl , B2, Вm) и множество классов объектов λ= (λ 1, λ2..., λm) вводится
|
n |
вероятность Pi j = Р{Bi є λj}. При этом считаем |
Pij 1 (события Bi j={Bi є λj} cоставляют |
j |
1 |
полную группу). В качестве меры зависимости событий Bi j и Bk l (i, k = 1, 2, ...,m; j, l = 1, 2, ..., n) вводятся так называемые коэффициенты совместимости Cijmk. Релаксационная разметка представляет собой итерационный процесс, в котором значение каждой вероятности Pi j уточняется. Такое уточнение происходит с использованием других значений Pm k и коэффициентов совместимости Cijmk.
В итоге получаются предельные значения вероятностей:
Выполнение последнего соотношения означает что объект Вi, относится к классу λk.
74
Значения Cijmk выбирают исходя из условия: — 1≤ Cijmk ≤1. При этом Cijmk = 1 означает сильную совместимость событий Bi j и Bm k , Cijmk —1 — их слабую совместимость, Cijmk = 0 означает, что события Bi j
и Bm k независимы.
Итерационный процесс строится таким образом, чтобы при большом значении Pmk и близком к единице значении Cijmk вероятность Pi j возрастала; при большом значении Pmk и значении Cijmk , близком к - 1, вероятность Pi j убывала; при малом значении Pmk и значении Cijmk , близком к нулю, вероятность Pi j существенно не изменялась.
Указанные требования выполняются для следующего рекурентного алгоритма:
(1.22)
Где  Такая схема применяется во многих конкретных алгоритмах сегментации. Известно, что достаточным
Такая схема применяется во многих конкретных алгоритмах сегментации. Известно, что достаточным
условием ее сходимости является существование предела |
Pik* lim P(l) |
, где l — номер итерации. |
|
ij |
|
|
l |
|
Реализуемость этого метода во многом зависит от того, насколько удачно выбраны значения коэффициентов
Cijmk.
Следующим этапом обработки является построение описания изображения, т. е. представление функции F(m, n) в виде совкупности количественных и качественных характеристик, образующих набор признаков, который в дальнейшем используется для распознавания объекта и его классификации, а также позволяет определить положение объектов и их ориентацию [25]. Отметим, что на этом этапе используется не само изображение т. е. функция F(m, n), а его код, представляющий информацию об изображении в сжатом виде. Кодирование производится в соответствии с основными положениями теории информации,
относящимися к нахождению оптимальных кодов. Так, при кодировании функции F(m, n) для часто
75
встречающихся значений используются более короткие коды, а для редко встречающихся — длинные. Можно кодировать также однородные в смысле значения F(m, n) отрезки строки-развертки, указав
значение яркости на данном отрезке и его длину. Такое кодирование позволяет по сравнению с функцией F(m, n) сократить в 5—10 раз объем информации, описывающей изображение.
Иногда для описания контура объекта или линии, на которой значение функции яркости F(m, n) постоянно, применяют так называемые цепные коды.
На рис. 1.20 приведен пример цепного кода контурной линии [25]. Каждая позиция такого кода указывает одно из восьми (0—8) возможных направлений перехода к соседнему элементу вдоль постоянного значения функции F (m,n).

Рис. 1.20. - Цепной кода контурной линии Анализ отфильтрованного изображения, прошедшего предварительную обработку и закодированного
заключается в определении его принадлежности к одному из заданных заранее классов объектов. Для такой классификации должна быть выделена некоторая система признаков, однозначно определяющих принадлежность визируемого объекта тому или иному классу. При выборе признаков учитываются
алгоритмы классификации и возможности датчиков изображения, простейшими являются геометрические
76
признаки, дающие некоторые универсальные инварианты объектов. В работе [30] предложены несколько признаков распознавания, основными из которых являются площадь объектов; максимальное, минимальное и среднее расстояния от центра инерции изображения до края; периметр изображения объекта; скорректированный периметр (с учетом веса каждой точки на крае изображения); координаты центров различных моментов инерции изображения; несколько начальных коэффициентов преобразования Фурье расстояния от центра инерции изображения до края; размеры минимального правильного геометрического тела, ограничивающего изображение.
Площадь изображения вычисляют подсчетом элементов дискретной функции яркости, отличных от нуля (т.е. входящих в состав изображения), периметр — после нахождения границ объекта [27].
Для определения координат центров отверстий, их радиусов и т. п. следует найти геометрический центр изображения, координаты которого x0, y0 определяются по формулам:
(1.23)
Где δij=1, если точка (xij или yij) принадлежит изображению, и δij=0 – в противном случае. Моменты инерции изображения определяются по функции яркости f(x, y) относительно главных осей инерции J1, J2 рассчитывают по формуле:
77
Здесь моменты инерции Jx и Jy относительно соответствующих осей координат вычисляются следующим образом:
(1.24)
В свою очередь xc, yc – координаты центра тяжести изображения:
где N — число элементов дискретного изображения.
Считается, что значения J1, J2 в наибольшей степени характеризуют принадлежность объекта определенному классу. Это означает, что другие признаки следует принимать во внимание лишь в том случае, когда вычисления значений J1, J2 таковы, что объект можно отнести сразу к двум или нескольким классам. Иногда используют так называемый лингвистический подход к описанию объектов, основанный на признаках, которые выделяются человеком эвристически при изучении свойств объектов (угол, стрелка, острие, тип пересечения и др.). Однако лингвистический подход не нашел широкого применения в СТЗ промышленных роботов и поэтому обычно ограничиваются заданием простых эвристических правил классификации объектов.
Рассмотренные геометрические признаки в большинстве случаев не обеспечивают полного описания визируемых объектов, достаточного для его классификации, и зачастую приходится использовать более сложные формальные инварианты, например,
78
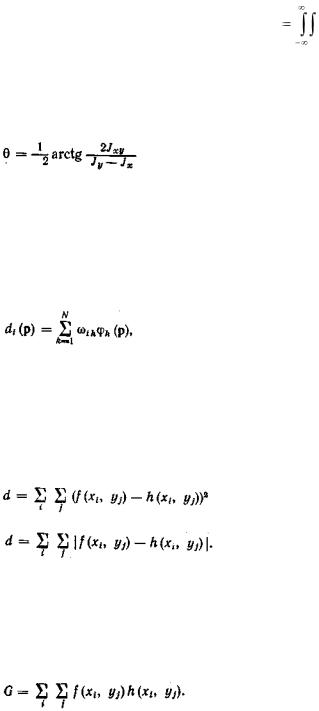
моментный функционал изображения Mp, q |
x p yq S(x, y)dxdy (на практике p=q=1; 2) и др. |
Если же и более сложные признаки не позволяют однозначно идентифицировать объект, следует усилить роль эвристических правил распознавания в рамках лигвистического подхода.
Для определения положения объекта в общем случае необходимо найти три значения координат его центра масс и три эйлеровых угла его ориентации в трехмерном пространстве. Если изображение двумерно то положение характеризуется двумя координатами центра масс xc, yc и углом наклона оси симметрии объекта к одной из координатных осей. Угол наклона оси объекта к оси х определяется по формуле
Витоге построения описания изображения каждый объект характеризуется упорядоченным вектором
признаков р = (р1, p2, …pn), который представляет собой точку в n-мерном пространстве признаков. Если заданы N классов объектов К1,K2, ..., Кn, то объект можно классифицировать методом дискриминирующих функций [25, 26], суть которого в общем случае состоит в вычислении значений N функций d1(р), d2(р),..., dN (p), таких, что для любого вектора р*є Ki , di (р*) > dj (р) при i ≠ j для всех j = 1, 2, ..., N. Дискриминирующая функция di (p*) (i = 1, 2, ..., N) выбирается таким образом, чтобы ошибка классификации была как можно меньше.
Вчастности, такой выбор делается с помощью специальной процедуры обучения [25], когда дискриминирующая функция представляется в виде
где ωi k — коэффициенты; φk (p) — заранее заданные функции (чаще всего полиномы). Оценки коэффициентов ωi k могут быть получены на основе анализа достаточно большого числа объектов, принадлежность которых к тому или иному из заданных классов известна заранее.
Частным случаем метода дискриминирующих функций является сравнение с эталоном. Поскольку объект практически всегда отличается от любого из эталонов, необходимо задать некоторую числовую
характеристику этого отличия. Тогда принадлежность визируемого объекта тому или иному классу опреде79
ляется по минимуму этой характеристики. Если f (х, у) — изображение, a h (x, у) — эталон, то характеристика отличия (расстояние от объекта до эталона) находится, как правило, по одной из следующих формул:
или
Для проверки совпадения с эталоном задают некоторое пороговое значение А. Если d < А, считают, что объект совпадает с эталоном, в противном случае — нет. Тогда изображение сравнивается с другим эталоном и т. д. В общем случае все множество признаков располагается по степени важности, что соответствует порядку сравнения.
В некоторых случаях для сравнения с эталоном применяют корреляционный метод, основанный на вычислении корреляционной функции эталона и изображения. Тогда большему значению функции соответствует более высокая вероятность принадлежности изображения соответствующему классу. Значение этой функции определяется по формуле
Следует отметить, что сравнение изображения с эталоном требует их одинаковой ориентации и совмещения. Чтобы совместить в пространстве изображение и эталон, необходимо, во-первых, совместить центры их масс, во-вторых, расположить их так, чтобы три угла, задающие ориентацию, были равны. При этом для определения центра масс изображения используют функцию яркости f (х, у). Чаще всего эта процедура существенно упрощается, поскольку изображение является плоским.
В качестве примера другого подхода к решению проблемы идентификации необходимо указать группу так называемых структурно-синтаксических методов [25], основанных на структурных отношениях между простейшими фрагментами изображения объекта. Эти методы используют известные структуры дискретной математики: формальные грамматики80 , графы, сети и др.
Мы рассмотрели методы обработки одномерных и двумерных изображений, которые широко применяются для обнаружения дефектов поверхностей различных изделий, некоторых измерений и т. д. Более сложные задачи, возникающие при автоматизации сортировки деталей, извлечения из бункера, контроля сборочных операций, приводят к необходимости обработки трехмерных изображений [31]. В системах обработки трехмерной информации, а также для оптических измерений расстояний широко используются лазерные дальномеры. Лазер представляет собой идеальный источник света для измерения расстояний и проверки качества поверхности детали. Чтобы из двумерного изображения получить
трехмерное, необходимо каждой ячейке двумерной матрицы освещенности поставить в соответствие еще одну характеристику (например, расстояние от ячейки до телекамеры).
81
81

ГЛАВА 2. ХАРАКТЕРИСТИКИ ИЗОБРАЖЕНИЙ
В этой главе мы исследуем черно-белые (бинарные) изображения. Их легче получать, хранить и обрабатывать, чем изображения, в которых имеется много уровней яркости. Однако, поскольку в бинарных изображениях кодируется информация лишь о силуэте объекта, область их применения ограничена. В дальнейшем будут сформулированы условия, необходимые для успешного использования методов обработки бинарных изображений. Здесь же внимание акцентируется на таких простых геометрических характеристиках изображений, как площадь объекта, его положение и ориентация. Подобные величины могут использоваться, например, в процессе управления механическим манипулятором при его работе с деталями. Другие аспекты, касающиеся бинарных изображений, например методы итеративной модификации, обсуждаются в следующей главе.
Поскольку изображения содержат большой объем информации, важную роль начинают играть вопросы ее представления. Мы покажем, что интересующие нас геометрические характеристики можно извлечь из проекций бинарных изображений. Проекции гораздо легче хранить и обрабатывать. В большей части данной главы речь пойдет преимущественно о непрерывных бинарных изображениях, характеристическая функция которых равна нулю или единице в каждой точке плоскости изображения. Это упрощает анализ; однако при использовании ЭВМ изображение необходимо разбить на дискретные элементы. Глава заканчивается обсуждением дискретных бинарных изображений и путей уменьшения затрат на передачу, хранение и обработку данных посредством учета пространственных взаимосвязей между элементами.
2.1. Геометрические характеристики бинарных изображений Начнем со случая, когда в поле зрения находится единственный объект а все
остальное считается «фоном». Если объект оказывается заметно темнее (или светлее), чем
83
фон, то легко определить характеристическую функцию b(х, у), которая равна нулю для всех точек изображения, соответствующих фону, и единице для точек на объекте (рис. 2.1)
Рис. 2.1. Бинарное изображение, определяемое характеристической функцией b(х, у), которая принимает значение «нуль» или «единица».
Часто бинарное изображение получают пороговым разделением обычного изображения. К нему также можно прийти путем порогового разделения расстояния на «изображении», полученном на основе измерений расстояния.

Такую функцию, принимающую два значения и называемую бинарным изображением, можно получить пороговым разделением полутонового изображения. Операция порогового разделения заключается в том, что характеристическая функция полагается равной нулю в точках, где яркость больше некоторого порогового значения, и
единице, где она не превосходит его (или наоборот).
84
Иногда бывает удобно компоненты изображения, а также отверстия в них рассматривать как множества точек. Это позволяет комбинировать изображения с помощью теоретико-множественных операций, например объединение и пересечение. В других случаях удобно поточечно использовать булевы операции, подобные логическому и (/\ ) и логическому или (\/). На самом деле это лишь два различных способа описания одних и тех же действий над изображениями.
Поскольку количество информации, содержащееся в бинарном изображении, на порядок меньше, чем в совпадающем с ним по размерам полутоновом изображении, бинарное изображение легче обрабатывать, хранить и пересылать. Естественно, определенная часть информации при переходе к бинарным изображениям теряется, и, кроме того, сужается круг методов обработки таких изображений. В настоящее время существует достаточно полная теория того, что можно и чего нельзя делать с бинарными изображениями, чего, к сожалению, нельзя сказать о полутоновых изображениях.
Прежде всего мы можем вычислить различные геометрические характеристики изображения, например размер и положение объекта. Если в поле зрения находится более одного объекта, то можно определить топологические характеристики имеющейся совокупности объектов: например, разность между числом объектов и числом отверстий. Нетрудно также пометить отдельные объекты и вычислить геометрические характеристики для каждого из них в отдельности. Наконец, перед дальнейшей обработкой изображение можно упростить, постепенно модифицируя его итеративным образом.
Обработка бинарных изображений хорошо понятна, и ее нетрудно приспособить под быструю аппаратную реализацию, но при этом нужно помнить об ограничениях. Мы уже упоминали о необходимости высокой степени контраста между объектом и фоном. Кроме того, интересующий нас образ должен быть существенно двумерным. Ведь все, чем мы располагаем, — лишь очертания85или силуэт объекта. По такой информации трудно судить о его форме или пространственном положении.
Характеристическая функция b (х, у) определена в каждой точке изображения. Такое изображение будем называть непрерывным. Позже мы рассмотрим дискретные бинарные изображения, получаемые путем подходящего разбиения поля изображения на элементы.
2.1.1. Простые геометрические характеристики
Допустим снова, что в поле зрения находится лишь один объект. Если известна характеристическая функция b(х, у), то площадь объекта вычисляется следующим образом:
A  b(x, y)dxdy,
b(x, y)dxdy,
I
где интегрирование осуществляется по всему изображению I. При наличии более одного объекта эта формула дает возможность определить их суммарную площадь.
2.1.2. Площадь и положение
Как определить положение объекта на изображении? Поскольку объект, как правило, состоит не из одной единственной точки, мы должны четко определить смысл термина «положение». Обычно в качестве характерной точки объекта выбирают его геометрический центр (рис. 2.2). Геометрический центр — это центр масс однородной фигуры той же формы. В свою очередь центр масс определяется точкой, в которой можно
86

сконцентрировать всю массу объекта без изменения его первого момента относительно любой оси. В двумерном случае первый момент относительно оси х рассчитывается по формуле
|
b(x, y)dxdy |
xb(x, y)dxdy, |
x |
||
|
I |
I |
Рис. 2.2. Положение области на бинарном изображении, которое можно определить ее геометрическим центром, который представляет собой центр масс тонкого листа материала той же формы.
а относительно оси у — по формуле
|
b(x, y)dxdy |
yb(x, y)dxdy, где (х, у) – координаты геометрического центра. |
y |
||
|
I |
I |
Интегралы в левой части приведенных соотношений — не что иное, как площадь А, о которой речь шла выше. Чтобы найти величины х и у, необходимо предположить, что величина А не равна нулю. Заметим попутно, что величина А представляет собой момент нулевого порядка функции b(х,у).
2.1.3. Ориентация
Мы также хотим определить, как расположен объект в поле зрения, т. е. его ориентацию. Сделать это несколько87 сложнее. Допустим, что объект немного вытянут вдоль некоторой оси; тогда ее ориентацию можно принять за ориентацию объекта (рис. 2.3). Как точно определить ось, вдоль которой вытянут объект? Обычно выбирают ось минимального второго момента. Она представляет собой двумерный аналог оси наименьшей инерции. Нам необходимо найти прямую, для которой интеграл от квадратов расстояний до точек объекта минимален; этот интеграл имеет вид
E |
r 2b(x, y)dxdy, |
|
I |
где |
r — расстояние вдоль перпендикуляра от точки с координатами |
(х, у) до искомой прямой.

Рис. 2.3. Ориентация области на изображении, определяемая направлением оси наименьшей инерции.
Она представляет собой ось, относительно которой момент инерции тонкого листа материала той же формы минимален.
Положение прямой на плоскости задается двумя параметрами. Удобной парой параметров служат расстояние р от начала координат до прямой и угол 0 между прямой и осью х, измеренный против часовой стрелки (рис. 2.4). Мы выбрали эти параметры потому, что при сдвигах и поворотах системы координат они меняются непрерывно. Кроме того, не возникает проблем88, когда прямая параллельна или почти параллельна одной из координатных осей.
Спомощью этих параметров уравнение прямой записывается в виде х sinΘ — у cosΘ +
р= 0, причем сразу отметим, что прямая пересекает ось х в точке с абсциссой - p/sinΘ, а ось у - в точке с ординатой + p/cosΘ. Ближайшая к началу координат точка прямой имеет координаты (-psinΘ, +pcosΘ). Параметрические уравнения для точек прямой
Рис. 2.4. Два удобных параметра для идентификации заданной на плоскости прямой (это угол наклона Θ по отношению к оси х и расстояние р вдоль перпендикуляра от начала координат до прямой)
89