

Учебное пособие 1747
.pdfквадратные скобки означают включение границы в интервал; круглые скобки - игнорирование граничного значения.
Достаточно часто в ряд вводится графа, в которой подсчитываются накоп-
ленные частоты - Si. Накопленные (кумулятивные) частоты показывают,
сколько единиц совокупности имеют значение признака не больше, чем данное значение, и исчисляются путем последовательного прибавления к частоте первого интервала частот последующих интервалов, т.е. S1=f1,S2=S1+f2 и т.д.
Накопленная частота последнего интервала равна общему объему совокупности – N.
Частоты ряда fi могут быть заменены частостями (wi) – относительными частотами. Частость определяется по формуле
wi fi f .
Таблица 4
Группировка данных и построение вариационного ряда
xi |
fi |
wi |
Si |
|
|||
20 .. 30 |
|
|
|
|
|
|
|
30 .. 40 |
|
|
|
|
|
|
|
40 .. 50 |
|
|
|
|
|
|
|
50 .. 60 |
|
|
100 |
|
|
|
|
|
|
100 |
— |
|
|
|
|
Если расчеты выполнены без ошибок, сумма частостей будет равна 100 %. Замена частот частостями позволяет сопоставлять вариационные ряды с
различным числом наблюдений.
Накопленная частота также может быть выражена в процентах, если для ее расчета используется не частота, а частость: S1=w1, S2=S1+w2 и т.д.
При таком варианте расчета накопленная частота последнего интервала равна 100 %.
Следующим этапом после построения вариационного ряда является его графическое изображение, которое облегчает анализ и позволяет судить о форме распределения. Для графического изображения вариационного ряда в статистике строят гистограмму, полигон и кумуляту распределения.
Гистограмма – столбиковая диаграмма, для построения которой на оси абсцисс откладывают отрезки, равные величине интервалов вариационного ряда. На отрезках строят прямоугольники, высота которых в принятом масштабе по оси ординат соответствует частотам (или частостям) (рис. 1).
Полигон частот – изображение вариационного ряда с помощью ломаной линии. Для построения полигона достаточно соединить отрезками прямых ли-
11
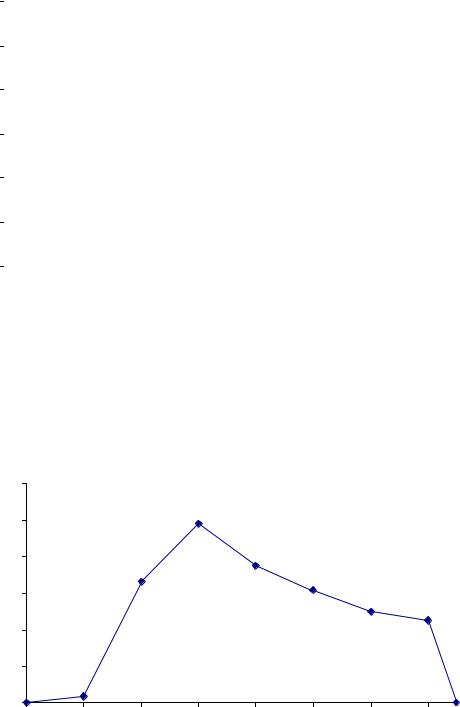
ний середины верхних сторон прямоугольников (рис.2).
f |
i |
30 |
|
|
|
|
|
|
f |
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
25 |
|
|
|
|
|
|
24,6 |
|
f4 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
f2 |
|
|
|
f5 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
20 |
|
|
|
|
|
|
|
|
18,8 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
16,5 |
|
|
|
|
|
|
f |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
15,4 |
6 |
|
f7 |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
15 |
|
|
|
|
|
|
|
|
|
|
12,5 |
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11,3 |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 |
|
f |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
x |
2 |
x |
|
x |
4 |
x |
x |
6 |
x |
7 |
x |
8 |
|||
|
|
|
1 |
|
3 |
|
|
5 |
|
|
|
|||||||
Рис. 1. Гистограмма ряда распределения
Крайние точки полученного графика соединяют с точками по оси абсцисс, отстоящими в принятом масштабе на величину интервалов от середины первого и последнего интервалов.
Число жителей, в % к итогу (w)
30 |
|
|
|
|
|
|
|
25 |
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
15 |
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
0,5 |
1 |
1,5 |
2 |
2,5 |
3 |
3,5 |
Среднедушевой доход, тыс. руб. (x)
Рис. 2. Полигон распределения
12

Кумулята распределения строится по накопленным частотам (частостям). При построении кумуляты интервального ряда нижней границе первого интервала соответствует нулевая частота (частость), верхней – вся частота (частость) первого интервала. Верхней границе второго интервала – сумма частот (частостей) первого и второго интервалов и т.д. Верхней границе последнего интервала
– сумма накопленных частот (частостей) во всех интервалах, что соответствует общей численности изучаемой совокупности или 100 % (рис. 3).
Si , % |
100 |
50 |
0 |
Рис. 3. Кумулята распределения |
Задача 3. Расчет параметров ряда распределения
По сгруппированным данным и графикам из задачи 2 определите:
•среднее арифметическое;
•моду;
•медиану;
•первую и девятую децили;
•коэффициент децильной дифференциации. Сравните результаты с решением Задачи 1.
Методика решения
При расчетах по группированным данным учитывается частота появления каждого варианта (табл. 4). Среднее значение - средняя арифметическая взвешенная:
|
|
m |
|
|
|
|
xi fi |
|
|
x |
|
i 1 |
, |
|
m |
||||
|
|
|
||
|
|
fi |
|
|
|
|
i 1 |
|
13

где xi – варианты признака; fi – частоты (частости).
При расчете средней величины интервального ряда в качестве вариантов
признака используются значения середины интервалов – xi' .
Таблица 5
Расчет среднего значения
xi |
xi' |
fi |
xi' fi |
10 .. 20 |
15 |
|
|
|
|
|
|
.. |
|
|
|
|
|
|
|
50 .. 60 |
55 |
|
|
|
|
|
|
|
— |
|
|
|
|
|
|
Можно при расчете средней величины в качестве весов использовать частости распределения. Величина средней от этого не меняется.
Мода – значение признака, наиболее часто встречающееся в изучаемой совокупности, т.е. это одна из вариант признака, которая в ряду распределения имеет наибольшую частоту (частость). Для интервального ряда мода - это координата основания самого высокого столбика гистограммы, т.е. модального интервала. В качестве оценки моды используют не середину модального интервала, а скорректированное значение (рис. 4).
fi
Мо |
xi |
Рис. 4. Графическое определение моды |
|
Значение моды по сгруппированным данным также можно определить по формуле
Мо xМо hMo |
|
|
|
fMo fMo1 |
|
|
|
. |
||
( f |
Mo |
f |
Mo1 |
) ( f |
Mo |
f |
Mo1 |
) |
||
|
|
|
|
|
|
|
||||
14

где xMo - нижняя граница модального интервала; hMo – величина модального интервала; fMo, fMo–1, fMo+1 - частоты (частости) соответственно модального, предмодального и послемодального интервалов.
Модальный интервал – это интервал, имеющий наибольшую частоту (частость).
Для определения медианного значения признака в интервальном ряду сначала находят номер медианы:
N Me n 1, 2
где n – объем совокупности.
После чего определяют медианный интервал, т.е. интервал, в котором находится порядковый номер медианы N Me . С этой целью определяют, накопленная частота какого интервала первой превышает номер медианы.
|
|
|
|
Таблица 6 |
|
Пример. Пусть есть следующий интервальный ряд: |
|
|
|||
|
|
|
|
|
|
xi |
fi |
wi, % |
Si(fi) |
Si(wi), % |
|
|
|
|
|
|
|
20 .. 30 |
10 |
20 |
10 |
20 |
|
30 .. 40 |
16 |
32 |
26 |
52 |
|
40 .. 50 |
17 |
34 |
43 |
86 |
|
50 .. 60 |
7 |
14 |
50 |
100 |
|
|
50 |
100 |
— |
— |
|
|
|
|
|
|
|
NMe = 25,5 или NMe = 50 %, т.е. медиане соответствует среднее из двух значений, стоящих под номерами 25 и 26 в упорядоченном вариационном ряду, или 50 % совокупности.
Найдем медианный интервал. Накопленная частота первого интервала S1=10, S1 < 25,5; значит, в этом интервале лежит 10 единиц упорядоченного вариационного ряда и нет медианного значения. Накопленная частота второго интервала S2 =26, S2 >25,5; значит, в первом и втором интервалах находится 26 единиц упорядоченного вариационного ряда, в том числе и медиана. Таким образом, мы определили медианный интервал – [30 - 40].
К такому же результату мы придем, если будем искать медианный интервал по накопленным частостям. Накопленная частость второго интервала S2=52 %, что больше NMe = 50 %, значит, именно в нем находится медиана.
Точное значение медианы для сгруппированных данных рассчитываем по формуле
1 |
m |
|
||
fi SMe 1 |
|
|||
|
|
|
|
|
Ме xМе hMе |
|
2 i 1 |
, |
|
|
fMe |
|||
|
|
|
|
|
15

где xMe – нижняя граница медианного интервала; hMe – величина медианного интервала; SMe–1 – накопленная частота (частость) предмедианного интервала, fMe - частота (частость) медианного интервала.
Медиану также можно найти графически, используя кумуляту распределения (рис. 5).
Рис. 5. Графическое определение медианы
Оценки моды и медианы, полученные по результатам группировки, могут отличаться от оценок показателей, полученных без группировки. Группировка данных - это обобщение, укрупнение, при котором могут теряться отдельные мелкие подробности, но зато становится видна «картина в целом».
К структурным характеристикам, кроме моды и медианы, относятся и другие порядковые статистики: квартили Qi – делящие ряд на 4 равные части, децили Di – делящие ряд на 10 частей и др.
Остановимся на расчете показателей децилей, нашедших широкое применение в анализе дифференциации различных социально-экономических явлений.
Общая схема расчета децилей следующая:
1) поскольку децили отсекают десятые части совокупности, по накопленным частостям определяем интервалы, куда попадают порядковые номера децилей: для первой децили - интервал, где находится вариант, отсекающий 10 % совокупности с наименьшими значениями признака; для второй – 20 % и т. д.; для девятой децили - интервал, содержащий вариант, отсекающий 90 % с наименьшими значениями, или, что то же самое, 10 % с наибольшими значениями признака;
2) рассчитываем величину децилей по формулам, аналогичным формуле для нахождения медианы. Например, первая и девятая децили находятся по формулам:
|
1 |
m |
|
|
|
fi SD1 1 |
|
||
|
|
|
|
|
D1 xO |
10 i 1 |
; |
||
hD1 |
fD1 |
|||
D1 |
|
|
|
|
|
|
|
|
|
16

|
|
|
|
|
|
9 |
m |
|
|
|
|
|
|
|
fi |
SD9 1 |
|
|
|
|
|
|
|
|
||
|
|
|
|
D9 xO |
hD9 |
10 i 1 |
, |
|
|
|
|
|
D 9 |
|
|
fD9 |
|
|
|
|
|
|
|
|
|
|
где xO |
D1 |
, xO |
D 9 |
- начала интервалов, где находятся первая и девятая децили; |
||||
|
|
|
|
|
|
|
||
hD1 , hD9 - |
величины интервалов, где находятся первая и девятая децили; |
|||||||
m |
|
|
|
|
|
|
|
|
fi - общая сумма частот (частостей); |
SD1 1 , |
SD9 1 - суммы накопленных |
||||||
i1 |
|
|
|
|
|
|
|
|
частот (частостей) интервалов, предшествующих тем, в которых находятся
первая и девятая децили; f D1 , f D9 - частоты (частости) интервалов, содер-
жащих первую и девятую децили.
Соотношение децильных доходов в социальной статистике получило на-
звание коэффициента децильной дифференциации доходов населения KD:
K D D9 .
D1
Задача 4. Аналитическая группировка
Проведите аналитическую группировку Y и Z, используя X и Y как факторные признаки, для выявления зависимостей Y(X), Z(X), Z(Y). Сделайте выводы.
Методика решения
Аналитическая группировка данных - это деление совокупности на группы единиц по какому-либо признаку с целью выявления зависимости. Такой признак называют факторным или группировочным. Группировка позволяет оценить характер зависимости между переменными путем вычисления условного среднего.
Построение аналитических группировок проходит следующие этапы:
выбор группировочного признака;
определение необходимого числа групп, на которые необходимо разбить изучаемую совокупность;
установление границ интервалов группировки;
составление аналитической группировки.
Выбор группировочного признака является одним из существенных и сложных вопросов теории статистической группировки и статистического исследования в целом. От правильного выбора группировочного признака зависят выводы статистического исследования. В качестве основания группировки необходимо использовать признаки, наиболее полно отражающие сущность изу-
17
чаемых социально-экономических явлений и процессов в условиях поставленных целей и задач.
Для целей настоящей курсовой работы в качестве группировочного признака мы выбрали X и Y.
Определение числа групп и границ интервалов было подробно рассмотрено в задаче 2. После расчета этих величин можно переходить к составлению вспомогательной таблицы для аналитической группировки (табл. 7).
Таблица 7 Вспомогательная таблица для аналитической группировки
Номер |
Группы |
|
Номер единицы со- |
xi |
yi |
группы |
по факторно- |
|
вокупности, попав- |
||
|
|
|
|||
|
му признаку |
|
шей |
|
|
|
|
|
в интервал |
|
|
1 |
[ x1 ; x1 h ] |
4 |
x4 |
y4 |
|
|
29 |
||||
|
|
|
x29 |
y29 |
|
|
|
|
12 |
||
|
|
|
30 |
x12 |
y12 |
|
|
|
|
||
|
|
|
|
x30 |
y30 |
|
Итого |
|
f1 =4 |
xi |
yi |
|
|
|
|||
… |
… |
|
… |
… |
… |
|
Итого |
|
f j |
xi |
yi |
|
|
|
|||
m |
[ xm ; xm h |
] |
2 |
x2 |
y2 |
|
5 |
||||
|
|
|
10 |
x5 |
y5 |
|
|
|
|
x10 |
y10 |
|
Итого |
|
fm =3 |
xi |
yi |
|
|
|
|||
|
Всего |
|
N |
N |
N |
|
|
|
|
xi |
yi |
|
|
|
|
1 |
1 |
|
|
|
|
|
|
По каждой группе (интервалу) в этой таблице необходимо отметить номера единиц совокупности, попадающих в указанный интервал, а также выписать со-
ответствующие им значения факторного xi и результативного yi признаков. После этого производится расчет суммарных показателей по каждой группе: ко-
личество единиц в группе f j , суммарное значение факторного признака xi
18
и суммарное значение результативного признака yi .
Для установления наличия связи на основе данных вспомогательной таблицы построим итоговую аналитическую группировку, для чего перейдем от суммарных показателей по группам к средним величинам (табл. 8).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 8 |
||||||
|
|
|
|
|
Аналитическая группировка |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Х |
|
|
|
|
|
|
|
|
|
|
Y |
|
|
|
|
|
|
||||
|
Группы по |
|
|
Сумма |
|
|
|
|
Групповая |
|
Сумма |
|
|
|
|
Групповая |
||||||||||||||||
|
|
|
|
|
|
|
|
средняя |
|
|
|
|
|
|
средняя |
|||||||||||||||||
№ |
|
|
по |
|
|
|
|
|
|
по |
|
|
|
|
|
|||||||||||||||||
факторному |
Частота |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
п/п |
группе |
|
|
|
|
|
|
|
|
xi |
|
группе |
|
|
|
|
|
|
|
|
yi |
|||||||||||
признаку |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
x j |
|
|
|
y j |
|||||||||||||||||||||||
|
|
|
|
|
|
xi |
|
|
f j |
|
yi |
|
|
f j |
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
1 |
[ x1 |
; x1 |
h ] |
f1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
… |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
… |
|
… |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
h ] |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
[ xm ; xm |
fm |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
m |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
j f j |
|
|
|
|
|
|
|
|
|
|
|
j f j |
||||
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
x |
|
N |
|
|
|
|
|
|
|
x |
||||||||
|
|
Итого |
N |
|
xi |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
yi |
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
1 |
|
|
|
|
m |
|
1 |
|
|
|
|
m |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
f j |
|
|
|
|
|
|
|
|
|
|
f j |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Групповые средние по факторному признаку в этой таблице расположены в порядке возрастания. Как же ведет себя результативный признак при увеличении факторного? Если также растет, то налицо прямая зависимость между признаками. Если убывает, то связь – обратная. Если тенденция не видна, т.е. групповые средние по результативному признаку померено увеличиваются и уменьшаются, то однозначного вывода о наличии зависимости сделать нельзя.
Пример. Пусть составлена следующая аналитическая группировка для выявления зависимости суммы выданных кредитов от размера процентной ставки (табл. 9).
Мы видим, что по мере возрастания средней процентной ставки (12,7; 15,5; 18,0; 21,1; 24,5) происходит снижение средней суммы выданных кредитов (25,9; 19,25; 12,73; 7,1; 2,25), а значит, налицо обратная зависимость между этими показателями.
19
Таблица 9 Зависимость суммы выданных кредитов от размера процентной ставки
|
Группы бан- |
|
Процентная ставка |
Сумма выданных |
|||
|
|
кредитов, млн руб. |
|||||
|
ков по вели- |
|
|
|
|||
№ |
Число |
|
|
|
|
||
|
|
|
в сред- |
||||
чине про- |
|
средняя |
|
||||
п/п |
банков |
|
|
нем на |
|||
центной |
всего |
процентная |
всего |
||||
|
|
один |
|||||
|
ставки |
|
|
ставка |
|
||
|
|
|
|
банк |
|||
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
1 |
11 – 14 |
4 |
50,7 |
12,7 |
103,5 |
25,9 |
|
2 |
14 – 17 |
7 |
108,8 |
15,5 |
134,75 |
19,25 |
|
3 |
17 – 20 |
10 |
179,7 |
18,0 |
127,32 |
12,73 |
|
4 |
20 – 23 |
6 |
126,8 |
21,1 |
42,75 |
7,1 |
|
5 |
23 - 26 |
3 |
73,6 |
24,5 |
6,75 |
2,25 |
|
|
|
|
|
|
|
|
|
|
Итого |
30 |
539,6 |
18,0 |
415,07 |
13,8 |
|
|
|
|
|
|
|
|
|
Задача 5. Алгоритм выбора средней степенной величины
1.Затраты предприятия на производство i-го вида продукции составляют Зi=0,01xGixi2, где xi – объем производства i-го вида продукции. Предприятие выпускает n=5 видов продукции. Определить среднее значение объема выпуска для i=1, 2, …, 5. Обоснуйте выбор вида средней.
2.На выполнение технологической операции первый рабочий потратил x5 мин, а второй — x6 мин. Определить среднее время, затрачиваемое на выполнение данной операции в течение 8-часового рабочего дня и обосновать выбор вида средней.
3.Используя данные об объеме промышленного производства Воронежской области за последние 5 лет, определить темпы роста и средний темп роста объемов производства.
(Данные брать с официального сайта Федеральной службы государственной статистики по Воронежской области http://www.voronezhstat.gks.ru).
Методика решения
Для выбора вида средней степенной величины возможно использование следующего алгоритма:
1.Определить цели и задачи вычисления средней степенной величины.
2.Определить определяющий показатель и формулу его расчета.
3.Выбрать вид средней степенной величины исходя из правила: значение определяющего показателя не должно измениться при замене индивидуальных значений признака на среднее значение.
Пример. Необходимо осуществлять контроль за фондом заработной платы предприятия, если известна средняя зарплата по каждому подразделению xj, численность каждого подразделения nj и число структурных подразде-
20