


Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
1.5. Контрольные задачи
Задача 1.8. Хронометражными наблюдениями установлено количество рейсов в смену х, которое совершают автосамосвалы при вывозке песка из карьера. Построить вариационный ряд распределения для количества рейсов. Рассчитать показатели вариации, структурные средние, коэффициент Джини, децильный коэффициент дифференциации.
Таблица 1.12
Распределение автосамосвалов по количеству рейсов в смену (дискретный вариационный ряд)
Значения |
30 |
31 |
32 |
33 |
34 |
35 |
36 |
37 |
Частота |
2 |
5 |
8 |
9 |
11 |
8 |
5 |
2 |
Частость |
0,04 |
0,10 |
0,16 |
0,18 |
0,22 |
0,16 |
0,10 |
0,04 |
Задача 1.9. Для статистического анализа контроля качества на заводе ЖБК были произведены замеры геометрических величин размеров железобетонных изделий. Построить интервальный вариационный ряд изменения длины изделия. Рассчитать показатели вариации, структурные средние, коэффициент Джини, децильный коэффициент дифференциации.
Таблица 1.13
Распределение ЖБИ по размерам (интервальный вариационный ряд)
Интервалы |
Середина |
Частота, |
Накопленные |
длины, мм |
интервала |
fi |
(кумулятивные) |
|
|
|
частоты fiнак |
964,5-967,5 |
966 |
5 |
5 |
967,5-970,5 |
969 |
11 |
16 |
970,5-973,5 |
972 |
17 |
33 |
973,5-976,5 |
975 |
23 |
56 |
976,5-979,5 |
978 |
18 |
74 |
979,5-982,5 |
981 |
10 |
84 |
982,5-985,5 |
984 |
8 |
92 |
985,5-988,5 |
987 |
3 |
95 |
Итого |
|
95 |
- |
|
|
42 |
|

1. Построение рядов распределения. Основные показатели ряда
Задача 1.10. Имеются следующие данные о распределении общего объема денежных доходов предприятий за первое полугодие 2010 года. Построить кривую Лоренца для распределения общего объема денежных доходов предприятий по выделенным группам. Рассчитать коэффициент концентрации доходов – коэффициент Джини.
Таблица 1.14
Распределение денежных доходов предприятий по группам
|
|
Доля общего |
Накопленные итоги, % |
||
Группы |
Количество |
объема |
доли |
доли общего |
|
предприятий по |
предприятий, |
доходов |
количества |
||
объема |
|||||
уровню доходов |
% к итогу |
по группам, |
предприятий |
||
доходов qi |
|||||
|
|
% к итогу |
pi |
||
|
|
|
|||
|
|
|
|
|
|
Первая |
20 |
6,2 |
20 |
6,2 |
|
(с наименьшими |
|||||
доходами) |
|
|
|
|
|
Вторая |
20 |
10,4 |
40 |
16,6 |
|
Третья |
20 |
15,6 |
60 |
32,2 |
|
Четвертая |
20 |
22,5 |
80 |
54,7 |
|
Пятая |
|
|
|
|
|
(с наивысшими |
20 |
45,3 |
100 |
100 |
|
доходами) |
|
|
|
|
|
Итого |
100 |
100,0 |
- |
- |
|
Задача 1.11. Имеются следующие данные о стоимости произведенной продукции по 30 однородным предприятиям одной из отраслей промышленности за год, млн. руб. По исходным данным построить статистический ряд распределения предприятий по выпуску продукции, образовав пять групп с равными интервалами. Построить графики ряда распределения (полигон, гистограмму и кумуляту). Рассчитать коэффициент Джини и построить кривую Лоренца. Рассчитать показатели вариации, структурные средние, децильный коэффициент дифференциации.
43

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
36,8 |
24,6 |
21,0 |
35,9 |
38,0 |
47,2 |
27,2 |
18,2 |
28,0 |
36,0 |
34,1 |
51,0 |
25,0 |
23,3 |
29,5 |
38,2 |
40,0 |
26,2 |
30,0 |
32,4 |
41,0 |
29,8 |
36,1 |
37,2 |
39,4 |
32,5 |
38,4 |
39,3 |
30,0 |
36,0 |
|
|
|
|
|
|
|
|
|
|
Задача 1.12. Имеются данные о распределении водителей автотранспортного предприятия по степени выполнения норм грузоперевозок за месяц. Рассчитать показатели вариации, структурные средние, коэффициент Джини, децильный коэффициент дифференциации.
|
|
|
|
|
|
|
|
|
|
Таблица 1.15 |
||
|
Распределение водителей по степени выполнения |
|||||||||||
|
|
|
|
норм грузоперевозок |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
Степень |
|
|
|
|
|
|
|
|
|
|
|
|
выполнения |
|
80-70 |
90-80 |
|
100-90 |
110-100 |
|
120-110 |
130-120 |
|
140-130 |
|
норм |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
грузоперевозок |
|
|
|
|
|
|
|
|
|
|
|
|
, |
|
|
|
|
|
|
|
|
|
|
|
|
% |
|
|
|
|
|
|
|
|
|
|
|
|
Число |
|
10 |
40 |
|
140 |
120 |
|
80 |
60 |
|
50 |
|
водителей, fi |
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
Задача 1.13. Выполнить структурную группировку по сумме активов баланса (тыс. руб.) 30 предприятий региона России.
571 |
1122 |
2154 |
2988 |
1981 |
1053 |
485 |
3542 |
7018 |
3124 |
6470 |
5489 |
3787 |
782 |
584 |
3917 |
2337 |
4758 |
3833 |
2487 |
2003 |
3848 |
832 |
3667 |
5523 |
4158 |
1762 |
6941 |
2715 |
3379 |
|
|
44 |
|
|

1.Построение рядов распределения. Основные показатели ряда
1.Проранжировать данные.
2.Определить число групп с использованием формулы Стерджесса.
3.Найти величину интервала.
4.Построить ряд распределения.
5.Рассчитать среднею арифметическую взвешенную.
6.Подсчитать структурные средние. Изобразить ряд графически.
7.Рассчитать показатели вариации
8.Сделать выводы.
1.6. Контрольные вопросы
1.Перечислите статистические признаки, характеризующие единицы совокупности.
2.Дайте определение статистической совокупности.
3.Назовите основные стадии экономико-статистического исследования.
4.Какие показатели относятся к обобщающим величинам?
5.Что является экономико-статистическим показателем? Его назначение?
6.В чем состоит назначение сводки как второго этапа статистического исследования?
7.Что называется статистической группировкой и группировочными признаками?
8.Дайте характеристику структурной группировки.
9.Что представляют собой статистические ряды распределения? 10.Как подразделяются вариационные ряды распределения?
11.Как связаны между собой количество групп при построении рядов распределения и величина интервала?
12.Для чего рассчитывается формула Стерджесса?
13.Каковы правила построения полигона, гистограммы, кумуляты?
45

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
14.С какой целью используется кривая Лоренца и коэффициент Джини?
15.Как пройдет кривая Лоренца относительно линии равномерного распределения, если коэффициент Джини стремится к нулю?
16.В чем главный смысл закона больших чисел?
17.Дайте определение средней величины в статистике.
18.Какие виды средних используются в статистических исследованиях?
19.Как вычисляется средняя арифметическая простая и взвешенная? В каких случаях они используются?
20.Назовите основные свойства средней арифметической.
21.Какие показатели относятся к структурным средним?
22.Как они определяются в дискретных и интервальных вариационных рядах? Аналитически и графически.
23.Как рассчитывается и что характеризует децильный коэффициент дифференциации?
24.Что представляет собой вариация признака?
25.Укажите основные показатели вариации. Абсолютные и относительные
26.Что представляет собой правило сложения дисперсий?
27.Перечислите основные виды дисперсий.
28.Как определить показатели вариации для альтернативного признака?
46

2.Методы корреляционно-регрессионного анализа
2.МЕТОДЫ КОРРЕЛЯЦИОННО-РЕГРЕССИОННОГО
АНАЛИЗА
2.1. Основные понятия корреляционно-регрессионного анализа
Экономический анализ деятельности предприятия базируется на диалектическом методе познания, так как изучение деятельности проводится с учетом всех взаимосвязей между явлениями. Цель экономического анализа заключается не только в установлении причинно-следственных связей, но и в определении количественных характеристик, т.е. в измерении влияния факторов на результаты деятельности. Использование корреляционно-регрессионного анализа в экономических исследованиях дает точный результат и придает выводам обоснованность. Корреляционно-регрессионный анализ используются на втором этапе экономико-статистических исследований при выполнении аналитической группировки, является основным разделом математической статистики. Используются при прогнозировании и планировании деятельности предприятий, так как основан на логике массовых явлений и точно измеряет связь между наблюдаемыми явлениями при выполнении экономических исследований.
Задачи, решаемые методами корреляционно-регрессионного анализа:
1.Определение формы связи между изучаемыми явлениями (задача регрессионного анализа).
2.Количественное описание взаимосвязей, т.е. измерение интенсивности связи между явлениями, характеризующих силу влияния факторных признаков на результативный показатель (задача корреляционного анализа).
При изучении экономических процессов возникает два вида зависимостей: функциональная и корреляционная. Функциональная связь рассматривается как корреляционная с предельно высокой теснотой зависимости. При функциональной зависимости каждой переменной х по некоторому закону ставится в соответствие определенное значение у. Особенность данного вида связи – в каждом
случае известны все факторов, влияющие на результативный показатель и точный механизм их влияния (например: S = πr2). Это
47

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
абстрактные связи. При изучении экономических процессов используются корреляционные связи. При корреляционной зависимости числовому значению какого-либо фактора х соответствует не конкретная величина, а групповая средняя результативного показателя у. На изменение результативного показателя влияет факторный признак и частично другие факторы. Например, объем затрат на производство продукции зависит от производительности труда на предприятии. Но в экономике действует сложный комплекс взаимно переплетающихся причин. На затраты также влияют стоимость основных производственных фондов, выбранная технология производства продукции, потери от брака и другие неучтенные факторы в данной модели. Корреляционная связь проявляется во всей совокупности, по всем эмпирическим данным, получаемым при статистическом наблюдении, а не в каждой единице. При статистическом изучении корреляционной связи используется способ научной абстракции, т.е. определяется влияние выбранных факторов, а прочие игнорируются.
Результаты корреляционных расчетов используются в углубленном экономическом анализе, прогнозировании, планировании и управлении производством.
2.2. Основные этапы построения корреляционно-регрессионной модели
Подготовительный этап построения корреляционнорегрессионной модели состоит в определении цели исследования, системы показателей (факторов), определении достаточного числа наблюдений в выборке (табл. 2.1), формировании выборочной совокупности.
Часть отобранных объектов из генеральной совокупности является выборочной совокупностью (выборкой), а вся совокупность единиц, из которых производится отбор – генеральной. Генеральная совокупность объединяет большое число наблюдений. Применительно к экономическим явлениям генеральная совокупность обозначает наблюдения по всем предприятиям, относящихся к одной отрасли, за длительный период времени. Для того чтобы по отобранным значениям некоторого количественного показателя можно было достаточно уверенно судить обо всей совокупности,
48

|
|
|
|
|
|
|
|
|
|
2. Методы корреляционно-регрессионного анализа |
|||||||||||||||||
полученная |
|
|
выборка |
должна |
|
быть |
|
репрезентативной |
|||||||||||||||||||
(представительной), т.е. правильно отражать пропорции генеральной |
|||||||||||||||||||||||||||
совокупности. |
|
Репрезентативность |
выборки |
обеспечивается |
|||||||||||||||||||||||
случайностью отбора объектов в выборку. Основные способы |
|||||||||||||||||||||||||||
формирования |
|
выборочной |
совокупности: |
индивидуальный |
отбор |
||||||||||||||||||||||
(собственно случайный, механический, стратифицированный) и |
|||||||||||||||||||||||||||
серийный отбор. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 2.1 |
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
Формулы предельной ошибки и необходимого объема выборки |
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
для различных случаев отбора [1] |
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
Собственно |
|
Стратифициро- |
|
|
Серийная |
|
||||||||||||||
|
|
|
|
|
|
|
случайная |
|
|
|
|
|
ванная |
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
Выборка |
|
Повт |
Бесповторн |
Повт |
Бесповторн |
Повто |
Бесповторна |
|||||||||||||||||||
|
|
|
|
|
|
ор- |
ор- |
|
р- |
|
|||||||||||||||||
|
|
|
|
|
ная |
|
|
|
ая |
|
ная |
|
|
ая |
|
ная |
|
|
|
я |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
Сред- |
t |
|
S2 |
t |
S2 |
n |
|
S |
2 |
t |
S2 |
(1 |
n |
м2.с. |
|
м2.с. |
(1 |
nс |
|||||||
Предельная |
|
|
|
|
|
(1 |
) |
t |
|
|
|
) |
t |
|
t |
|
|
|
|||||||||
ошибка, |
ней, |
x |
|
|
n |
|
n |
|
N |
n |
|
|
n |
|
N |
nс |
|
nс |
|
Nс |
|||||||
Доли, |
t |
|
pq |
t |
pq (1 n ) |
t |
pq |
t |
pq (1 n ) |
t pqм.с. |
t pqм.с. |
(1 nс ) |
|||||||||||||||
|
|
|
|
|
|
|
n |
|
|
n |
|
N |
|
n |
|
n |
|
N |
nс |
nс |
|
Nс |
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Необходимая |
численность, n |
Сред- |
t2S2 |
|
t2S2N |
|
t2Sср |
2 |
|
t2Sср2 N |
|
t2Sм.с |
2 |
t2Sм2 |
.с N |
|
|||||||||||
ней, |
x |
|
2 |
|
t2S2 2N |
2 |
|
|
t2Sср2 2N |
2 |
|
t2Sм2 |
.с 2N |
||||||||||||||
Доли, |
t |
2 |
pq |
|
t |
2 |
pqN |
|
t2 pqср |
|
t2 pqср N |
t2 pqм.с |
t2 pqм.с N |
|
|||||||||||||
|
|
|
|
2 |
|
|
t2 pqср 2N |
2 |
|
t2 pqм.с 2N |
|||||||||||||||||
|
|
|
|
2 |
t2 pq 2N |
|
|
|
|||||||||||||||||||
где t– квантиль распределения соответствующая уровню значимости : |
|
|
|||||||||||||||||||||||||
а) |
при |
n 30, t u /2 |
– |
квантиль |
|
нормального |
закона |
|
распределения |
||||||||||||||||||
(определяется по прил. 1), б) при n 30, |
t – квантиль распределения Стьюдента |
||||||||||||||||||||||||||
с |
n 1 |
степенями |
свободы |
для |
двусторонней области (определяется по |
||||||||||||||||||||||
прил. 2); |
S2 |
– выборочная дисперсия; |
pq – дисперсия относительной частоты в |
||||||||||||||||||||||||
схеме повторных независимых испытаний; |
N |
– |
объем |
генеральной |
|||||||||||||||||||||||
совокупности; |
n– |
объем выборки; Sср2 |
|
– |
средняя арифметическая групповых |
||||||||||||||||||||||
дисперсий (внутригрупповая дисперсия); |
pq ср |
– |
средняя |
арифметическая |
|||||||||||||||||||||||
дисперсий |
групповых |
|
долей; |
м2.с. |
|
– |
|
|
межсерийная |
дисперсия; |
|
pqм.с. |
– |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
49 |
|
|
|
|
|
|
|
|
|
|
|
||
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
межсерийная дисперсия доли; Nc – число серий в генеральной совокупности; nc
– число отобранных серий (объем выборки); – предельная ошибка выборки.
Собственно случайный отбор (или случайная выборка) проводится с помощью жеребьевки или по таблице случайных чисел (прил. 3). При механическом способе отбора выборки отбирается каждый N/n элемент (N – множество единиц генеральной совокупности; n – множество единиц выборочной совокупности). Отбор единиц из неоднородной совокупности проводится стратифицированным способом. В этом случае генеральную совокупность разбивают на однородные группы с помощью типологической группировки, после этого производят отбор единиц из каждой группы в выборочную совокупность случайным или механическим способом. При использовании данного метода единицы разных групп включаются в выборку пропорционально их численности в генеральной совокупности. Особая форма составления выборки – серийный отбор, при котором в порядке случайной или механической выборки выбирают не единицы, а определенные районы, серии, внутри которых производится сплошное наблюдение.
Существует два метода отбора единиц в выборочную совокупность – повторный (отбор по схеме возвращенного шара) и бесповторный (отбор по схеме невозвращенного шара). При повторном отборе каждая попавшая в выборку единица возвращается в генеральную совокупность и имеет шанс вторично попасть в выборку. При этом вероятность попадания в выборочную совокупность всех единиц генеральной совокупности остается одинаковой. Бесповторный отбор означает, что каждая отобранная единица не возвращается в генеральную совокупность и не может подвергнуться вторичной регистрации, а потому для остальных единиц вероятность попасть в выборку увеличивается.
Бесповторный отбор дает более точные результаты по сравнению с повторным, так как при одном и том же объеме выборки наблюдение охватывает больше единиц генеральной совокупности. Поэтому он чаще используется в экономико-статистических исследованиях. Повторная выборка проводится в тех случаях, когда бесповторный отбор провести нельзя (при обследовании пассажирооборота и т. п.).
Разность между показателями выборочной и генеральной совокупности называется ошибкой выборки (табл. 2.1). Расчет
50

2. Методы корреляционно-регрессионного анализа
ошибки выборки производится для средних [15] и относительных величин.
На первом этапе осуществляется выбор формы связи и численная оценка её параметров. Это первая задача корреляционнорегрессионного анализа. Для аналитических целей корреляционную связь представляют при помощи математических функций (табл. 2.2), т.е. придают ей функциональную форму. Форма связи – это тенденция, которая проявляется в изменении результативного признака в связи с изменением фактора. Уравнением связи является уравнение регрессии, а анализ, производимый с помощью уравнения регрессии, называется регрессионным анализом. Уравнение регрессии является математической моделью связи, которое определяет среднюю величину результативного признака у в зависимости от вариации фактического признака х, bi – коэффициенты регрессии.
|
|
|
|
|
Таблица 2.2 |
|
|
Математические функции |
|||||
|
|
|
|
|
|
|
Прямолинейная |
|
|
y bx a |
|
||
зависимость |
|
|
|
|
|
|
y b1x1 |
b2x2 ... bmxm a |
|||||
|
Логарифмическая |
|
y blg(x) a |
|
||
|
Параболическая |
|
y b1x b2x2 a0 |
|
||
Криволинейные |
Гиперболическая |
|
y b |
1 |
a |
|
|
|
|
||||
зависимости |
|
|
|
x |
|
|
|
Показательная |
|
y abx |
|
||
|
|
|
|
|
||
|
Степенная |
|
y axb |
|
||
|
|
|
|
|
|
|
Чаще всего в экономико-статистических исследованиях используются линейные модели в силу простоты и логичности их экономической интерпретации. Численная оценка параметров выбранного уравнения регрессии осуществляется методом наименьших квадратов: сумма квадратов отклонений фактических y от выровненных ~y должна быть минимальной (для линейной зависимости – по формулам п. 3.2). Эмпирическое исследование уравнения формы связи включает построение графиков
51
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
корреляционных полей и линий регрессий. Корреляционным полем является нанесенные в прямоугольной системе координат в определенном масштабе точки, соответствующие одновременно значениям двух величин. Параметры линии регрессии вычисляются с помощью Excel (рис. 3.7 – 3.9) или по формулам [9].
Адекватность означает совпадение основных свойств построенной математической модели и изучаемого экономического явления. Проверка линейного уравнения регрессии на адекватность состоит из решения нескольких вопросов:
1. Определение значимости коэффициентов регрессии.
Рассчитывается для малой выборочной совокупности (при численности до 30 единиц) с помощью t-критерия Стьюдента. Фактические значения tфакт сравниваются с табличными tтабл:
ta |
|
a |
|
n 2 |
|
|
; |
|
tb b |
|
n 2 Sx |
; |
|
|||||||||
0 |
|
S ост |
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Sост |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
~ |
|
|
2 |
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
) |
|
|
|
|
(xi |
x) |
|
|
|||||||||
|
S |
|
|
|
(yi yi |
|
|
|
S |
|
|
|
|
(2.1) |
||||||||
|
ост |
|
|
|
|
|
; |
|
|
|
|
, |
|
|||||||||
|
|
|
|
n |
|
|
|
|
x |
n |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
где n – численность выборочной совокупности; Sост– среднее квадратическое отклонение результативного признака у от теоретических значений ~y ; ~y – значение результативного признака, полученные путем подстановки значений факторного признака х в уравнении регрессии; Sx – среднее квадратическое отклонение фактического признака.
Параметры уравнения регрессии b и a признаются типичными,
если tфакт больше tтабл: ta tтабл tb . Табличные значения t-критерия Стьюдента приведены в прил. 2.
2. Определение значимости уравнения регрессии. В некоторых случаях разброс точек корреляционного поля настолько велик, что для принятия решения в управлении нельзя ориентироваться на полученное уравнение регрессии, так как погрешность во взаимосвязи анализируемых явлений будет высокая. Адекватность проверяется с помощью расчета средней квадратической ошибки уравнения регрессии (Se) – это среднее квадратическое отклонение фактических значений у относительно значений, рассчитанных по уравнению
52

2. Методы корреляционно-регрессионного анализа
регрессии ỹ. Величина Sе – это показатель значимости и полезности прямой, выражающей соотношение между признаками. Величина Se сопоставляется со средним квадратическим отклонением результативного признака Sу. Если Se<Sу, то использование уравнения регрессии является целесообразным. Чем меньше рассеяние эмпирических точек вокруг прямой, тем меньше средняя квадратическая ошибка уравнения.
|
|
~ 2 |
|
|
|
yi |
|
|
2 |
|
|
|
|
|
|
|
|
||||
Se |
|
yi y |
; Sy |
|
y |
(2.2) |
||||
n k |
|
, |
||||||||
|
|
|
|
|
n |
|
||||
где yi – фактические значения результативного признака, полученные по данным наблюдения; ỹ – значение результативного признака, полученные путем подстановки значений факторного признака х в уравнении регрессии; k – число параметров в уравнении регрессии (в линейном уравнении регрессии k = 2).
На втором этапе решается следующая задача корреляционнорегрессионного анализа – измерение интенсивности связи между явлениями. Оценки, полученные с помощью регрессии, имеют точность тем большую, чем интенсивнее связь, т.е. тем меньше влияние неучтенных факторов в изучаемой модели.
Соотношение между факторной и общей дисперсии характеризует меру тесноты связи между фактором (х) и результативным признаком (у) называется коэффициентом детерминации:
r2 S~y2 ,
Sy2
|
|
|
~ |
|
|
|
2 |
|
|
|
|
y) |
|||||
где |
2 |
|
(yi |
|
– факторная дисперсия, отображающая вариацию у |
|||
S~y |
|
|
|
|
|
|
||
n |
|
|||||||
|
|
|
|
|
||||
только от воздействия х; Sу2 – дисперсия результативного признака. Показатель определяет долю влияния факторов, не включенных в модель, на результативный признак.
Вычислением коэффициента корреляции оценивают, в какой степени связи между факторами приближаются к линейному закону. Парная линейная корреляция (r) – это простейший вид корреляционной связи, практический смысл которой состоит в том, что среди факторов, влияющих на результативный признак,
53

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
выделяется один важнейший фактор – определяющий вариацию результативного признака.
Корреляция является прямой, если с ростом значения х растут значения у, и обратной, если наоборот.
Коэффициент корреляции вычисляется по формуле [9]
r
1
где m n (xi xcp) (yi ycp)
|
m |
, |
(2.3) |
S x |
S y |
||
– |
эмпирический |
корреляционный |
|
момент; n – |
количество единиц в выборке; xcp |
|
1 |
xi , |
ycp |
|
1 |
yi – |
|
n |
n |
||||||||
|
|
|
|
|
|
|
|||
выборочные |
средние; Sx, Sy – среднеквадратические |
отклонения; |
|||||||
Sx2 Dx 1n (xi xcp )2, Sy2 Dy 1n (yi ycp )2 –дисперсии.
Подставляя рассмотренные величины в формулу (2.3) получаем коэффициент корреляции
r |
|
(xi x)(yi |
y) |
|||||||
|
|
|
|
|
|
|
. |
|||
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
||||||
|
|
(xi |
|
x |
)2 (yi |
y |
)2 |
|
|
|
Он лежит в пределах: -1≤ r ≤+1. Знак плюс означает прямую, а знак минус – обратную связь. Если х и у связаны точной линейной зависимостью, то r = 1, если прямая связь и r = -1 – обратная. В зависимости от рассчитанного коэффициента корреляции определяется интенсивность связи между экономическими явлениями
(табл. 2.3).
Таблица 2.3
Практическая значимость коэффициента корреляции
От 0 до ±0,4 |
±0,4 до ±0,6 |
±0,6 до ±0,8 |
±0,8 до ±0,9 |
±0,9 до ±1 |
|
|
|
|
|
Связь |
Средняя |
Высокая |
Очень |
Полная |
отсутствует |
зависимость |
зависимость |
высокая |
зависимость |
|
|
|
|
|
При наличии криволинейной зависимости линейный коэффициент корреляции недооценивает степень тесноты связи и
54

2. Методы корреляционно-регрессионного анализа
может быть равен 0. В этих случаях в качестве показателя тесноты связи используется индекс корреляции
|
|
S~2 |
|
|
|
|
|
|
|
(yi |
|
~ |
|
|
2 |
|
|
|
|
|
|
|
2 |
|
|
|
|
||||||||
i |
y |
|
1 |
Sост |
|
1 |
|
yi ) |
|
|
|||||||
|
|
|
|
|
|
|
|
|
2 . |
||||||||
2 |
2 |
|
|
|
|
|
|||||||||||
|
|
(yi y) |
|||||||||||||||
|
|
Sy |
|
|
|
Sy |
|
|
|
|
|
|
|||||
Величина индекса зависит от формы уравнения регрессии. Принимает значения в пределах от 0 до 1. Если он равен или близок к 0, это означает, что между переменными х и у нет связи, или она не может быть охарактеризована выбранной формой уравнения регрессии. Близость величины индекса к 1 означает, что связь между признаками достаточно хорошо описывается избранным уравнением регрессии. Равенство индекса корреляции линейному коэффициенту корреляции означает, что лучше аппроксимирует фактические данные линейная зависимость.
Возможны случаи, когда отклонение от нуля коэффициента корреляции, рассчитанного по выборочной совокупности, оказывается обусловленным случайными колебаниями данных, на основании которых он вычислен. Для распространения выводов по результатам выборки на генеральную совокупность оценивается существенность линейного коэффициента корреляции. В зависимости от объема выборочной совокупности и величины коэффициента корреляции используются различные методы оценки его существенности, т.е. различные критерии значимости. Общее условие
– это нормальное распределение значений признака в генеральной совокупности. Проверка соответствия эмпирических данных нормальному закону распределения осуществляется с помощью проверки критериев согласия [15].
Основные критерии значимости для проверки коэффициента корреляции на существенность:
1. Проверка нулевой гипотезы используется для больших выборок (n > 30). В основе гипотезы предположение, что в генеральной совокупности коэффициент корреляции (ρ) равен нулю
[15]: если |
|
r |
|
|
|
xp |
|
, то нулевая гипотеза подтверждается и с |
|
|
|||||||
|
|
|
|
|
||||
|
|
|
|
|
|
(n 1) |
||
|
|
|
|
|
|
|||
|
|
|
|
|
|
55 |
||

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
вероятностью Р можно утверждать, что между двумя величинами
может не быть связи в генеральной совокупности, если |
|
r |
|
|
|
xp |
|
, то |
|
|
|||||||
|
|
|
|
|
||||
|
|
|
|
|
|
(n 1) |
||
|
|
|
|
|
|
|||
с этой же вероятностью можно утверждать, что нулевая гипотеза отвергается и такая связь есть, хр – аргумент, характеризующий вероятность нормального распределения в интегральной функции распределения (прил. 1). При исследовании взаимосвязей между экономическими явлениями в расчетах принимается девяносто пяти процентная вероятность.
2. Критерий Стьюдента рассчитывается в малых выборках для определения значимости коэффициента корреляции:
t |
|
r |
n 2 |
, |
|
расч |
1 r2 |
||||
|
|
|
где n –2 – число степеней свободы.
Теоретическое значение tтабл определяется по таблице распределения Стьюдента (прил. 2). Если tтабл ≤ tрасч, то предположение о нулевом значении коэффициента корреляции в генеральной совокупности не подтверждается. Если tтабл ≥ tрасч, то в генеральной совокупности коэффициент корреляции может быть равен нулю.
3. Метод преобразованной корреляции, предложенный Фишером, используется для определения значимости коэффициента корреляции, рассчитанного по малой выборке и имеющего значение по модулю близкое к 1. Средняя квадратическая ошибка Z-распределения зависит только от объема выборки и определяется по формуле
S 1 .

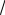 n 3
n 3
По таблице соотношений между r и Z (прил. 4) определяется Z, в зависимости от значения коэффициента корреляции. Отношение Z к средней квадратической ошибке Sz сравнивается с табличным значением по критерию Стьюдента при уровни значимости 5%. Если tтабл ≤ tрасч, то можно считать, действительно существует связь между признаками в генеральной совокупности.
56

2. Методы корреляционно-регрессионного анализа
Выбор адекватной модели затрудняется тем, что, используя математический аппарат, теоретически зависимость между признаками может быть выражена большим числом различных функций. Для выбора наиболее адекватной модели рассчитывается показатель средней ошибки аппроксимации
|
|
|
|
|
~ |
|
|
|
|
|
1 |
|
|
| yi yi |
| |
100% , |
(2.4) |
n |
yi |
|
||||||
|
|
|
|
|
|
где n – количество единиц в выборке; yi – фактические значения результативного признака; ~y – значение результативного признака,
полученные путем подстановки значений факторного признака х в уравнении регрессии.
Он определяет качество модели: от 0 до 10% – хорошее качество; от 10% до 40% – удовлетворительное; от 40% до 100% – плохое.
Для решения практических задач исследуется влияние факторов производства на его конечные результаты. Поэтому из корреляционных связей выделилась совокупность математикостатистических моделей, которые выражают зависимость результативных показателей от производственных факторов. Существует самостоятельное направление исследований – производственные функции.
Производственная функция – это математическая модель исследуемого явления или процесса, которая в форме уравнения или их системы описывает зависимость результативного показателя от одного или ряда производственных факторов.
К производственным функциям относится корреляционные и функциональные связи, которые моделируют зависимости производственных показателей от одного или ряда факторов. Производственные функции моделирую связи, которые имеют место в реальной производственной сфере. Они практически используются для решения аналитических, проектных и управленческих вопросов.
Задача 2.1. Известны данные по предприятию за несколько лет. Выбрать наиболее адекватную модель для прогнозирования развития явления.
57
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
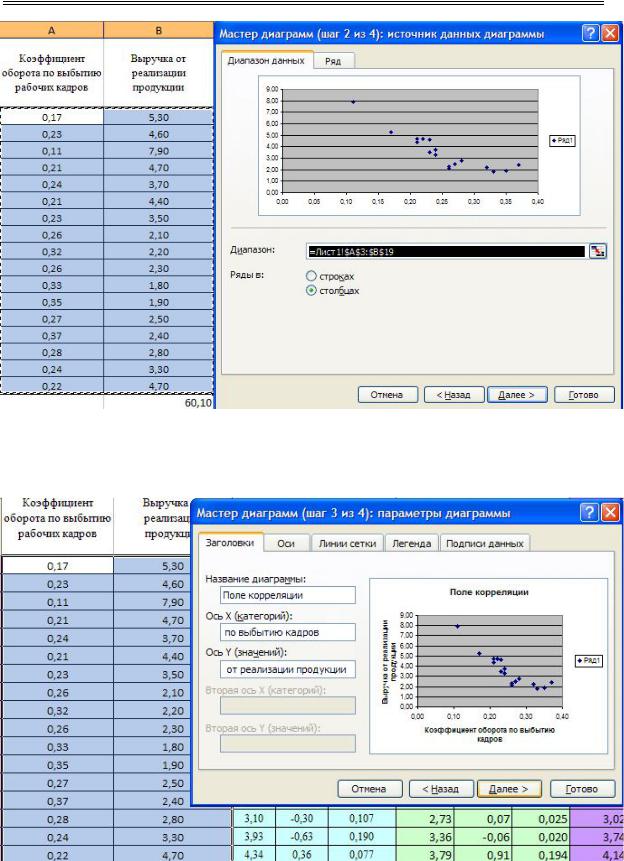
Решение. 1. На основании исходных данных строится поле корреляции: активизировать меню «Мастер диаграмм»; в окне «Тип» выбирается «Точечная» (рис. 2.1), вид графика выбирается в поле рядом со списком типов.
2.Установить флажок размещения данных в столбцах (рис. 2.2). Выделить диапазон исходных данных.
3.Заполнить параметры диаграммы на разных закладках (рис. 2.3): название диаграммы и осей, значения осей, линия сетки, параметры легенды, таблица и подписи данных.
4.Указать место размещения диаграммы на имеющемся листе. Готовая диаграмма (построенное поле корреляции) представлена на рис. 2.4.
Рис. 2.1. Диалоговое окно «Мастер диаграмм: тип диаграмм: вид диаграммы»
58
2. Методы корреляционно-регрессионного анализа
Рис. 2.2. Фрагмент диалогового окна «Мастер диаграмм: источник данных»
Рис. 2.3. Диалоговое окно «Мастер диаграмм: параметры диаграммы»
59
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.4. Поле корреляции
Рис. 2.5. Фрагмент диалогового окна типов линий тренда
60
2. Методы корреляционно-регрессионного анализа
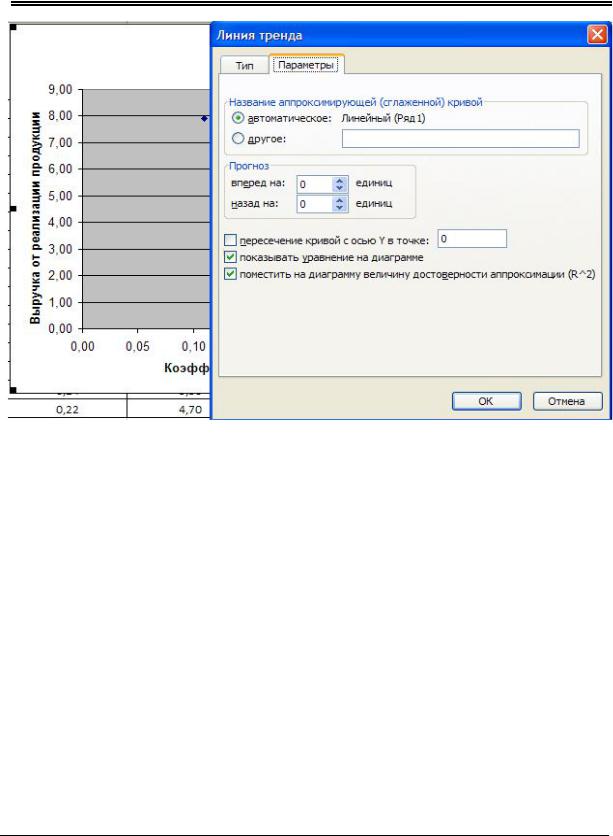
Рис. 2.6. Фрагмент диалогового окна «Параметры линии тренда»
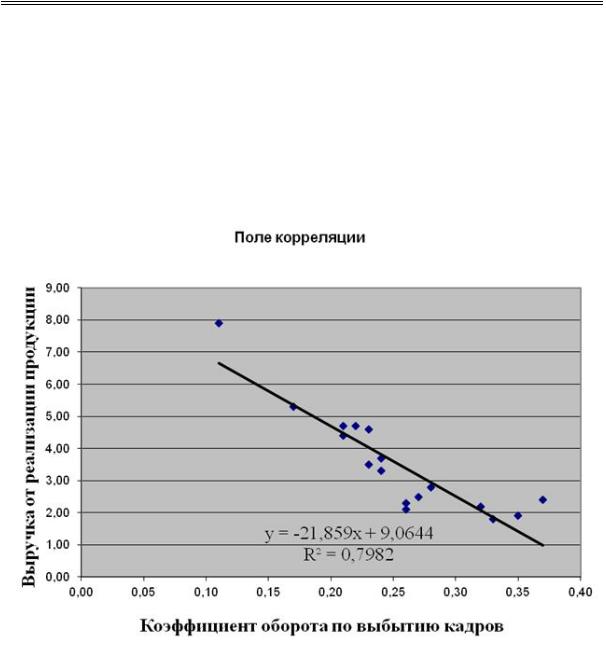
5. Добавить линию тренда на диаграмму: выделяется область построения диаграммы; в главном меню выбирается «Диаграмма/Добавить линию тренда». В появившемся диалоговом окне (рис. 2.5) выбирается вид линии тренда: например, «Линейный». В качестве дополнительной информации на диаграмме отображается уравнение регрессии и значение коэффициента детерминации (рис. 2.6). Линейный тренд изображен на рис. 2.7. Результаты всех рассчитанных уравнений регрессий с помощью построения линий тренда представлены в табл. 2.4.
|
Уравнения регрессии |
Таблица 2.4 |
|
|
|
|
|
|
|
|
|
1 |
2 |
3 |
|
Вид тренда |
Уравнение тренда |
Величина |
|
Линейный |
y = -21,859x + 9,0644 |
детерминации2 |
|
R = 0,7982 |
|
||
|
|
|
|
|
|
|
|
|
61 |
|
|
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Степенной |
y = 0,5092x-1,313 |
R2 = 0,8161 |
|
|
|
|
|
Логарифмический |
y = -5,1904Ln(x) – 3,7853 |
R2 |
= 0,8809 |
|
|
|
|
Полиномиальный |
y = 93,594x2 – 68,643x + 14,535 |
R2 = 0,912 |
|
|
|
|
|
Экспоненциальный |
y = 13,97e-5,7722x |
R2 |
= 0,8058 |
|
|
|
|
Рис. 2.7. Линейный тренд
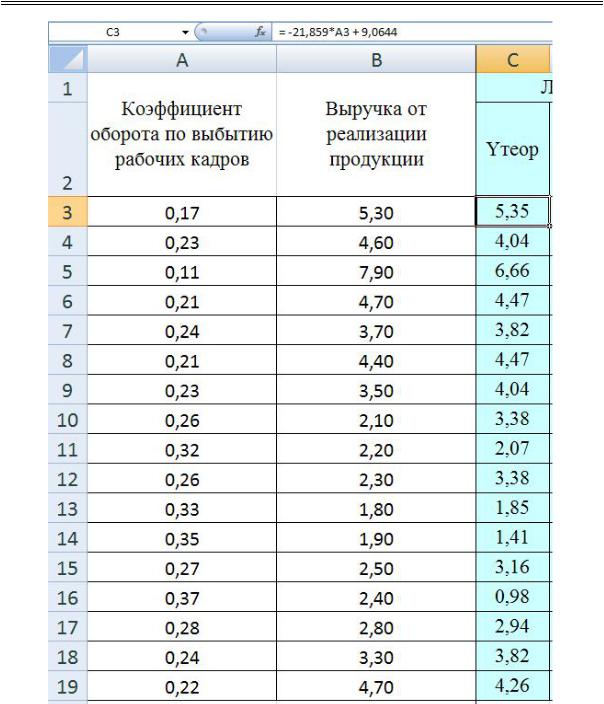
6.Рассчитываются теоретические значения. Для этого в таблице
сисходными данными (рис. 2.8) вводится формула для расчета: активизировать строку формул, введя с клавиатуры знак «=»; набрать
склавиатуры уравнение линейного тренда, при этом вместо x необходимо указать значение коэффициента по выбытию кадров; скопировать полученную формулу в диапазоне ячеек D3:D19 (рис. 2.8).
62
2. Методы корреляционно-регрессионного анализа
Рис. 2.8. Расчет теоретических значений
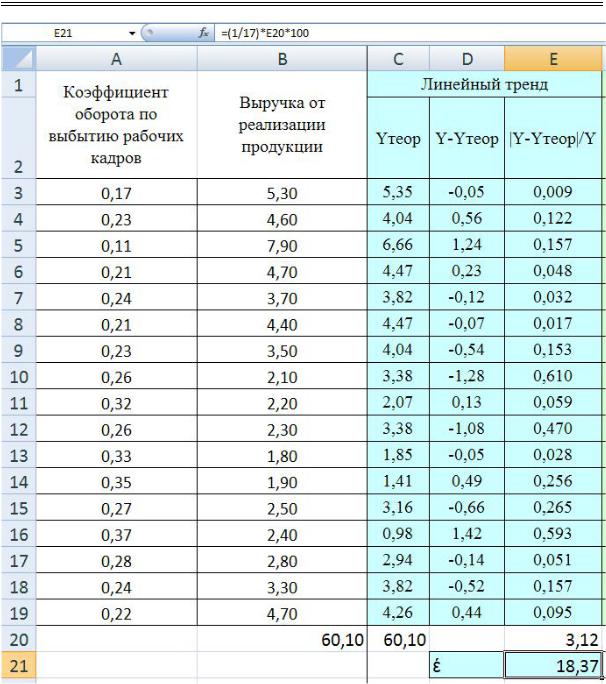
7.Расчет ошибки аппроксимации (форм. 2.4). Вычисления в MS Ecxel приведены на рисунке 2.9.
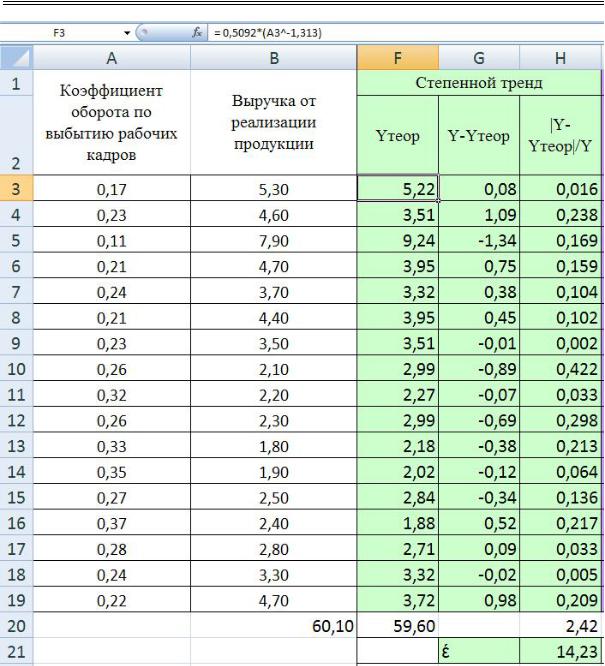
8.Аналогичные расчеты производятся для остальных регрессионных зависимостей (рис. 2.10 – 2.13).
63
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.9. Расчет ошибки аппроксимации в таблице MS Excel для линейного тренда
64
2. Методы корреляционно-регрессионного анализа
Рис. 2.10. Расчет ошибки аппроксимации в таблице MS Excel для степенного тренда
65
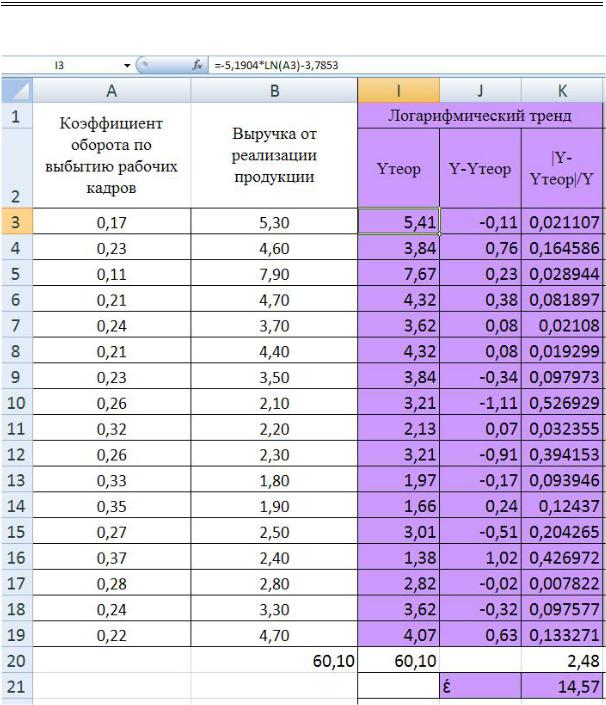
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2. 11. Расчет ошибки аппроксимации в таблице MS Excel для логарифмического тренда
66
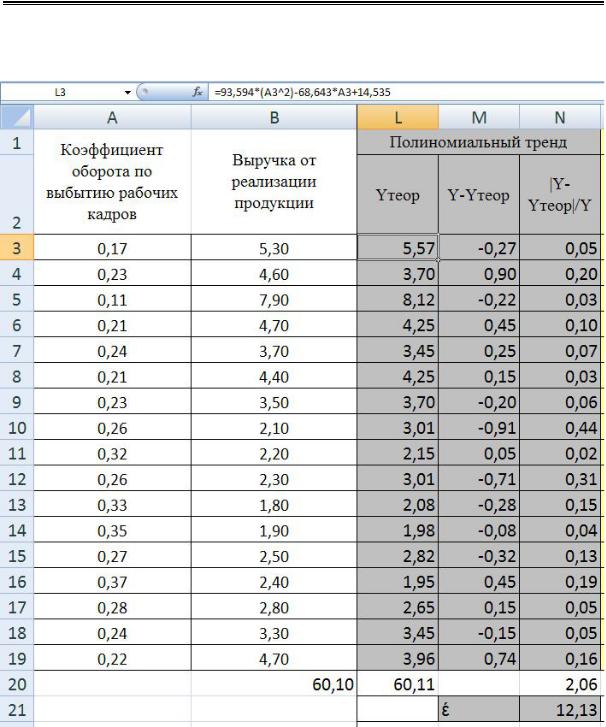
2. Методы корреляционно-регрессионного анализа
Рис. 2.12. Расчет ошибки аппроксимации в таблице MS Excel для полиномиального тренда
67
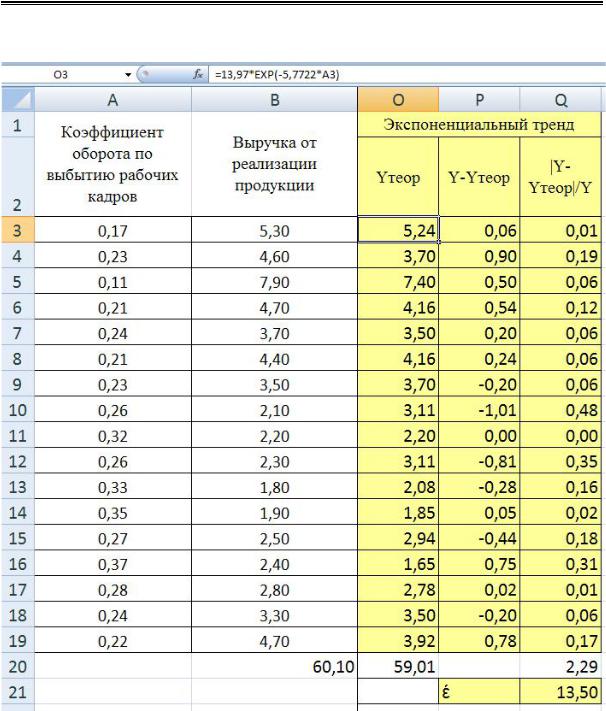
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.13. Расчет ошибки аппроксимации в таблице MS Excel для экспоненциального тренда
Анализируя полученные значения ошибок аппроксимации можно сделать вывод, что наиболее адекватной моделью для аппроксимации эмпирических данных является полиномиальная зависимость, с наименьшей ошибкой аппроксимации.
68

2.Методы корреляционно-регрессионного анализа
2.3.Построение множественной корреляционно-регрессионной модели
Вэкономике на результирующий показатель влияет не один, а несколько взаимосвязанных факторов. Поэтому более эффективно изучение множественных зависимостей. В моделях, если эти модели претендуют на адекватность, необходимо учитывать совокупное влияние нескольких факторов. Это совокупное влияние факторов определяется методами множественной корреляции. На практике чаще всего возникает необходимость исследовать зависимость результативного показателя от нескольких факторных признаков. В этом случае статистическая модель представляется уравнением регрессии с несколькими переменными величинами. Такая регрессия является множественной.
Основными задачами множественного корреляционнорегрессионного анализа являются:
1. Определение количественной оценки взаимосвязи между результативным показателем и факторными признаками.
2. Выбор множественного уравнения регрессии.
Сложным этапом построения множественной регрессии являются отбор и последующее включение факторов в модель, так как почти все экономические показатели взаимосвязаны. Определение оптимального числа факторных признаков является одной из основных проблем построения множественного уравнения регрессии. Чем больше факторов включено в уравнение, тем оно лучше описывает явление. Но модель с большой размерностью сложно реализуема. Сокращение размерности модели за счет исключения экономически и статистически несущественных факторов способствует простоте и качеству ее реализации.
Факторами являются любые экономические, технические, климатические, организационные, социальные и другие показатели, оказывающие количественное влияние на какой-либо результирующий показатель. Для построения множественной корреляционно-регрессионной модели с целью определения комплексного воздействия факторов в условиях их независимости друг от друга, отбираются факторы в два этапа. На первом отбираются факторы в зависимости от целей исследования, имеющие логические связи с результативным показателем. На втором этапе
69
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
проверяется критерий мультиколлинеарности между отобранными факторами, т.е. они не должны быть тесно связаны между собой. Для определения независимости факторов строится матрица парных коэффициентов корреляции r с использованием Excel: «Сервис/Анализ данных/Корреляция» (рис. 2.16 – 2.18). По корреляционной матрице легко выявить зависимые и независимые факторы: два фактора являются коллинеарны, т.е. зависимы, если
rxi x j 0 ,7 . В этом случае в модель включается только один фактор.
Для исключения мультиколлинеарности между факторами можно использовать эмпирический подход [16]:
r |
xiy |
r |
xix j |
||||
|
|
||||||
|
|
|
|
rx |
|
, если данная система неравенств выполняется, то оба |
|
rx |
j |
y |
x |
j |
|||
|
|
|
|
i |
|
||
фактора включаются в модель. При невыполнении хотя бы одного из неравенств – из модели исключается фактор xi или xj, имеющий менее тесную связь с результативным показателем. Например, в одну корреляционно-регрессионную модель нельзя одновременно включать факторы: «Среднесписочная численность персонала» и «Фондовооруженность» как независимые, так как между ними существует полная, обратная зависимость. Окончательный вывод при отборе факторов в модель должен быть сделан в соответствии с экономическим содержанием и логикой взаимосвязи конкретных факторов.
Практическая значимость регрессионной модели оценивается с помощью количественной оценки тесноты связи между факторами и результативным показателем. Для любых видов зависимостей рассчитывается множественный коэффициент корреляции R и его квадрат – коэффициент детерминации (R2):
Ryx x |
...x |
|
1 |
Sост2 |
, |
|
Sy2 |
||||||
1 2 |
|
m |
|
|
||
где Sост2 – остаточная дисперсия, |
Sy2 – дисперсия результативного |
|||||
признака.
Он определяет тоже самое, что и коэффициент корреляции, рассчитанный для парной зависимости: интенсивность связи только уже между рядом факторов (x1, x2,….xm) и результативным показателем (y). Изменяется в пределах от -1 до +1. Коэффициент
70

2. Методы корреляционно-регрессионного анализа
корреляции, рассчитанный для модели, после включения дополнительных факторов должен с каждым разом (после включения очередного фактора) увеличиваться. Так же, как и в парной зависимости, чем ближе коэффициент детерминации к единице, тем меньше влияние на результативный показатель факторов, не вошедших в модель. Дополнительный показатель 1–R2 определяет долю влияния факторных признаков, не вошедших в модель, но оказывающий влияние на результативный показатель.
Показатели множественной корреляционно-регрессионной модели, аналогично показателям парной модели, подвержены влиянию случайных факторов. Проверка на адекватность осуществляется с помощью проверки соответствующих критериев значимости.
Для оценки значимости множественного коэффициента корреляции R применяется F-критерий Фишера, вычисляемый по формуле
F |
|
|
R2 |
|
n k |
, |
расч |
(1 R2 ) |
|
||||
|
|
|
k 1 |
|||
где n – количество единиц в выборке; k – число коэффициентов в множественной модели. Если Fрасч превышает некоторое критическое значение (Fтабл) для данных n и k с вероятностью 95% (прил. 4), то величина R считается существенной, т.е в генеральной совокупности коэффициент корреляции отличен от нуля.
Аналитическая форма выражения связи результативного показателя и ряда факторных признаков называется множественным уравнением регрессии:
y b1x1 ... |
bmxm a, |
(2.5) |
где bi – коэффициенты множественной регрессии.
Коэффициенты множественной регрессии (bi) определяют среднее изменение результативного показателя с изменением фактора на одну единицу при неизменном значении других факторов, закрепленных на среднем уровне. Они вычисляются аналогично коэффициентам парной регрессии методом наименьших квадратов при помощи систем нормальных уравнений. Это достаточно трудоемкий процесс. С использованием Excel возможен расчет параметров множественных линейной и экспоненциальной моделей.
71

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Первый способ построения множественной линейной зависимости. Выбрать в Excel функцию ЛИНЕЙН (изв. зн. Y, изв. зн. X, константа, статистика,) где изв. зн. Y – это известные значения результативного показателя; изв. зн. X – это известные значения факторных признаков; константа – определяет чему равен свободный член уравнения а (форм. 2.5), если константа имеет значение ЛОЖЬ то а полагается равным 1, иначе а вычисляется обычным образом; статистика – если значение равно ИСТИНА то будет представлена дополнительная регрессионная статистика, если ЛОЖЬ то нет.
Построение линейной множественной регрессионной зависимости, с выводом всей статистической информации:
1.Выделяется диапазон: 5 строк, количество столбцов k + 1, k – количество коэффициентов в множественной модели.
2.С нажатой клавишей F2 ввести формулу =ЛИНЕЙН.
3.После окончания ввода формулы нажать комбинацию клавиш Ctrl+Shift+Enter так как данная функция возвращает массив значений.
В результате в выделенном диапазоне будет полная статистическая информация:
bn |
bn-1 |
… |
a |
Sen |
Sen-1 |
… |
Seb |
R2 |
Sey |
|
|
F |
Df |
|
|
Ssreg |
Ssresid |
|
|
где Se – стандартная ошибка для соответствующего коэффициента bi; Seb – стандартная ошибка для свободного члена a; R2 – коэффициент множественной детерминации; Sey – стандартная ошибка для y; F – критерий Фишера определяет случайная или нет взаимосвязь между зависимой и независимыми переменными; Df – степень свободы системы; Ssreg – регрессионная сумма квадратов; Ssresid – остаточная сумма квадратов.
Второй способ построения множественной линейной зависимости с использованием возможностей Excel: «Сервис» /Анализ данных» / «Регрессия».
72

2. Методы корреляционно-регрессионного анализа
Построение множественной экспоненциальной зависимости в Excel осуществляется с помощью функции ЛГРФПРИБЛ(изв. зн. Y, изв. зн. X, константа, статистика). Порядок заполнения данных при использовании функций описан выше. Пример использования данных функций приведен в задаче 2.2.
Проверка адекватности корреляционно-регрессионной модели, построенной на основе уравнения регрессии, осуществляется с помощью проверки значимости каждого коэффициента регрессии по t-критерию Стьюдента
tрасч |
|
|
bi |
|
|
|
, |
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
||||
|
|
|
|
S2 |
|
|
||||
|
|
|
|
bi |
|
|
||||
где b - коэффициенты множественной регрессии; |
S2 |
- дисперсия |
||||||||
i |
|
|
|
|
|
|
|
b |
|
|
|
|
|
|
|
|
|
|
|
i |
|
определенного коэффициента регрессии (1 раздел). Коэффициенты регрессии считаются статистически значимыми, если выполняется условие: tpасч ≥ tтабл Теоретическое значение tтабл определяется по таблице распределения Стьюдента (прил. 2). Если tтабл ≥ tрасч, то в генеральной совокупности коэффициенты регрессии могут равняться нулю с 95% вероятностью.
Для проверки на значимость множественного уравнения регрессии используется F-критерий Фишера
Fрасч |
|
Sy2 |
n k |
|
||
|
|
|
|
|
, |
|
S |
2 |
k 1 |
||||
|
|
ост |
|
|||
где n – количество единиц в выборке; k – число коэффициентов в
множественной модели; Sост2 - остаточная дисперсия, Sy2 - дисперсия результативного признака. Если Fрасч превышает некоторое критическое значение (Fтабл) для данных n и k с вероятностью 95% (прил. 4), то данное уравнение регрессии считается статистически значимым.
По полученным показателям множественной регрессии нельзя определить степень влияния факторных признаков на результативный показатель, так они могут измеряться в различных единицах измерения. Для оценки доли влияния каждого фактора в суммарном влиянии факторов, включенных в уравнении регрессии и для определения степени сравнительной связи между факторами и
73

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
резервов, заложенных в них, определяются относительные показатели:
1. Частные коэффициенты эластичности показывают, на сколько процентов в среднем изменяется результативный показатель у с изменением фактора хi на один процент при фиксированном положении других факторов, и рассчитывается по формуле:
Эi |
bi |
|
|
x |
i |
, |
|
|
|
||||
|
|
|
y |
|||
где bi –коэффициент множественной регрессии при i-м факторе;
x – среднее арифметическое значения соответствующего факторного показателя; y – среднее арифметическое значение результативного показателя.
2.-коэффициенты (бэтта-коэффициенты) показывают на
какую часть среднеквадратического отклонения изменится результативный показатель у с изменением соответствующего фактора х на величину среднеквадратического отклонения. Этот коэффициент позволяет сравнивать влияние колеблемости различных факторов на вариацию исследуемого показателя, что позволяет выявить факторы, в развитии которых заложены наибольшие резервы изменения результативного показателя:
|
i |
bi |
|
S x i |
, |
|
|
||||
|
|
|
|
S y |
|
где S x i – |
среднеквадратическое |
|
отклонение соответствующего |
||
фактора; |
S y – среднеквадратическое отклонение результативного |
||||
показателя.
3. -коэффициенты (дельта-коэффициенты):
i rxi y 2 i ,
R
где rxi y парные коэффициенты корреляции; i - соответствующий
бэтта – коэффициент; R2– множественный коэффициент детерминации.
Содержательный анализ моделей в целях уточнения приоритетности фактора опирается на сравнение перечисленных коэффициентов. При большом количестве факторов, включенных в уравнение регрессии, производится ранжирование факторов по
74
2. Методы корреляционно-регрессионного анализа
величинам Э, , , рассчитывается средний ранг и отбираются факторы, имеющие наибольшее влияние на результативный показатель [10].
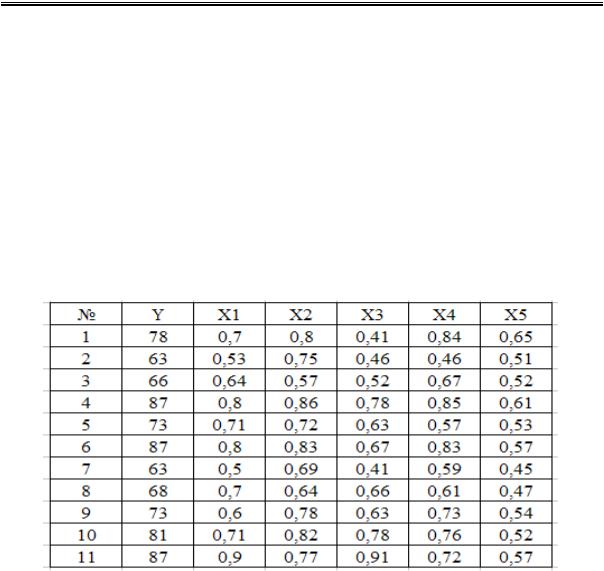
Задача 2.2. Имеются данные по 11-ти предприятиям отрасли. С целью изыскать резервы для получения дополнительной прибыли построить и выбрать наиболее адекватную множественную корреляционно-регрессионную модель для прогнозирования. Определить зависимость рентабельности (Y) от ряда факторов: Х1 – коэффициент финансовой независимости; Х2 – коэффициент капитализации; Х3 – коэффициент обновления основных средств; Х4 – механовооруженность; Х5 – коэффициент текучести рабочих кадров.
Рис. 2.14. Исходные данные
75
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.15. Электронная таблица MS Ecxel: выбор функции «Анализ данных»
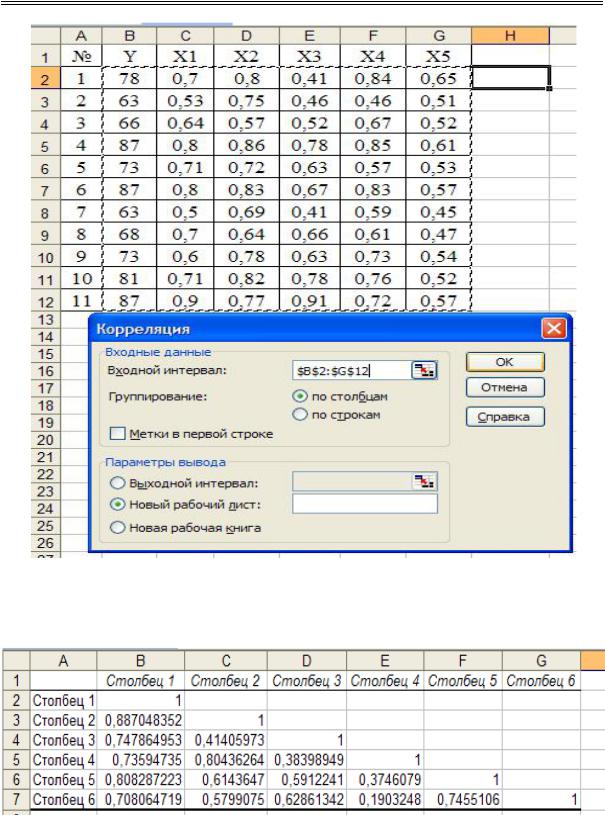
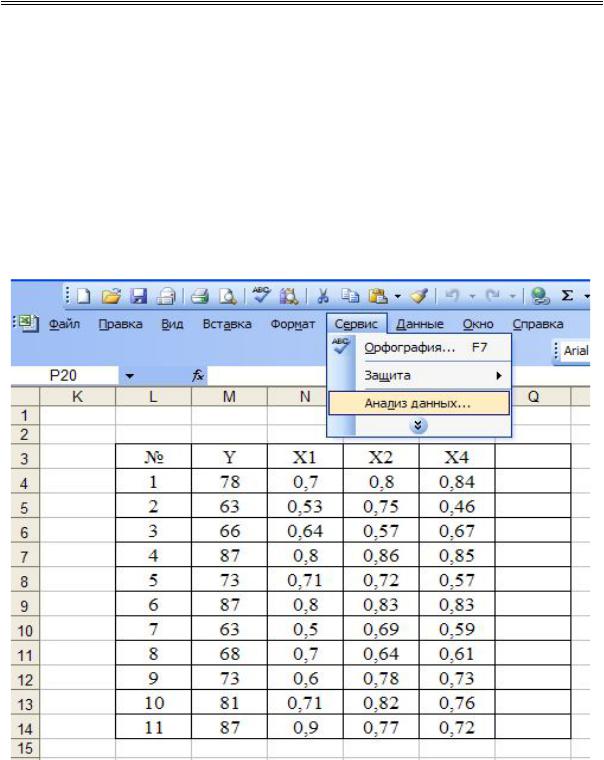
Решение. Анализ данных осуществляется с использованием MS Excel в следующей последовательности: активизировать кнопку «Сервис» (рис. 2.15), в распадающемся меню выбрать строку «Анализ данных»; в окне «Анализ данных» выбрать строку «Корреляция» (рис. 2.16); в окошке «Входной интервал» ввести соответствующий диапазон данных (рис. 2.17); расчет итогов будет выведен на отдельный лист MS Excel в виде таблицы(рис. 2.18).
76
2. Методы корреляционно-регрессионного анализа
Рис. 2.16. Фрагмент окна «Анализ данных»: выбор функции «Корреляция»
77
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.17. Фрагмент окна «Корреляция»: выбор входных данных
Рис. 2.18. Лист Excel с корреляционной матрицей (5 факторов)
78
2. Методы корреляционно-регрессионного анализа
Анализ матрицы коэффициентов парной корреляции показывает, что существенное влияние на зависимую переменную оказывают все факторы, но факторы в парах. X1 и X3; X4 и X5 явно коллинеарны между собой, так как коэффициенты корреляции между данными факторами больше, чем 0,7. Для исключения явления мультиколлинеарности факторы X3 и X5 исключаются из модели, так как оказывают наименьшее влияние на результативный признак. Остаются наиболее значимые факторы и повторяется процедура анализа данных (рис. 2.19–2.22).
Рис. 2.19. Фрагмент окна «Анализ данных»
79
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.20. Фрагмент окна «Анализ данных»: выбор функции «Корреляция»
Рис. 2.21. Фрагмент окна «Корреляция: выбор входных данных»
80
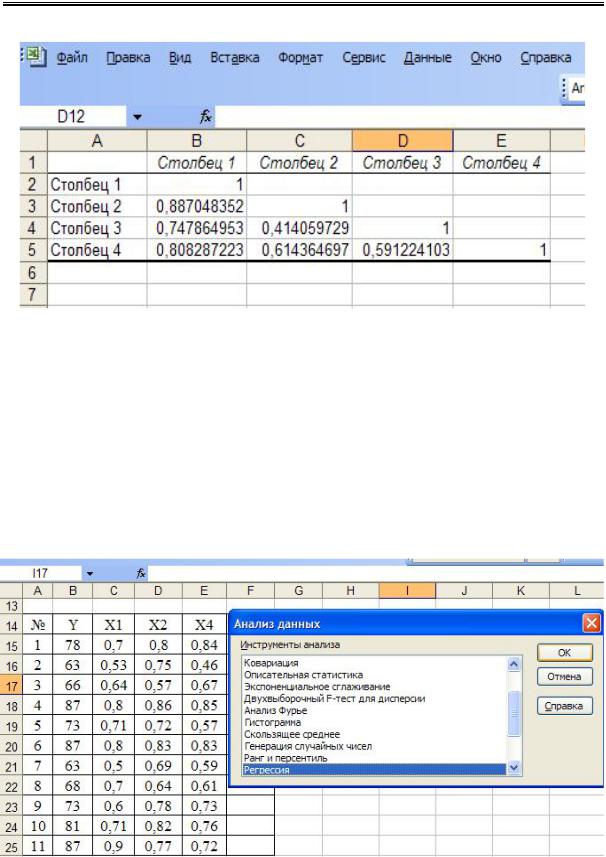
2. Методы корреляционно-регрессионного анализа
Рис. 2.22. Лист Excel с корреляционной матрицей (3 фактора)
Для наиболее значимых факторов рассчитываются параметры множественной корреляционно-регрессионной модели. Для этого в окне «Анализ данных» выбрать строку «Регрессия» (рис. 2.23); в окошке «Входной интервал Y» ввести соответствующий диапазон данных (рис. 2.24); в окошке «Входной интервал Х» вводится соответствующий диапазон данных (рис. 2.25); расчет и вывод итогов выведен на отдельный лист Excel в виде таблицы (рис. 2.26).
Рис. 2.23. Фрагмент окна «Анализ данных»: выбор функции «Регрессия»
81
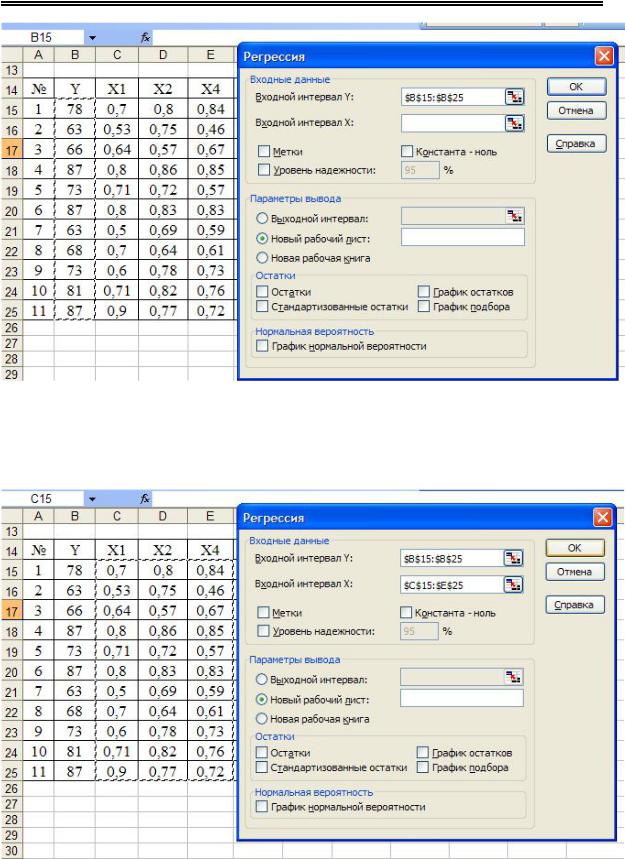
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.24. Фрагмент окна «Регрессия»: выбор «Входной интервал Y»
Рис. 2.25. Фрагмент окна «Регрессия»: выбор «Входной интервал Хn»
82
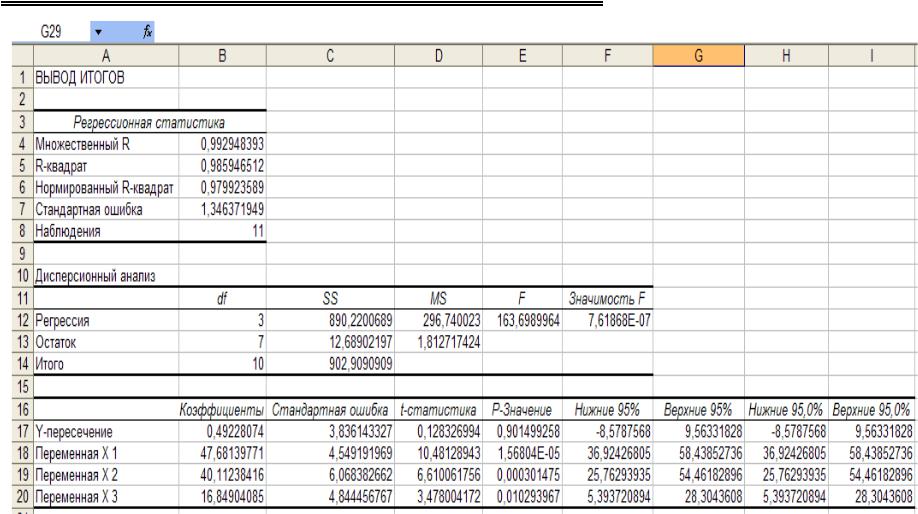
2. Методы корреляционно-регрессионного анализа
Рис. 2.26. Лист Excel с «Выводом итогов»
83

Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Множественный коэффициент корреляции R равен 0,993. Это означает, что связь между факторами очень высокая и полученное уравнение регрессии достаточно хорошо описывает изучаемую взаимосвязь между факторами. Коэффициент детерминации (R2 = 0,99), определяет долю влияния х1, х2, х4 на результативный показатель у; 1 – R2 = 0,01 характеризует долю влияния факторов, не вошедших в модель, но оказывающих влияние на результативный показатель. Это доля небольшая, значит наиболее значимые факторы, вариация которых влияет на вариацию результативного признака, вошли в построенную модель.
В регрессионном анализе наиболее важными результатами являются коэффициенты при переменных bi (форм. 2.5) и Y- пересечение (ai). В результате множественное уравнение регрессии имеет вид:
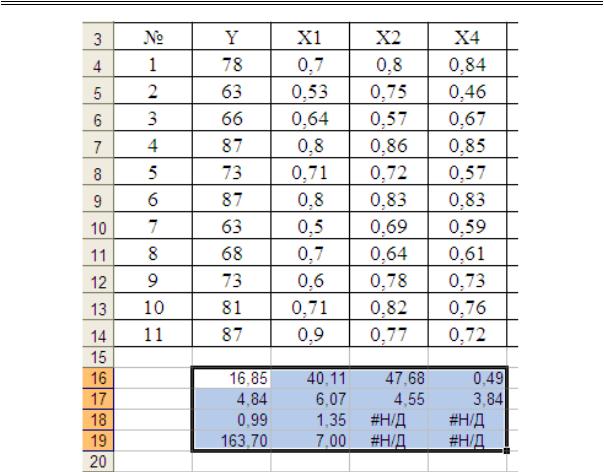
y 47,68 x1 40,11 x2 16,85 x3 0,49. |
(2.6) |
Коэффициенты множественной регрессии, |
полученные в |
результате проведения корреляционно-регрессионного анализа, характеризуют влияние факторных признаков на изучаемый результативный признак: при увеличении коэффициента финансовой независимости на единицу рентабельность увеличится на 47,68%; при увеличении коэффициента коэффициент капитализации на 1 рентабельность увеличится на 40,11%; при увеличении механовооруженности на единицу рентабельность изменится на
16,85%.
Доверительные интервалы (при уровне значимости 5% ) для найденных коэффициентов корреляционно-регрессионной модели
приведены в таблице: 36,92 x1 58,44; 25,76 x2 54,46; 5,39 x3 28,3.
В рассмотренной задаче, значение F-критерия Фишера (163,7) значительно превосходит критическое. Критическое значение F- критерия Фишера равно 4,46 (прил. 4).
Проверка значимости каждого коэффициента регрессии по t- критерию Стьюдента показала, что расчетные значения превышают критическое tтабл = 2,262 (прил. 2). Следовательно, все факторы, использованные в уравнении регрессии, полезны для предсказания рентабельности по предприятиям отрасли.
Используя функции ЛИНЕЙН и ЛГРФПРИБЛ рассчитаем показатели множественной линейной и показательной зависимостей.
84
2. Методы корреляционно-регрессионного анализа
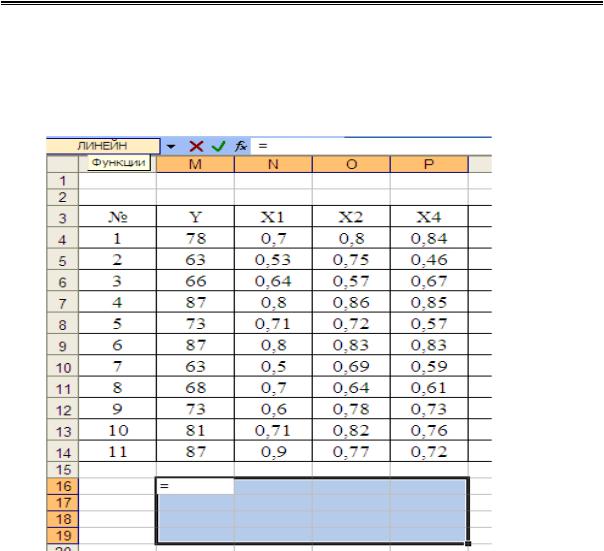
Рассмотрим построение линейной множественной регрессионной зависимости, с выводом всей статистической информации:
1. Выделяется диапазон: 5 строк, количество столбцов k + 1, k – количество коэффициентов в множественной модели (рис. 2.27).
Рис. 2.27. Ввод функции ЛИНЕЙНАЯ
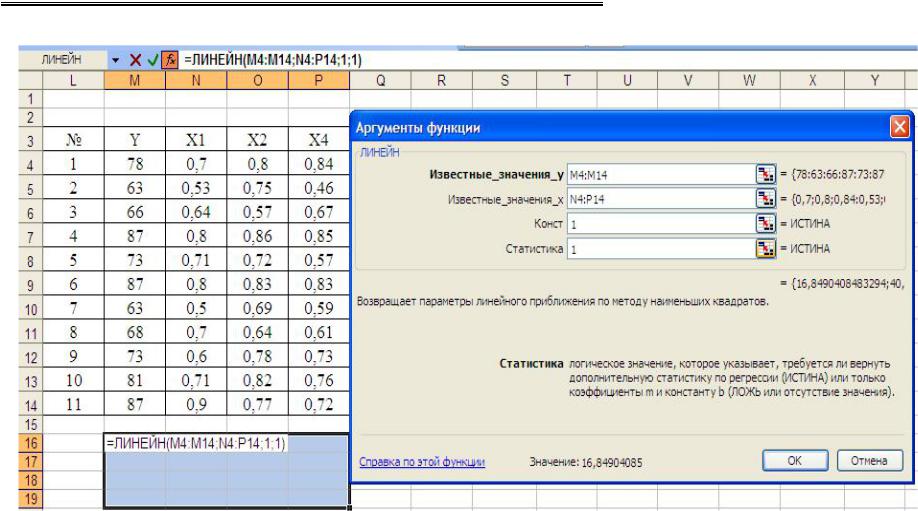
2.С нажатой клавишей F2 ввести формулу =ЛИНЕЙН
(рис. 2.28).
3.После окончания ввода формулы нажать комбинацию клавиш Ctrl+Shift+Enter так как данная функция возвращает массив значений
(рис. 2.29).
В результате в выделенном диапазоне будет полная статистическая информация.
85
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.28. Выбор исходных данных для построения линейной функции
86
2. Методы корреляционно-регрессионного анализа
Рис. 2.29. Выходные данные для линейной зависимости
Построение множественной показательной зависимости в MS Excel осуществляется с помощью функции ЛГРФПРИБЛ (рис. 2.30, 2.31).
87
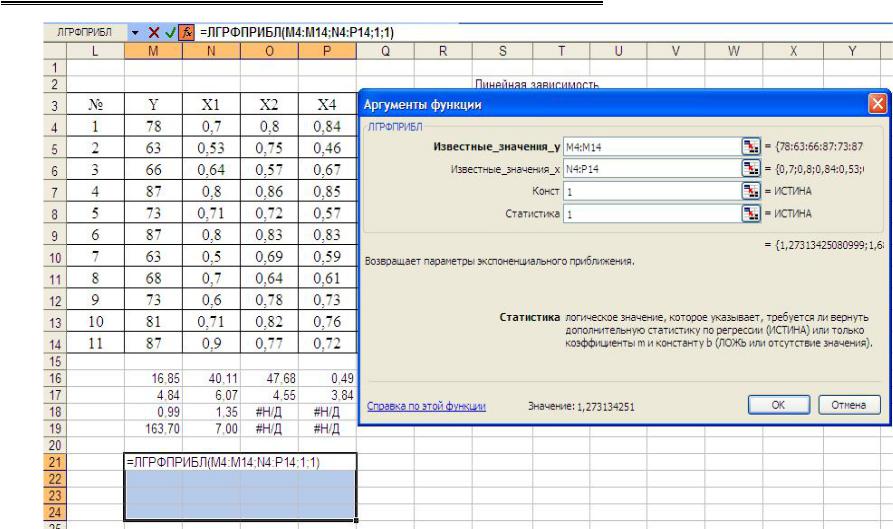
Конорева А.А., Харинова М.Ю. Экономико-статистические методы исследования систем при управлении предприятиями дорожной отрасли
Рис. 2.30. Построение показательной зависимости
88
2. Методы корреляционно-регрессионного анализа
Рис. 2.31. Выходные данные для показательной зависимости
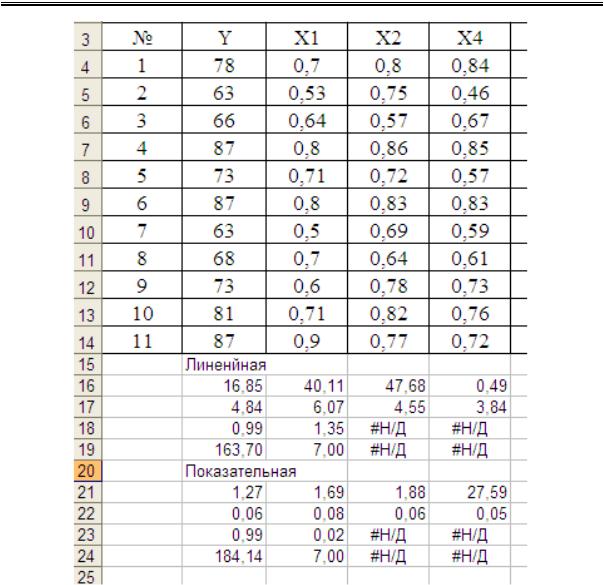
Результаты, полученные при расчете с использованием инструмента «Регрессия/Надстройки/Пакет анализа», совпали с результатами, полученными при помощи функции ЛИНЕЙН.
Подставляя найденные коэффициенты множественной регрессии в показательное уравнение: y a b1x1 b2x2 bnxn ,
получаем y 27,59 1,88x1 1,69x2 1,27x3 .
Коэффициент детерминации у показательной зависимости (0,99) не превышает коэффициент детерминации у линейной зависимости.
89