

10.3 Наиболее употребительные распределения. Замена переменных
Вырожденноераспределение.X=C=const

Распределение Бернулли. Этому распределению отвечает следующая схема испытаний: имеется опыт с двумя исходами (1 — «успех», 0 — «неудача»), заданы вероятностиP(X= 1) =p,P(X= 0) = 1 −p=q.
|
x |
0 |
1 |
|
p |
p |
q |
Функция распределения имеет вид

Биномиальное распределение. Производитсяnнезависимых испытаний, а исходы кодируются двоичной последовательностьюωдлиныn(0 отвечает неудаче, 1 — успеху). За случайную величину беретсяX(ω) =m— число успехов. Из §9 знаем, что
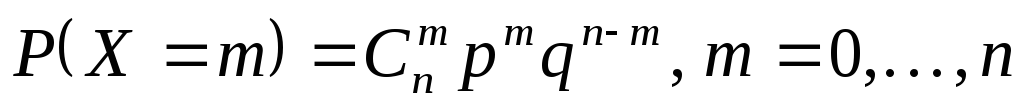 .
Таблица распределения имеет вид
(∑
pi
= 1):
.
Таблица распределения имеет вид
(∑
pi
= 1):
|
x |
0 |
1 |
|
n |
|
p |
p0 |
p1 |
|
pn |
Функция распределения

Распределение Пуассона
Случайная величина принимает значения 0, 1, 2, …, n, …, причем
![]()
|
λ |
0 |
1 |
|
n |
|
p |
p0 |
p1 |
|
pn |
Равномерное распределениена конечной совокупности
|
x |
x1 |
x2 |
|
xn |
|
p |
1/n |
1/n |
|
1/n |

Равномерное распределениена интервале [a,b]
И з
интервала выбирается точкаω;X(ω)
=ω.
з
интервала выбирается точкаω;X(ω)
=ω.
Плотность распределения вероятности равна
 .
.
Функция распределения
 .
.
Теорема(преобразование Смирнова). ПустьХ — случайная величина с непрерывной функцией распределенияF, тогдаF(x) =Y — новая случайная величина, имеющая равномерное распределение на [0,1], т.е.
 .
.
Доказательство. ЕслиFмонотонно возрастает, существует обратная функцияF−1, и тогда
![]() .
.
П
 оказательноераспределение
оказательноераспределение
 .
.
Функция распределения
![]() .
.

Симметричное показательное распределение
![]()
Нормальное распределение. Говорят, что случайная величинаXимеет стандартное нормальное распределение, если плотность распределения равна
![]() ,
,
и нормальное распределение с параметрами aиσ, если плотность ее распределения
 .
.
(у стандартного нормального распределения a= 0,σ= 1).
График нормального распределения:

Распределение Коши — пример распределения с плохими свойствами:
![]() .
.
Примеры
Маяк, расположенный в 1 км от прямоугольного берега, посылает луч под углом α, имеющим равномерное распределение в интервале [−π/2,π/2]. Найти плотность и функцию распределения координаты лучаx.
![]()

 .
.
![]()
![]() .
.
Случайная величина Xимеет равномерное распределение на [a,b];F(0) = 1/4,F(1) = 1/2. Найти параметры распределения (a иb).
Как известно,
 .
.
Подставим вместо x — 0 и 1, и решим получившуюся систему уравнений
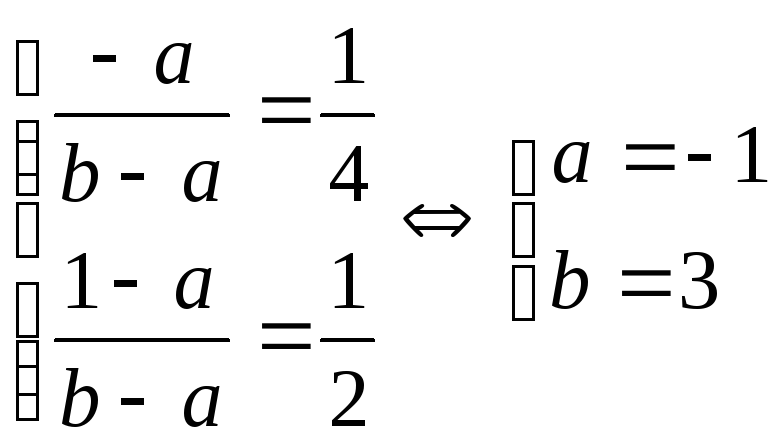 .
.
График функции распределения (качественно):

Случайная величина Xимеет показательное распределение с параметромα. Найти плотность распределения величиныY=exp x.
Решение.![]()
![]() ,
,![]() .
.
Случайная величина Xнормально распределена с параметрамиaиσ, т.е.
![]() .
.
Найти вероятность того, что X(1,3).
Решение.
![]()
 ,
,
где Φ — функция Лапласа:
![]() .
.
Обобщим результат примера 4 — докажем теорему о плотности распределения преобразованного вектора. Пусть дана случайная величинаXс плотностью распределенияpX(x),Y=φ(X). Требуется найти плотность распределенияpY(y).
Будем считать φ(X) монотонна и дифференцируема (вообще говоря, монотонность требуется для взаимно-однозначного отображенияX↔Y).
Предположим, φ(X)
монотонно возрастает (для монотонного
убывания доказательство аналогично).
В таком случае .
.
По правилу дифференцирования обратной функции можно также записать
![]() .
.
Доказательство.
![]() .
.
Продифференцируем это выражение по y:
 .
.
Пусть теперь φ(X) монотонно убывает. Тогда
![]() .
.
Продифференцировав, получим знак «−»
перед выражением для pY.
Однако![]() при этом также будет отрицательной
величиной. Отсюдавывод: в общем
случае формула имеет вид
при этом также будет отрицательной
величиной. Отсюдавывод: в общем
случае формула имеет вид .
Теорема доказана.
.
Теорема доказана.
Рассмотрим важный случайприменения
теоремы. Пустьφ(X)
— линейная функция, т.е.φ(X)
=aX+b.
Тогда![]() .
Отсюда,
.
Отсюда,
![]() .
.
В частности, если X~N(0, 1)9,Y=aX+b, то
![]()
Вывод: при линейном преобразовании
получили величину с нормальным
распределениемN(b,a2). И наоборот:
если дана величинаY~N(a,σ2), то![]() имеет стандартное нормальное распределение.
С учетом этих результатов пример 4)
решается более просто: нам дано 1 ≤X≤ 3, гдеX~N(a,σ2). Возьмем
имеет стандартное нормальное распределение.
С учетом этих результатов пример 4)
решается более просто: нам дано 1 ≤X≤ 3, гдеX~N(a,σ2). Возьмем![]() ,
тогда
,
тогда
![]() .
.
Проинтегрировав pY(y) в пределах от (1−a)/σдо (3−a)/σ, получим то же самое.
Пусть X~U(0, 1),Y= −alnX+b. НайтиpY(y).
Решение. Применим теорему:
 .
.
Отсюда
 ,y>b.
,y>b.
При b= 0 получаем показательное распределение.
Замечание. Вообще говоря, теорема не всегда применима. Действительно, пустьX~N(0, 1), аY=X 2. Легко видеть, чтоX 2немонотонна, но в данном конкретном случае плотность распределения найти можно:
![]()
![]() .
.