

2. Жизненный цикл программного обеспечения. Структура жизненного цикла согласно международного стандарта.
ЖЦ ПО - это непрерывный процесс, который начинается с момента принятия решения о необходимости его создания и заканчивается в момент его полного изъятия из эксплуатации.
Структура ЖЦ ПО по стандарту ISO/IEC 12207 базируется на трех группах процессов:
основные процессы ЖЦ ПО (приобретение, поставка, разработка, эксплуатация, сопровождение);
вспомогательные процессы, обеспечивающие выполнение основных процессов (документирование, управление конфигурацией, обеспечение качества, верификация, аттестация, оценка, аудит, решение проблем);
организационные процессы (управление проектами, создание инфраструктуры проекта, определение, оценка и улучшение самого ЖЦ, обучение).
К настоящему времени наибольшее распространение получили следующие две основные модели ЖЦ:
каскадная модель (70-85 г.г.);
спиральная модель (86-90 г.г.).
В изначально существовавших однородных ИС каждое приложение представляло собой единое целое. Для разработки такого типа приложений применялся каскадный способ. Его основной характеристикой является разбиение всей разработки на этапы, причем переход с одного этапа на следующий происходит только после того, как будет полностью завершена работа на текущем (рис. 1.1). Каждый этап завершается выпуском полного комплекта документации, достаточной для того, чтобы разработка могла быть продолжена другой командой разработчиков.
Положительные стороны применения каскадного подхода заключаются в следующем [2]:
на каждом этапе формируется законченный набор проектной документации, отвечающий критериям полноты и согласованности;
выполняемые в логичной последовательности этапы работ позволяют планировать сроки завершения всех работ и соответствующие затраты.
К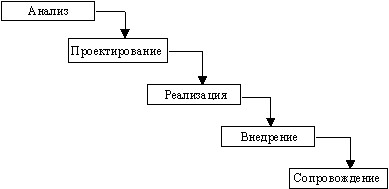 аскадный
подход хорошо зарекомендовал себя при
построении ИС, для которых в самом
начале разработки можно достаточно
точно и полно сформулировать все
требования, с тем чтобы предоставить
разработчикам свободу реализовать их
как можно лучше с технической точки
зрения. В эту категорию попадают сложные
расчетные системы, системы реального
времени и другие подобные задачи.
Однако, в процессе использования этого
подхода обнаружился ряд его недостатков,
вызванных прежде всего тем, что реальный
процесс создания ПО никогда полностью
не укладывался в такую жесткую схему.
В процессе создания ПО постоянно
возникала потребность в возврате к
предыдущим этапам и уточнении или
пересмотре ранее принятых решений. В
результате реальный процесс создания
ПО принимал следующий вид (рис. 1.2):
аскадный
подход хорошо зарекомендовал себя при
построении ИС, для которых в самом
начале разработки можно достаточно
точно и полно сформулировать все
требования, с тем чтобы предоставить
разработчикам свободу реализовать их
как можно лучше с технической точки
зрения. В эту категорию попадают сложные
расчетные системы, системы реального
времени и другие подобные задачи.
Однако, в процессе использования этого
подхода обнаружился ряд его недостатков,
вызванных прежде всего тем, что реальный
процесс создания ПО никогда полностью
не укладывался в такую жесткую схему.
В процессе создания ПО постоянно
возникала потребность в возврате к
предыдущим этапам и уточнении или
пересмотре ранее принятых решений. В
результате реальный процесс создания
ПО принимал следующий вид (рис. 1.2):
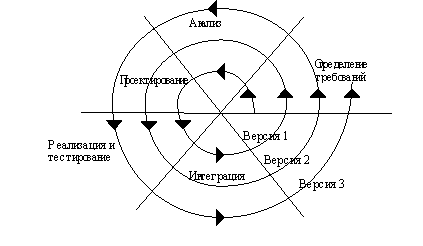
Основным недостатком каскадного подхода является существенное запаздывание с получением результатов. Согласование результатов с пользователями производится только в точках, планируемых после завершения каждого этапа работ, требования к ИС "заморожены" в виде технического задания на все время ее создания. Таким образом, пользователи могут внести свои замечания только после того, как работа над системой будет полностью завершена. В случае неточного изложения требований или их изменения в течение длительного периода создания ПО, пользователи получают систему, не удовлетворяющую их потребностям. Модели (как функциональные, так и информационные) автоматизируемого объекта могут устареть одновременно с их утверждением.
Разработка итерациями отражает объективно существующий спиральный цикл создания системы. Неполное завершение работ на каждом этапе позволяет переходить на следующий этап, не дожидаясь полного завершения работы на текущем. При итеративном способе разработки недостающую работу можно будет выполнить на следующей итерации. Главная же задача - как можно быстрее показать пользователям системы работоспособный продукт, тем самым активизируя процесс уточнения и дополнения требований.
Основная проблема спирального цикла - определение момента перехода на следующий этап. Для ее решения необходимо ввести временные ограничения на каждый из этапов жизненного цикла. Переход осуществляется в соответствии с планом, даже если не вся запланированная работа закончена. План составляется на основе статистических данных, полученных в предыдущих проектах, и личного опыта разработчиков.
3. Язык C++ позволяет классу наследовать элементы данных и функций одного или нескольких классов. Новый класс называют производным, старый – базовым. Производный может быть, в свою очередь, базовым для другого. Производный класс может переопределить некоторые свойства базового класса, наследуя основной объем и архитектуру
Синтаксис описания порожденного класса.
class BASE { }:
class DERIVED: [ключ доступа] BASE, другие классы с ключом { ..];
Ключ доступа определяет уровень доступа к элементам базового класса внутри производного. По умолчанию public.
Существуют т.н. абстрактные классы- классы, содержащие хотя бы один абстрактный метод, т.е. виртуальный метод, не реализованный в данном классе и который будет реализован лишь в порожденных. Абстрактные классы могут быть только базовыми для других классов. Объектов абстрактного класса быть не может, могут быть лишь указатели.
В связи с тем, что порожденный класс содержит в себе базовую часть, между порожденным и базовым классами возможны некоторые стандартные преобразования:
1. объект порожденного класса неявно преобразуется к объекту базового класса.
2. ссылка на объект порожденного класса неявно преобразуется к ссылке на объект базового класса.
3. указатель на объект порожденного класса неявно преобразуется к указателю на объект базового класса
4. указатель на член базового класса неявно преобразуется к указателю на член порожденного класса.
Конструктор не наследуется. Если конструктор базового класса требует спецификации одного или нескольких параметров, конструктор производного класса должен вызывать базовый конструктор, используя список инициализации элементов. Если базовый класс не имеет конструктора или конструктор не требует аргументов, то задавать конструктор базового класса в списке инициализации необязательно.
При инициализации объекта порожденного класса сначала вызывается конструктор базового класса, затем конструкторы объектов внутри порожденного класса (в порядке объявления), а затем собственный. При удалении объекта деструкторы вызываются в обратном порядке.
Объект порожденного класса может быть инициализирован другим объектом того же класса с помощью конструктора копии. Возможны несколько вариантов. Если порожденный класс не имеет конструктора копии, а базовый - имеет, то компилятор использует поэлементное копирование членов-данных порожденного класса и конструктор копии базового. Если порожденный класс имеет конструктор копии, то он полностью отвечает за копирование как собственных, так и наследуемых членов-данных, независимо от наличия конструктора копии базового класса. Последний в случае необходимости может быть вызван из списка инициализации. Ситуация с операцией присваивания аналогична.
Множественное наследование. Это случай, когда класс является производным от нескольких базовых классов. Это позволяет в одном классе сочетать поведение нескольких классов:
class DERIVED: public CLASS1; private CLASS2; protected CLASS3...
Определенный таким образом производный класс наследует все компоненты базовых классов, дополняя их своими, и получает доступ к общим и защищенным компонентам базовых классов.
В иерархии с множественным наследованием класс может косвенно наследовать два экземпляра базового класса
class base {...};
c/ass der1 base { }:
class der2 base { .},
class derived: deri,der2 {...};
В таком случае возникает двусмысленность которая приведет к ошибкам при компиляции. Одним из вариантов решения данной проблемы - применение операции разрешения видимости ::
Для более эффективного разрешения двусмысленности используют так называемые виртуальные базовые классы. Для этого необходимо при объявлении производного класса указать ключевое слово virtual. Для выше описанного примера необходимо сделать следующие исправления:
c/ass der1 virtual base {...}, class der2 virtual base { ..}; class derived der1, der2 {...},
В этом случае включение в производный класс полей виртуального класса осуществляется один раз, а инициализация их будет происходить в таком его производном классе, который не является прямым потомком данного базового класса
Порядок вызовов конструкторов и деструкторов:
1. конструктор виртуальных базовых классов выполняются до конструкторов не виртуальных базовых классов вне зависимости от того, как классы заданы в списке порождения
2. если класс имеет несколько виртуальных базовых классов то конструкторы этих классов вызываются в порядке объявления
3. деструкторы виртуальных базовых классов всегда выполняются после деструкторов не виртуальных базовых классов.
Билет 23