


H0 : a = 0
H1 : a ≠ 0
Здесь возможно два варианта проверки.
Вариант на основе критерия Вальда
Доказано, что в самом общем случае статистика W = a)'[Cov( a))]−1 a) при выполнении основной гипотезы асимптотически имеет χ2 - распределение с числом степеней свободы равным размерности вектора a . Этот факт позволяет построить асимптотическую критическую область, которая имеет вид луча в +∞ , ограниченного значением квантили указанного распределения порядка 1−α слева, где α - вероятность ошибки первого рода.
Вариант на основе нормальной гипотезы
При выполнении нормальной гипотезы для построенной модели и отсутствии гетероскедастичности для случайной составляющей можно поступить иначе. Построим две модели – «короткую» («с ограничением»), т.е. без взаимодействия с фиктивной переменной и «длинную» («без ограничений») с переменными взаимодействия. Зафиксируем коэффициенты детерминации в обоих случаях - RR2 (для короткой регрессии) и RUR2 (для длинной регрессии)
соответственно. Тогда при выполнении основной гипотезы статистика
|
(R2 |
− R2 )/ k |
||
FChow = |
UR |
|
R |
|
(1 − R2 |
|
)/(T − 2k ) |
, где“T” - объем выборки, а “k” – размерность |
|
|
UR |
|
|
|
короткой регрессии имеет F – распределение с k и T – 2k степенями свободы. [7
– 9]
Отсюда следует правило построения критической области, которая имеет вид луча в +∞ ограниченного значением квантили указанного распределения порядка 1−α , где α - вероятность ошибки первого рода.
При проведении критерия Чоу желательно не только проверить указанную пару гипотез, но и пояснить, как указано выше, в чем конкретно заключается различие, если оно обнаружено.
Минимальные требования
Необходимо проверить гипотезу об однородности выборки относительно наилучшей из построенных в первой части моделей с помощью критерия Чоу на основе критерия Вальда против гипотезы о наличии различий без проведения дополнительного анализа.
Обнаружение выбросов Теоретические основы
Выбросами называются измерения, которые плохо описываются с помощью выбранной модели, т.е. соответствующая апостериорная остаточная разность для них велика по отношению к остальным измерениям. Следует помнить, что выбросы корректно определены только относительно конкретной модели. При изменении ее структуры множество выбросов может существенно измениться. Для определения измерений, которые являются выбросами, следует проанализировать значения апостериорных остаточных разностей. В

качестве правила определения выбросов можно использовать «правило 3σ » основанное на неравенстве Чебышева: если величина апостериорной остаточной разности по модулю превышает ее утроенное стандартное отклонение для некоторого наблюдения, его можно рассматривать как «выброс». В случае, если количество выбросов будет незначительным, можно ужесточить правило и выделять превышение удвоенного стандартного отклонения. Целью анализа является получение модели с лучшими характеристиками из рассмотренных выше. Обнаруженные выбросы следует исключить из расчетов и пересчитать модель без них. В то же время, данные записи не следует удалять из базы данных. Желательно проанализировать на основании значений регрессоров причину возникновения аномалии. Следует помнить, что удаление выбросов снижает объем выборки и, тем самым, при большом количестве выбросов может привести к росту дисперсии оценок значений параметров линейной регрессии. Если обнаруживается, что выбросов очень много, например, их количество приближается к половине объема выборки, то следует пересмотреть вид модели. Удовлетворительным можно считать количество, не превышающее 5 – 10 % от объема выборки.
Минимальные требования
Проанализировать наличие выбросов с помощью указанного правила и пересчитать модель без них.
Построение доверительного интервала для нового значения зависимой переменной Теоретические основания
Одна из целей построения регрессионной модели состоит в организации прогнозирования, т.е. в ответе на вопрос «что будет, если…». Эта задача может быть решена с помощью построения доверительного интервала для нового значения зависимой переменной, которое будет отвечать интересующим исследователя условиям, т.е. определенным значениям независимых переменных. В случае линейной регрессии есть возможность получить общую формулу для границ данного интервала при выполнении нормальной гипотезы. Известно, что она имеет вид (a), x)±t1+α (T − n) s2 + x'C)x , где С – оценка
s2 + x'C)x , где С – оценка
2
ковариационной матрицы оценок значений параметров линейной регрессии, а
t1+α (T −n) |
- квантиль распределения Стьюдента порядка |
1+α |
, с ‘T-n’ степенями |
|||
2 |
||||||
|
2 |
|
|
|
||
свободы. Здесь α - уровень доверия.
Минимальные требования
Данный пункт не является обязательным.
Организация вычислений Построение модели с учетом переменной ПОРОДА (Модель №5)
Вернемся теперь к предположениям 1 и 2, которые мы сделали в самом начале работы. Напомним, что все наблюдения разбиты на две группы: к первой группе относятся чистопородные животные, ко второй – все остальные.

Основной идеей в этих предположениях была мысль о том, что существуют различия в показателе удоя и жирности молока для чистопородных и не чистопородных коров. Для того, что бы воспользоваться техникой фиктивных переменных, введем новую переменную, которая равна 1 для чистопородных коров и 0 для остальных. Тем самым за базу сравнения мы принимаем не чистопородных коров. Очевидно, что указанное преобразование достигается командой series rid=2-race. Образуем переменные взаимодействия. За основу дальнейшего анализа возьмем Модель №1. Таким образом, у нас возникает две дополнительные переменные:
-series rw=rid*weight (взаимодействие породы и веса);
-series rym=rid*yield_m (взаимодействие породы и удоя матери). Построим новую модель с учетом введенной фиктивной переменной. Таблица 16 Результаты оценивания модели №5
Dependent Variable: YIELD
Method: Least Squares
Date: 06/05/05 Time: 14:45
Sample: 1 200
Included observations: 200
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
C |
-7523.581 |
1692.846 |
-4.444338 |
0.0000 |
WEIGHT |
19.87692 |
3.271488 |
6.075804 |
0.0000 |
YIELD_M |
0.215841 |
0.139232 |
1.550230 |
0.1227 |
RID |
12.02917 |
2193.303 |
0.005484 |
0.9956 |
RW |
-2.259048 |
4.201226 |
-0.537711 |
0.5914 |
RYM |
0.292950 |
0.166674 |
1.757624 |
0.0804 |
R-squared |
0.476957 |
Mean dependent var |
4627.630 |
|
Adjusted R-squared |
0.463476 |
S.D. dependent var |
1265.533 |
|
S.E. of regression |
926.9753 |
Akaike info criterion |
16.53127 |
|
Sum squared resid |
1.67E+08 |
Schwarz criterion |
16.63022 |
|
Log likelihood |
-1647.127 |
F-statistic |
|
35.38123 |
Durbin-Watson stat |
1.898304 |
Prob(F-statistic) |
0.000000 |
|
Сравнение с результатами оценивания исходной модели показывает, что модель стала несколько хуже – увеличились значения критериев Акаики и Шварца, уменьшилось значение R2. Кроме того, все дополнительные переменные, а также переменная yield_m (удой матери) имеют незначимые коэффициенты регрессии.
|
|
|
|
|
|
|
|
|
10000 |
|
|
|
|
|
|
|
|
|
8000 |
|
|
|
|
|
|
|
|
|
6000 |
6000 |
|
|
|
|
|
|
|
|
4000 |
4000 |
|
|
|
|
|
|
|
|
2000 |
2000 |
|
|
|
|
|
|
|
|
0 |
0 |
|
|
|
|
|
|
|
|
|
-2000 |
|
|
|
|
|
|
|
|
|
-4000 |
|
|
|
|
|
|
|
|
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Residual |
Actual |
|
Fitted |
|
|||
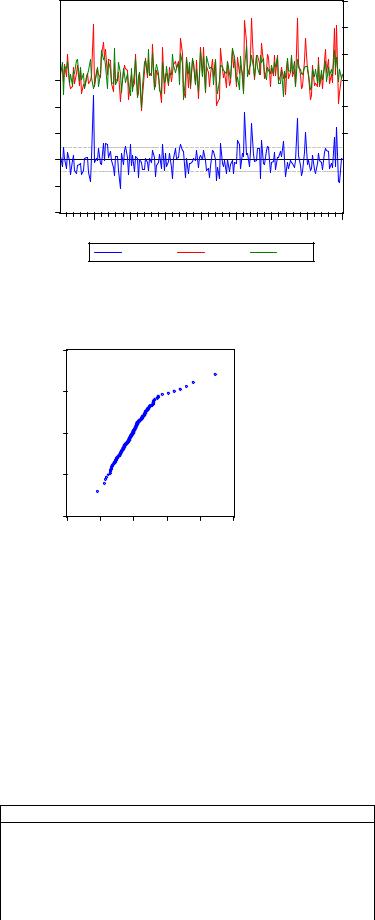
Рисунок 13. Визуальный анализ качества модели №5 Визуальный анализ свидетельствует о наличии ряда «выбросов». Ими мы
займемся позже.
Normal Quantile
4
2
0
-2
-4 -4000 -2000 0 2000 4000 6000
RESID
Рисунок 14. Анализ вида распределения с помощью нормальной кривой в модели №5
Видно, что апостериорные остаточные разности имеют асимметрию вправо, т.е. модель недооценивает значения зависимой переменной.
В целом можно сделать вывод о том, что учет породы пока не дал положительных результатов при построении модели.
Критерий Чоу
Не смотря на результаты предыдущего пункта, проведем проверку совместной значимости оценок коэффициентов дополнительных переменных.
Таблица 17 Результат проведения критерия Чоу
Wald Test:
Equation: MODEL_5
Null Hypothesis: |
C(4)=0 |
|
|
|
|
C(5)=0 |
|
|
|
|
C(6)=0 |
|
|
|
F-statistic |
1.143536 |
|
Probability |
0.332709 |
Chi-square |
3.430609 |
|
Probability |
0.329874 |