

Вибрати команду Сервіс-Настройки.
В діалоговому вікні Настройка встановити прапорець Пакет аналізу та натиснути ОК.
А
Рис.1 10 Діалогове вікно Середнього значення дозволяє
Визначити період спостережень
ктивізувати робочий лист, що містить дані.В меню Сервіс з’являється нова
команда Аналіз даних.
В діалоговому вікні Аналіз даних,
в якому містяться всі доступні
функції аналізу даних.
З’явиться діалогове вікно
Середнього значення (рис.1.10)
В полі Вхідний інтервал вводимо дані нашої базової лінії, тобто вказуємо діапазон на робочому листі.
В полі Інтервал вводимо кількість місяців, які входять в підрахунок.
В полі Вихідний інтервал вводимо адресу комірки, з якої буде починатись вихід.
Натиснути на кнопку ОК.
Програма Excel виконає роботу по внесенню значень у формулу для обрахунку. Значення середнього починаються із #Н/Д , які дорівнюють значенню вказаному вами інтервалу мінус один. Це виникає внаслідок недостатньої кількості даних для обчислення. На рис. 1.11 показано результат даного обрахунку.
Рис.1.11
Обрахунок з використанням середнього
значення

Об’єму продажу
Як правило прогнозування з використанням середнього розглядається як прогноз на період безпосередньо наступний за періодом спостереження. Наприклад, необхідно обрахувати середній прибуток від продажу за результатами трьох місяців, і останні дані спостереження включають результати за січень, лютий, березень. середнє значення цих трьох даних зазвичай вважають середнім для квітня, тобто першого місяця, безпосередньо слідую чого за результатами спостереження.
Складання прогнозу за допомогою діаграми
Найкраще наочно видно результати на графіку. Для цього необхідно:
Виділити дані своєї базової лінії
Вибрати команду Діаграма з меню Вставка
На першому етапі вибрати тип діаграми – графік та натиснути кнопку Далі.
На другому етапі роботи перевірте правильність ссилок на комірки базової лінії.
На третьому етапі виберіть параметри графіка.
На останньому, четвертому, етапі визначте місце розташування діаграми на робочому листку.
Виділіть створену вами діаграму та натисніть праву кнопку миші. В контекстному вікні, що відкриється виберіть команду Добавити лінію тренда
В діалоговому вікні, що відкриється Лінія тренда, вибираємо вкладнику Тип та виділяємо Лінійна фільтрація, а потім необхідні періоди за допомогою лічильника – Крапки. Період – це кількість спостережень, які включаються в будь-яке обчислення середнього значення.
Натискаємо кнопку ОК.
В
Рис.1.12
Графічне представлення середнього
значення
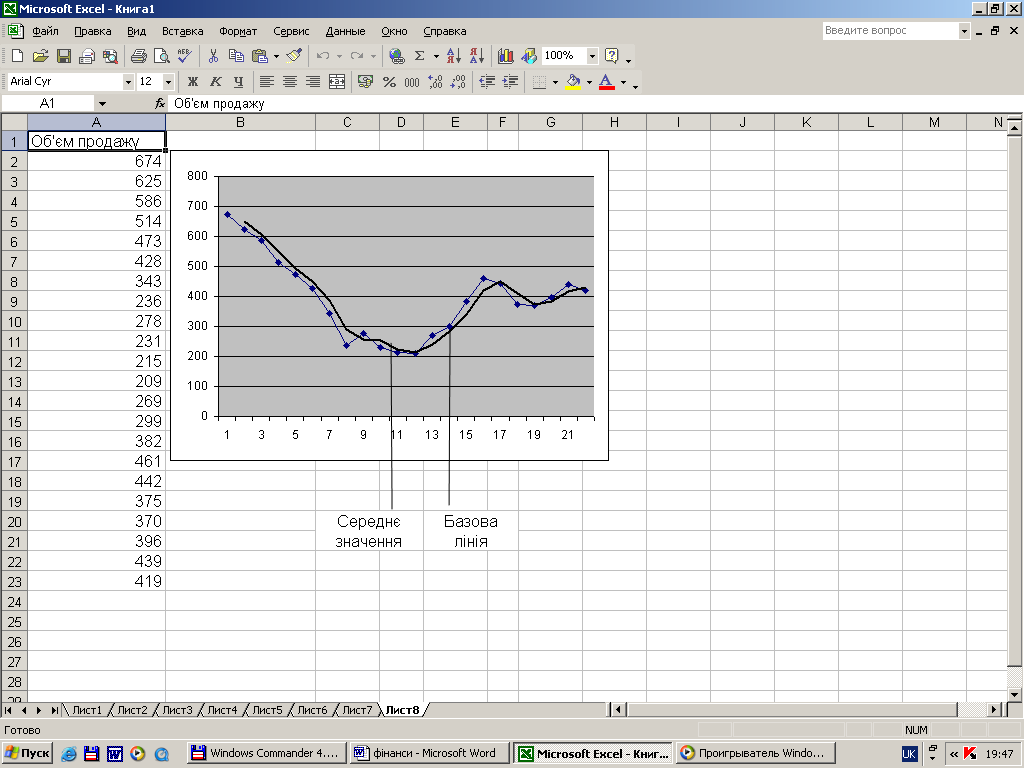
(рис. 1.12)
Прогнозування за допомогою функцій регресій Excel
Прогнозування результатів діяльності підприємства з використанням середнього значення є досить простим та швидким методом, але має деякі неточності. Він не дає прогнозу, що виходить за межі відомих даних. Це робити можна за допомогою функцій регресії Excel, які оцінюють взаємозв’язок фактичних даних спостереження та інших параметрів, які найчастіше є показниками того, коли були зроблені ці спостереження. Це можуть бути, як числові значення кожного результату спостереження в часовому ряду, так і дата спостереження.
Створення лінійний прогнозів: функція Тенденція
Використання функції робочого листа Тенденція – самий простий спосіб регресивного аналізу. Припустимо результати наших спостережень внесені в комірки А1:А10, а дні місяця розміщені в комірках В1:В10 (рис.1.13)

Виділяємо комірки С1:С10 та вводимо формулу використовуючи формулу масиву:
= ТЕНДЕНЦІЯ (А1:А10;В1:В10)
Порада |
Для введення масиву необхідно скористатись комбінацією клавіш <Ctrl+Shift+Enter>. |
Розглядаючи даний метод прогнозування, слід відмітити ряд особливостей:
1. Кожний результат в комірках С1:С10 отримується на основі однієї і тієї ж формули масиву, всередині якої схований більш складніший вираз. В даному випадку формула має наступний вигляд:
комірка С1: = 9,13+0,61*1;
комірка С2 :=9,13+0,61*2
комірка С3: =9,13+0,61*3.
Значення 9,13 – це довжина відрізку, тобто значення прогнозу в початковий момент. Значення 0,61 – це кутовий коефіцієнт лінії прогнозу, іншими словами, значення прогнозу змінюються внаслідок зміни дат проведених спостережень.
2. Оскільки всі значення прогнозу складаються на основі одних і ти самих показників відрізку та кутового коефіцієнту, прогноз не відображає змін в часовому ряді.
3. В даному прикладі функція ТЕНДЕНЦІЯ обраховує прогноз , заснований на зв’язку між фактичними результатами спостережень та числами 1-10, які можуть відображати або перші десять днів місяця або перші десять місяців року. Excel відображає перший аргумент як аргумент відомі значення – у функції ТЕНДЕНЦІЯ, а другий – як аргумент функції відомі значення – х.
Регресивний аналіз робить можливим перспективну оцінку на більш віддалений період. Однак регресивний прогноз, приклад якого наведено на рис.1.13, розповсюджується за межі самого останнього фактичного спостереження. Але на практиці бажано складати прогноз хоча б на перший наступний, тобто на той, для якого іще не має результатів спостереження. Розглянемо, як це можна зробити з використанням функції ТЕНДЕНЦІЯ.
Використовуючи дані робочого листа, представлені на рис.1.13, введемо в комірку В11 число 11, а в комірку С11- формулу:
= ТЕНДЕНЦІЯ (А1:А10;В1:В10;В11)
Аргументи А1:А10 визначають дані спостережень базової лінії ( відомі значення –у), аргументи В1:В10 – часові моменти, в яких ці дані були отримані (відомі-значення –х). Значення 11 в комірці В11 є новим – значенням - х і визначає час, який пов’язується з перспективною оцінкою.
Формулу можна констатувати так: Якщо відоме, якимось чином у-значення в діапазоні А1:А10 співвідносяться з х- значенням в діапазоні В1:В10, то який результат у- значення ми отримаємо, знаючи нове х- значення часового моменту, що рівне 11? Отримане значення 15,87 є прогнозом на основі фактичних даних на період, що іще не наступив.
Крім того, існує можливість одночасного прогнозування даних для декількох нових часових моментів. Наприклад, ввівши числа 11-24 в комірки В11:В24, а потім виділити комірки С11:С24 та ввести за допомогою формули масиву наступне:
= ТЕНДЕНЦІЯ ( А1:А10;В1:В10;В11:В24)
Програма Excel поверне в комірки С11:С24 прогноз на часовий період з 11по 24. Даний прогноз буде базуватись на зв’язку між даними спостереження базової лінії діапазону А1:А10 та часовими моментами базової лінії з 1 по 10, вказаний в комірках В1:В10.
Складання нелінійного прогнозу: функція РОСТ
Функція ТЕНДЕНЦІЯ обраховує прогноз, що ґрунтується на лінійному зв’язку між результатами спостереження та часом, коли це спостереження було зафіксоване. Припустимо, що необхідно створити лінійний графік даних, на вертикальній вісі якого знаходяться результати спостережень, а на горизонтальній розташовані часові моменти їх отримання. Якщо цей взаємозв’язок носить лінійний характер, то лінія на графіку або буде прямою, або нахилена в одну чи іншу сторону, або горизонтальною. Це буде найкращою підказкою, що взаємозалежність є лінійною, і тому в даному випадку функція ТЕНДЕНЦІЯ – самий зручний спосіб регресивного аналізу.
Однак, якщо лінія має різкий згин в одному із напрямків, це означає, що взаємозв’язок показників носить нелінійний характер. Існує велика кількість типів даних, які змінюються в часі нелінійним способом. Деякими прикладами таких даних є об’єм продажу нової продукції, приріст населення, виплати по кредиту та коефіцієнт питомого прибутку. При нелінійному взаємозв’язку функція Excel РОСТ допоможе отримати більш точну картину напрямку розвитку бізнесу, ніж функція ТЕНДЕНЦІЯ.
Ситуація для аналізу
Книжкова торгівля
Уявимо собі, що менеджер по купівлі відділу „Книга поштою” нещодавно розіслав клієнтам новий каталог, що рекламує роман, який отримав досить високу оцінку критиків. Менеджер вважає, що слід завчасно замовити додаткову кількість екземплярів, щоб не склалась ситуація, коли книги закінчаться раніше, ніж перестануть приходити заявки на них, тому він почав відслідковувати замовлення на роман та реєструвати об’єм продажу (рис.1.14). На ньому демонструється, яким чином фактичні та прогнозовані дані фіксуються в стандартному лінійному графіку. Оскільки лінія наявності товарів різко перегинається до верху, менеджер приймає рішення скласти прогноз за допомогою функції РОСТ. Як і при використанні функції ТЕНДЕНЦІЯ, користувач в даному випадку може генерувати прогнози, просто представляючи аргумент нові-значення – х. Щоб прогнозувати результати 11-13 тижня, слід ввести ці числа в комірки В12:В14, а потім за допомогою формули масиві в діапазон комірок С2:С14 ввести наступну формулу:
= РОСТ (А2:А11;В2:В11;В2:В14)

В комірках С12:С14 наведені значення попередньої оцінки кількості замовлень, яке може очікувати менеджер в наступні три тижні при умові, що поточна тенденція росту залишиться незмінною. Однак, слід врахувати, що такий оптимістичний прогноз на практиці, швидше за все буде мати певні зміни. Якщо при обрахуванні прогнозу кількості планованих замовлень перевищить кількість клієнтів, то від нього слід відмовитись.
Я
Рис.1.15
Логарифмічна залежність експоненціального
росту замовлень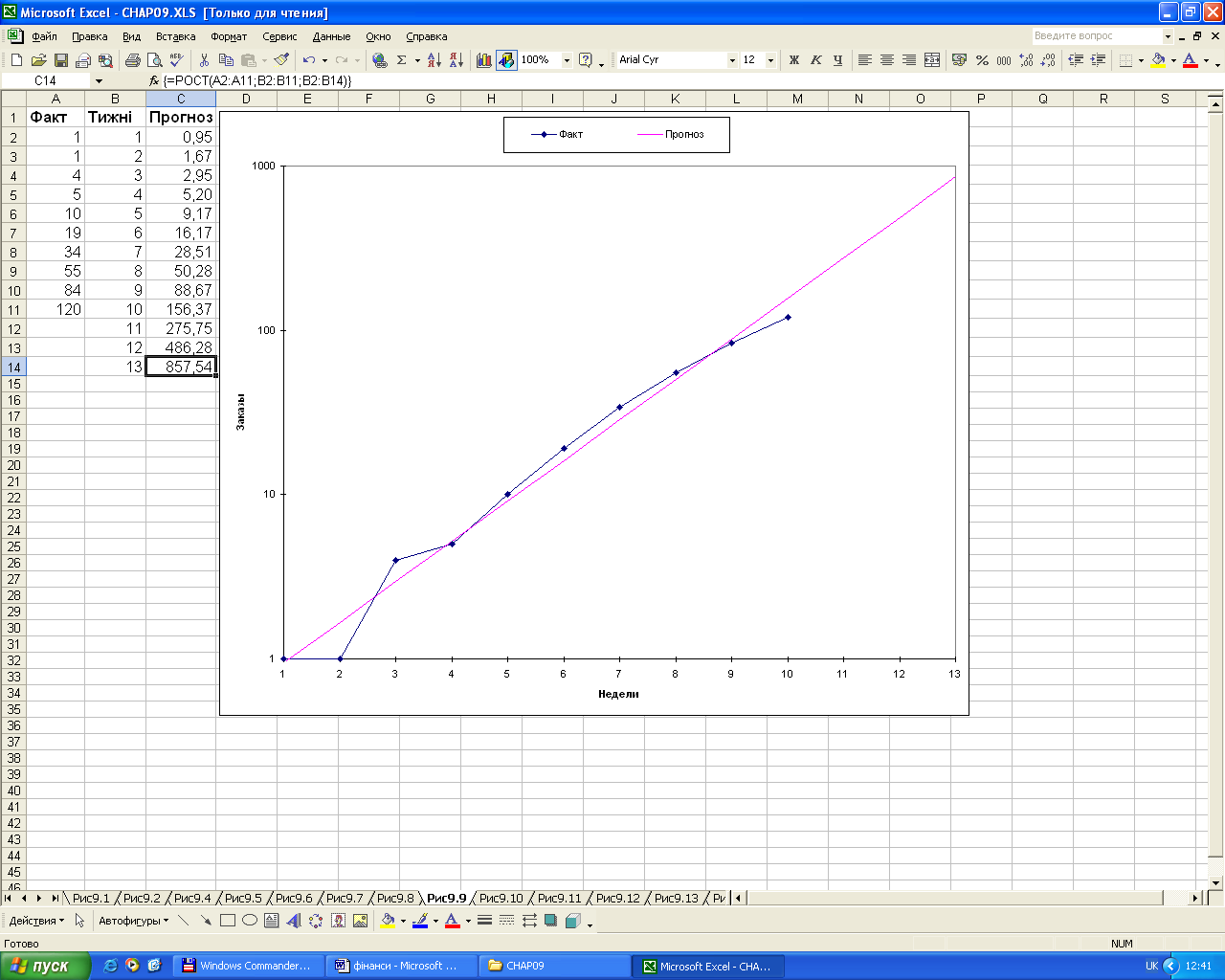
Дані по відділу „Книга поштою” представлені у вигляді вертикальної вісі графіка, шкалу вертикальної вісі якого становлять логарифмічні значення. Замість функції РОСТ можна використати функцію ТЕНДЕНЦІЯ в даному прикладі. В такому разі, оскільки аргумент відомі – значення х носять лінійний характер, то функція ТЕНДЕНЦІЯ покаже лінійні значення. На рис. 1.16 видно, що ряд ТЕНДЕНЦІЯ в стовпчику С описує пряму графіка; крива РОСТ набагато точніше відображає тенденцію перших 10 результатів спостереження ніж лінія ТЕНДЕНЦІЯ. Значення, що передбачаються функцією РОСТ, дуже близькі до реальних, а лінія РОСТ краще описує перші 10 спостережень, отриманих в процесі діяльності, ніж лінія ТЕНДЕНЦІЯ. Внаслідок, для цієї базової лінії більш точне прогнозування наступних даних з використанням функції РОСТ, а не ТЕНДЕНЦІЇ. Використання функції РОСТ вказує на те, що базова лінія не є лінійною.
Рис.1.16
Лінія Тренда побудована за допомогою
функції РОСТ
Функція РОСТ є досить зручним способом отримання специфічних логарифмічних результатів.
Регресивний аналіз з використанням діаграм
Часто при створенні прогнозу використовують діаграми, що використовуються для точнішого зображення фінансових ситуацій. Інколи виникає потреба в проведенні регресивного аналізу безпосередньо на графіку, без введення даних в робочий лист. Це можна зробити за допомогою графічної лінії тренда. Для прикладу побудуємо графік засобами Microsoft Excel на основі даних комірок А2:А25 (рис.1.17).
Виділивши діаграму можна зайти в режим її редагування. Викликавши контекстне меню за допомогою правої кнопки миші виконаємо наступні дії:
З контекстного меню вибираємо команду Додати лінію тренда.
Тип лінії тренда – Лінійна.
Відкриємо вкладку Параметри.
В полі Вперед на введемо кількість періодів, протягом яких лінія тренда буде прокладатись.
Якщо виникне потреба, можна поставити прапорець в полі Показувати рівняння на діаграмі. Внаслідок рівняння для прогнозу будуть розміщуватись на графіку у вигляді тексту.
Натиснути кнопку ОК.
Рис.1.17
Прогнозування з використанням лінії
тренда
Прогнозування з використанням функції експоненціального згладжування
Згладжування – це спосіб, що забезпечує швидке реагування прогнозу на будь-які події, що відбуваються протягом періоду протяжності базової лінії. Методи, що базуються на регресії, такі, як і функції ТЕНДЕНЦІЯ та РОСТ.
Розробка перспективних оцінок з використанням методу згладжування.
Основна мета методу згладжування полягає в тому, що кожний новий прогноз отримується внаслідок переміщення попереднього прогнозу в напрямку, який би дав кращий результат в порівнянні із попереднім прогнозом. Базове рівняння має наступний вигляд:
F [t+1] = F[t] + a * e[t], де
t - часовий період (наприклад, 1-й місяць, 2-й місяць і т.д.);
F [t] – прогноз, виконаний в момент часу t;
F[t+1] – відображає прогноз у часовий період, безпосередньо за моментом часу t;
а – константа згладжування;
е [t] – погрішності, тобто відмінність між прогнозом, створеним в момент часу t та фактичними результатами спостереження в момент часу t.
Таким чином, константа зглажування є самокорегуючою величиною. Іншими словами, кожний новий прогноз являє собою суму попереднього прогнозу та поправочного коефіцієнта, який і передвигає новий коефіцієнтв напрямку роблячи попередній результат більш точним.
Методи прогнозування під назвою „зглажуванням” враховують ефекти скачку функції набагато краще, ніж методи регресивного аналізу. Excel безпосередньо підтримує один з таких методів за допомогою засобу Експоненціальне зглажування в надбудові Пакет аналізу. Аналізувати засіб Експоненціальне згладжування можна вибравши команду Сервіс- Аналіз даних після завантаження надбудови Пакет аналізу.
Ситуація для аналізу
Прокат автомобілів
Уявимо собі, що ми керуємо агентством із прокату автомобілів, що розміщене в гірсій місцевості. По мірі наближення зими прослідковується надходження заявок клієнтів на транспорт з багажником для перевезення лиж. Через декілька днів після проведення дослідження в нашій місцевості випадає дуже багато снігу, і як правило, очікувана кількість заявок різко зростає. Отже, на десятий дань спостереження нам необхідно дізнатись скільки необхідно приготувати автомобілів, щоб повністю задовольнити попит на одинадцятий день.
Для цього необхідно ввести дані за перші 10 днів в комірки А1:А11 робочого листа, а потім активізувати засіб Excel Експоненціальне згладжування. Потім використаємо дані діапазону комірок А1:А11 в якості параметра Вхідний інтервал, встановимо прапорець Мітки, комірку В2 використаємо в якості параметра Вихідний інтервал, а значення 0,7 – в якості параметра Фактор затухання (рис.1.18).
Фактор затухання в діалоговому вікні Експоненціальне згладжування та константа згладжування зв’язані між собою так:1 – константа згладжування = фактор затухання
Таким чином, якщо відомий фактор затухання, то це означає що можна обрахувати константу згладжування та навпаки. Excel проводить обчислення за допомогою параметру Фактор затухання.
Порада |
Щоб скласти прогноз на період, що слідує за останнім показником базової лінії, необхідно ввести в поле Вхідний інтервал діалогового вікна Експоненціальне згладжування на один рядок більше ніж потрібно |
Рис.1.18
Дані про прокат автомобілів внаслідок
прогнозування за допомогою згладжування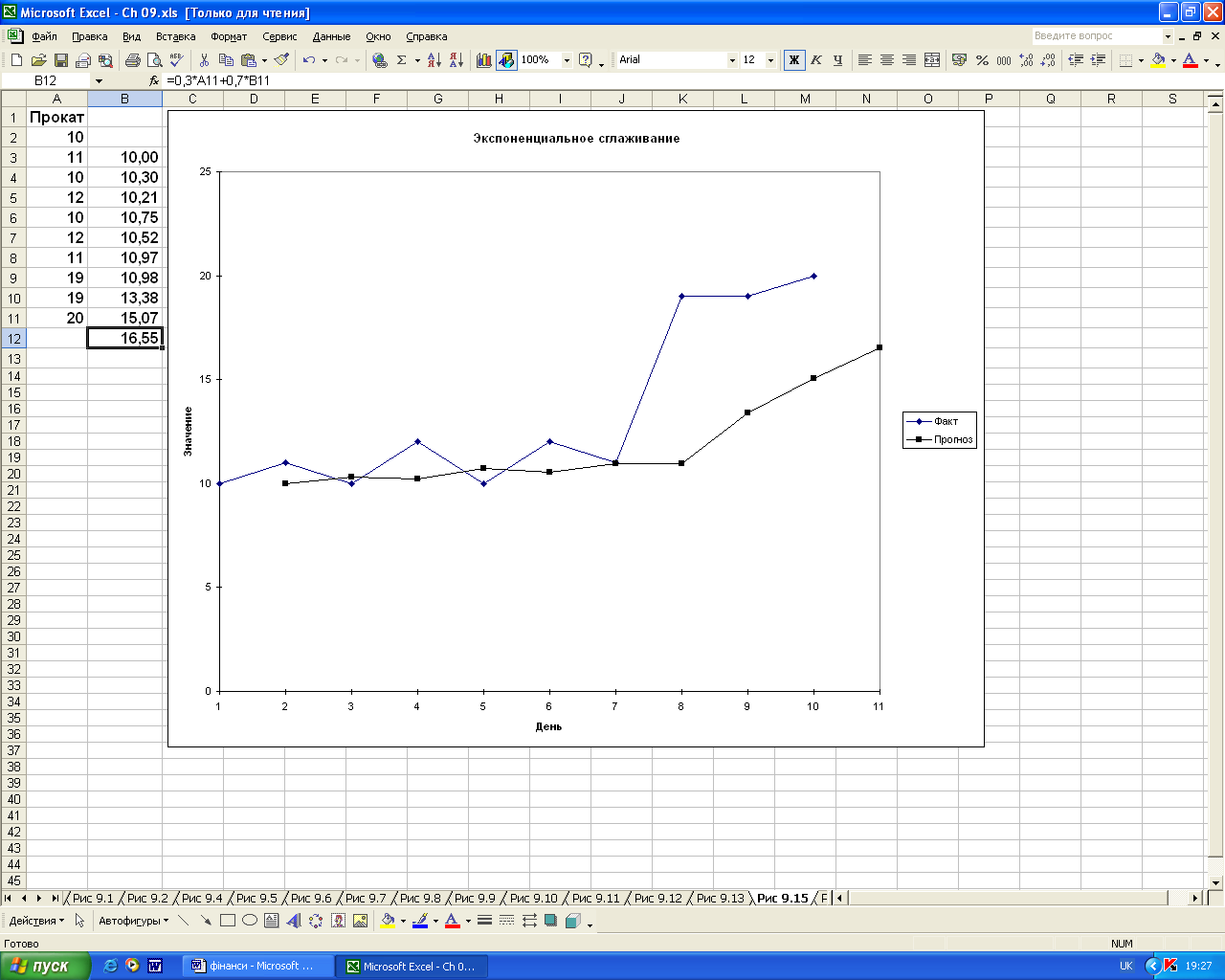
Згідно даних прогнозу, для задоволення потреб клієнтів на одинадцятий день потрібно мати шістнадцять або сімнадцять автомобілів з багажниками для лиж. Така оцінка відображає як загальний рівень даних базової лінії, так і збільшення кількості заявок, що надійшли на восьмий день спостережень. Фактичне число заявок в одинадцятий день може впасти на декілька одиниць за багатьма причинами, починаючи із зміни погодних умов та закінчуючи підвищенням цін на квитки і т.д. Прогноз за допомогою згладжування дозволяє найбільш вигідно збалансувати наплив заявок із середнім показником кількості заявок протягом всього десятиденного періоду.
При виконанні прогнозування слід уникати параметру Фактор затухання менший значення 0,7. Якщо це так, то необхідно скористатись методом автокореляції.
Автокореляція є досить важливим параметром процесу прогнозування. Вона спостерігається в тих випадках, коли існує залежність між даними спостережень, отриманими в певний час і даними спостереженнями, отриманими на декілька часових періодів раніше. Наприклад, якщо обёєднати кожний результат спостереження з попереднім результатом, то можна обрахувати кореляцію між цими двома наборами даних. Значення кореляції, яке буде не менше 0,5, означає високий рівень автокореляції. Саме автокореляція, тобто залежність між попередніми та наступними спостереженнями, служить джерелом прогнозів, що базуються на регресії. Однак, якщо в наборі даних базової лінії за певний період часу відзначається значний вплив автокореляції, прогнозування за допомогою згладжування не дасть достовірних результатів.
Для проведення перевірки автокореляції можна скористатись функцією КОРЕЛ. Припустимо, що базова лінія включає діапазон комірок А1:А10. Функція матиме вигляд:
= КОРЕЛ (А1:А9;А2:А10)
Дану функцію можна використати для оцінки автокореляції між кожним результатом спостереження та попереднім періодом.Якщо показник автокореляції високий, значить, кожний результат в більшій мірі залежить від значення спостереження, отриманого безпосередньо перед цим.
Якщо автокореляція в базовій лінії не сильно велика, то оптимальну постійну згладжування можна отримати за допомогою засобу Пошук рішення. Принцип такого підходу полягає в тому, щоб обрахувати величину погрішності в прогнозах з використанням однієї згладжуючої сталої, а потім налаштувати Пошук рішень на мінімізацію цього значення погрішності шляхом зміни сталої згладжування. Для цього необхідно виконати ряд дій (рис. 1.18):
Додати засіб Пошук рішень.
В комірку В15 ввести формулу = КОРІНЬ (СУММРАЗНКВ(А3:А11;В3:В11)/9)
присвоїти одній із комірок ім’я Стала Згладжування та ввести в неї значення 0,3.
Присвоїти іншій комірці ім’я Фактор Затухання та ввести в неї формулу = 1 – Постійна Згладжування.
Вибрати команду Сервіс- Пошук рішення. Ввести В15 в поле Установити цільову комірку та встановити перемикач на мінімальне значення в групі Рівно. В полі Зміни комірки необхідно вказати ім’я Постійна Згладжування. Потім необхідно натиснути кнопку Виконати.
Формула в комірці В15 обраховує так званий корінь середньої квадратичної погрішності. В цій формулі використовується функція робочого листка СУММРАЗНКВ, яка повертає різницю між дійсними спостереженнями та згладженими прогнозами, піднесену до квадрату, - це квадратична погрішність. Потім формула ділить отримане значення на кількість прогнозів та витягує квадратний корінь із отриманого результату. Корінь середньої квадратичної погрішності є стандартною зміною погрішності в прогнозуванні. При використанні засобу Пошук рішення прораховуються різноманітні значення постійної згладжування до тих пір, поки не буде знайдено таке, яке мінімізує корінь середньої квадратичної погрішності, тобто значення, яке дає найбільш точний згладжений прогноз.