

1) Объект и идентификатора объекта
Любая сущность реального мира в объектно-ориентированных языках и системах моделируется в виде объекта.
В реляционной модели сущности реального мира представляются в виде набора двух мерных таблиц – в данном случае описания может быть гораздо сложнее.
Любой объект при своем создании получает генерируемый системой уникальный идентификатор, который связан с объектом во все время его существования и не меняется при изменении состояния объекта
(2) атрибуты и методы
Каждый объект имеет состояние и поведение.
1) Состояние объекта - набор значений его атрибутов.
Значение атрибута объекта - это тоже может быть некоторый объект или даже множество объектов.
Если в реляционной модели любой атрибут является атомарным, то в данной случае поддерживается иерархия вложенности.
2) Поведение объекта - набор методов (программный код), оперирующих над состоянием объекта.
Данный элемент отсутствует в реляционной модели.
Состояние и поведение объекта инкапсулированы в объекте; взаимодействие между объектами производится на основе передачи сообщений и выполнении соответствующих методов.
Инкапсуляция — это принцип, согласно которому любой объект должен рассматриваться как «чёрный ящик»:
пользователь должен видеть и использовать только интерфейсную часть (т.е. список декларируемых свойств и методов) и не вникать в его внутреннюю реализацию.
доступ к данным по чтению или записи осуществлялся не напрямую, а с помощью методов.
Сокрытие данных — часть объектно-ориентированного подхода, управляющая областями видимости. Является логическим продолжением инкапсуляции.
целью сокрытия - невозможность для пользователя испортить внутреннее состояние объекта.
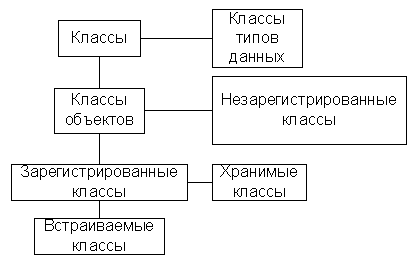
(3) классы
Множество объектов с одним и тем же набором атрибутов и методов образует класс объектов. Объект должен принадлежать только одному классу.
Допускается наличие примитивных предопределенных классов, объекты-экземпляры которых не имеют атрибутов: целые, строки и т.д.
Класс, объекты которого могут служить значениями атрибута объектов другого класса, называется доменом этого атрибута
(4) иерархия и наследование классов
|
Принцип наследования - одна из наиболее важных черт объектно-ориентированной модели. Наследование - процесс порождение нового класса на основе уже существующего класс.
|

Различаются случаи простого и множественного наследования.
В первом случае подкласс может определяться только на основе одного суперкласса. Если в языке или системе поддерживается единичное наследование классов, набор классов образует древовидную иерархию.
Во втором случае суперклассов может быть несколько. Объект подкласса считается принадлежащим любому суперклассу этого класса.
|
Классы типов данных подразделяется на два подкласса типов:
Атомарными классами типов обычно являются традиционные скалярные типы данных (строки, даты, числа, деньги и др.). Структурированные классы типов данных - списки, массивы… Классы объектов делятся на:
Зарегистрированные классы обладают предопределенным поведением, т.е. фиксированным набором методов. Незарегистрированные классы не обладают предопределенным поведением, разработка функций (методов) класса целиком и полностью возлагается на разработчика. Зарегистрированные классы могут быть двух типов:
|
Основной особенностью хранения встраиваемого класса является то, что объекты встраиваемых классов существуют в памяти как независимые экземпляры, однако могут быть сохранены в базе данных, только будучи встроены в другой класс. |
|
* 4 -соответствие
62. Укажите соответствие элементов объектно-ориентированной модели (слева) и элементов реляционной модели (справа).
Объектное понятие |
Реляционное понятие |
Класс |
Таблица |
Экземпляр |
Строка |
Идентификатор объекта (OID) |
ID-столбец в виде первичного ключа |
Свойство-константа |
Столбец |
Ссылка на хранимый объект |
Внешний ключ |
Встраиваемый объект |
Индивидуальные столбцы |
Индекс |
Индекс |
* 2 -несколько правильных ответов
63. Объектно-ориентированный подход. Наследование – это процесс порождение нового класса на основе уже существующего класса (суперкласса). Укажите его отличительные черты:
В этом случае новый класс, называемый подклассом существующего класса (суперкласса), наследует все атрибуты и методы суперкласса.
В подклассе, кроме того, могут быть определены дополнительные атрибуты и методы.
* 2 -несколько правильных ответов
64. Отметьте способы реализации распределенной БД в локальной компьютерной сети:
(1-1) Файловый сервер
Данный подход впервые реализован фирмой Novell в продукте Netware.
Основное достоинство: минимальные требования к ресурсам сервера
Недостатки: 1) основной комплекс программ на клиентской станции, что предъявляет повышенные требования к ее ресурсам и 2) высокая интенсивность трафика по ЛВС.
(1-2) Распределенный файловый сервер.
Вариант применяется для снижения нагрузки на ЛВС путем разделения данных. При этом часть БД доступна только на локальной машине.
(2-1) SQL-сервер БД
Наиболее часто используемый вариант для средних и крупных баз данных.
В качестве основного интерфейса между клиентской и серверной частями выступает язык баз данных SQL - стандарт интерфейса СУБД в открытых системах.
Серверы баз данных, интерфейс которых основан исключительно на языке SQL, обладают своими преимуществами и своими недостатками.
(+) Очевидное преимущество - стандартность интерфейса. Клиентские части любой SQL-ориентированной СУБД могут работать с любым SQL-сервером вне зависимости от того, кто его произвел.
(-) Недостаток тоже довольно очевиден. При таком высоком уровне интерфейса между клиентской и серверной частями системы на стороне клиента работает слишком мало программ СУБД.
(2-2) Распределенный SQL-сервер. При этом часть БД кэшируется на локальной машине и затем переносится в ОСНОВНУЮ ЧАСТЬ!!!
0) В типичном на сегодняшний день случае на стороне клиента СУБД работает только такое программное обеспечение, которое не имеет непосредственного доступа к базам данных, а обращается для этого к серверу с использованием языка SQL.
1) В некоторых случаях хотелось бы включить в состав клиентской части системы некоторые функции для работы с "локальным кэшем" базы данных, т.е. с той ее частью, которая интенсивно используется клиентской прикладной программой.
2) С другой стороны, иногда хотелось бы перенести большую часть прикладной системы на сторону сервера, если разница в мощности клиентских рабочих станций и сервера чересчур велика.
(3) Сервер приложений
Используется при применении дорогих (количество лицензий) и ресурсоемких прикладных программ.
* 2 -несколько правильных ответов
65. Термин "сервер баз данных" используют для обозначения всей БД, основанной на архитектуре "клиент-сервер". Он включает следующие компоненты:
Представление данных – клиентская часть, образующая интерфейс пользователя с базой данных.
Приложение – прикладная программа, реализующая необходимые прикладные функции для работы с базой данных.
Доступ к ресурсам – работа с данными, расположенными на физическом носителе.
* 4 -соответствие
66. Укажите соответствие способов реализации распределенной БД в локальной сети, приведенным справа характеристикам:
(1-1) Файловый сервер
Данный подход впервые реализован фирмой Novell в продукте Netware.
Основное достоинство: минимальные требования к ресурсам сервера
Недостатки: 1) основной комплекс программ на клиентской станции, что предъявляет повышенные требования к ее ресурсам и 2) высокая интенсивность трафика по ЛВС.
(1-2) Распределенный файловый сервер.
Вариант применяется для снижения нагрузки на ЛВС путем разделения данных. При этом часть БД доступна только на локальной машине.
(2-1) SQL-сервер БД
Наиболее часто используемый вариант для средних и крупных баз данных.
В качестве основного интерфейса между клиентской и серверной частями выступает язык баз данных SQL - стандарт интерфейса СУБД в открытых системах.
Серверы баз данных, интерфейс которых основан исключительно на языке SQL, обладают своими преимуществами и своими недостатками.
(+) Очевидное преимущество - стандартность интерфейса. Клиентские части любой SQL-ориентированной СУБД могут работать с любым SQL-сервером вне зависимости от того, кто его произвел.
(-) Недостаток тоже довольно очевиден. При таком высоком уровне интерфейса между клиентской и серверной частями системы на стороне клиента работает слишком мало программ СУБД.
(2-2) Распределенный SQL-сервер. При этом часть БД кэшируется на локальной машине и затем переносится в ОСНОВНУЮ ЧАСТЬ!!!
0) В типичном на сегодняшний день случае на стороне клиента СУБД работает только такое программное обеспечение, которое не имеет непосредственного доступа к базам данных, а обращается для этого к серверу с использованием языка SQL.
1) В некоторых случаях хотелось бы включить в состав клиентской части системы некоторые функции для работы с "локальным кэшем" базы данных, т.е. с той ее частью, которая интенсивно используется клиентской прикладной программой.
2) С другой стороны, иногда хотелось бы перенести большую часть прикладной системы на сторону сервера, если разница в мощности клиентских рабочих станций и сервера чересчур велика.
(3) Сервер приложений
Используется при применении дорогих (количество лицензий) и ресурсоемких прикладных программ.
* 4 -соответствие
67. Для каждого из трех сценариев реализации WWW-доступа к БД укажите отличительную характеристику:
Однократное или периодическое преобразование содержимого БД в статические документы
В этом варианте содержимое БД просматривает специальная программа (преобразователь), создающая множество файлов – связных HTML-документов (рис.06P2-1). Полученные файлы копируются на WWW-сервер. Доступ к ним осуществляется как к статическим гипертекстовым документам сервера.
(+) Этот вариант характеризуется минимальными начальными расходами.
(+) Он эффективен на небольших массивах данных простой структуры и редким обновлением,
(-) Пониженные требования к актуальности данных, предоставляемых через WWW.
(-) Полное отсутствие механизма поиска, хотя возможно использование индексирования.
В качестве преобразователя может выступать программное обеспечение, автоматически или полуавтоматически генерирующее статические документы.
Программа-преобразователь может являться самостоятельно разработанной программой, либо быть интегрированным средством из числа существующих на рынке разнообразных программ типа генераторов отчетов.
Динамическое создание гипертекстовых документов на основе содержимого БД
В этом варианте доступ к БД осуществляется с помощью специальной программы, запускаемой WWW-сервером в ответ на запрос WWW-клиента. Эта программа, обрабатывая запрос, просматривает содержимое БД и создает выходной HTML-документ, возвращаемый клиенту (рис.06p2-2).
(+) Это решение эффективно для больших баз данных со сложной структурой и при необходимости поддержки операций поиска.
(+) Данный вариант эффективен также при частом обновлении и невозможности синхронизации преобразования БД в статические документы с обновлением содержимого.
(+) В этом варианте можно осуществлять изменение БД из WWW-интерфейсов.
(-) Большое время обработки запросов,
(-) Необходимость постоянного доступа к основной базе данных,
(-) Дополнительная загрузка средств поддержки БД, связанная с обработкой запросов от WWW-сервера.
(-) Необходимость специальных мер защиты данных
Для реализации такой технологии необходимо использовать взаимодействие WWW-сервера с запускаемыми программами или ряд других технологий. Выбор программных средств для их реализации в настоящее время достаточно широк –
это универсальные языки программирования (C, Perl),
интегрированные средства типа генераторов отчетов.
При использовании современных реляционных СУБД с внутренними языками программирования возможно использования этого языка для генерации документов.
Создание информационного хранилища на основе высокопроизводительной СУБД с языком запросов SQL
Наилучшим вариантом с точки зрения перспективы развития для рассматриваемой системы является использование технологии, получившей название "информационного хранилища" (ИХ), с периодической загрузкой данных в хранилище из основных СУБД.
Для обработки разнообразных запросов, в том числе и от WWW-сервера, используется промежуточная БД высокой производительности.
Информационное наполнение промежуточной БД осуществляется специализированным программным обеспечением на основе содержимого основных баз данных и включает два этапа:
перегрузка данных (рис.06P2-3);
обработка запросов (рис.06P2-4).
Данный вариант свободен ото всех недостатков предыдущей схемы. Несмотря на кажущуюся громоздкость такой схемы, для задач обеспечения WWW-доступа к содержимому нескольких баз данных накладные расходы существенно уменьшаются.
Основой повышения производительности обработки WWW-запросов и резкого увеличения скорости разработки WWW-интерфейсов является использование внутренних языков СУБД информационного хранилища для создания гипертекстовых документов.
Для загрузки содержимого основной БД в информационное хранилище могут использоваться все перечисленные решения (языки программирования, интегрированные средства), а также специализированные средства перегрузки, поставляемые с SQL-сервером и продукты поддержки информационных хранилищ.
* 2 -несколько правильных ответов
68. Цель Semantic Web - реализация возможности машинной обработки информации, доступной в Интернет. В основе Semantic Web лежит использование:
во-первых, универсальных идентификаторов ресурсов (URI),
во-вторых — онтологий и языков описания метаданных.
* 5 -последовательность
69. Расставьте первые четыре уровня архитектуры Semantic Web (от простого к сложному):
(1) Первый уровень – объекты
URI и Unicode – адресация всех объектов, представленных (упоминаемых) в WEB. Кодировка Unicode (2-х байтная кодировка) обеспечивает стандартную поддержку всех существующих национальных кодировок (языков).
Внизу пирога находятся уникальные идентификаторы ресуров (URI). Предназначение URI:
Создать пространство имён виртуальных ресурсов, достаточное для представления в web всех важных объектов реального мира.
Избежать неоднозначности в именовании ресурсов в web.
Semantic Web предоставляет средства для того, чтобы говорить об объектах. Возьмем, к примеру, следующее высказывание: Иванов Павел Сергеевич знает Губанову Марфу Андреевну. Данное высказывание можно интерпретировать по-разному, ведь никто не гарантирует уникальность имен объектов (Павел и Марфа) и отношений между ними (знать). URI нужны именно для такой гарантии.
http://ivanovpavel.spb.ru –> http://xmlns.com/foaf/0.1/knows --> http://marphaemc.com
Делится на два семейства:
URN (Uniform Resource Name) - позволяет идентифицировать ресурс, но не указывает на его местоположение.
URL (Uniform Resource Locator) - указывает на способ получения доступа к ресурсу.
(2) Второй уровень – описание данных и их представлений.
XML — текстовый формат, предназначенный для хранения структурированных данных (взамен существующих файлов баз данных), для обмена информацией между программами, а также для создания на его основе более специализированных форматов обмена данными. На сегодня в семействе XML есть целая куча форматов, предназначенных для различных целей.
XML предоставляет синтаксис для определения структуры документа, подлежащего машинной обработке. Синтаксис XML не несёт семантической нагрузки.
XML Schema определяет ограничения на структуру XML-документа. Стандартный синтаксический анализатор языка XML в состоянии проверить произвольный XML-документ на соответствие его структуры так называемой схеме документа, описанной в XML Schema.
(3) Третий уровень - задача построить максимально полную модель отношений всех объектов, описанных URI и представленных в Web
RDF представляет собой простой способ описания данных в формате субъект-отношение-объект, в котором в качестве любого элемента этой тройки используются только идентификаторы ресурсов.
Существует стандартизованное отображение этих троек на XML-документы предопределённой структуры (т.е. консорциумом W3 определена схема XML-документов, содержащих RDF-описания), а также на другие форматы представления (например, в нотацию N3).
(4) Уровень 4. Формирование онтологий (понятий и терминов) на основе троек RDF
OWL - это логический язык для формального описания онтологий. OWL предоставляет средства для логического описания семантики (т.е. смысла) понятий, благодаря чему последние могут согласованно использоваться как людьми, так и приложениями в различных информационных системах (Web-сайтах, базах данных, экспертных системах, системах поддержки принятия решений и т.д.).
Выражаясь неформально, OWL позволяет гарантировать, что в условиях высокой гетерогенности современных информационных систем, термины, объявленные в одной системе, будут корректно интерпретированы в другой системе, причем независимо от технических особенностей систем и сценариев работы с ними
Русский перевод описания OWL тут: http://zajtcev.org/docs/w3c/ru/REC-owl2 … 91027.html
(5-7) Уровни 5-7 (пока только прорабатываются на концептуальном уровне).
Цифровые подписи
Для того, чтобы контролировать целостность передаваемых документов, защищаться от подделки данных, доказывать авторство документа в семантическом вебе существует слой цифровых подписей. Мы не будем про него много говорить, так как здесь пользователи семантик веба удовлетворяются уже существующими алгоритмами и ПО.
(5) ЛОГИКА
Когда мы говорим о представлении знаний и разрабатываем языки представления, надеясь, что из одних фактов мы будем получать другие, нам недостаточно неформальных определений семантики. Логический слой семантического веб служит именно для того, чтобы предоставить однозначную трактовку для языков представления знаний.
Здесь была выбрана так дескрипционная логика - формализм, позволяющий описывать объекты в терминах объектов, свойств объектов и их классов. OWL базируется именно на этом формализме, а уровень Logic представлен программами, позволяющими осуществлять логический вывод одних фактов из других
(6) На уровне Proof должны находиться средства, позволяющие дать объяснения выведенных фактов на RDF.
(7) На уровне Trust должны находиться средства, позволяющие для пользователя доверять одним источникам и не верить другим.
* 1 -один правильный ответ
70. К какой нереляционной модели данных относится понятие «многомерная база данных»
NoSQL