

Обработка эксперим данных Роганов
.pdfПостроение доверительного интервала для математического
ожидания |
а при известной дисперсии σ2 |
нормально распределенной |
|
генеральной совокупности. |
|
|
|
|
Пусть выборка |
X1, X2 , ..., Xn |
состоит из независимых |
нормально |
распределенных |
с параметрами |
а и σ случайных величин, |
причем σ известно, а величину а оцениваем по выборке:
a ≈ X = 1 ∑n Xk . n k =1
Оценим точность этого приближенного равенства, т.е. укажем границы (доверительные пределы), в которых практически достоверно лежит
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
неизвестное |
число |
а. Сумма |
|
ζn = ∑ξk |
независимых |
|
нормально |
|||||||
|
|
|
|
|
k =1 |
|
|
|
|
|
|
|
|
|
распределенных с параметрами |
а |
и |
σ |
случайных |
величин ξ1, ..., ξn |
|||||||||
распределена |
также |
нормально |
с |
математическим |
ожиданием |
а и |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
n |
|
среднеквадратичным |
отклонением |
σ |
n , |
а |
величина |
|
|
= |
∑Xk |
|||||
X |
||||||||||||||
|
n |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
k =1 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
распределена нормально с математическим ожиданием а и
среднеквадратичным отклонением σ /  n . Поэтому
n . Поэтому
|
|
P( |
|
|
|
|
<ε)= |
1 |
ε |
n /σ |
|
ε |
n |
|
|
|
|
|
|
|
|
|
∫e |
−x2 / 2 |
|
||||||
|
|
X −α |
|
|
|
|
|
|
|
−1 |
|||||
|
|
|
2π −ε |
|
dx = 2Φ |
σ |
|
||||||||
где Φ(x)= |
1 |
x |
|
|
n /σ |
|
|
|
|||||||
e−t2 / 2dt |
– стандартная нормальная функция распределения. |
||||||||||||||
|
2π |
−∞∫ |
|
|
|
|
|
|
|
|
|
|
|||
Зададим |
коэффициент доверия |
|
|
таким, |
чтобы событие с |
||||||||||
вероятностью можно было считать практически достоверным, и пусть t
– корень уравнения 2Φ(t )−1 = , который можно найти |
по таблицам |
|
|
x |
|
нормальной функции распределения или функции Лапласа |
21π ∫0 |
e−t2 / 2dt . |
101
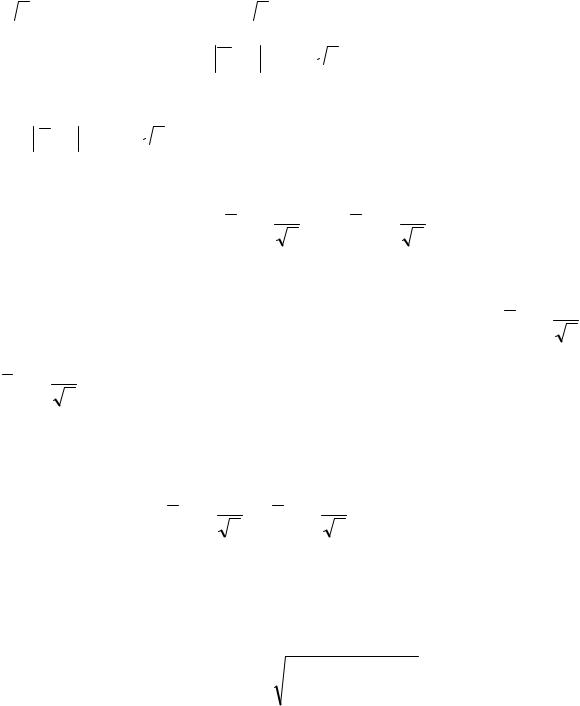
Например, при = 0,999 имеем t = 3,29 . Определим из условия
ε n / σ = t число ε : ε = t σ /
n / σ = t число ε : ε = t σ /  n . Для данного ε
n . Для данного ε
P(X −α < t σ /  n )= 2Φ(t )−1 =
n )= 2Φ(t )−1 =
Таким образом, практически достоверно ( точнее, с вероятностью ),
что X −a < t σ /  n , где 2Φ(t )−1 = . Последнее неравенство запишем в
n , где 2Φ(t )−1 = . Последнее неравенство запишем в
виде |
|
|
|
|
|
|
|
|
|
|
|
X −t |
σ |
< a < X +t |
σ |
. |
|
(10) |
|
|
|
n |
n |
|
|
||||
|
|
|
|
|
|
|
|
||
Получена так называемая классическая оценка. |
|
|
|
||||||
Таким |
образом, интервал |
со |
случайными |
концами X −t |
σ |
и |
|||
|
|
|
|
|
|
|
|
n |
|
X +t σ |
с вероятностью |
покрывает неизвестное значение a = MXk . |
|||||||
n |
|
|
|
|
|
|
|
|
|
Этот интервал является доверительным интервалом для |
а, |
||||||||
соответствующим |
коэффициенту доверия . Доверительные пределы в |
||||||||
этом случае таковы: |
X −t σ |
и |
X +t σ . |
|
|
|
|
||
|
|
n |
|
n |
|
|
|
|
|
Оценка (10) предполагает известным среднее квадратичное отклонение σ , которое на практике чаще всего бывает неизвестно. Если величину σ в неравенстве (10) заменить ее приближенным значением
σ ≈ |
1 |
∑n [X k − |
|
]2 |
|
X |
|||||
|
|||||
|
n −1 k=1 |
||||
то коэффициент доверия оценки (10) уменьшится. Поэтому если величина σ неизвестна, используют другой способ построения доверительного интервала для математического ожидания.
Построение доверительного интервала для математического ожидания а при неизвестной дисперсии σ2 нормально распределенной
102
генеральной совокупности. Для построения доверительного интервала воспользуемся следующей леммой.
Лемма. |
В выборке |
|
X1, X2 , ..., Xn |
|
из |
нормально |
|
распределенной |
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
n |
|
|
|
|
|
|
генеральной совокупности выборочное среднее |
|
|
= |
∑Xk и выборочная |
||||||||||||||||||
X |
||||||||||||||||||||||
|
n |
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
k =1 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
дисперсия |
S 2 |
= 1 ∑n [X k − |
|
]2 |
взаимно независимы. Величина |
|
|
|
распределена |
|||||||||||||
X |
||||||||||||||||||||||
Х |
||||||||||||||||||||||
|
|
n k =1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
нормально |
с |
параметрами |
а |
и σ / |
n , |
а |
величина |
nS2 / σ2 |
имеет |
|||||||||||||
распределение χn2−1 с (n −1) степенями свободы. |
|
|
|
|
|
|
|
|
||||||||||||||
Рассмотрим |
две величины |
Z = |
n(X −α)/σ |
и V = nS2 / σ2 , которые |
||||||||||||||||||
согласно |
лемме |
независимы, |
причем |
Z |
распределена |
нормально с |
||||||||||||||||
параметрами 0 и 1, а V |
распределена по закону |
χn2−1 с |
(n −1) степенями |
|||||||||||||||||||
свободы. |
В |
этом |
случае |
величина |
ζ = (Z / |
V ) |
n −1 = X −α |
n −1 |
имеет |
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
S |
|
|
|||
распределение Стьюдента с (n −1) степенями свободы. Зададим коэффициент доверия и предположим, что t – корень уравнения
∫t Sn−1 (x)dx = ,
−t
где Sn−1 (x) – плотность распределения вероятностей закона Стьюдента с (n −1) степенями свободы. Для значения t , которое находится из таблиц,
имеем
P(ζ < t )= t∫Sn−1 (x)dx =
−t
Таким образом, с коэффициентом доверия выполняется неравенство
|
ζ |
|
< t или |
X −a |
n −1 < t . Преобразуя последнее неравенство, получаем |
|
|
||||
|
|
|
|
S |
|
|
|
|
|
|
103
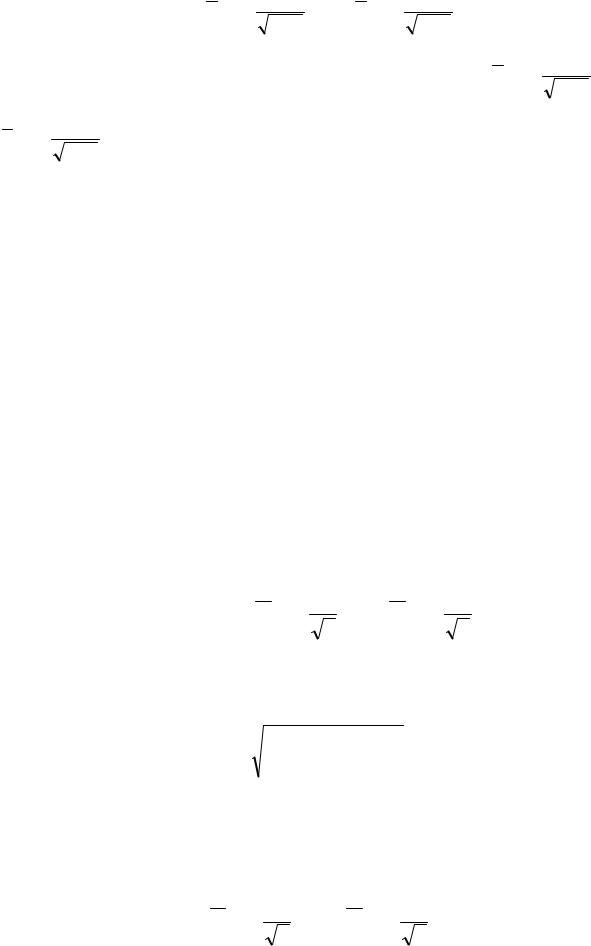
|
|
X −t |
|
S |
< a < X +t |
S . |
|
|
|
|
|
|
|
n −1 |
|
n −1 |
|
|
|
||
Итак, |
случайный интервал |
с |
концами в |
точках |
X −t |
S |
и |
|||
n −1 |
||||||||||
|
|
|
|
|
|
|
|
|
||
X +t |
S |
с вероятностью |
|
содержит |
внутри |
себя неизвестное |
||||
n −1 |
||||||||||
|
|
|
|
|
|
|
|
|
||
значение а. Таким образом, построен доверительный интервал для величины а, соответствующий коэффициенту доверия .
Построение доверительного интервала для математического ожидания а в случае ненормально распределенной генеральной совокупности. Каков бы ни был закон распределения независимых одинаково распределенных случайных величин ξ1, ξ2 , ..., ξn , имеющих
n
конечную дисперсию, их сумма ζn = ∑ξk распределена приближенно
k =1
нормально при достаточно больших (согласно центральной предельной теореме). Оценка (10) имеет место с вероятностью, близкой к при достаточно больших n , и в случае, когда закон распределения генеральной совокупности не является нормальным, т.е.
|
σ |
<α < X +t |
σ |
≈ |
(11) |
P X −t |
n |
|
|||
|
|
n |
|
|
Здесь предполагается известным значение σ . Если же σ неизвестно, то можно использовать оценку величины σ по выборке
σ ≈ |
1 |
∑n [X k − |
|
]2 =σ * |
|
X |
|||||
|
|||||
|
n −1 k=1 |
||||
и заменить в равенстве (11) неизвестную величину σ величиной σ* . При больших значениях такая замена мало влияет на коэффициент доверия, и мы имеем
|
σ* |
|
σ* |
|
|
|
<α < X +t |
|
≈ |
P X −t |
n |
|
||
|
|
n |
|
104

|
|
σ* |
σ* |
|
|
|
|
<α < X +t |
|
доверительным |
|
т.е. интервал X −t |
является |
||||
|
|
n |
n |
|
|
интервалом для а с коэффициентом доверия, близким к . |
|
|
|||
Построение |
доверительного |
интервала |
для |
среднего |
|
квадратического отклонения σ и дисперсии
распределенной генеральной совокупности. Пусть выборка из нормальной генеральной совокупности. величина
2 |
|
n |
|||
nS2 = |
1 |
∑(X i − |
|
)2 |
|
X |
|||||
2 |
|||||
σ |
σ |
i=1 |
|||
σ2 нормально
X1, X2 , ..., Xn -
Согласно лемме
распределена по закону χ2n−1 с (n −1) степенями свободы. Зададим
коэффициент доверия и определим числа χ12 и χ22 из условия
χ22
∫kn−1(x)dx = ,
χ12
где kn−1(x) — плотность распределения вероятности закона χ2−1 с (n −1)
n
степенями свободы. Очевидно, числа χ12 и χ22 удовлетворяющие данному условию, можно выбрать бесчисленным множеством способов. Потребуем дополнительно, чтобы
χ2 |
|
1− |
|
∫1 kn−1 (x)dx = |
|||
0 |
|
2 |
|
тогда |
|
|
|
∞∫kn−1 |
(x)dx = |
1− |
|
2 |
|
||
χ2 |
|
|
|
2 |
|
|
|
и числа χ12 и χ22 однозначно |
(их значения находятся из таблиц |
||
распределения χ2n−1 с (n −1) степенями). Для величины nS2 / σ2 имеем
105

|
2 |
|
nS 2 |
2 |
χ22 |
|
|
|
|
|
χ1 |
< |
|
2 |
|
= ∫kn−1(x)dx = |
|
|
|
P |
σ |
< χ2 |
|
|
|||||
|
|
|
|
|
χ 2 |
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
Итак, с вероятностью выполнены неравенства |
χ12 < nS2 / σ2 < χ22 , |
||||||||
откуда |
|
|
|
|
|
|
|
|
|
или |
|
nS2 / χ22 <σ2 < nS2 / χ12 , |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
nS / χ2 <σ < nS / χ1. |
[ |
|
nS / χ1 ] |
||||
Таким образом, интервалы [nS 2 / χ22 , nS 2 / χ12 ] и |
nS / χ2 , |
||||||||
являются доверительными |
интервалами |
для дисперсии |
σ2 и |
среднего |
|||||
квадратичного отклонения σ , соответствующими коэффициенту доверия в случае нормально распределенной генеральной совокупности.
§5. Обработка результатов измерений Оценка истинного значения измеряемой величины и
среднеквадратичной ошибки измерения.
Как правило, для получения истинного значения а измеряемой величины (а также для оценки средней квадратичной ошибки σ измерения) производят некоторое число n независимых измерений этой величины. Обозначим результаты измерений через X1, X2 , ..., Xn. Известно, что результат измерения есть случайная величина, распределенная нормально. Предположим, что MXi = a – условие отсутствия систематической ошибки,
и положим DXi = σ2 . Таким образом, величины X1, X2 , ..., Xn оказываются независимыми нормально распределенными с параметрами а и σ случайными величинами. Эти параметры подлежат определению по результатам измерений, т.е. по выборке. Истинное значение а измеряемой
величины и среднюю квадратичную ошибку σ |
измерения находят по |
||||||||
формулам: |
|
|
|
|
|
|
|||
|
|
|
n |
|
n |
(X i − |
|
)2 |
|
α ≈ |
|
= |
1 ∑X i , σ ≈ |
1 |
∑ |
|
|||
X |
X |
||||||||
|
|||||||||
|
|
|
n i=1 |
n −1 i=1 |
|
|
|
||
106
Для оценки точности данных приближенных равенств можно построить доверительные интервалы.
Сглаживание экспериментальных зависимостей. Пусть величины Х и Y связаны функциональной зависимостью вида Y =ϕ(X ), причем функция
ϕ нам не известна и ее требуется определить по результатам наблюдений.
Предположим, что имеется возможность на опыте измерять значения величины Y в различных точках xi . Обозначая результат i -го измерения через yi , имеем
yi =ϕ(xi )+δi ,
где δi – случайная измерения. Таким образом, величина yi как всякий результат измерения является случайной величиной. Если нанести на график точки (xi ; yi ) и соединить их кривой, вид этой кривой отличается от кривой из-за наличия случайных погрешностей при определении ее ординат. Возникает вопрос: как обработать опытные данные, чтобы
наилучшим образом определить зависимость Y от X ?
Это так называемая задача о сглаживании экспериментальных зависимостей. Рассмотрим частный, но наиболее важный для приложений случай, когда заранее известно, что функция ϕ(X ) принадлежит к
некоторому классу функций, зависящему от одного или нескольких параметров, т.е. ϕ(X )= ϕ(X ,α1,α2 , ...,αk ). В этом случае задача отыскания
наилучшей функции |
ϕ(X ) |
сводится к задаче наилучшего определения |
параметров α1 , α2 , |
..., αk |
по опытным данным. Словам “наилучшим |
образом” необходимо придать точный смысл, что можно сделать по-разному. В соответствии с этим возможны разные способы решения задачи о сглаживании. Слова “наилучшим образом” будем понимать в дальнейшем в смысле метода наименьших квадратов, так как такое понимание является общепринятым и на практике приводит обычно к несложным вычислениям. Будем говорить, что неизвестные параметры α1 , α2 , ..., αk функции
107
ϕ(X ,α1,α2 , ...,αk ), задающей зависимость Y = ϕ(X ,α1,α2 , ...,αk ),
определены наилучшим образом в смысле метода наименьших квадратов,
если сумма квадратов отклонений экспериментальных точек yi от ординат сглаживающей кривой ϕ(xi ,α1,α2 , ...,αk ) минимальна, т.е. минимальна величина
n
δ 2 = ∑[yi −ϕ(xi ,α1,α2 ,...,αk )]2
i=1
Для нахождения точки минимума величины δ2 в обычных аналитических условиях нужно приравнять нулю ее частные производные по
α1 , α2 , ..., αk :
∑[yi −ϕ(xi ,α1,α2 ,...,αk )]= ∂ϕ(xi ,α1,α2 ,...,αk ) |
= 0, 1 ≤ j ≥ k . |
|||
n |
|
|
|
|
i=1 |
∂αj |
|
|
|
Таким образом, имеем систему k |
уравнений с k |
неизвестными, из |
||
которой определяем искомые значения α1 , α2 , ..., αk . Заметим, что система
содержит случайные величины y1, y2 , ..., yn , |
поэтому и |
ее решение |
|
α*1 , α*2 , ..., α*k |
также случайно. Величины α*1 , α*2 , ..., α*k являются оценками |
||
неизвестных |
параметров α1 , α2 , ..., αk по |
результатам |
наблюдений. |
Рассмотренная задача отличается от задачи оценки неизвестных параметров распределения, изученной выше, так как величины y1, y2 , ..., yn хотя и предполагаются независимыми, но имеют, вообще говоря, различные распределения.
Рассмотрим оценку по методу наименьших квадратов параметров
линейной |
функции |
Y = kX +b. Пусть |
из опыта |
известна совокупность |
|
|
|
|
n |
значений |
(xi ; yi ). |
Рассмотрим |
величину |
δ 2 = ∑(yi −kxi −b)2 . |
|
|
|
|
i=1 |
Продифференцировав, получим систему: |
|
|
||
|
|
n |
n |
|
|
|
∑(yi −kxi −b) xi = 0, ∑(yi −kxi −b)= 0 |
||
|
|
i=1 |
i=1 |
|
108

Из второго уравнения находим
|
1 |
n |
1 |
n |
|
b = y − kx , где y = |
∑yi , x = |
∑xi . |
|||
n |
n |
||||
|
i=1 |
i=1 |
|||
|
|
|
Подставив найденное значение в первое уравнение и преобразовав его, придем к равенству
|
|
|
|
n |
|
|
|
n |
|
|
|
|
|
|
|
∑yi xi −k∑xi2 −nx(y −kx)= 0 |
|||||||
|
|
|
|
i=1 |
|
|
|
i=1 |
|
|
|
откуда |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
n |
|
|
|
|
|
|
|
∑yi xi −nxy |
|
|
∑(yi − y)(xi − x) |
||||
|
|
|
k = |
i=1 |
|
= |
i=1 |
|
|
, k = m*x, y / Sx2 , |
|
|
|
|
n |
|
|
n |
|
||||
|
|
|
|
∑xi2 −nx 2 |
|
|
|
∑(xi − x)2 |
|||
|
|
|
|
i=1 |
|
|
|
|
i=1 |
|
|
* |
1 |
n |
2 |
|
1 |
|
n |
|
2 |
|
|
где mx, y = n |
∑i=1 |
(yi − y)(xi − x), Sx |
= n |
∑i=1 (xi |
− x) . |
||||||
Таким образом, задача решена, и линейная функция
m*
Y = Sx2, y x
m*
X + y − Sx2, y x x
наилучшим образом среди всех линейных функций выражает зависимость Y от X.
§6. Проверка статистических гипотез
Постановка задачи
Часто функция распределения случайной величины бывает заранее не известна, и возникает необходимость ее определения по эмпирическим данным. Во многих случаях из некоторых дополнительных соображений могут быть сделаны предположения о виде функции распределения FX (x).
Любое такое предположение называется (статистической) гипотезой и
математически выражается соотношением {FX H }, где H – множество функций распределения, FX – функция распределения наблюдаемой
109
случайной величины. Гипотезу обычно обозначают тем же символом, что и множество функций распределения: H = {FX H }.
Рассмотрим примеры статистических гипотез.
1. {FX F}, где – фиксированная функция распределения. В этом случае Н – множество, состоящее из единственного
|
элемента F. |
|
|
|
|
|
|
|
|
||
|
Определение. |
Статистическая гипотеза {FX F} называется простой |
|||||||||
гипотезой. |
|
|
|
|
|
|
|
|
|||
|
|
|
|
x −a |
|
|
F = F (x) |
|
|||
2. |
F |
|
(x) F |
|
|
, −∞ <α < ∞, σ |
> 0 |
, где |
– фиксированная |
||
|
X |
|
σ |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|||
функция распределения. Данная гипотеза состоит в том, что распределение наблюдаемой случайной величины принадлежит некоторому фиксированному типу. Так например, если – стандартная нормальная функция распределения, то данная гипотеза состоит в нормальности наблюдаемой случайной величины.
|
|
|
|
x |
|
|
|
F = F (x) – фиксированная |
|
|
|
|
|
||||||
3. |
FX (x) F |
|
, T ≥T0 |
|
|
, где |
|||
|
|||||||||
|
|
|
T |
|
|
|
|
||
функция распределения.
Определение. Гипотеза, не являющаяся простой, называется сложной. По эмпирическим данным нужно проверить статистическую гипотезу Н. Для определенности назовем Н основной гипотезой. С гипотезой Н
конкурирует альтернативная гипотеза K = {FX K}. Здесь K – множество функций распределения, не пересекающееся с множеством Н. Если K – множество всех F, не входящих в Н, то это множество обычно вообще не упоминается.
Все гипотезы проверяют по эмпирическим данным, т.е. |
по выборке. |
|||
Таким образом, необходимы критерии, |
которые позволяли |
бы судить, |
||
согласуются ли наблюдаемые значения |
X1, X2 , ..., Xn |
величины |
Х с |
|
гипотезой относительно ее функции распределения. |
Разработка |
таких |
||
110