

Обзор уровней raid
В следующей таблице перечислены достоинства и недостатки разных уровней RAID: Уровень RAID Надежность Объем Производительность Стоимость
Уровень RAID |
Надежность |
Объем |
Производительность |
Стоимость |
0 |
нет |
100 % |
высокая |
средняя |
1 |
зеркальные копии |
50 % |
средняя/высокая |
высокая |
2/3 |
контроль четности |
80 % |
средняя |
средняя |
4/5/6/7 |
контроль четности |
80 % |
средняя |
средняя |
10 |
зеркальные копии |
50 % |
высокая |
высокая |
Обзор производительности различных уровней raid
Наиболее часто встречаются массивы RAID следующих уровней: 0, 1, 3 и 5. Уровни 2, 4 и 6 не имеют функциональных преимуществ перед другими уровнями, и их производительность в отдельных ситуациях ограничена. Как правило, вместо RAID 3 используется RAID 5, что позволяет избежать недостатков, связанных с хранением контрольной информации на одном диске.
Уровни RAID 0 и RAID 1 могут быть реализованы одними только программными средствами. Для работы с RAID 3, 5 и 7 необходимы специальные программы и устройства (специальные контроллеры и адаптеры RAID).
Рекомендации по применению raid-массивов
Дюльдин 22. Понятие виртуализации. Виртуализация в СХД.
Процесс представления набора ресурсов для хранения данных или их логического объединения, который даёт какие-либо преимущества перед оригинальной конфигурацией.
Все современные ЦОДы строятся по виртуальному принципу. Мы имеем набор выч.ресурсов, имеем набор систем хранения данных, над всем этим стоит ПО например компания веймвара дочерняя компания EMC, мы можем эффективно управлять ресурсами, нам нужна новая серверная система, мы заходим на систему виртуализации, создаем там некую виртуальную машину, на эту виртуалку устанавливаем нужное ПО и с ним дальше работаем. Данное ПО поддерживает БП нашей компании, которые на текущий момент актуальны. Мы эффективно используем вычислительные ресурсы, тем.. Создание сервисов для поддержки БП компании значительно упрощается и повышается эффективность IT-инфраструктуры в целом.
ПО - менеджер томов volume manager, смысл механизма – предоставить гибкий механизм по управлению дисковым пространством на уровне хост – систем. Подобные симстемы виртуализации могут работать не только с локальными ресурсами, но и с ресурсами доступными по сетям хранения данных, сети общего пользования, (с NAS системами)
Методы виртуализации:
На уровне конечных систем
Менеджер томов (Volume Manager) на лабораторных работах – типичная реализация менеджера томов на уровне 2003-го сервера, базовыми средствами ОС добились эффекта виртуализации.
Система виртуализации SAN. В сеть хранения данных помещается некое оборудование, которое позволяет разделить потоки данных которые поступают в сеть хранения данных таким образом, чтобы замаскировать собой те устройства, которые находятся в сети хранения данных и предоставить их в виде некого единого пула систем хранения.
Примеры таких наиболее популярных продуктов:
NetApp V3000/V6000 Series
EMC Invista
На уровне интеллектуальных хранилищ
Могут обслуживать большое количество пользователей, на них можно создавать логических томов, при этом каждое это хранилище данных если рассматривать хайэнд устройство может содержать 1000-2000 устройств хранения данных, интеллектуальность проявляется в гибком управлении этим всем ресурсом хранения, создания RAID томов, управления группами хранения данных, полностью маскируем все наши конечные устройства хранения данных HDD либо флэш накопители этой системой.
Стек программного обеспечения подсистемы хранения
Система каталогизации
Менеджер томов
ПО для DMP
Драйвера устройств
Управление адресным пространством
Агрегирование
Есть некий ресурс хранения, который состоит из большого количества более мелких ресурсов - получаем большое адресное пространство, подход простой и на практике используется повсеместно.
Разделение
Есть некий ресурс хранения большой, при этом, он может быть создан по предыдущему принципу (собран из более мелких устройств) но нам этот ресурс хранения весь на текущий момент не нужен, мы его можем разделить на более мелкие порции
Подмена
Старые дисковые массивы с новым большим потоком запросов уже не могут справиться. Купили новый дисковый массив нужно на него перенести данные, мигрировать на него. Есть кластерный комплекс который через сеть хранения данных работает со старым дисковым массивом, мы добавляем новый дисковый массив, и добавляем подсистему виртуализаци- некое устройство, получаем такую конфигурацию, потом перенастраиваем (это происходит за микросекунды, запускается скрипт) в фоне, в процессе у нас начинается миграция данных на новый дисковый массив, в результате невидимо для нашего бизнеса осуществили переезд на новый дисковый массив.
Зеркалирование
Решаем задачу разделения потоков данных. При этом данные хранятся не на одном дисковом массиве в результате, а абсолютно одинаковые копии этих данных хранятся на отдельных дисковых массивах. Технологии локальных и удаленных репликации, это по большому счету реализация подобных технологий, но на уровне отдельного конкретного устройства. На практике механизмы репликации реализуются на уровне специального ПО хоста, либо на уровне программно-аппаратного обеспечения системы хранения данных. Мы работаем не с дисковым массивом, а с неким устройством, которое «говорит» я – дисковый массив, собой маскирует другие дисковые массивы и пересылает данные на 2 или иногда 3 устройства.
Стюхляева 23. Непрерывность бизнеса. Основные понятия.
Краткий словарь терминов: Continuous Data Protection (непрерывная защита данных), далее CDP - методика постоянного отслеживания изменений данных и сохранения изменений независимо от первичных данных, позволяющая восстановить данные на любой момент времени в прошлом.

CDP системы могут быть реализованы на уровне блоков, файловых систем или отдельных приложений и обеспечивать сколь угодно малую дискретность при восстановлении объектов на любой момент времени, вплоть до одиночной операции записи. Согласно этому определению SNIA (Storage Networking Industry Association - ассоциация индустрии сетевого хранения), все CDP решения должны иметь следующие свойства:
Изменения постоянно отслеживаются и записываются
Все изменения хранятся на отдельном устройстве
RPO (точка восстановления) - произвольная и не должна быть определена заранее (до момента восстановления)
Recovery Point Objective (RPO) - Допустимая точка восстановления
[Data Recovery] The maximum acceptable time period prior to a failure or disaster during which changes to data may be lost as a consequence of recovery. Data changes preceding the failure or disaster by at least this time period are preserved by recovery. Zero is a valid value and is equivalent to a "zero data loss" requirement.
Максимально допустимый период времени, предшествующий сбою или катастрофе за который все внесенные изменения в систему могут быть потеряны в результате выполнения процедуры восстановления. Изменения, внесенные перед началом этого периода сохраняются при выполнении процедуры восстановления. Нулевое значение тоже является корректным и эквивалентно требованию на полное отсутствие потерь.
Recovery Time Objective (RTO) - Допустимое время восстановления
[Data Recovery] The maximum acceptable time period required to bring one or more applications and associated data back from an outage to a correct operational state.
Максимально допустимый период времени, требуемый для того, чтобы вернуть приложение и требуемые для его работы данные в состояние, приемлемое для продолжения корректной работы с ними.
Пролог
В таблице представлены некоторые вехи из истории разработки ПО резервного копирования и ориентировочные стоимостные показатели "сырой емкости" (цены на устройства хранения взяты с сайта http://www.mattscomputertrends.com)
Дата |
Наиболее востребованные диски (MB) |
Цена $/MB |
Цена диска, $ |
Среднее количество файлов на одном диске |
1986 - первый релиз GNU Tar |
40 MB |
57 |
2300 |
сотни |
1990 - Legato Networker 1.0 |
110 MB |
13 |
1500 |
тысячи |
1999 - первый релиз rsync |
17,000 MB |
0,002 |
340 |
10,000 |
2002 - первый релиз FalconStor CDP |
80,000 MB |
0,002 |
212 |
100,000 |
2005 - IPStor для OEM (iSer Infiniband), первый релиз R1Soft CDP для Linux |
200,000 MB |
0,0007 |
140 |
1,000,000 |
2007 - AIX JFS2& Solaris ZFS snap-mirror, MS VSS near-CDP, EMC RecoverPoint (Kashya) |
320,000 MB |
0,0004 |
140 |
3,000,000 |
2009 - MS DPM, IBM FastBack, NexentaStor CDP - Freeware. |
2,000,000 MB |
0,00007 |
150 |
10,000,000 |
Вместе с положительным эффектом от масштаба, наблюдаемым для "сырой" емкости хранения, запросы на рынке систем резервного копирования c 2000г начали меняться вследствие быстро увеличивающегося разрыва между производительностью внешних систем хранения, требуемой емкостью и производительностью серверов и сетевого оборудования.Подобный дисбаланс приводил к большому времени восстановления в случае катастрофы системы хранения с неструктурированными данными или к существенному удорожанию всего решения по защите от катастроф. На фоне отсутствия корпоративных решений в области CDP очередной опрос Forrester Research выявил интересную тенденцию в среде крупных компаний. Низкая эластичность по показателю [Цена/GB при минимальных RTO/RPO] существующих на тот момент систем резервного копирования предвещала для новой категории продуктов очень комфортный старт. С этого момента инструменты по непрерывной защите данных начали свое самостоятельной развитие. До 2000 г. CDP функциональность была доступна только как дополнительная функция в составе систем хранения. Принципиальная несовместимость механизмов CDP между системами хранения различных производителей не позволяла воспользоваться всеми конкурентными преимуществами этих систем при объединении их в рамках одной инфраструктуры заказчика.
В настоящий момент SNIA описывает CDP как часть инициативы по защите данных (DPI): http://www.snia.org/forums/dmf/knowledge/white_papers_and_reports/SNIA_DMF_V6_DPI_Guide_4WEB.pdf
Навигация для быстрого поиска материалов на сайте SNIA: SNIA ( http://www.snia.org ) - Forums – DMF( http://www.snia.org/forums/dmf ) - DPI - CDP В категории "CDP продуктов" по классификации SNIA представлены: FalconStor СDP и EMC RecoverPoint CDP. http://www.snia.org/forums/dmf/knowledge/white_papers_and_reports/SNIA_DMF_V6_DPI_MatrixOnly.pdf
Картина первая, лирическая …
Воссоздавая в памяти первый поучительный инцидент из области "непрерывности бизнеса" более полно, невольно возвращаюсь к 1990г., когда работа в качестве технического специалиста в банке совмещалась с написанием диплома. Испытания на инженерную смекалку проходили каждый день т.к. головное отделение банка внедряло в филиалах новый "операционный день" (в наши дни подобное ПО является частью любой Автоматизированной Банковской Системы) и инструкции по эксплуатации не содержали описания всех исключительные ситуаций, в которых система побывала с момента начала внедрения (про CoBIT, ITIL, SLA и прочие правильные понятия в лихие 90-е задумывались редко). Один из подобных трудовых будней запомнился особенно ярко. В отделе валютных операций перестала работать система электронных переводов. Причина на первый взгляд казалась тривиальной. ПК не загружался со знакомым всем сообщением, что устройство, необходимое для загрузки, отсутствует. Однако, очень скоро стало понятно, что подключенное к этому ПК заведомо исправное загрузочное устройство проблему не решит. Привычное поведение ПК при загрузке изменялось благодаря дополнительному устройству, компоненты которого были залиты лаком, и единственная разборчивая надпись очень напоминала номер телефона. Позвонив по этому номеру и попав на очень приветливого оператора, сотрудники банка были огорчены следующим ответом - "Система защиты от несанкционированного доступа была Вам поставлена с двумя аппаратными ключами, и если один из них вышел из строя, то Вы можете воспользоваться другим. Изготовление новой дополнительной пары ключей займет несколько дней". Растерянное лицо оператора ПК, который держал в руках один из "неисправных" ключей подсказало очевидное решение. Второй ключ нашелся быстро, но множество растерянных лиц пополнилось еще одним - лицом руководителя отдела валютных операций. По законам жанра второй ключ тоже не подошел. В подобных ситуациях часы начинают тикать особенно громко. После того, как из операционного зала поступил запрос от клиента, который пришел за денежным переводом, руководство решило, что стоимость ПК не сопоставима с теряемой банком репутацией и произнесло сакраментальную фразу - "Делайте что угодно, но система переводов должна заработать в течение часа!". На окошке оператора повесили табличку с объявлением "Технический перерыв" и отдали ПК в тех.отдел в нарушении всех инструкций вместе с ключами и всей документацией. На коротком совещании все сошлись во мнении, что необходимо решить две задачи: 1 - научиться сравнивать ключи между собой, 2 - заставить работать систему без ключей. Задача № 1 позволяла ответить на вопрос о целостности ключей и собственном уровне надежности поставленного нам средства защиты от "несанкционированного доступа". Решение задачи №2 избавляло некоторых сотрудников от увольнения. 20-и минутные старания с выбором правильного момента задержки при подключении PATA шлейфа к диску были потрачены не напрасно и ПК удалось запустить без ключа. Далее, приложив вроде бы неисправный ключ, запустили и систему переводов. После этого инцидента методику резервирования сервиса пересмотрели в корне - поставили еще один ПК с отдельной парой ключей (которые были уникальными, как выяснилось позже, после успешного решения задачи №1). Поучительность этой истории в том, что истинная цена победы была гораздо ниже - всего один блок на диске (даже не начальный), но понять это в условиях сильного сопротивления со стороны системы защиты бывает порой не просто. Задача о внесении изменений в конфигурацию вычислительной системы с оператором (называемой эргатическим комплексом) с требованием "безусловной высокой доступности" сервиса в строгих терминах эквивалентна поиску глобального экстремума у функции нескольких переменных с ограничением по параметрам (число конкурентных лицензий, целостность системы, доступность каналов и т.д.), которые в свою очередь зависят от времени. Еще более экзотические классы задач приходится решать, когда система перестает быть устойчивой при попытке оптимизации скоринговых процедур в экспертной части ITSM. Анализ рисков при выборе в пользу "чуть большей безопасностью" и "чуть меньшей доступностью" сильно осложняется, когда ключевые информационные ресурсы компании распределены географически и организационная структура не позволяет получить состоятельную оценку риска за требуемый промежуток времени. Несмотря на то, что банки и страховые компании одними из первых стали применять "Attrition scoring", собственные информационные ресурсы в комплексе с системой безопасности обычно выпадают из этого анализа. К сожалению, описание первопричин этого феномена не укладывается в рамки данной статьи. Но даже если оставить в стороне аксиомы и красивые выводы из них, результат теории оптимизации эргатических комплексов удручает не меньше - внешние воздействия оператора предсказать и эффективно компенсировать невозможно и на все случаи жизни заранее просчитать сценарии оптимального реагирования нельзя (оптимизатор отнимет ресурсов больше, чем Вы получите эффект от оптимизации, иначе оператора можно исключить). Как же тогда обеспечить высокую доступность сервиса? Ответ очевиден - нужно быть готовым к самому худшему из сценариев - к катастрофе. Все промежуточные состояния легко экстраполируются, как в известной истории с математиком и чайником... "по индукции".
Картина вторая - парадоксы логики ответственных за принятие решений.
В руководстве по катастрофоустойчивости одного известного вендора эпиграфом к главе "Backup" выбрана замечательная русская поговорка "Fix your cart in winter, and sled in summer. Russian proverb". Следующая глава "Recovery" начиналась не менее известной, но уже британской поговоркой "The Lord helps those who help themselves.". Вся современная парадигма "обеспечения непрерывности бизнеса" по прежнему умещается в этих простых народных мудростях. Для обеспечения непрерывности бизнеса (как минимум) требуется сделать непрерывными три связанных процесса:
Непрерывное сохранение генерируемых изменений (в самом простом случае их сериализация)
Непрерывное восстановление (прикладывание изменений к резервным копиям)
Непрерывная оценка доступности сервиса и своевременное переключение на требуемую резервную копию
В этом месте изложения апологеты ERP систем и администраторы БД этих ERP систем обычно произносят что-то вроде - "В ERP системах все критичные для бизнеса изменения уже защищены журналами транзакций и технология резервных БД с успехом применяется для построения катастрофоустойчивых решений уже второй десяток лет". Это достойный аргумент для организации проекта по внедрению подходящей ERP системы, но те, кто работает с ERP два десятка лет прекрасно знают, что журнал БД приложить сложнее, чем журнал CDP. Представьте себе, что при параллельном безостановочном перестроении кластерного индекса на трех экземплярах Real Application Cluster с одновременной загрузкой данных в кластер на трех оставшихся экземплярах один из потоков изменений в архивном журнале N будет содержать ошибку? Сколько времени придется потратить на выяснение первопричины ошибки и, главное - как изменится RTO резервной БД?
Рассмотрим некоторые нюансы возможных комбинаций "CDP уровня приложения" и "CDP блочного уровня" более детально на следующем примере:
Вводные: Компания X строит резервный ЦОД для защиты основного от катастроф. Организован канал связи между основным и резервным ЦОДами с гарантированной полосой пропускания в 2-а раза превышающей среднюю скорость генерации изменений. Анализ скорости проводится за год, интервал усреднения - 1 час. Надежность канала умышленно исключим из анализа. Средняя латентность канала - 250mc (London-Tokyo). На расстоянии в 3km от основного ЦОДа есть резервный кампус с аналогичным по полосе каналом до основного и резервного ЦОДа. Спрашивается: каким будет максимальное время восстановления (RTO) и самый пессимистичный сценарий развития событий в случае катастрофы? Понятно, что при двойном запасе по полосе пропускания максимальное время восстановления будет около 30мин. (представьте себе график, на котором за первую минуту мы генерируем 100% изменений, а затем начинаем передавать их по каналу. Двойной запас по полосе сокращает время с часа до 30 мин) Но более неожиданным может быть тот факт, что при катастрофе (полной недоступности) основного ЦОДа в период пиковой нагрузки время восстановления может быть меньше 30 мин., а вот потери для бизнеса могут быть невосполнимыми (RPO>0) . Ключевым здесь является тот факт, что канал до кампуса не рассчитан на пиковую нагрузку, а только на среднюю. Потеря 20 мин. работы может иметь более тяжелые последствия, чем прерывание операционной деятельности на 30 мин. Если потеря изменений дороже простоя, то каналы асинхронной репликации необходимо закладывать из расчета на пиковую скорость генерации изменений или переходить на синхронную репликацию до кампуса и мириться с ограничением производительности всей системы. Но как можно предсказать будущие пики? Не можем предсказать - попробуем построить механизм для их сглаживания…Потоком изменений эффективнее всего управлять, если это поток с уровня приложения. На практике это означает, что для восстановления используется не "сырой" журнал изменений с уровня блочных устройств, а некая его производная. Типичным примером являются потоки журнальных операций БД или журнальные файлы, если используется асинхронная передача. Прикладывание журнала БД к резервной копии не всегда гарантирует 100%-е совпадение с оригинальной БД. Это может быть следствием выполнения массивных операций перестроения индексов, отсутствие которых при старте с резервной БД замедлит работу компании, но не прервет ее. Но что делать, если объем изменений сопоставим с объемом БД? Разумно иметь два механизма: первый - для поддержания точных резервных копий на кампусе; второй - для быстрого старта после катастрофы, следующей за массивными изменениями на основном сайте. В случае проблем с журналами БД администратор CDP всегда сможет подстраховать DBA, а DBA сможет сгладить пиковую нагрузку и защитить компанию от потери данных в случае катастрофы. В отличие от журналов БД, CDP журналы всегда можно приложить к резервной копии. Достаточно иметь исправное блочное устройство. Ошибки с журналированием на уровне RDBMS больше не будут носить фатальный характер. Более того, имея два независимых механизма всегда можно сравнить результаты и выбрать правильную стратегию восстановления БД. На этом простейшем сценарии по оптимизации показателей RTO/RPO отчетливо прослеживается необходимость в согласованных действиях между администратором CDP кластера и DBA для достижения оптимального отношения "RTO/цена решения" при RPO=0. Пытливый DR-менеджер (сотрудник, ответственный за восстановление в случае катастроф) быстро обнаружит неполноту в этих рассуждениях. Действительно, показатели RTO при оценке доступности бизнес-сервиса почти всегда не совпадают с RTO при оценке доступности конфигурационной единицы. Если после восстановления БД необходимо откатить транзакции, которые блокируют некий бизнес-сервис, то это время тоже необходимо учесть в RTO. Понятно, что катастрофа в момент выполнения процедуры закрытия года в ERP системе скорее всего приведет к существенному увеличению RTO.
Кроме технической составляющей, стоит затронуть организационный вопрос: "Сrash-consistent image" vs "Transaction-consistent image". Интересная дилемма, суть которой в следующем: представьте, что Вам необходимо принять решение о том, прикладывать ли все изменения к резервной копии вплоть до последних миллисекунд, когда сгорающее оборудование еще работало, или Вы решите потерять 5 минут с транзакциями, полученными "из огня" (с процессора, перегретого так, что его отключил IPMI, после чего тоже сгорел)? Сложность дилеммы в том, что оперативный анализ подобных рисков сродни гаданию на кофейной гуще. Обстановка уточняется по ходу принятия решения. Наличие плана восстановления (Disaster Recovery Plan, далее DRP) в этом случае сохраняет DR-менеджеру массу нервных клеток, но для этого придется приложить усилия в процессе создания и утверждения самого плана спасения.
Эпилог.
Представьте себе, что в потоке сгенерированных изменений Вам необходимо обнаружить и отменить необратимый процесс, запущенный по ошибке. Последствия этой ошибки уже сохранены в CDP журнале, переданы и приложены к резервным копиям. Получается, что права на ошибку у ответственных исполнителей больше нет? Требования непрерывности бизнеса обязывают планировать свои действия более тщательно? Это уже начинает напоминать не бизнес, а минное поле. Если система журналирования обеспечивает только хранение изменений на блочном уровне, то все последствия ошибок падают на плечи тех, кто принимает решение о запуске необратимых процессов. Апологеты RDBMS могут упрекнуть автора в том, что здесь оставлены без внимания такие механизмы "CDP уровня приложений", как LogMiner, Streams, и будут правы, частично. Современный бизнес все еще зависит от доступности неструктурированных данных. Представьте, что Вы вернулись из отпуска и не можете найти почту в своем корпоративном ящике, почему-то очищен календарь, и список контактов явно поредел. Начиная вспоминать, что же Вы сделали в последний рабочий день, понимаете, что обучение нового офис-менеджера работе с корпоративной почтой не прошло без последствий. Вы обращаетесь с вопросом к IT менеджеру, который через 15 мин. демонстрирует Вам содержание Вашего почтового ящика на тот злосчастный момент в прошлом, когда началось обучение офис-менеджера. На этом чудеса не заканчиваются, и Вы замечаете, что вся входящая почта, поступившая за время Вашего отпуска тоже доступна. При этом IT менеджер специально не контролирует именно Вашу переписку и не вникает во все проблемы бизнеса. В чем секрет фокуса? В первом приближении (почему только в первом станет ясно чуть позже), большинство современных CDP решений позволяют решать описанные задачи. В контексте построения сервиса корпоративного уровня по обработке CDP журналов внимание привлекают продукты, обладающие следующими качествами:
Централизованный, кластеризуемый сервис по хранению и обработке CDP журналов.
Репликатор уровня SAN и, как следствие, "OS agnostic" CDP код. Для различных ОС ключевая функциональность реализуется одним программным кодом. Это качество оказывает сильное влияние на скорость развития продукта и стабильность критичных участков кода.
Полноценный CLI для кастомизации процедур управления журналами, снимками, резервными копиями и т.д.
Возможность обратимой виртуализации для "CDP блочного уровня". Включение CDP механизма не оказывает влияния на защищаемое блочное устройство. Уникальность этого свойства состоит в том, что в любой момент времени один CDP продукт можно заменить на другой.
Поддержка современных протоколов блочного уровня: FC, iSCSI, iSer
В отношении заявленных свойств продукты из перечня SNIA (см.начало статьи) привлекают к себе самое пристальное внимание. Они не случайно выделены SNIA и стоят особняком от других CDP продуктов, таких как: Symantec BackupExec CDP (http://eval.symantec.com/mktginfo/products/White_Papers/Data_Protection/Backup_Exec_10d_CPS_best_practices_final.pdf ), IBM Tivoli FastBack (http://www-01.ibm.com/software/au/tivoli/fastback), CommVault Simpana (http://www.commvault.com/pdf/DS_QR_Overview.pdf), R1Sorf CDP (http://wiki.r1soft.com/display/CDP3/CDP 3.0 Editions ), и т.д.
Формат данной статьи не позволяет рассмотреть в деталях оба продукта. Сегодня мне хотелось бы обратить Ваше внимание на преимущества FalconStor NSS (Network Storage Server (NSS) ). FalconStor NSS выделяется в первую очередь тем, что это полноценный программный продукт для установки под Linux. В отличие от большинства программно-аппаратных комплексов он может быть установлен в целях ознакомления как на виртуальную платформу (VmWare, Xen, VirtualBox и т.д.) так и на существующее у Вас физическое оборудование. Полноценно кластеризуемое решение доступно как на виртуальных машинах, так и на физических. Поддерживаются две топологии кластера - симметричная и несимметричная (не все блочные устройства должны быть доступны на обоих узлах). В отношении мультипротокольности это самый открытый из существующий продуктов. Судите сами - CDP сервис доступен по протоколам iSCSI, iSCSI(iSer), FC в любых сочетаниях систем хранения и для любых клиентов. Вы можете предоставить одновременный доступ к FC HDS массиву для iSer Linux клиентов и FC клиентов AIX. На лабораторном стенде компании Тринити успешно реплицируются изменения с томов IBM DS4700 на Infortrend F16F-S4031 и далее на IBM DS3400. Помимо защиты данных это еще и удобное средство виртуализации, в котором можно объединить емкости этих устройств в общий пул и раздать его группам администраторов CDP, разграничив доступ и установив квоты по управлению виртуальными блочными устройствами. Скорости доступа к блочным устройствам, полученные на реальных образцах техники представлены для ознакомления:

Для начального этапа внедрения FalconStor NSS исключительно важным является то, что это CDP продукт с обратимой виртуализацией. Вы можете включить его "в разрыв" между любой СХД с SAN и проверить функциональность не внося изменений в хранимые данные. Если какие-то показатели Вас не устроят, то достаточно вернуть схему коммутации и настройку хостов в прежнее состояние.
Типичная схема организации мультипротокольного CDP кластера на базе FalconStor NSS:
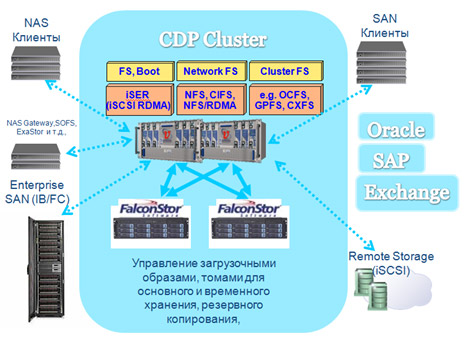
Ключевая функциональность CDP кластера на базе FalconStor NSS:
Быстрое восстановление локальных данных в случае повреждения или системного сбоя в любой момент времени в прошлом (случайно удален файл, перемещен каталог, отформатирована файловая система и т.д.).
Восстановление после локальных или региональных катастроф путем переключения на резервный сайт
Безостановочное резервное копирование в любой момент времени без влияния на производительность промышленной системы.
Безостановочная миграция данных на другие системы хранения.
Методика отладки приложений над точными копиями промышленных данных, не требующая ожидания процедур копирования и не требующая дополнительного объема.
Защита данных для серверов с непосредственным хранением (DAS) при наличии свободного Fibre Channel/Ethernet/IB канала.
Наивысшая из всех альтернативных технологий скорость сохранения изменений.
Основные триггеры для принятия решения о необходимости внедрения CDP кластера:
Снижение затрат на хранение журналов при увеличении их суммарного объема (возможность сокращения расходов от положительного эффекта масштаба http://en.wikipedia.org/wiki/Returns_to_scale)
Независимость DRP от сложности сети хранения данных
Формализация процедур верификации DRP (оценка предельных циклов переключения между основным и резервным сайтами)
Единая точка контроля над рисками потери данных (минимизация RPO) и временем простоя компании (устранение организационной SPOF)
Максимизация эластичности показателя цена/качество по ключевым параметрам (RTO, цена каждого GB защищенных данных, масштабируемость по объему и скорости доступа к основным ресурсам защищаемой СХД).
EMC RecoverPoint - во многом аналогичный продукт и заслуживает отдельного повествования, чему и я с удовольствием посвящу одну из следующих статей.
Дополнительная информация по всей линейке продуктов FalconStor расположена на сайте компании Тринити: http://www.trinitygroup.ru/products/soft/falconstor
Обратите внимание на возможность интеграции FalconStor NSS в процедуры управления восстановлением резервного сайта на базе VMware vCenter (FalconStor Failback Manager for VMware vCenter Site Recovery Manager). Весь потенциал технологий виртуализации СХД по настоящему раскрывается в составе комплексной виртуализации центров обработки данных. Якунин 24. Непрерывность бизнеса. Технологии обеспечения на уровне СХД. DMP.
Технологии СХД для обеспечения непрерывности бизнеса
●Создание удаленных копий данных
●Создание архивных копий
●Множественные пути доступа к данным
Понятие Dynamic Multipathing (DMP)
DMP – Распределяет операции ввода-вывода по всем доступным каналам между сервером и массивом хранения данных для повышения производительности и доступности. Благодаря этой возможности можно избежать распространенных отказов каналов ввода-вывода, HBA и ошибок переключения.
(определяет
номера логических устройств (LUN)
участвующих в процессе ввода/вывода в
качестве задающего и целевого устройства.)
Dynamic Multi-pathing позволяет повысить скорость ввода-вывода и доступность хранилища в инфраструктурах с разнородными серверами и устройствами хранения данных.
Dynamic Multipathing позволяет выравнивнить нагрузки на каналы. ввода-вывода, что увеличивает пропуск ную способность и повышает доступность приложений благодаря перенаправлению трафика ввода-вывода на другие каналы в случае отказа одного из каналов.
DMP
можно
манипулировать
с
помощью
инструмента
"vxdmpadm".
Этот
инструмент позволяет включить, отключить
DMP,
и
для
различных операций
DMP,
таких как отключение
пути
для
технического
обслуживания. Чтобы посмотреть,
какие пути доступны
для
данного
диска
использовать
vxdisk
команды.
(синтаксис vxdisk list <devname>). DMP
хорош
в
том,
что она
редко
требует
вмешательства
администратора.
Проще
говоря,
если
ваша
система
настроена
правильно,
это
"просто
работает"
Назарова 25. Непрерывность бизнеса. Технологии обеспечения на уровне СХД. Резервные копии данных.
Создание удаленных копий данных
Задачи создания удаленных копий
Практически немедленная доступность данных
Обеспечение целостности и согласованности данных, атомарности операций над данными
Восстановление функционирования датацентра первичного сайта
Иерархия площадок и хранилищ для создания удаленных копий
Основные
Вторичные
Третичные
Бункерные
Режимы создания удаленных копий
Синхронный
Асинхронный
Частично синхронный
Обеспечение избыточности систем ввода/вывода
На уровне серверных систем
Кластеры
Фермы серверов
На уровне сетевых/шинных адаптеров
На уровне сетевого коммуникационного оборудования
На уровне портов подсистем хранения
Внутри подсистем хранения данных
Создание архивных копий
Применение резервного копирования
●Защита данных от сбоев и катастроф
●Ведение архивов
●Миграция систем и приложений
●Обмен данными
Операции резервного копирования
●Окно резервного копирования
●Типы автоматических операций резервного копирования
◦Полное
◦Инкрементное
◦Дифференциальное
◦Специальное
Пример схемы создания резервных копий при 5-дневной рабочей неделе
Понедельник |
Дифференциальное |
Вторник |
Дифференциальное |
Среда |
Дифференциальное |
Четверг |
Дифференциальное |
Пятница |
Полное |
Пример схемы создания резервных копий при 5-дневной рабочей недели
Понедельник |
Инкрементальное |
Вторник |
Инкрементальное |
Среда |
Инкрементальное |
Четверг |
Инкрементальное |
Пятница |
Полное |
Резервное копирование12
Резервное копирование (англ. backup) — процесс создания копии данных на носителе (жёстком диске, дискете и т. д.), предназначенном для восстановления данных в оригинальном или новом месте их расположения в случае их повреждения или разрушения.
Наименование операций
Резервное копирование данных (Резервное дублирование данных) — процесс создания копии данных
Восстановление данных — процесс восстановления в оригинальном месте
Цель
Резервное копирование необходимо для возможности быстрого и недорогого восстановления информации (документов, программ, настроек и т. д.) в случае утери рабочей копии информации по какой-либо причине.
Кроме этого решаются смежные проблемы:
Дублирование данных
Передача данных и работа с общими документами
Требования к системе резервного копирования
Надёжность хранения информации — обеспечивается применением отказоустойчивого оборудования систем хранения, дублированием информации и заменой утерянной копии другой в случае уничтожения одной из копий (в том числе как часть отказоустойчивости).
Простота в эксплуатации — автоматизация (по возможности минимизировать участие человека: как пользователя, так и администратора).
Быстрое внедрение — простая установка и настройка программ, быстрое обучение пользователей.
Виды резервного копирования
Полное резервирование (Full backup)
Полное резервирование обычно затрагивает всю вашу систему и все файлы. Еженедельное, ежемесячное и ежеквартальное резервирование подразумевает полное резервирование. Первое еженедельное резервирование должно быть полным резервированием, обычно выполняемым по пятницам или в течение выходных, в течение которого копируются все желаемые файлы. Последующие резервирования, выполняемые с понедельника по четверг до следующего полного резервирования, могут быть добавочными или дифференциальными, главным образом для того, чтобы сохранить время и место на носителе. Полное резервирование следует проводить, по крайней мере, еженедельно.
Дифференциальное резервирование (Differential backup)
При разностном (дифференциальном) резервировании каждый файл, который был изменен с момента последнего полного резервирования, копируется каждый раз заново. Дифференциальное резервирование ускоряет процесс восстановления. Все, что вам необходимо, это последняя полная и последняя дифференциальная резервная копия. Популярность дифференциального резервирования растет, так как все копии файлов делаются в определенные моменты времени, что, например, очень важно при заражении вирусами.
Инкрементное резервирование (Incremental backup)
При добавочном («инкрементальном») резервировании происходит копирование только тех файлов, которые были изменены с тех пор, как в последний раз выполнялось полное или добавочное резервное копирование. Последующее добавочное резервирование добавляет только файлы, которые были изменены с момента предыдущего добавочного резервирования. В среднем, добавочное резервирование занимает меньше времени, так как копируется меньшее количество файлов. Однако, процесс восстановления данных занимает больше времени, так как должны быть восстановлены данные последнего полного резервирования, плюс данные всех последующих добавочных резервирований. При этом, в отличие от дифференциального резервирования, изменившиеся или новые файлы не замещают старые, а добавляются на носитель независимо.
Резервирование клонированием
Клонирование позволяет скопировать целый раздел или носитель (устройство) со всеми файлами и директориями в другой раздел или на другой носитель. Если раздел является загрузочным, то клонированный раздел тоже будет загрузочным.
Резервирование в виде образа
Образ — точная копия всего раздела или носителя (устройства), хранящаяся в одном файле.
Резервное копирование в режиме реального времени
Резервное копирование в режиме реального времени позволяет создавать копии файлов, директорий и томов, не прерывая работу, без перезагрузки компьютера.
Схемы ротации
Смена рабочего набора носителей в процессе копирования называется их ротацией. Для резервного копирования очень важным вопросом является выбор подходящей схемы ротации носителей (например, магнитных лент).
Одноразовое копирование
Простейшая схема, не предусматривающая ротации носителей. Все операции проводятся вручную. Перед копированием администратор задает время начала резервирования, перечисляет файловые системы или каталоги, которые нужно копировать. Эту информацию можно сохранить в базе данных, чтобы её можно было использовать снова. При одноразовом копировании чаще всего применяется полное копирование.
Простая ротация
Простая ротация подразумевает, что некий набор лент используется циклически. Например, цикл ротации может составлять неделю, тогда отдельный носитель выделяется для определенного рабочего дня недели. Недостаток данной схемы — она не очень подходит для ведения архива, поскольку количество носителей в архиве быстро увеличивается. Кроме того, инкрементальная/дифференциальная запись проводится на одни и те же носители, что ведет к их значительному износу и, как следствие, увеличивает вероятность отказа.
«Дед, отец, сын»
Данная схема имеет иерархическую структуру и предполагает использование комплекта из трех наборов носителей. Раз в неделю делается полная копия дисков компьютера («отец»), ежедневно же проводится инкрементальное (или дифференциальное) копирование («сын»). Дополнительно раз в месяц проводится еще одно полное копирование («дед»). Состав ежедневного и еженедельного набора постоянен. Таким образом, по сравнению с простой ротацией в архиве содержатся только ежемесячные копии плюс последние еженедельные и ежедневные копии. Недостаток данной схемы состоит в том, что в архив попадают только данные, имевшиеся на конец месяца, а также износ носителей.
«Ханойская башня»
Схема призвана устранить некоторые из недостатков схемы простой ротации и ротации «Дед, отец, сын». Схема построена на применении нескольких наборов носителей. Каждый набор предназначен для недельного копирования, как в схеме простой ротации, но без изъятия полных копий. Иными словами, отдельный набор включает носитель с полной недельной копией и носители с ежедневными инкрементальными (дифференциальными) копиями. Специфическая проблема схемы «ханойская башня» — ее более высокая сложность, чем у других схем.
«10 наборов»
Данная схема рассчитана на десять наборов носителей. Период из сорока недель делится на десять циклов. В течение цикла за каждым набором закреплен один день недели. По прошествии четырехнедельного цикла номер набора сдвигается на один день. Иными словами, если в первом цикле за понедельник отвечал набор номер 1, а за вторник — номер 2, то во втором цикле за понедельник отвечает набор номер 2, а за вторник — номер 3. Такая схема позволяет равномерно распределить нагрузку, а следовательно, и износ между всеми носителями.
Схемы «Ханойская башня» и «10 наборов» используются нечасто, так как многие системы резервирования их не поддерживают.
Хранение резервной копии
Лента стримера — запись резервных данных на магнитную ленту стримера;
«Облачный» бэкап» — запись резервных данных по «облачной» технологии через онлайн-службы специальных провайдеров;
DVD или CD — запись резервных данных на компактные диски;
HDD — запись резервных данных на жёсткий диск компьютера;
LAN — запись резервных данных на любую машину внутри локальной сети;
FTP — запись резервных данных на FTP-серверы;
USB — запись резервных данных на любое USB-совместимое устройство (такое, как флэш-карта или внешний жёсткий диск);
ZIP, JAZ, MO — резервное копирование на дискеты ZIP, JAZ, MO.
Методы борьбы с утерей информации
Утеря информации бывает по разным причинам.
Эксплуатационные поломки носителей информации
Описание: случайные поломки в пределах статистики отказов, связанные с неосторожностью или выработкой ресурса. Конечно же, если какая-то важная информация уже потеряна, то можно обратиться в специализированную службу — но надёжность этого не стопроцентная.
Борьба: хранить всю информацию (каждый файл) минимум в двух экземплярах (причём каждый экземпляр на своём носителе данных). Для этого применяются:
RAID 1, обеспечивающий восстановление самой свежей информации. Файлы, расположенные на сервере с RAID, более защищены от поломок, чем хранящиеся на локальной машине;
Ручное или автоматическое копирование на другой носитель. Для этого может использоваться система контроля версий, специализированная программа резервного копирования или подручные средства наподобие периодически запускаемого cmd-файла.
Стихийные и техногенные бедствия
Описание: шторм, землетрясение, кража, пожар, прорыв водопровода — всё это приводит к потере всех носителей данных, расположенных на определённой территории.
Борьба: единственный способ защиты от стихийных бедствий — держать часть резервных копий в другом помещении.
Вредоносные программы
Описание: в эту категорию входит случайно занесённое ПО, которое намеренно портит информацию — вирусы, черви, «троянские кони». Иногда факт заражения обнаруживается, когда немалая часть информации искажена или уничтожена.
Борьба:
Установка антивирусных программ на рабочие станции. Простейшие антивирусные меры — отключение автозагрузки, изоляция локальной сети от Интернета, и т. д.
Обеспечение централизованного обновления: первая копия антивируса получает обновления прямо из Интернета, а другие копии настроены на папку, куда первая загружает обновления; также можно настроить прокси-сервер таким образом, чтобы обновления кешировались (это всё меры для уменьшения трафика).
Иметь копии в таком месте, до которого вирус не доберётся — выделенный сервер или съёмные носители.
Если копирование идёт на сервер: обеспечить защиту сервера от вирусов (либо установить антивирус, либо использовать ОС, для которой вероятность заражения мала). Хранить версии достаточной давности, чтобы существовала копия, не контактировавшая с заражённым компьютером.
Если копирование идёт на съёмные носители: часть носителей хранить (без дописывания на них) достаточно долго, чтобы существовала копия, не контактировавшая с заражённым компьютером.
Человеческий фактор
Описание: намеренное или ненамеренное уничтожение важной информации — человеком, специально написанной вредоносной программой или сбойным ПО.
Борьба:
Тщательно расставить права на все ресурсы, чтобы другие пользователи не могли модифицировать чужие файлы. Исключение делается для системного администратора, который должен обладать всеми правами на всё, чтобы быть способным исправить ошибки пользователей, программ и т. д.
Построить работающую систему резервного копирования — то есть, систему, которой люди реально пользуются и которая достаточно устойчива к ошибкам оператора. Если пользователь не пользуется системой резервного копирования, вся ответственность за сохранность ложится на него.
Хранить версии достаточной давности, чтобы при обнаружении испорченных данных файл можно было восстановить.
Перед переустановкой ОС следует обязательно копировать всё содержимое раздела, на которой будет установлена ОС, на сервер, на другой раздел или на CD / DVD.
Оперативно обновлять ПО, которое заподозрено в потере данных.
Удалённое резервное копирование данных3
Удалённое резервное копирование данных — это сервис, предоставляющий пользователям систему для резервного копирования и хранения компьютерных файлов.
Системы удалённого резервного копирования обычно встраиваются в клиентскую программу, которая выполняется обычно один раз в день. Эта программа собирает, сжимает, шифрует и передаёт данные серверам поставщика услуг резервного копирования. Другим типом данного продукта, также доступном на рынке, является удалённая непрерывная защита данных (ТМВ).
История
Большинство сетевых (удалённых) служб резервного копирования появилось во время пузыря доткомов в конце 1990-х. Первое время на рынке было немного поставщиков этих услуг, но крупные промышленники быстро поняли важность той роли, которую эти провайдеры играли на арене веб-служб, поэтому деятельность M&A стала преобладающей в последние несколько лет.
Начиная с 2005 года большинство поставщиков услуг резервного копирования данных используют стратегию SaaS («программное обеспечение как услуга»). В последние годы также зафиксировано значительное увеличение числа провайдеров услуг резервного копирования с единственной и независимой активностью, которые составляют часть крупной промышленности.
Характерные черты
Резервное копирование использующихся файлов
Возможность резервного копирования файлов, которые часто остаются открытыми, такие как Outlook файлы (*.pst) или SQL-базы данных. Это позволяет ИТ-администраторам запускать резервное копирование в любое время суток.
Мульти-платформенность
Мультиплатформенный резервный сервис может копировать файлы разных платформ, таких как различные версии Windows, Macintosh, и Linux/Unix.
Зашифрованная передача данных
Шифрование для предотвращения перехвата данных. Это не означает, что данные обязательно будут зашифрованы при хранении.
Преимущества удаленного резервного копирования
Удаленное резервное копирование имеет преимущества по сравнению с традиционными методами резервного копирования:
возможно самый важный аспект копирования — то, что резервные копии сохранены отдельно от оригинальных данных;
удалённое резервное копирование не требует пользовательского вмешательства;
неограниченное хранение данных;
некоторые удалённые резервные службы могут работать непрерывно, копируя изменения в файлах;
большинство удалённых резервных служб содержит список версий файлов;
большинство удалённых резервных служб использует 128 — 448-битовое шифрование для отправки данных по небезопасным каналам передачи данных (например через Интернет);
некоторые службы удаленного резервного копирования могут сократить продолжительность резервного копирования передавая на сервер только изменившиеся данные.
Недостатки удаленного резервного копирования
Удаленного резервного копирования имеет некоторые недостатки:
в зависимости от доступной сетевой полосы пропускания восстановление данных может быть медленным. Поскольку данные хранятся отдельно, они могут быть восстановлены либо с помощью пересылки через Интернет, либо через диск, отправленный от поставщика услуг удалённого резервного копирования;
у некоторых поставщиков этих услуг не даётся гарантия, что данные будут сохранены конфиденциально, поэтому рекомендуется шифрование данных перед сохранением или автоматизацией процесса резервирования;
в случае, если поставщик услуг удалённого резервного копирования обанкротится или будет выкуплен другой компанией, то это может повлиять на доступность данных или стоимость использования сервиса;
если пароль кодирования будет потерян, то восстановление данных будет невозможно;
у некоторых поставщиков услуг удалённого резервного копирования часто есть ежемесячные лимиты, которые препятствуют большим
Никитин 26. Непрерывность бизнеса. Технологии обеспечения на уровне СХД. Репликация данных. Козачек 27. Управление жизненным циклом информации (ILM).
![]()
Information Lifecycle Management
2010/04/20 12:04:34
Information Lifecycle Management (ILM) — управление жизненным циклом информации, метод руководства информационными ресурсами предприятия, который нацелен на удовлетворение потребностей и на сокращение общей стоимости владения. Системы ILM представляют собой комплекс программный и аппаратных средств для оптимизации и обеспечения жизненного цикла от точки до точки.
Содержание [убрать]
|
В системе информационных технологий ILM — это перемещение информации различного рода и ценности в системе хранения данных (СХД) на основании модифицирующихся требований бизнеса к критериям защищенности и доступности информации с учетом ее ценности, актуальности и оптимизации расходов на ее хранение.
Понятие ILM основывается на том, что информация имеет определенный период жизни. Сначала происходит создание информации, которая находится в пользовании клиента определенный период времени и в итоге происходит ее уничтожение. В течение своего жизненного цикла ценность информации для бизнеса не стабильна и процесс ILM заключается в том, чтобы определить информационному ресурсу уровень обслуживания в соответствии с изменениями ценности информации. Другими словами, защита и доступ к наиболее важным данным должны быть значительно надежнее и быстрее, чем защита и доступ к данным, имеющим меньшую важность. В процессе жизненного цикла значение каждой информации для бизнес-процессов в разные периоды времени может меняться, поэтому уровень обслуживания данного информационного ресурса должен измениться соответственно.
[править]Цели и области проекта ILM
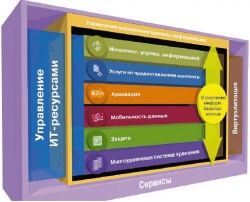
![]()
Структура ILM по версии EMC
Главной целью ILM является гарантирование актуальности и доступности данных посредством сохранения информации на различных уровнях СХД, а также приведение расходов на системы хранения данных к минимальному уровню с помощью оптимизации размещения данных в СХД. В число основных областей ILM входит: архивирование электронной почты, файлов и системы управления реляционными базами данных, управление ресурсами хранения и записями, многоуровневый комплекс оборудования.
Вследствие уменьшения количества повторяющихся файлов, а также выявления используемых и неиспользуемых файлов и соответствующего управления ими происходит лучшее управление ростом объемов данных.
Простое передвижение — начиная с уже имеющейся инфраструктуры, ее можно увеличивать за счет введения ITIL-совместимых методов использования открытых систем.
Абсолютный контроль расходов — связан с более результативным использованием ресурсов хранения, а также обеспечением сходства между уровнем обслуживания хранящихся данных и меняющейся со времени ценностью данных.
Качественно улучшенное использование данных — благодаря осуществлению требований к подготовке, производительности, управлению рисками потерь данных и обеспечению потребностей в долгосрочном хранении данных.
[править]ILM-решения
ILM решение — это комплект базирующихся на шаблонах, отвечающих потребностям бизнеса практических методов управления, которые дают возможность модифицировать многие аспекты введения и администрирования инфраструктуры хранения данных. Предприятия могут начать процессы реформирования инфраструктуры хранения с целью управления жизненным циклом информации с нескольких отправных точек.
Решение по управлению жизненным циклом информации дает возможность вводить процессы, политики, методики и инструменты с целью экономически эффективного расположения данных в среде хранения согласно их ценности для бизнеса - с момента возникновения данных до их уничтожения.
Как правило, в первую очередь компании стремятся удовлетворить потребностям в долгосрочном хранении электронной почты, управлении хранящимися в письмах вложениями и размером почтовых ящиков. В данном случае можно начинать с ERP-приложений, так как в них с течением времени собираются большие объемы данных. Для увеличения производительности и сокращения нагрузки на ресурсы хранения в данных приложениях можно использовать средства архивирования. Для того чтобы уменьшить расходы, организации довольно часто начинают с введения многоуровневой инфраструктуры хранения. Для еще большей экономии расходов, организации могут в дальнейшем вводить методы управления распределением данных по уровням хранения и разным приспособлениям и их передвижения между уровнями хранения на различных уровнях жизненного цикла.
В общем, ILM основывается на базовой оценке имеющихся ресурсов хранения и данных. Обычно она реализуется совместно с внедрением новых возможностей аварийного восстановления, новых распределений данных с позиции обеспечения безопасности или выполнением новых нормативных требований к архивированию данных для их долгосрочного хранения.
[править]Программно-аппаратные решения
IBM System Storage
IBM SVC (SAN Volume Controller)
IBM Digital Media Center
Informatica ILM
Informatica Data Archaive
Informatica Data Subset
Informatica Data Masking
EMC Storage Insight
Hitachi Services Oriented Storage Solutions, SOSS
HDS HCAP
HP ILM System
HP StorageWorks Reference Information Storage System (RISS)
HP StorageWorks File System Extender 3.1
HP ILM DSPP
SAP ILM
Symantec Storage Foundation 5.0
Symantec Dynamic Storage Tiering (DST)
[править]Область применения
Абсолютной реализации управления жизненным циклом информации в настоящее время нет. Однако определенные технологии используются уже сегодня. Эти технологии предоставят достаточно ощутимые преимущества и дадут возможность легче реализовать переход на ILM-стратегию в будущем. Ступенчатая инфраструктура хранения — основная деталь первого этапа реализации ILM-стратегии. Такая система устанавливает последовательность систем хранения на базе требований к качеству обслуживания, таких как постоянство бизнеса, производительность, охрана данных, защищенность хранимой информации, соответствие нормативным актам.
Фактически инфраструктура является объединением некоторого количества систем хранения в сеть. Различаются эти системы по стоимости и уровню обслуживания, который они предоставляют. Для любого типа информации и относящегося к нему приложения подбирается наиболее подходящее хранилище. В связи с тем, что абсолютная реализация ILM в гетерогенной среде приложений практически невозможна, главные поставщики систем хранения предоставляют инструменты для управления хранением структурированной и неструктурированной информацией. Для управления ссылочной информацией подготовлены новые специализированные решения. Способы управления структурированной информацией — это программные продукты, которые выполняют перенос данных в инфраструктуре хранения по установленным правилам. Файловая система серверов или таблицы баз данных могут быть представлены как структурированная информация.
В одном случае часть файловой системы будет перемещаться в подходящие на данный момент системы хранения в ступенчатой. В другом случае перенос данных будет выполняться из таблиц в архив или в другую СУБД. Средства управления неструктурированной информацией применяются для перенесения данных, у которых отсутствует выраженная структура, и тоже требуют интеграции на уровне приложений. На рынке уже есть программные продукты для управления почтовыми архивами (например, EMC EmailXtender).
Управление ссылочной информацией выполняется посредством программных, или программно-аппаратных средств — Content Addressed Storage (CAS). Отличительной чертой этих систем является то, что они дают возможность находить документы по содержимому, индексируя их в момент размещения в хранилище. В первую очередь их используют в архивах неструктурированной информации. Осуществление концепции управления жизненным циклом информации в инфраструктуре дата-центра — долгий и трудный процесс, но начинать его и добиться положительного результата выгоду от внедрения можно уже сейчас.
Сапрыкина 28. Понятие файловой системы. Основные задачи. Структура ФС.
Файловая система:
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы обеспечить пользователю удобный интерфейс при работе с данными, хранящимися на диске, и обеспечить совместное использование файлов несколькими пользователями и процессами.
Из лекций!
●Регламент, определяющий способ организации, хранения и именования данных на носителях информации.
●Определяет формат физического хранения информации, которую принято группировать в виде файлов:
◦ размер имени файла;
◦ максимально возможный размер файла
◦ набор атрибутов файла
◦ разграничение доступа
◦ шифрование файлов
Задачи файловой системы
именование файлов;
программный интерфейс работы с файлами для приложений;
отображения логической модели файловой системы на физическую организацию хранилища данных;
организация устойчивости файловой системы к сбоям питания, ошибкам аппаратных и программных средств;
содержание параметров файла, необходимых для правильного его взаимодействия с другими объектами системы (ядро, приложения и пр.).
В многопользовательских системах появляется ещё одна задача: защита файлов одного пользователя от несанкционированного доступа другого пользователя, а также обеспечение совместной работы с файлами, к примеру, при открытии файла одним из пользователей, для других этот же файл временно будет доступен в режиме «только чтение».
Структура файловой системы