

Основы теории информации
Понятие информатики как науки.
Информатика - молодая научная дисциплина, изучающая вопросы, связанные с поиском, сбором, хранением, преобразованием и использованием информации в самых различных сферах человеческой деятельности. Генетически информатика связана с вычислительной техникой, компьютерными системами и сетями, т.к. именно компьютеры позволяют порождать, хранить и автоматически перерабатывать информацию в таких количествах, что научный подход к информационным процессам становится одновременно необходимым и возможным. До настоящего времени толкование термина "информатика" (в том смысле как он используется в современной научной и методической литературе) еще не является установившимся и общепринятым. Обратимся к истории вопроса, восходящей ко времени появления электронных вычислительных машин.
После второй мировой войны возникла и начала бурно развиваться кибернетика как наука об общих закономерностях в управлении и связи в различных системах: искусственных, биологических, социальных. Рождение кибернетики принято связывать с опубликованием в 1948 г. американским математиком Норбертом Винером, ставшей знаменитой, книги "Кибернетика, или управление и связь в животном и машине". В этой работе были показаны пути создания общей теории управления и заложены основы методов рассмотрения проблем управления и связи для различных систем с единой точки зрения. Развиваясь одновременно с развитием электронно-вычислительных машин, кибернетика со временем превращалась в более общую науку о преобразовании информации.
Под информацией в кибернетике понимается любая совокупность сигналов, воздействий или сведений, которые некоторой системой воспринимаются от окружающей среды (входная информация X), выдаются в окружающую среду (выходная информация Y), а также хранятся в себе (внутренняя, внутрисистемная информация Z).
Развитие кибернетики в нашей стране встретило идеологические препятствия. Как отмечал академик А.И.Берг, в конце 50-х, начале 60-х годов в нашей литературе были допущены грубые ошибки в оценке значения и возможностей кибернетики. Все это нанесло серьезный ущерб развитию науки, привело к задержке в разработке многих теоретических положений и даже самих электронных машин.
Достаточно сказать, что еще в философском словаре 1959 года издания кибернетика характеризовалась как "буржуазная лженаука". Причиной этого явления послужили, с одной стороны, недооценка новой бурно развивающейся науки отдельными учеными "классического" направления, с другой - неумеренное пустословие тех, кто вместо активной разработки конкретных проблем кибернетики в различных областях спекулировал на полуфантастических прогнозах о безграничных возможностях кибернетики, дискредитируя тем самым эту науку.
Дело к тому же осложнялось тем, что развитие отечественной кибернетики на протяжении многих лет сопровождалось серьезными трудностями в реализации крупных государственных проектов, например, создания автоматизированных систем управления (АСУ). Однако, за это время удалось накопить значительный опыт создания информационных систем и систем управления технико-экономическими объектами. Требовалось выделить из кибернетики здоровое научное и техническое ядро и консолидировать силы для развития нового движения к давно уже стоящим глобальным целям.
Подойдем сейчас к этому вопросу с терминологической точки зрения. Вскоре вслед за появлением термина "кибернетика" в мировой науке стало использоваться англоязычное "Computer Science", а чуть позже, на рубеже шестидесятых и семидесятых годов, французы ввели получивший сейчас широкое распространение термин "Informatique". В русском языке раннее употребление термина "информатика" связано с узко-конкретной областью изучения структуры и общих свойств научной информации, передаваемой посредством научной литературы. Эта информационно-аналитическая деятельность, совершенно необходимая и сегодня в библиотечном деле, книгоиздании и т.д., уже давно не отражает современного понимания информатики. Как отмечал академик А.П.Ершов, в современных условиях термин - информатика - "вводится в русский язык в новом и куда более широком значении - как название фундаментальной естественной науки, изучающей процессы передачи и обработки информации. При таком толковании информатика оказывается более непосредственно связанной с философскими и общенаучными категориями, проясняется и ее место в кругу "традиционных" академических научных дисциплин"[1].
Попытку определить, что же такое современная информатика, сделал в 1978 г. Международный конгресс по информатике. Он отметил, что понятие информатики охватывает области, связанные с разработкой, созданием, использованием и материально-техническим обслуживанием систем обработки информации, включая машины, оборудование, математическое обеспечение, организационные аспекты, а также комплекс промышленного, коммерческого, административного и социального воздействия.
![]()
(1) Ершов А.П. Информатика: предмет и понятие. В кн.: Кибернетика. Становление информатики. - М.: Наука, 1986.
Информатика как единство науки и технологии.
Информатика - отнюдь не только "чистая наука". У нее, безусловно, имеется научное ядро, но важная особенность информатики - широчайшие приложения, охватывающие почти все виды человеческой деятельности: производство, управление, науку, образование, проектные разработки, торговлю, финансовую сферу, медицину, криминалистику, охрану окружающей среды и др. И, может быть, главное из них - совершенствование социального управления на основе новых информационных технологий.
Как наука, информатика изучает общие закономерности, свойственные информационным процессам (в самом широком смысле этого понятия). Когда разрабатываются новые носители информации, каналы связи, приемы кодирования, визуального отображения информации и многое другое, то конкретная природа этой информации почти не имеет значения. Для разработчика системы управления базами данных (СУБД) важны общие принципы организации и эффективность поиска данных, а не то, какие конкретно данные будут затем заложены в базу многочисленными пользователями. Эти общие закономерности есть предмет информатики как науки.
Объектом приложений информатики являются самые различные науки и области практической деятельности, для которых она стала непрерывным источником самых современных технологий, называемых часто "новые информационные технологии" (НИТ). Многообразные информационные технологии, функционирующие в разных видах человеческой деятельности (управлении производственным процессом, проектировании, финансовых операциях, образовании и т.п.), имея общие черты, в то же время существенно различаются между собой.
Перечислим наиболее впечатляющие реализации информационных технологий используя, ставшие традиционными, сокращения.
АСУ - автоматизированные системы управления - комплекс технических и программных средств, которые во взаимодействии с человеком организуют управление объектами в производстве или общественной сфере. Например, в образовании используются системы АСУ-ВУЗ.
АСУТП - автоматизированные системы управления технологическими процессами. Например, такая система управляет работой станка с числовым программным управлением (ЧПУ), процессом запуска космического аппарата и т.д.
Структура современной информатики.
Оставляя в стороне прикладные информационные технологии, опишем составные части "ядра" современной информатики. Каждая из этих частей может рассматриваться как относительно самостоятельная научная дисциплина; взаимоотношения между ними примерно такие же, как между алгеброй, геометрией и математическим анализом в классической математике - все они хоть и самостоятельные дисциплины, но, несомненно, части одной науки.
Теоретическая информатика - часть информатики, включающий ряд математических разделов. Она опирается на математическую логику и включает такие разделы как теория алгоритмов и автоматов, теория информации и теория кодирования, теория формальных языков и грамматик, исследование операций и другие. Этот раздел информатики использует математические методы для общего изучения процессов обработки информации.
Вычислительная техника - раздел, в котором разрабатываются общие принципы построения вычислительных систем. Речь идет не о технических деталях и электронных схемах (это лежит за пределами информатики как таковой), а о принципиальных решениях на уровне, так называемой, архитектуры вычислительных (компьютерных) систем, определяющей состав, назначение, функциональные возможности и принципы взаимодействия устройств. Примеры принципиальных, ставших классическими решений в этой области - неймановская архитектура компьютеров первых поколений, шинная архитектура ЭВМ старших поколений, архитектура параллельной (многопроцессорной) обработки информации.
Программирование - деятельность, связанная с разработкой систем программного обеспечения. Здесь отметим лишь основные разделы современного программирования: создание системного программного обеспечения и создание прикладного программного обеспечения. Среди системного - разработка новых языков программирования и компиляторов к ним, разработка интерфейсных систем (пример - общеизвестная операционная оболочка и система Windows). Среди прикладного программного обеспечения общего назначения самые популярные - системы обработки текстов, электронные таблицы (табличные процессоры), системы управления базами данных. В каждой области предметных приложений информатики существует множество специализированных прикладных программ более узкого назначения.
Информационные системы - раздел информатики связанный с решением вопросов по анализу потоков информации в различных сложных системах, их оптимизации, структурированию, принципах хранения и поиска информации. Информационно-справочные системы, информационно-поисковые системы, гигантские современные глобальные системы хранения и поиска информации (включая широко известный Internet) в последнее десятилетие XX века привлекают внимание все большего круга пользователей. Без теоретического обоснования принципиальных решений в океане информации можно просто захлебнуться. Известным примером решения проблемы на глобальном уровне может служить гипертекстовая поисковая система WWW, а на значительно более низком уровне - справочная система, к услугам которой мы прибегаем, набрав телефонный номер 09.
Искусственный интеллект - область информатики, в которой решаются сложнейшие проблемы, находящиеся на пересечении с психологией, физиологией, лингвистикой и другими науками. Как научить компьютер мыслить подобно человеку? - Поскольку мы далеко не все знаем о том, как мыслит человек, исследования по искусственному интеллекту, несмотря на полувековую историю, все еще не привели к решению ряда принципиальных проблем. Основные направления разработок, относящихся к этой области - моделирование рассуждений, компьютерная лингвистика, машинный перевод, создание экспертных систем, синтез и анализ сообщений на естественных языках, распознавание образов и другие. От успехов работ в области искусственного интеллекта зависит, в частности, решение такой важнейшей прикладной проблемы как создание интеллектуальных интерфейсных систем взаимодействия человека с компьютером, благодаря которым это взаимодействие будет походить на общение между людьми и станет более эффективным.
Место информатики в системе наук.
Рассмотрим место науки информатики в традиционно сложившейся системе наук (технических, естественных, гуманитарных и т.д.). В частности, это позволило бы найти место общеобразовательного курса информатики в ряду других учебных предметов.
Напомним, что по определению А.П.Ершова информатика - фундаментальная естественная наука. Академик Б.Н.Наумов определял информатику как естественную науку, изучающую общие свойства информации, процессы, методы и средства ее обработки (сбор, хранение, преобразование, перемещение, выдача).
Уточним, что такое фундаментальная наука и что такое естественная наука. К фундаментальным принято относить те науки, основные понятия которых носят общенаучный характер, используются во многих других науках и видах деятельности. Нет, например, сомнений в фундаментальности столь разных наук как математика и философия. В этом же ряду и информатика, так как понятия "информация", "процессы обработки информации" несомненно имеют общенаучную значимость.
Естественные науки - физика, химия, биология и другие - имеют дело с объективными сущностями мира, существующими независимо от нашего сознания. Отнесение к ним информатики отражает единство законов обработки информации в системах самой разной природы - искусственных, биологических, общественных.
Однако, многие ученые подчеркивают, что информатика имеет характерные черты и других групп наук - технических и гуманитарных (или общественных).
Черты технической науки придают информатике ее аспекты, связанные с созданием и функционированием машинных систем обработки информации. Так, академик А.А.Дородницын определяет состав информатики как три неразрывно и существенно связанные части: технические средства, программные и алгоритмические. Первоначальное наименовании школьного предмета "Основы информатики и вычислительной техники" в настоящее время изменено на "Информатика" (включающее в себя разделы, связанные с изучением технических, программных и алгоритмических средств). Науке информатике присущи и некоторые черты гуманитарной (общественной) науки, что обусловлено ее вкладом в развитие и совершенствование социальной сферы. Таким образом, информатика является комплексной, междисциплинарной отраслью научного знания.
Социальные аспекты информатики.
Термин "социальные аспекты" применительно к большей части наук, тем более фундаментальных, звучит странно. Вряд ли фраза "Социальные аспекты математики" имеет смысл. Однако, информатика - не только наука. Вспомним цитированное выше определение: "... комплекс промышленного, коммерческого, административного и социального воздействия".
И впрямь, мало какие факторы так влияют на социальную сферу обществ (разумеется, находящихся в состоянии относительно спокойного развития, без войн и катаклизмов) как информатизация. Информатизация общества - процесс проникновения информационных технологий во все сферы жизни и деятельности общества. Многие социологи и политологи полагают, что мир стоит на пороге информационного общества. В.А.Извозчиков под "информационным" ("компьютеризированным") обществом такое общество, во все сферы жизни и деятельности членов которого включены компьютер, телематика, другие средства информатики в качестве орудий интеллектуального труда, открывающих широкий доступ к сокровищам библиотек, позволяющих с огромной скоростью проводить вычисления и перерабатывать любую информацию, моделировать реальные и прогнозируемые события, процессы, явления, управлять производством, автоматизировать обучение и т.д.". Под "телематикой" он понимает службы обработки информации на расстоянии (кроме традиционных телефона и телеграфа).
Последние полвека информатизация является спутницей перетока людей из сферы прямого материального производства в, так называемую, информационную сферу. Промышленные рабочие и крестьяне, составлявшие в середине XX века более 2/3 населения, сегодня в развитых странах составляют менее 1/3. Все больше тех, кого называют "белые воротнички" - людей, не создающих материальные ценности непосредственно, а занятых обработкой информации (в самом широком смысле): это и учителя, и банковские служащие, и программисты, и многие другие категории работников. Появились и новые пограничные специальности. Можно ли назвать рабочим программиста, разрабатывающего программы для станков с числовым программным управлением? - По ряду параметров можно, однако его труд не физический, а интеллектуальный.
Приведем статистические данные, описывающие изменения в профессиональной структуре труда в США (стране, где информатизация идет особенно быстро) за период с 1970 по 1980 гг.
Таблица 1. Изменения в структуре труда в США за 10 лет |
|||
Категория работающих |
1970 г. в % |
1980 г., % |
Относительный прирост численности, % |
Работники сервиса |
19,9 |
21,5 |
+0,1 |
Рабочие (промышленные,сельскохозяйственные,фермеры) |
38,7 |
34,2 |
-11,6 |
Занятые обработкой информации(всего) |
41,5 |
44,4 |
+6,7 |
в том числе:менеджеры |
8,5 |
8,7 |
+2,4 |
конторские служащие |
18,0 |
18,9 |
+5,0 |
специалисты с высшимобразованием |
15,0 |
16,8 |
+12,0 |
Динамика, отраженная в этой таблице, подтверждает сказанное выше. Разумеется, не вся она обусловлена информатизацией, есть и иные факторы, но информатизация вносит решающий вклад. Даже в традиционных сферах деятельности - промышленности и торговле - работа с информацией становится на уровень работы с материальными объектами, в чем убеждают данные, приведенные в таблице 2.
Таблица 2. Профессиональная структура занятости в экономике США |
||
Отрасль |
Работают с информацией, % |
Работают с материальными объектами,% |
Обрабатывающая промышленность |
40 |
60 |
Транспорт и связь |
44 |
56 |
Оптовая торговля |
68 |
32 |
Розничная торговля |
58 |
42 |
Сфера услуг |
63 |
37 |
Финансовая деятельность |
92 |
8 |
Государственные учреждения |
70 |
30 |
За годы, прошедшие с момента публикации этих данных, ситуация изменилась в сторону дальнейшего увеличения доли населения, занятого в профессиональном труде обработкой информации. К середине 90-х годов численность "информационных работников" (к которым причисляют всех, в чьей профессиональной деятельности доминирует умственный труд), достигла в США 60%. Добавим, что за те же годы производительность труда в США за счет научно-технического прогресса (ведь информатизация - его главная движущая сила) в целом выросла на 37%.
Информатизация сильнейшим образом влияет на структуру экономики ведущих в экономическом отношении стран. В числе их лидирующих отраслей промышленности традиционные добывающие и обрабатывающие отрасли оттеснены максимально наукоемкими производствами электроники, средств связи и вычислительной техники - так называемой сферой высоких технологий. В этих странах постоянно растут капиталовложения в научные исследования, включая фундаментальные науки. Темпы развития сферы высоких технологий и уровень прибылей в ней превышают в 5-10 раз темпы развития традиционных отраслей производства. Такая политика имеет и социальные последствия - увеличение потребности в высокообразованных специалистах и связанный с этим прогресс системы высшего образования. Информатизация меняет и облик традиционных отраслей промышленности и сельского хозяйства. Промышленные роботы, управляемые ЭВМ, станки с ЧПУ стали обычным оборудованием. Новейшие технологии в сельскохозяйственном производстве не только увеличивают производительность труда, но и облегчают его, вовлекают более образованных людей.
Казалось бы, компьютеризация и информационные технологии несут в мир одну лишь благодать, но социальная сфера столь сложна, что последствия любого, даже гораздо менее глобального процесса, редко бывают однозначными. Рассмотрим, например, такие социальные последствия информатизации как рост производительности труда, интенсификацию труда, изменение условий труда. Все это, с одной стороны, улучшает условия жизни многих людей, повышает степень материального и интеллектуального комфорта, стимулирует рост числа высокообразованных людей, а с другой - является источником повышенной социальной напряженности. Например, появление на производстве промышленных роботов ведет к полному изменению технологии, которая перестает быть ориентированной на человека. Тем самым меняется номенклатура профессий. Значительная часть людей вынуждена менять либо специальность, либо место работы - рост миграции населения характерен для большинства развитых стран.
Государство и частные фирмы поддерживают систему повышения квалификации и переподготовки, но не все люди справляются с сопутствующим стрессом.
Прогрессом информатики порожден и другой достаточно опасный для демократического общества процесс - все большее количество данных о каждом гражданине сосредоточивается в разных (государственных и негосударственных) банках данных. Это и данные о профессиональной карьере (базы данных отделов кадров), здоровье (базы данных учреждений здравоохранения), имущественных возможностях (базы данных страховых компаний), перемещении по миру и т.д. (не говоря уже о тех, которые копят специальные службы). В каждом конкретном случае создание банка может быть оправдано, но в результате возникает система невиданной раньше ни в одном тоталитарном обществе прозрачности личности, чреватой возможным вмешательством государства или злоумышленников в частную жизнь. Одним словом, жизнь в "информационном обществе" легче, по-видимому, не становится, а вот то, что она значительно меняется - несомненно.
Трудно, живя в самом разгаре описанных выше процессов, взвесить, чего в них больше - положительного или отрицательного, да и четких критериев для этого не существует. Тяжелая физическая работа в не слишком комфортабельных условиях, но с уверенностью, что она будет постоянным источником существования для тебя и твоей семьи, с одной стороны, или интеллектуальный труд в комфортабельном офисе, но без уверенности в завтрашнем дне. Что лучше? Конечно, вряд ли стоит уподобляться английским рабочим, ломавшим в конце XYIII века станки, лишавшие их работы, но правительство и общество обязаны помнить об отрицательных социальных последствиях информатизации и научно-технического прогресса в целом и искать компенсационные механизмы.
Правовые аспекты информатики.
Деятельность программистов и других специалистов, работающих в сфере информатики, все чаще выступает в качестве объекта правового регулирования. Некоторые действия при этом могут быть квалифицированы как правонарушения (преступления).
Правовое сознание в целом, а в области информатики особенно, в нашем обществе находится на низком уровне. Все ли знают ответы на следующие вопросы:
можно ли не копируя купленную программу предоставить возможность пользоваться ею другому лицу;
кому принадлежит авторское право на программу, созданную студентом в ходе выполнения дипломной работы;
можно ли скопировать купленную программу для себя самого, чтобы иметь резервную копию;
можно ли декомпилировать программу, чтобы разобраться в ее деталях или исправить ошибки;
в чем состоит разница между авторским и имущественным правом.
Вопросов, подобных этим, возникает множество. Есть, конечно, такие, ответы на которые очевидны: нельзя создавать вирусы, нельзя хулиганить в сетях, нельзя в некоммерческих телеконференциях запускать коммерческую информацию, нельзя вскрывать и искажать защищенную информацию в чужих базах данных и т.д., т.е. совершать поступки, которые могут быть объектом уголовного преследования. Но на многие вопросы ответы отнюдь не очевидны, а иногда казуистически запутаны, причем не только в нашей стране. Остановимся на правовом регулировании в области информатики в России более подробно.
Необходимо отметить, что регулирование в сфере, связанной с защитой информации, программированием и т.д., является для российского законодательства принципиально новым, еще слабо разработанным направлением. К 1992 году был принят Закон Российской Федерации "О ПРАВОВОЙ ОХРАНЕ ПРОГРАММ ДЛЯ ЭЛЕКТРОННЫХ ВЫЧИСЛИТЕЛЬНЫХ МАШИН И БАЗ ДАННЫХ", содержащий обширный план приведения российского законодательства в сфере информатики в соответствие с мировой практикой. Действие этого Закона распространяется на отношения, связанные с созданием и использованием программ для ЭВМ и баз данных. Также предусматривалось внести изменения и дополнения в Гражданский кодекс РФ, в Уголовный кодекс РФ, другие законодательные акты, связанные с вопросами правовой охраны программ для электронных вычислительных машин и баз данных, привести решения Правительства РФ в соответствие с Законом, обеспечить пересмотр и отмену государственными ведомствами и другими организациями РФ их нормативных актов, противоречащих указанному Закону, обеспечить принятие нормативных актов в соответствии с указанным Законом и т.д.
Главное содержание данного Закона - юридическое определение понятий, связанных с авторством и распространением компьютерных программ и баз данных, таких как Авторство, Адаптация, База данных, Воспроизведение, Декомпилирование, Использование, Модификация и т.д., а также установление прав, возникающих при создании программ и баз данных - авторских, имущественных, на передачу, защиту, регистрацию, неприкосновенность и т.д.
Авторское право распространяется на любые программы для ЭВМ и базы данных (как выпущенные, так и не выпущенные в свет), представленные в объективной форме, независимо от их материального носителя, назначения и достоинства. Авторское право распространяется на программы для ЭВМ и базы данных, являющиеся результатом творческой деятельности автора. Творческий характер деятельности автора предполагается до тех пор, пока не доказано обратное.
Предоставляемая настоящим Законом правовая охрана распространяется на все виды программ для ЭВМ (в том числе на операционные системы и программные комплексы), которые могут быть выражены на любом языке и в любой форме, и на базы данных, представляющие собой результат творческого труда по подбору и организации данных. Предоставляемая правовая охрана не распространяется на идеи и принципы, лежащие в основе программы для ЭВМ и базы данных или какого-либо их элемента, в том числе идеи и принципы организации интерфейса и алгоритма, а также языки программирования.
Авторское право на программы для ЭВМ и базы данных возникает в силу их создания. Для признания и осуществления авторского права на программы для ЭВМ и базы данных не требуется опубликования, регистрации или соблюдения иных формальностей. Авторское право на базу данных признается при условии соблюдения авторского права на каждое из произведений, включенных в базу данных.
Автором программы для ЭВМ и базы данных признается физическое лицо, в результате творческой деятельности которого они созданы.
Если программа для ЭВМ и база данных созданы совместной творческой деятельностью двух и более физических лиц, то, независимо от того, состоит ли программа для ЭВМ или база данных из частей, каждая из которых имеет самостоятельное значение, или является неделимой, каждое из этих лиц признается автором такой программы для ЭВМ и базы данных.
Автору программы для ЭВМ или базы данных или иному правообладателю принадлежит исключительное право осуществлять и (или) разрешать осуществление следующих действий:
выпуск в свет программы для ЭВМ и базы данных;
воспроизведение программы для ЭВМ и базы данных (полное или частичное) в любой форме, любыми способами;
распространение программы для ЭВМ и баз данных;
модификацию программы для ЭВМ и базы данных, в том числе перевод программы для ЭВМ и базы данных с одного языка на другой;
иное использование программы для ЭВМ и базы данных.
Однако, имущественные права на программы для ЭВМ и базы данных, созданные в порядке выполнения служебных обязанностей или по заданию работодателя, принадлежат работодателю, если в договоре между ним и автором не предусмотрено иное. Таким образом, имущественное право на программу, созданную в ходе дипломного проектирования, принадлежит не автору, а вузу - по крайней мере, пока между ними не будет заключено специальное соглашение.
Имущественные права на программу для ЭВМ и базу данных могут быть переданы полностью или частично другим физическим или юридическим лицам по договору. Договор заключается в письменной форме и должен устанавливать следующие существенные условия: объем и способы использования программы для ЭВМ или базы данных, порядок выплаты и размер вознаграждения, срок действия договора.
Лицо, правомерно владеющее экземпляром программы для ЭВМ или базы данных, вправе без получения дополнительного разрешения правообладателя осуществлять любые действия, связанные с функционированием программы для ЭВМ или базы данных в соответствии с их назначением, в том числе запись и хранение в памяти ЭВМ, а также исправление явных ошибок. Запись и хранение в памяти ЭВМ допускаются в отношении одной ЭВМ или одного пользователя в сети, если иное не предусмотрено договором с правообладателем. Также допускается без согласия правообладателя и без выплаты ему дополнительного вознаграждения осуществлять следующие действия:
адаптацию программы для ЭВМ или базы данных;
изготавливать или поручать изготовление копии программы для ЭВМ или базы данных при условии, что эта копия предназначена только для архивных целей и при необходимости (в случае, когда оригинал программы для ЭВМ или базы данных утерян, уничтожен или стал непригодным для использования) для замены правомерно приобретенного экземпляра.
Лицо, правомерно владеющее экземпляром программы для ЭВМ, вправе без согласия правообладателя и без выплаты дополнительного вознаграждения выполнять декомпилирование программы для ЭВМ с тем, чтобы изучить кодирование и структуру этой программы при следующих условиях:
информация, необходимая для взаимодействия независимо разработанной данным лицом программы для ЭВМ с другими программами, недоступна из других источников;
информация, полученная в результате этого декомпилирования, может использоваться лишь для организации взаимодействия независимо разработанной данным лицом программы для ЭВМ с другими программами, а не для составления новой программы для ЭВМ, по своему виду существенно схожей с декомпилируемой программой.
Свободная перепродажа экземпляра программы для ЭВМ и базы данных допускается без согласия правообладателя и без выплаты ему дополнительного вознаграждения после первой продажи или другой передачи права собственности на этот экземпляр.
Выпуск под своим именем чужой программы для ЭВМ или базы данных, а также незаконное воспроизведение или распространение таких произведений влечет за собой уголовную ответственность.
В настоящее время уголовное законодательство РФ не в полной мере учитывает все возможные компьютерные преступления. Вообще же, в законодательной практике многих стран отмечены различные виды компьютерных преступлений и разработаны методы борьбы с ними.
Компьютерные преступления условно можно разделить на две большие категории.
Преступления, связанные с вмешательством в работу компьютеров.
Преступления, использующие компьютеры как необходимые технические средства.
Можно выделить следующие виды компьютерной преступности 1-го вида:
несанкционированный доступ в компьютерные сети и системы, банки данных с целью шпионажа или диверсии (военного, промышленного, экономического), с целью, так называемого, компьютерного хищения или из хулиганских побуждений;
ввод в программное обеспечение так называемых "логических бомб", срабатывающих при определенных условиях (логические бомбы, угрожающие уничтожением данных, могут использоваться для шантажа владельцев информационных систем, или выполнять новые, не планировавшиеся владельцем программы, функции, при сохранении работоспособности системы; известны случаи, когда программисты вводили в программы финансового учета команды, переводящие на счета этих программистов денежные суммы, или скрывающие денежные суммы от учета, что позволяло незаконно получать их);
разработку и распространение компьютерных вирусов;
преступную небрежность в разработке, изготовлении и эксплуатации программно-вычислительных комплексов, приведшую к тяжким последствиям;
подделку компьютерной информации (продукции) и сдача заказчикам неработоспособных программ, подделка результатов выборов, референдумов;
хищение компьютерной информации (нарушение авторского права и права владения программными средствами и базами данных).
Среди компьютерных преступлений 2-го вида, т.е. использующих компьютер как средство преступления, следует отметить преступления, спланированные на основе компьютерных моделей, например, в сфере бухгалтерского учета.
Для современного состояния правового регулирования сферы, связанной с информатикой, в России в настоящее время наиболее актуальными являются вопросы, связанные с нарушением авторских прав. Большая часть программного обеспечения, использующегося отдельными программистами и пользователями и целыми организациями, приобретена в результате незаконного копирования, т.е. хищения. Назрела потребность узаконить способы борьбы с этой порочной практикой, поскольку она мешает, прежде всего, развитию самой информатики.
Этические аспекты информатики.
Далеко не все правила, регламентирующие деятельность в сфере информатики, можно свести в правовым нормам. Очень многое определяется соблюдением неписаных правил поведения для тех, кто причастен к миру компьютеров. Впрочем, в этом отношении информатика ничуть не отличается от любой другой сферы деятельности человека в обществе.
Как и в любой другой большой и разветвленной сфере человеческой деятельности, в информатике к настоящему времени сложились определенные морально-этические нормы поведения и деятельности.
Морально-этические нормы в среде информатиков отличаются от этики повседневной жизни несколько большей открытостью, альтруизмом. Большинство нынешних специалистов-информатиков сформировались и приобрели свои знания и квалификацию благодаря бескорыстным консультациям и содействию других специалистов. Очевидно, поэтому они готовы оказать бескорыстную помощь, дать совет или консультацию, предоставить компьютер для выполнения каких-либо манипуляций с дискетами и т.д. Ярким примером особой психологической атмосферы в среде информатиков является расширяющееся международное движение программистов, предоставляющих созданные ими программные средства для свободного распространения.
Это - положительные аспекты, но есть и отрицательные. Обратим внимание на язык информатиков. Сленг российских информатиков построен на искаженных под русское произношение англоязычных терминах и аббревиатурах, введенных иностранными фирмами - разработчиками компьютеров и программного обеспечения в технической документации. Одновременно формируется и набор сленговых слов, заимствованных из русского языка на основе аналогий и ассоциаций по сходству и смежности (например: архивированный - "утоптанный", компьютер - "железо" или "тачка" и т.д.). С тем, что многие специальные термины пришли к нам из США, приходится мириться. Никто сегодня уже не перейдет от термина "принтер" к аналогичному "автоматическое цифровое печатающее устройство" (которым пользовались не так уж давно). Приживаемости подобных слов в отечественной литературе способствует, в частности, их относительная краткость.
Особую остроту этические проблемы приобретают при работе в глобальных телекоммуникационных сетях. Вскрыть защиту чужой базы данных - уголовное преступление. А можно ли позволять себе нецензурные выражения или прозрачные их эвфемизмы? Коммерческую рекламу в некоммерческой телеконференции? - Независимо от того, предусмотрено за это законом возмездие или нет, порядочный человек этого делать не станет.
Этика - система норм нравственного поведения человека. Порядочный человек не прочтет содержимое дискеты, забытой соседом на рабочем месте, не потому, что это грозит ему наказанием, а потому, что это безнравственный поступок; не скопирует программу в отсутствие ее хозяина не потому, что на него могут подать в суд, а потому, что этот поступок осудят его коллеги. Всякий раз, собираясь совершить сомнительный поступок в сфере профессиональной деятельности, человек должен задуматься, соответствует ли он этическим нормам, сложившимся в профессиональном сообществе.
Философские аспекты информации.
Как ни важно измерение информации, нельзя сводить к нему все связанные с этим понятием проблемы. При анализе информации социального (в широким смысле) происхождения на первый план могут выступить такие ее свойства как истинность, своевременность, ценность, полнота и т.д. Их невозможно оценить в терминах "уменьшение неопределенности" (вероятностный подход) или числа символов (объемный подход). Обращение к качественной стороне информации породило иные подходы к ее оценке. При аксиологическом подходе стремятся исходить из ценности, практической значимости информации, т.е. качественных характеристик, значимых в социальной системе. При семантическом подходе информация рассматривается как с точки зрения формы, так и содержания. При этом информацию связывают с тезаурусом, т.е. полнотой систематизированного набора данных о предмете информации.
Отметим, что эти подходы не исключают количественного анализа, но он становится существенно сложнее и должен базироваться на современных методах математической статистики.
Понятие информации нельзя считать лишь техническим, междисциплинарным и даже наддисциплинарным термином. Информация - это фундаментальная философская категория. Дискуссии ученых о философских аспектах информации надежно показали не сводимость информации ни к одной из этих категорий. Концепции и толкования, возникающие на пути догматических подходов, оказываются слишком частными, односторонними, не охватывающими всего объема этого понятия.
Попытки рассмотреть категорию информации с позиций основного вопроса философии привели к возникновению двух противостоящих концепций - так называемых, функциональной и атрибутивной. "Атрибутисты" квалифицируют информацию как свойство всех материальных объектов, т.е. как атрибут материи. "Функционалисты" связывают информацию лишь с функционированием сложных, самоорганизующихся систем. Оба подхода, скорее всего, неполны. Дело в том, что природа сознания, духа по сути своей является информационной, т.е. сознание суть менее общее понятие по отношению к категории "информация". Нельзя признать корректными попытки сведения более общего понятия к менее общему. Таким образом, информация и информационные процессы, если иметь в виду решение основного вопроса философии, опосредуют материальное и духовное, т.е. вместо классической постановки этого вопроса получается два новых: о соотношении материи и информации и о соотношении информации и сознания (духа).
Можно попытаться дать философское определение информации с помощью указания на связь определяемого понятия с категориями отражения и активности.
Информация есть содержание образа, формируемого в процессе отражения. Активность входит в это определение в виде представления о формировании некоего образа в процессе отражения некоторого субъект-объектного отношения. При этом не требуется указания на связь информации с материей, поскольку как субъект, так и объект процесса отражения могут принадлежать как к материальной, так и к духовной сфере социальной жизни. Однако существенно подчеркнуть, что материалистическое решение основного вопроса философии требует признания необходимости существования материальной среды - носителя информации в процессе такого отражения. Итак, информацию следует трактовать как имманентный (неотъемлемо присущий) атрибут материи, необходимый момент ее самодвижения и саморазвития. Эта категория приобретает особое значение применительно к высшим формам движения материи - биологической и социальной.
Данное выше определение схватывает важнейшие характеристики информации. Оно не противоречит тем знаниям, которые накоплены по этой проблематике, а наоборот, является выражением наиболее значимых.
Современная практика психологии, социологии, информатики диктует необходимость перехода к информационной трактовке сознания. Такая трактовка оказывается чрезвычайно плодотворной, и позволяет, например, рассмотреть с общих позиций индивидуальное и общественное сознание. Генетически индивидуальное и общественное сознание неразрывны и в то же время общественное сознание не есть простая сумма индивидуальных, поскольку оно включает информационные потоки и процессы между индивидуальными сознаниями.
В социальном плане человеческая деятельность предстает как взаимодействие реальных человеческих коммуникаций с предметами материального мира. Поступившая извне к человеку информация является отпечатком, снимком сущностных сил природы или другого человека. Таким образом, с единых методологических позиций может быть рассмотрена деятельность индивидуального и общественного сознания, экономическая, политическая, образовательная деятельность различных субъектов социальной системы.
Данное выше определение информации как философской категории затрагивает не только физические аспекты существования информации, но и фиксирует ее социальную значимость.
Одной из важнейших черт функционирования современного общества выступает его информационная оснащенность. В ходе своего развития человеческое общество прошло через пять информационных революций. Первая из них была связана с введением языка, вторая - письменности, третья - книгопечатания, четвертая - телевидения, и, наконец, пятая - компьютеров (а также магнитных и оптических носителей хранения информации). Каждый раз новые информационные технологии поднимали информированность общества на несколько порядков, радикально меняя объем и глубину знания, а вместе с этим и уровень культуры в целом.
Одна из целей философского анализа понятия информации - указать место информационных технологий в развитии форм движения материи, в прогрессе человечества и, в том числе, в развитии разума как высшей отражательной способности материи. На протяжении десятков тысяч лет сфера разума развивалась исключительно через общественную форму сознания. С появлением компьютеров начались разработки систем искусственного интеллекта, идущих по пути моделирования общих интеллектуальных функций индивидуального сознания.
Информация в физическом мире.
Известно большое количество работ, посвященных физической трактовке информации. Эти работы в значительной мере построены на основе аналогии формулы Больцмана, описывающей энтропию статистической системы материальных частиц, и формулы Хартли.
Заметим, что при всех выводах формулы Больцмана явно или неявно предполагается, что макроскопическое состояние системы, к которому относится функция энтропии, реализуется на микроскопическом уровне как сочетание механических состояний очень большого числа частиц, образующих систему (молекул). Задачи же кодирования и передачи информации, для решения которых Хартли и Шенноном была развита вероятностная мера информации, имели в виду очень узкое техническое понимание информации, почти не имеющее отношения к полному объему этого понятия. Таким образом, большинство рассуждений, использующих термодинамические свойства энтропии применительно к информации нашей реальности, носят спекулятивный характер.
В частности, являются необоснованными использование понятия "энтропия" для систем с конечным и небольшим числом состояний, а также попытки расширительного методологического толкования результатов теории вне довольно примитивных механических моделей, для которых они были получены. Энтропия и негэнтропия - интегральные характеристики протекания стохастических процессов - лишь параллельны информации и превращаются в нее в частном случае.
Информацию следует считать особым видом ресурса, при этом имеется ввиду толкование "ресурса" как запаса неких знаний материальных предметов или энергетических, структурных или каких-либо других характеристик предмета. В отличие от ресурсов, связанных с материальными предметами, информационные ресурсы являются неистощимыми и предполагают существенно иные методы воспроизведения и обновления, чем материальные ресурсы.
Рассмотрим некоторый набор свойств информации:
запоминаемость;
передаваемость;
преобразуемость;
воспроизводимость;
стираемость.
Свойство запоминаемости - одно из самых важных. Запоминаемую информацию будем называть макроскопической (имея ввиду пространственные масштабы запоминающей ячейки и время запоминания). Именно с макроскопической информацией мы имеем дело в реальной практике.
Передаваемость информации с помощью каналов связи (в том числе с помехами) хорошо исследована в рамках теории информации К.Шеннона. В данном случае имеется ввиду несколько иной аспект - способность информации к копированию, т.е. к тому, что она может быть "запомнена" другой макроскопической системой и при этом останется тождественной самой себе. Очевидно, что количество информации не должно возрастать при копировании.
Воспроизводимость информации тесно связана с ее передаваемостью и не является ее независимым базовым свойством. Если передаваемость означает, что не следует считать существенными пространственные отношения между частями системы, между которыми передается информация, то воспроизводимость характеризует неиссякаемость и неистощимость информации, т.е. что при копировании информация остается тождественной самой себе.
Фундаментальное свойство информации - преобразуемость. Оно означает, что информация может менять способ и форму своего существования. Копируемость есть разновидность преобразования информации, при котором ее количество не меняется. В общем случае количество информации в процессах преобразования меняется, но возрастать не может. Свойство стираемости информации также не является независимым. Оно связано с таким преобразованием информации (передачей), при котором ее количество уменьшается и становится равным нулю.
Данных свойств информации недостаточно для формирования ее меры, так как они относятся к физическому уровню информационных процессов.
Подводя итог сказанному в предыдущих шагах, отметим, что предпринимаются (но отнюдь не завершены) усилия ученых, представляющих самые разные области знания, построить единую теорию, которая призвана формализовать понятие информации и информационного процесса, описать превращения информации в процессах самой разной природы. Движение информации есть сущность процессов управления, которые суть проявление имманентной активности материи, ее способности к самодвижению. С момента возникновения кибернетики управление рассматривается применительно ко всем формам движения материи, а не только к высшим (биологической и социальной). Многие проявления движения в неживых - искусственных (технических) и естественных (природных) - системах также обладают общими признаками управления, хотя их исследуют в химии, физике, механике в энергетической, а не в информационной системе представлений. Информационные аспекты в таких системах составляют предмет новой междисциплинарной науки - синергетики.
Высшей формой информации, проявляющейся в управлении в социальных системах, являются знания. Это наддисциплинарное понятие, широко используемое в педагогике и исследованиях по искусственному интеллекту, также претендует на роль важнейшей философской категории. В философском плане познание следует рассматривать как один из функциональных аспектов управления. Такой подход открывает путь к системному пониманию генезиса процессов познания, его основ и перспектив.
Начальные определения информации.
Любая наука начинается со строгих определений используемых ею понятий и терминов. Поэтому было бы вполне разумным начать изложение основ теории информации именно с ее точного определения. Определить какое-либо понятие - значит выразить его через другие понятия, уже определенные ранее. Сложность ситуации, однако, в том, что информация является одной из исходных категорий мироздания, и, следовательно, определение "информации вообще" невозможно свести к каким-то более простым, более "исходным" терминам.
Что касается частных трактовок понятия "информация", то следует отметить значительное их расхождение в различных научных дисциплинах, в технике и на бытовом уровне. Такое положение не следует считать каким-то необычным - можно привести много аналогичных примеров, когда термин имеет и используется во множестве значений: движение, энергия, система, связь, язык и пр. Неоднозначность преодолевается тем, что в каждой "узкой" дисциплине дается свое определение термина - его следует считать частным - и именно оно используется. Но это, безусловно, не дает основания переносить такое определение и применять его вне рамок данной дисциплины. Например, в теоретической механике "связь" определяется как некое внешнее воздействие, ограничивающее возможности перемещения (степени свободы) тела; нет смысла такую трактовку пытаться применять, скажем, в телеграфии или социальных науках.
Аналогична ситуация и с термином "информация": на бытовом уровне и во многих научных дисциплинах он ассоциируется с понятиями сведения, знания, данные, известие, сообщение, управление и др. Общим во всех перечисленных примерах является то, в них существенным и значимым для использования является содержательная сторона информации - с позиций "здравого смысла" это представляется вполне естественным. Однако оценка смысла и ценности одной и той же информации различными людьми, вообще говоря, будет различной; объективная количественная мера смысловой стороны информации отсутствует. С другой стороны, можно привести примеры ситуаций, когда семантическая основа информации роли не играет, точнее, она принимается в виде атрибута (свойства, качества) информации, который не должен изменяться, а для этого следует обеспечить неизменность материального представления информации. По этой причине в ряде теоретических, технических и даже организационных приложений можно просто сосредоточиться на задаче обеспечения неизменности информации в процессах, с ней связанных (в первую очередь, это передача и хранение), а также поиске наилучших условий осуществления этих процессов безотносительно содержания самой информации. Например, задача библиотеки - обеспечить хранение, учет и доступ читателей к любым имеющимся в фонде книгам, независимо от их содержания; действия библиотекарей сводятся к тому, чтобы по формальным признакам - кодам, фамилии автора, названию - отыскать нужную книгу и выдать читателю; при этом содержание, полезность, новизну, значимость и т.п. книги оценивает именно читатель (т.е. лицо, использующее информацию), а не тот, кто ее хранит.
Отделив информацию от ее семантической основы, мы получаем возможность построить определение информации и параллельно ввести ее объективную количественную меру. Будет использован способ определения, который называется операционным и который состоит в описании метода измерения или нахождения значения определяемой величины - такому способу отдается предпочтение в научном знании, поскольку он обеспечивается однозначность и объективность, чего трудно добиться для категорий, не имеющих меры (например, попробуйте определить понятие "доброта"). Открытие такого способа определения информации является одной из главных заслуг теории информации.
Операционное определение информации будет нами рассмотрено позже, поскольку оно требует освоения ряда предшествующих и сопутствующих понятий. Пока же мы обсудим особенность, которой обладает любая информация, - это то, что информация - категория нематериальная. Следовательно, для существования и распространения в нашем материальном мире она должна быть обязательно связана с какой-либо материальной основой - без нее информация не может проявиться, передаваться и сохраняться, например, восприниматься и запоминаться нами. Введем определение:
Материальный объект или среду, которые служат для представления или передачи информации, будем называть ее материальным носителем.
Материальным носителем информации может быть бумага, воздух, лазерный диск, электромагнитное поле и пр. При этом хранение информации связано с некоторой характеристикой носителя, которая не меняется с течением времени, например намагниченные области поверхности диска или буква на бумаге, а передача информации - наоборот, с характеристикой, которая изменяется с течением времени, например амплитуда колебаний звуковой волны или напряжение в проводах. Другими словами, хранение информации связано с фиксацией состояния носителя, а распространение - с процессом, который протекает в носителе. Состояния и процессы могут иметь физическую, химическую, биологическую или иную основу - главное, что они материальны.
Однако не с любым процессом можно связать информацию. В частности, стационарный процесс, т.е. процесс с неизменными в течение времени характеристиками, информацию не переносит. Примером может служить постоянный электрический ток, ровное горение лампы, или равномерный гул - они содержат лишь ту информацию, что процесс идет, т.е. что-то функционирует. Иное дело, если мы будем лампу включать и выключать, т.е. изменять ее яркость, - чередованием вспышек и пауз можно представить и передать информацию (например, посредством азбуки Морзе). Таким образом, для передачи необходим нестационарный процесс, т.е. процесс, характеристики которого могут изменяться; при этом информация связывается не с существованием процесса, а именно с изменением какой-либо его характеристики.
Изменение характеристики носителя, которое используется для представления информации, называется сигналом, а значение этой характеристики, отнесенное к некоторой шкале измерений, называется параметром сигнала.
В таблице 1 приведены примеры процессов, используемых для передачи информации, и связанных с ними сигналов.
Таблица 1. Примеры процессов, используемых для передачи информации |
||
Способ передачи |
Процесс |
Параметры сигнала |
Звук |
Звуковые волны |
Высота и громкость звука |
Радио, телевидение |
Радиоволны |
Частота, амплитуда или фаза радиоволны |
Изображение |
Световые волны |
Частота и амплитуда световых волн |
Телефон, компьютерная сеть |
Электрический ток |
Частота и амплитуда электрических колебаний в линии связи |
Однако одиночный сигнал, как мы увидим в дальнейшем, не может содержать много информации. Поэтому для передачи информации используется ряд следующих друг за другом сигналов.
Последовательность сигналов называется сообщением.
Таким образом, от источника к приемнику информация передается в виде сообщений. Можно сказать, что сообщение выступает в качестве материальной оболочки для представления информации при передаче. Следовательно, сообщение служит переносчиком информации, а информация является содержанием сообщения.
Соответствие между сообщением и содержащейся в нем информацией называется правилом интерпретации сообщения.
Это соответствие может быть однозначным и неоднозначным. В первом случае сообщение имеет лишь одно правило интерпретации. Например, по последовательности точек, тире и пауз в азбуке Морзе однозначно восстанавливается переданная буква. Неоднозначность соответствия между сообщением и информацией возможна в двух вариантах:
одна и та же информация может передаваться различными сообщениями (например, прогноз погоды может быть получен по радио, из газеты, по телефону и пр.);
одно и то же сообщение может содержать различную информацию для разных приемников (примером может служить передача в 1936 г. по радио фразы "Над всей Испанией безоблачное небо", которое для непосвященных людей имело смысл прогноза погоды, а для знакомых с правилом интерпретации - сигналом к началу военных действий).
Обсудим следующее исходное понятие - информационный процесс. Вообще термин "процесс" применяется в тех случаях, когда некоторое качество, характеризующее систему или объект, меняется с течением времени в результате внешних воздействий или каких-то внутренних причин. Какие атрибуты могут изменяться с течением времени у нематериальной информации? Очевидно, только ее содержание и материальная оболочка, посредством которого информация представлена, т.е. сообщение. В связи с этим примем следующее определение:
Информационный процесс - это изменение с течением времени содержания информации или представляющего его сообщения.
Различных видов информационных процессов оказывается немного:
порождение (создание) новой информации;
преобразование информации (т.е. порождение новой информации в результате обработки имеющейся);
уничтожение информации;
передача информации (распространение в пространстве).
На самом деле все перечисленные события происходят не непосредственно с самой информацией, а с сообщением, т.е. ее материальной оболочкой. И с этих позиций возможны лишь два типа процессов: изменение сообщения с сохранением содержащейся в нем информации и изменение сообщения, сопровождающееся преобразованием информации. К процессам первого типа относится передача информации без потерь и обратимая перекодировка; к процессам второго типа - создание-уничтожение, необратимая перекодировка, передача с потерями, обработка с появлением новой информации.
Отдельно следует остановиться на хранении информации. Как уже было сказано, хранение связывается с фиксацией параметра материального носителя, который далее с течением времени не меняется. Следовательно, запись информации на носитель (непосредственно момент фиксации параметра) и ее последующее считывание подпадают под определение информационного процесса, но само хранение - нет. Хранение следовало бы назвать информационным состоянием, однако, такое понятие в информатике не используется.
С передачей информации связана еще одна пара исходных сопряженных понятий - источник и приемник информации.
Источник информации - это субъект или объект, порождающий информацию и представляющий ее в виде сообщения.
Приемник информации - это субъект или объект, принимающий сообщение и способный правильно его интерпретировать.
В этих определениях сочетание "субъект или объект" означает, что источники и приемники информации могут быть одушевленными (человек, животные) или неодушевленными (технические устройства, природные явления). Для того чтобы объект (или субъект) считался источником информации, он должен не только ее породить, но и иметь возможность инициировать какой-то нестационарный процесс и связать информацию с его параметрами, т.е. создать сообщение. Например, если человек что-то придумал, но держит это в своем мозге, он не является источником информации; однако он им становится, как только свою идею изложит на бумаге (в виде текста, рисунка, схемы и пр.) или выскажет словами.
В определении приемника информации важным представляется то, что факт приема сообщения еще не означает получение информации; информация может считаться полученной только в том случае, если приемнику известно правило интерпретации сообщения. Другими словами, понятия "приемник сообщения" и "приемник информации" не тождественны. Например, слыша речь на незнакомом языке, человек оказывается приемником сообщения, но не приемником информации.
Для связи с внешним миром у человека, как известно, имеются пять органов чувств. Следовательно, воспринимать сообщение мы можем только посредством одного из них (или группой органов). Это не означает, однако, что человек не может использовать для передачи и приема информации какие-то иные процессы, им не воспринимаемые, например радиоволны. В этом случае человек-источник использует промежуточное устройство, преобразующее его сообщение в радиоволны - радиопередатчик, а человек-приемник - другое промежуточное устройство - радиоприемник, преобразующий радиоволны в звук. Такой подход заметным образом расширяет возможности человека в осуществлении передачи и приема информации.
Промежуточные устройства-преобразователи получили название технические средства связи, а в совокупности с соединяющей их средой они называются линией связи. К ним относятся телеграф, телефон, радио и телевидение, компьютерные телекоммуникации и пр. При использовании таких средств возникает необходимость преобразования сообщения из одного вида в другой без существенной для получателя потери информации, а также увязки скорости передачи сообщения (т.е. интервала следования и величины отдельных сигналов) с возможностями линии связи и приемника. Обе эти проблемы оказываются центральными в теории информации.
Формы представления информации.
В предыдущем шаге было сказано, что передача информация производится с помощью сигналов, а самим сигналом является изменение некоторой характеристики носителя с течением времени. При этом в зависимости от особенностей изменения этой характеристики (т.е. параметра сигнала) с течением времени выделяют два типа сигналов: непрерывные и дискретные.
Сигнал называется непрерывным (или аналоговым), если его параметр может принимать любое значение в пределах некоторого интервала.
Если обозначить Z – значение параметра сигнала, а t – время, то зависимость Z(t) будет непрерывной функцией (рис.1(а)).
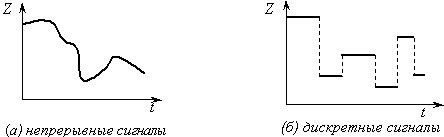 Рис.1.
Непрерывные и дискретные сигналы
Рис.1.
Непрерывные и дискретные сигналы
Примерами непрерывных сигналов являются речь и музыка, изображение, показание термометра (параметр сигнала – высота столба спирта или ртути – имеет непрерывный ряд значений) и пр.
Сигнал называется дискретным, если его параметр может принимать конечное число значений в пределах некоторого интервала.
Пример дискретных сигналов представлен на рис. 1(б). Как следует из определения, дискретные сигналы могут быть описаны дискретным и конечным множеством значений параметров {Z}. Примерами устройств, использующих дискретные сигналы, являются часы (электронные и механические), цифровые измерительные приборы, книги, табло и пр.
Поскольку последовательность сигналов есть сообщение, качество прерывности-непрерывности сигналов переносится и на сообщение – существуют понятия непрерывное сообщение и дискретное сообщение. Очевидно, что дискретным будет считаться сообщение, построенное из дискретных сигналов. Гораздо меньше оснований приписывать данное качество самой информации, поскольку информация – категория нематериальная и не может обладать свойством дискретности или непрерывности. С другой стороны, одна и та же информация, как уже было сказано, может быть представлена посредством различных сообщений, в том числе и отличающихся характером сигналов. Например, речь, которую мы слышим, можно записать в аналоговом виде с помощью магнитофона, а можно и законспектировать посредством дискретного набора букв. По этой причине в информатике существуют и используются сочетания непрерывная информация и дискретная информация. Их нужно понимать только как сокращение полных фраз: информация, представленная посредством непрерывных сигналов и информация, представленная посредством дискретных сигналов – именно в таком контексте эти понятия будут использоваться в дальнейшем изложении. Поэтому когда заходит речь о видах информации, правильнее говорить о формах ее представления в сообщении или о видах сообщений.
Принципиальным и важнейшим различием непрерывных и дискретных сигналов является то, что дискретные сигналы можно обозначить, т.е. приписать каждому из конечного числа возможных значений сигнала знак, который будет отличать данный сигнал от другого.
Знак – это элемент некоторого конечного множества отличных друг от друга сущностей.
Природа знака может любой – жест, рисунок, буква, сигнал светофора, определенный звук и т.д. Природа знака определяется носителем сообщения и формой представления информации в сообщении.
Вся совокупность знаков, используемых для представления дискретной информации, называется набором знаков. Таким образом, набор есть дискретное множество знаков.
Набор знаков, в котором установлен порядок их следования, называется алфавитом.
Следовательно, алфавит – это
упорядоченная совокупность знаков.
Порядок следования знаков в алфавите
называется лексикографическим.
Благодаря этому порядку между знаками
устанавливаются отношения больше–меньше:
для двух знаков
![]() <
<
![]() ,
если порядковый номер у
в
алфавите меньше, чем у
.
,
если порядковый номер у
в
алфавите меньше, чем у
.
Примером алфавита может служить совокупность арабских цифр 0,1…9 – с его помощью можно записать любое целое число в системах счисления от двоичной до десятичной. Если в этот алфавит добавить знаки "+" и "–", то им можно будет записать любое целое число, как положительное, так и отрицательное. Наконец, если добавить знак разделителя разрядов ("." или ","), то такой алфавит позволит записать любое вещественное число.
Поскольку при передаче сообщения параметр сигнала должен меняться, очевидно, что минимальное количество различных его значений равно двум и, следовательно, алфавит содержит минимум два знака – такой алфавит называется двоичным. Верхней границы числа знаков в алфавите не существует; примером могут служить иероглифы, каждый из которых обозначает целое понятие, и общее их количество исчисляется десятками тысяч.
Знаки, используемые для обозначения фонем человеческого языка, называются буквами, а их совокупность – алфавитом языка.
Сами по себе знак или буква не несут никакого смыслового содержания. Однако такое содержание им может быть приписано – в этом случае знак будет называться символом. Например, силу в физике принято обозначать буквой F – следовательно, F является символом физической величины сила в формулах. Другим примером символов могут служить пиктограммы, обозначающие в компьютерных программах объекты или действия.
Таким образом, понятия "знак", "буква" и "символ" нельзя считать тождественными, хотя весьма часто различия между ними не проводят, поэтому в информатике существуют понятия "символьная переменная", "кодировка символов алфавита", "символьная информация" – во всех приведенных примерах вместо термина "символьный" корректнее было бы использовать "знаковый" или "буквенный".
Представляется важным еще раз подчеркнуть, что понятия знака и алфавита можно отнести только к дискретным сообщениям.
Преобразование сообщений.
Вернемся к обсуждению информационных процессов, связанных с преобразованием одних сигналов в другие. Ясно, что технически это осуществимо. Ранее сигналы и их последовательности – сообщения – были названы нами «материальными оболочками для информации», и, естественно, встает вопрос: при изменении «оболочки» что происходит с его содержимым, т.е. с информацией? Попробуем найти ответ на него.
Поскольку имеются два типа сообщений, между ними, очевидно, возможны четыре варианта преобразований:
 Рис.1.
Варианты преобразований
Рис.1.
Варианты преобразований
Осуществимы и применяются на практике все четыре вида преобразований. Рассмотрим примеры устройств и ситуаций, связанных с такими преобразованиями, и одновременно попробуем отследить, что при этом происходит с информацией.
Примерами устройств, в которых
осуществляется преобразование типа
N1![]() N2,
являются микрофон (звук преобразуется
в электрические сигналы); магнитофон и
видеомагнитофон (чередование областей
намагничивания ленты превращается в
электрические сигналы, которые затем
преобразуются в звук и изображение);
телекамера (изображение и звук превращаются
в электрические сигналы); радио- и
телевизионный приемник (радиоволны
преобразуются в электрические сигналы,
а затем в звук и изображение); аналоговая
вычислительная машина (одни электрические
сигналы преобразуются в другие).
Особенностью данного варианта
преобразования является то, что оно
всегда сопровождается частичной потерей
информации. Потери связаны с помехами
(шумами), которые порождает само
информационное техническое устройство
и которые воздействуют извне. Эти помехи
примешиваются к основному сигналу и
искажают его. Поскольку параметр сигнала
может иметь любые значения (из некоторого
интервала), то невозможно отделить
ситуации: был ли сигнал искажен или он
изначально имел такую величину. В ряде
устройств искажение происходит в силу
особенностей преобразования в них
сообщения, например в черно-белом
телевидении теряется цвет изображения;
телефон пропускает звук в более узком
частотном интервале, чем интервал
человеческого голоса; кино- и
видеоизображение оказываются плоскими,
они утратили объемность.
N2,
являются микрофон (звук преобразуется
в электрические сигналы); магнитофон и
видеомагнитофон (чередование областей
намагничивания ленты превращается в
электрические сигналы, которые затем
преобразуются в звук и изображение);
телекамера (изображение и звук превращаются
в электрические сигналы); радио- и
телевизионный приемник (радиоволны
преобразуются в электрические сигналы,
а затем в звук и изображение); аналоговая
вычислительная машина (одни электрические
сигналы преобразуются в другие).
Особенностью данного варианта
преобразования является то, что оно
всегда сопровождается частичной потерей
информации. Потери связаны с помехами
(шумами), которые порождает само
информационное техническое устройство
и которые воздействуют извне. Эти помехи
примешиваются к основному сигналу и
искажают его. Поскольку параметр сигнала
может иметь любые значения (из некоторого
интервала), то невозможно отделить
ситуации: был ли сигнал искажен или он
изначально имел такую величину. В ряде
устройств искажение происходит в силу
особенностей преобразования в них
сообщения, например в черно-белом
телевидении теряется цвет изображения;
телефон пропускает звук в более узком
частотном интервале, чем интервал
человеческого голоса; кино- и
видеоизображение оказываются плоскими,
они утратили объемность.
Теперь обсудим общий подход к преобразованию типа N D. С математической точки зрения перевод сигнала из аналоговой формы в дискретную означает замену описывающей его непрерывной функции времени Z(t) на некотором отрезке [t1, t2] конечным множеством (массивом) {Zi, ti} (i изменяется от 0 до n, где n – количество точек разбиения временного интервала). Подобное преобразование называется дискретизацией непрерывного сигнала и осуществляется посредством двух операций: развертки по времени и квантования по величине сигнала.
Развертка по времени состоит
в том, что наблюдение за значением
величины Z производится не непрерывно,
а лишь в определенные моменты времени
с интервалом
![]() :
:
![]()
Квантование по величине – это отображение вещественных значений параметра сигнала в конечное множество чисел, кратных некоторой постоянной величине – шагу квантования ( Z).
Совместное выполнение обоих операций эквивалентно нанесению масштабной сетки на график Z(t), как показано на рисунке 2. Далее, в качестве пар значений {Zi, ti} выбираются узлы сетки, расположенные наиболее близко к Z(ti). Полученное таким образом множество узлов оказывается дискретным представлением исходной непрерывной функции. Таким образом, любое сообщение, связанное с ходом Z(t), может быть преобразовано в дискретное, т.е. представлено посредством некоторого алфавита.
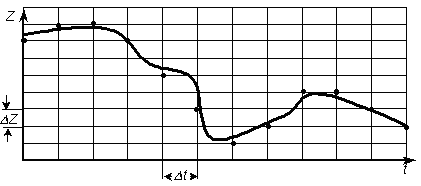 Рис.2.
Дискретизация аналогового сигнала за
счет операций развертки по времени и
квантования по величине
Рис.2.
Дискретизация аналогового сигнала за
счет операций развертки по времени и
квантования по величине
При такой замене довольно очевидно, что чем меньше n (больше t), тем меньше число узлов, но и точность замены Z(t) значениями Zi будет меньшей. Другими словами, при дискретизации может происходить потеря части информации, связанной с особенностями функции Z(t). На первый взгляд кажется, что увеличением количества точек n можно улучшить соответствие между получаемым массивом и исходной функцией, однако полностью избежать потерь информации все равно не удастся, поскольку n – величина конечная. Ответом на эти сомнения служит так называемая теорема отсчетов, доказанная в 1933 г. В.А.Котельниковым (по этой причине ее иногда называют его именем), значение которой для решения проблем передачи информации было осознано лишь в 1948 г. после работ К.Шеннона. Теорема, которую мы примем без доказательства, но результаты будем в дальнейшем использовать, гласит:
Непрерывный сигнал можно полностью отобразить и точно воссоздать по последовательности измерений или отсчетов величины этого сигнала через одинаковые интервалы времени, меньшие или равные половине периода максимальной частоты, имеющейся в сигнале.
Уточнения теоремы Шеннона.
Перечислим ограничения, не учитываемые теоремой Шеннона.
Теорема касается только тех линий связи, в которых для передачи используются колебательные или волновые процессы. Это не должно восприниматься как заметное ограничение, поскольку действие большинства практических устройств связи основано именно на этих процессах.
Любое подобное устройство использует не весь спектр частот колебаний, а лишь какую-то его часть; например, в телефонных линиях используются колебания с частотами от 300 Гц до 3400 Гц. Согласно теореме отсчетов определяющим является значение верхней границы частоты – обозначим его
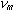 .
.
Смысл теоремы в том, что дискретизация не приведет к потере информации и по дискретным сигналам можно будет полностью восстановить исходный аналоговый сигнал, если развертка по времени выполнена в соответствии со следующим соотношением:
![]() (1)
(1)
Можно перефразировать теорему отсчетов:
Развертка по времени может быть осуществлена без потери информации, связанной с особенностями непрерывного (аналогового) сигнала, если шаг развертки не будет превышать t, определяемый в соответствии с (1).
Например, для точной передачи
речевого сигнала с частотой до
=
4000 Гц при дискретной записи должно
производиться не менее 8000 отсчетов в
секунду; в телевизионном сигнале
![]() 4
МГц, следовательно, для его точной
передачи потребуется около 8000000 отсчетов
в секунду.
4
МГц, следовательно, для его точной
передачи потребуется около 8000000 отсчетов
в секунду.
Однако, помимо временной развертки, дискретизация имеет и другую составляющую – квантование. Какими соображениями определяется шаг квантования Z? Любой получатель сообщения – человек или устройство – всегда имеют конечную предельную точность распознавания величины сигнала. Например, человеческий глаз в состоянии различить около 16 миллионов цветовых оттенков; это означает, что при квантовании цвета нет смысла делать большее число градаций. При передаче речи достаточной оказывается гораздо меньшая точность – около 1%; следовательно, для амплитуды звуковых колебаний Z 0,01·Zmax, а алфавит для обозначения всех градаций громкости должен содержать 100 знаков. Мы приходим к заключению, что шаг квантования определяется чувствительностью приемного устройства.
Указанные соображения по выбору шага развертки по времени и квантования по величине сигнала лежат в основе оцифровки звука и изображения. Примерами устройств, в которых происходят такие преобразования, являются сканер, модем, устройства для цифровой записи звука и изображения, лазерный проигрыватель, графопостроитель. Термины "цифровая запись", "цифровой сигнал" следует понимать как дискретное представление с применением двоичного цифрового алфавита.
Таким образом, преобразование сигналов типа N D, как и обратное D N, может осуществляться без потери содержащейся в них информации.
Преобразование типа D1 D2 состоит в переходе при представлении сигналов от одного алфавита к другому – такая операция носит название перекодировка и может осуществляться без потерь. Примерами ситуаций, в которых осуществляются подобные преобразования, могут быть: запись-считывание с компьютерных носителей информации; шифровка и дешифровка текста; вычисления на калькуляторе.
Таким образом, за исключением N1 N2 в остальных случаях оказывается возможным преобразование сообщений без потерь содержащейся в них информации. При этом на первый взгляд непрерывные и дискретные сообщения оказываются равноправными. Однако на самом деле это не так. Сохранение информации в преобразованиях N D и D N обеспечивается именно благодаря участию в них дискретного представления. Другими словами, преобразование сообщений без потерь информации возможно только в том случае, если хотя бы одно из них является дискретным. В этом проявляется несимметричность видов сообщений и преимущество дискретной формы. К другими ее достоинствам следует отнести:
высокая помехоустойчивость;
простота и, как следствие, надежность и относительная дешевизна устройств по обработке информации;
точность обработки информации, которая определяется количеством обрабатывающих элементов и не зависит от точности их изготовления;
универсальность устройств.
Последнее качество – универсальность – оказывается следствием того обстоятельства, что любые дискретные сообщения, составленные в различных алфавитах, посредством обратимого кодирования можно привести к единому алфавиту. Это позволяет выделить некоторый алфавит в качестве базового (из соображений удобства, простоты, компактности или каких-либо иных) и представлять в нем любую дискретную информацию. Тогда устройство, работающее с информацией в базовом алфавите, оказывается универсальным в том отношении, что оно может быть использовано для переработки любой иной исходной дискретной информации. Таким базовым алфавитом, как мы увидим в дальнейшем, является двоичный алфавит, а использующим его универсальным устройством – компьютер.
Несимметричность непрерывной и дискретной информации имеет более глубокую основу, чем просто особенности представляющих сигналов. Дело в том, что информация, порождаемая и существующая в природе, связана с материальным миром – это размеры, форма, цвет и другие физические, химические и прочие характеристики и свойства объектов. Данная информация передается, как было сказано, посредством физических и иных взаимодействий и процессов. Бессмысленно ставить вопросы: для чего существует такая информация и кому она полезна? Эту природную информацию можно считать хаотической и неупорядоченной, поскольку никем и ничем не регулируется ее появление, существование, использование. Чаще всего она непрерывна по форме представления. Напротив, дискретная информация – это информация, прошедшая обработку – отбор, упорядочение, преобразование; она предназначена для дальнейшего применения человеком или техническим устройством. Дискретная информация даже может не иметь прямого отношения к природе и материальным объектам, например представления и законы математики. Другими словами, дискретная – это уже частично осмысленная информация, т.е. имеющая для кого-то смысл и значение и, как следствие, более высокий (с точки зрения пользы) статус, нежели непрерывная, хаотичная. Однако в информатике, как было сказано, этот смысл не отслеживается, хотя и подразумевается. Эту же мысль можно выразить иначе: информатика имеет дело не с любой информацией и не с информацией вообще, а лишь с той, которая кому-то необходима; при этом не ставятся и не обсуждаются вопросы "Зачем она нужна?" и "Почему именно эта?" – это определяет потребитель информации.
Отсюда становится понятной приоритетность дискретной формы представления информации по отношению к непрерывной в решении глобальной задачи автоматизации обработки информации. Приведенные в данном параграфе соображения позволяют нам в дальнейшем исследовать только дискретную информацию, а для ее представления (фиксации) использовать некоторый алфавит. При этом нет необходимости рассматривать физические особенности передачи и представления, т.е. характер процессов и виды сигналов, – полученные результаты будут справедливы для любой дискретной информации независимо от реализации сообщения, с которым она связана. С этого момента и начинается наука информатика.
Понятие энтропии.
Случайные события могут быть описаны с использованием понятия "вероятность". Соотношения теории вероятностей позволяют найти (вычислить) вероятности как одиночных случайных событий, так и сложных опытов, объединяющих несколько независимых или связанных между собой событий. Однако описать случайные события можно не только в терминах вероятностей.
То, что событие случайно, означает отсутствие полной уверенности в его наступлении, что, в свою очередь, создает неопределенность в исходах опытов, связанных с данным событием. Безусловно, степень неопределенности различна для разных ситуаций. Например, если опыт состоит в определении возраста случайно выбранного студента 1-го курса дневного отделения вуза, то с большой долей уверенности можно утверждать, что он окажется менее 30 лет; хотя по положению на дневном отделении могут обучаться лица в возрасте до 35 лет, чаще всего очно учатся выпускники школ ближайших нескольких выпусков. Гораздо меньшую определенность имеет аналогичный опыт, если проверяется, будет ли возраст произвольно выбранного студента меньше 18 лет. Для практики важно иметь возможность произвести численную оценку неопределенности разных опытов. Попробуем ввести такую количественную меру неопределенности.
Начнем с простой ситуации, когда опыт имеет n равновероятных исходов. Очевидно, что неопределенность каждого из них зависит от n, т.е. мера неопределенности является функцией числа исходов (f(n)).
Можно указать некоторые свойства этой функции:
f(1) = 0, поскольку при n = 1 исход опыта не является случайным и, следовательно, неопределенность отсутствует;
f(n) возрастает с ростом n, поскольку чем больше число возможных исходов, тем более затруднительным становится предсказание результата опыта.
Для определения явного вида
функции f(n) рассмотрим два независимых
опыта
![]() и
и
![]() (для
обозначения опытов со случайными
исходами будем использовать греческие
буквы (
,
и
т.д.), а для обозначения отдельных исходов
опытов (событий) – латинские заглавные
(A, B и т.д.)) с количествами равновероятных
исходов, соответственно
(для
обозначения опытов со случайными
исходами будем использовать греческие
буквы (
,
и
т.д.), а для обозначения отдельных исходов
опытов (событий) – латинские заглавные
(A, B и т.д.)) с количествами равновероятных
исходов, соответственно
![]() ,
,
![]() .
Пусть имеет место сложный опыт, который
состоит в одновременном выполнении
опытов
и
;
число возможных его исходов равно
·
,
причем, все они равновероятны. Очевидно,
неопределенность исхода такого сложного
опыта
.
Пусть имеет место сложный опыт, который
состоит в одновременном выполнении
опытов
и
;
число возможных его исходов равно
·
,
причем, все они равновероятны. Очевидно,
неопределенность исхода такого сложного
опыта
![]() будет
больше неопределенности опыта
,
поскольку к ней добавляется неопределенность
;
мера неопределенности сложного опыта
равна f(
·
).
С другой стороны, меры неопределенности
отдельных
и
составляют,
соответственно, f(
)
и f(
).
В первом случае (сложный опыт) проявляется
общая (суммарная) неопределенность
совместных событий, во втором –
неопределенность каждого из событий в
отдельности. Однако из независимости
и
следует,
что в сложном опыте они никак не могут
повлиять друг на друга и, в частности,
не
может оказать воздействия на
неопределенность
,
и наоборот. Следовательно, мера суммарной
неопределенности должна быть равна
сумме мер неопределенности каждого из
опытов, т.е. мера неопределенности
аддитивна:
будет
больше неопределенности опыта
,
поскольку к ней добавляется неопределенность
;
мера неопределенности сложного опыта
равна f(
·
).
С другой стороны, меры неопределенности
отдельных
и
составляют,
соответственно, f(
)
и f(
).
В первом случае (сложный опыт) проявляется
общая (суммарная) неопределенность
совместных событий, во втором –
неопределенность каждого из событий в
отдельности. Однако из независимости
и
следует,
что в сложном опыте они никак не могут
повлиять друг на друга и, в частности,
не
может оказать воздействия на
неопределенность
,
и наоборот. Следовательно, мера суммарной
неопределенности должна быть равна
сумме мер неопределенности каждого из
опытов, т.е. мера неопределенности
аддитивна:
![]() (1.1)
(1.1)
Теперь задумаемся о том, каким может быть явный вид функции f(n), чтобы он удовлетворял свойствам (1) и (2) и соотношению (1.1)? Легко увидеть, что такому набору свойств удовлетворяет функция log(n), причем можно доказать, что она единственная из всех существующих классов функций. Таким образом: за меру неопределенности опыта с n равновероятными исходами можно принять число log(n).
Следует заметить, что выбор основания логарифма в данном случае значения не имеет, поскольку в силу известной формулы преобразования логарифма от одного основания к другому:
![]()
переход к другому основанию состоит во введении одинакового для обеих частей выражения (1.1) постоянного множителя logba, что равносильно изменению масштаба (т.е. размера единицы) измерения неопределенности. Поскольку это так, мы имеет возможность выбрать удобное для нас (из каких-то дополнительных соображений) основание логарифма. Таким удобным основанием оказывается 2, поскольку в этом случае за единицу измерения принимается неопределенность, содержащаяся в опыте, имеющем лишь два равновероятных исхода, которые можно обозначить, например, ИСТИНА (True) и ЛОЖЬ (False) и использовать для анализа таких событий аппарат математической логики.
Единица измерения неопределенности при двух возможных равновероятных исходах опыта называется бит (Название бит происходит от английского binary digit, что в дословном переводе означает "двоичный разряд" или "двоичная единица".)
Таким образом, нами установлен явный вид функции, описывающей меру неопределенности опыта, имеющего n равновероятных исходов: f(n) = log2n (1.2).
Эта величина получила название энтропии. В дальнейшем будем обозначать ее H.
Вновь рассмотрим опыт с n равновероятными исходами. Поскольку каждый исход случаен, он вносит свой вклад в неопределенность всего опыта, но так как все n исходов равнозначны, разумно допустить, что и их неопределенности одинаковы. Из свойства аддитивности неопределенности, а также того, что согласно (1.2) общая неопределенность равна log2n, следует, что неопределенность, вносимая одним исходом составляет
![]()
где
– вероятность любого из отдельных исходов.
Таким образом, неопределенность, вносимая каждым из равновероятных исходов, равна: H = - p log2p (1.3).
Теперь попробуем обобщить формулу (1.3) на ситуацию, когда исходы опытов неравновероятны, например, p(A1) и p(A2). Тогда:
H1 = - p(A1) log2 p(A1) и H2 = - p(A2) log2 p(A2) H = H1 + H2 = -p(A1) log2 p(A1) - p(A2) log2 p(A2)
Обобщая это выражение на ситуацию, когда опыт имеет n неравновероятных исходов A1, A2,..., An, получим:
![]() (1.4)
(1.4)
Введенная таким образом величина, как уже было сказано, называется энтропией опыта . Используя формулу для среднего значения дискретных случайных величин, можно записать:
H(
)
= - log2 p (![]() ),
),
где – обозначает исходы, возможные в опыте .
Энтропия является мерой неопределенности опыта, в котором проявляются случайные события, и равна средней неопределенности всех возможных его исходов.
Для практики формула (1.4) важна тем, что позволяет сравнить неопределенности различных опытов со случайными исходами.
![]()
Пример 1. Имеются два ящика, в каждом из которых по 12 шаров. В первом – 3 белых, 3 черных и 6 красных; во втором – каждого цвета по 4. Опыты состоят в вытаскивании по одному шару из каждого ящика. Что можно сказать относительно неопределенностей исходов этих опытов?
Согласно (1.4) находим энтропии обоих опытов:
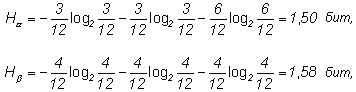
![]() ,
т.е. неопределенность результата в опыте
выше
и, следовательно, предсказать его можно
с меньшей долей уверенности, чем результат
.
,
т.е. неопределенность результата в опыте
выше
и, следовательно, предсказать его можно
с меньшей долей уверенности, чем результат
.
Свойства энтропии.
Как следует из (1.4), H = 0 только в двух случаях:
какая-либо из p(Aj) = 1; однако, при этом следует, что все остальные p(Ai) = 0 (i
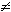 j),
т.е. реализуется ситуация, когда один
из исходов является достоверным (и
общий итог опыта перестает быть
случайным);
j),
т.е. реализуется ситуация, когда один
из исходов является достоверным (и
общий итог опыта перестает быть
случайным);
все p(Ai) = 0, т.е. никакие из рассматриваемых исходов опыта невозможны, поскольку нетрудно показать, что:
![]()
Во всех остальных случаях, очевидно, что H > 0.
Очевидным следствием (1.1) будет утверждение, что для двух независимых опытов и
![]() (1.5)
(1.5)
Энтропия сложного опыта, состоящего из нескольких независимых, равна сумме энтропий отдельных опытов.
В справедливости (1.5) можно убедиться непосредственно.
Пусть опыт
имеет
n исходов A1, A2,
..., An, которые реализуются
с вероятностями p(A1),
p(A2), ..., p(An),
а событие
–
m исходов B1, B2,
..., Bm с вероятностями p(B1),
p(B2), ..., p(Bm).
Сложный опыт
![]() имеет
n ·m исходов типа AiBj
(i=1...n, j=1...m). Следовательно:
имеет
n ·m исходов типа AiBj
(i=1...n, j=1...m). Следовательно:
![]() (1.6)
(1.6)
Поскольку и – независимы, то независимыми окажутся события в любой паре Ai Bj. Тогда:

В слагаемых произведено изменение порядка суммирования в соответствии со значениями индексов. Далее, по условию нормировки:
![]()
а из (1.4)
![]()
Окончательно имеем:
что и требовалось доказать.
Пусть имеется два опыта с одинаковым числом исходов n, но в одном случае они равновероятны, а в другом – нет. Каково соотношение энтропий опытов? Примем без доказательства следующее утверждение:
![]() (1.7)
(1.7)
При прочих равных условиях наибольшую энтропию имеет опыт с равновероятными исходами.
Другими словами, энтропия максимальна в опытах, где все исходы равновероятны. Здесь усматривается аналогия (имеющая глубинную первооснову!) с понятием энтропии, используемой в физике. Впервые понятие энтропии было введено в 1865 г. немецким физиком Рудольфом Клаузиусом как функции состояния термодинамической системы, определяющей направленность самопроизвольных процессов в системе. Клаузиус сформулировал II начало термодинамики. В частности, он показал, что энтропия достигает максимума в состоянии равновесия системы. Позднее (в 1872 г.) Людвиг Больцман, развивая статистическую теорию, связал энтропию системы с вероятностью ее состояния, дал статистическое (вероятностное) толкование II-му началу термодинамики и, в частности, показал, что вероятность максимальна у полностью разупорядоченной (равновесной) системы, причем, энтропия и термодинамическая вероятность оказались связанными логарифмической зависимостью. Другими словами, в физике энтропия оказывается мерой беспорядка в системе. При этом беспорядок понимается как отсутствие знания о характеристиках объекта (например, координат и скорости молекулы); с ростом энтропии уменьшается порядок в системе, т.е. наши знания о ней. Сходство понятий и соотношений между ними в теории информации и статистической термодинамике, как оказалось позднее, совершенно не случайно.
Кстати, результат, полученный в рассмотренном на предыдущем шаге примере, иллюстрирует справедливость формулы (1.7).
Понятие условной энтропии.
Найдем энтропию сложного опыта в том случае, если опыты не являются независимыми, т.е. если на исход оказывает влияние результат опыта . Например, если в ящике всего два разноцветных шара и состоит в извлечении первого, а – второго из них, то полностью снимает неопределенность сложного опыта , т.е. оказывается H( ) = H( ), а не сумме энтропии, как следует из (1.5).
Связь между
на
могут
оказывать влияние на исходы из
![]() ,
т.е. некоторые пары событий Ai
Bj не являются независимыми.
Но тогда в (1.6)
p (Ai
Bj) следует заменять не
произведением вероятностей, а, согласно:
,
т.е. некоторые пары событий Ai
Bj не являются независимыми.
Но тогда в (1.6)
p (Ai
Bj) следует заменять не
произведением вероятностей, а, согласно:
![]()
– вероятность наступления исхода Bj при условии, что в первом опыте имел место исход Ai. Тогда:
![]()
При подстановке в (1.6) получаем:

В первом слагаемом индекс j имеется только у B; изменив порядок суммирования, получим члены вида:
![]()
Однако,
![]()
поскольку
![]()
образует достоверное событие (какой-либо из исходов опыта при условии, что в опыте реализовался исход Ai – будем называть ее условной энтропией. Если ввести данное понятие и использовать его обозначение, то второе слагаемое будет иметь вид:
![]() (1.9)
(1.9)
где
![]() есть
средняя условная энтропия опыта
при
условии выполнении опыта
.
Окончательно получаем для энтропии
сложного опыта:
есть
средняя условная энтропия опыта
при
условии выполнении опыта
.
Окончательно получаем для энтропии
сложного опыта:
![]() (1.10)
(1.10)
Полученное выражение представляет собой общее правило нахождения энтропии сложного опыта. Совершенно очевидно, что выражение (1.5) является частным случаем (1.10) при условии независимости опытов и .
Относительно условной энтропии можно высказать следующие утверждения:
Условная энтропия является величиной неотрицательной. = 0 только в том случае, если любой исход полностью определяет исход (как в примере с двумя шарами), т.е.
![]()
В этом случае H ( ) = H ( ).
Если опыты и независимы, то
 ,
причем это оказывается наибольшим
значением условной энтропии. Другими
словами, опыт
не
может повысить неопределенность опыта
;
он может либо не оказать никакого
влияния (если опыты независимы), либо
понизить энтропию
.
,
причем это оказывается наибольшим
значением условной энтропии. Другими
словами, опыт
не
может повысить неопределенность опыта
;
он может либо не оказать никакого
влияния (если опыты независимы), либо
понизить энтропию
.
Приведенные утверждения можно объединить одним неравенством:
![]() (1.11)
т.е. условная энтропия не превосходит
безусловную.
(1.11)
т.е. условная энтропия не превосходит
безусловную.
Из соотношений (1.10) и (1.11) следует, что
![]() (1.12)
(1.12)
причем равенство реализуется только в том случае, если опыты и независимы.
Пример 1. В ящике имеются 2 белых шара и 4 черных. Из ящика извлекают последовательно два шара без возврата. Найти энтропию, связанную с первым и вторым извлечениями, а также энтропию обоих извлечений.
Будем считать опытом извлечение первого шара. Он имеет два исхода: A1 – вынут белый шар; его вероятность p(A1) = 2/6 = 1/3; исход A2 – вынут черный шар; его вероятность p(A2)=1 – p(A1) = 2/3. Эти данные позволяют с помощью (1.4) сразу найти H( ):
H( )= – p(A1)log2 p(A1) – p(A2)log2 p(A2) = –1/3 log21/3 – 2/3 log22/3 = 0,918 бит
Опыт – извлечение второго шара также имеет два исхода: B1 – вынут белый шар; B2 – вынут черный шар, однако их вероятности будут зависеть от того, каким был исход опыта . В частности:
![]()
Следовательно, энтропия, связанная со вторым опытом, является условной и, согласно (1.8) и (1.9), равна:
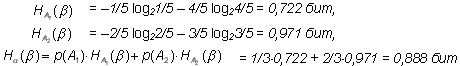
Наконец, из (1.10): H( ) = 0,918 + 0,888 = 1,806 бит.
Пример 2. Имеется три тела с одинаковыми внешними размерами, но с разными массами x1, x2 и x3. Необходимо определить энтропию, связанную с нахождением наиболее тяжелого из них, если сравнивать веса тел можно только попарно.
Последовательность действий достаточно очевидна: сравниваем вес двух любых тел, определяем из них более тяжелое, затем с ним сравниваем вес третьего тела и выбираем наибольший из них. Поскольку внешне тела неразличимы, выбор номеров тел при взвешивании будет случаен, однако общий результат от этого выбора не зависит. Пусть опыт состоит в сравнении веса двух тел, например, 1-го и 2-го. Этот опыт, очевидно, может иметь два исхода: A1 – x1 > x2; его вероятность p(A1) = 1/2; исход A2 – x1 < x2; также его вероятность p(A2)=1/2.
H( ) = –1/2 log21/2 – 1/2 log21/2 = 1 бит
Опыт – сравнение весов тела, выбранного в опыте , и 3-го – имеет четыре исхода: B1 – x1> x3, B2 – x1< x3, B3 – x2> x3, B4 – x2< x3; вероятности исходов зависят от реализовавшегося исхода – для удобства представим их в виде таблицы:
B1 |
B2 |
B3 |
B4 |
|
1/2 |
1/2 |
0 |
0 |
A1 |
0 |
0 |
1/2 |
1/2 |
A2 |
Вновь, воспользовавшись формулами (1.8) и (1.9), находим:
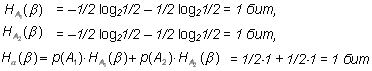
Следовательно, энтропия сложного опыта, т.е. всей процедуры испытаний:
![]()
Связь между энтропией и информацией.
Поучительность только что рассмотренного примера в том, что из него отчетливо видно как предшествующий опыт ( ) может уменьшить количество исходов и, следовательно, неопределенность последующего опыта ( ). Разность H( ) и , очевидно, показывает, какие новые сведения относительно мы получаем, произведя опыт . Эта величина называется информацией относительно опыта , содержащейся в опыте .
![]() (1.13)
(1.13)
Данное выражение открывает возможность численного измерения количества информации, поскольку оценивать энтропию мы уже умеем. Из него легко получить ряд следствий.
Следствие 1. Поскольку единицей измерения энтропии является бит, то в этих же единицах может быть измерено количество информации.
Следствие 2.
Пусть опыт
=
,
т.е. просто произведен опыт
.
Поскольку он несет полную информацию
о себе самом, неопределенность его
исхода полностью снимается, т.е.
![]() =0.
Тогда I(
,
)
= H (
),
т.е. можно считать, что энтропия равна
информации относительно опыта, которая
содержится в нем самом.
=0.
Тогда I(
,
)
= H (
),
т.е. можно считать, что энтропия равна
информации относительно опыта, которая
содержится в нем самом.
Можно построить уточнение: энтропия опыта равна той информации, которую мы получаем в результате его осуществления.
Отметим ряд свойств информации.
I( , )
 0,
причем I(
,
)
= 0 тогда и только тогда, когда опыты
и
независимы.
Это свойство непосредственно вытекает
из (1.10)
и (1.13).
0,
причем I(
,
)
= 0 тогда и только тогда, когда опыты
и
независимы.
Это свойство непосредственно вытекает
из (1.10)
и (1.13).
I( , ) = I( , ), т.е. информация симметрична относительно последовательности опытов.
Следствие 2 и представление энтропии в виде (1.4) позволяют записать:
![]() (1.14)
(1.14)
т.е. информация опыта равна среднему значению количества информации, содержащейся в каком-либо одном его исходе.
Рассмотрим ряд примеров применения формулы (1.14).
Пример 1. Какое количество информации требуется, чтобы узнать исход броска монеты? В данном случае n=2 и события равновероятны, т.е. p1=p2=0,5. Согласно (1.14):
I = – 0,5•log20,5 – 0,5•log20,5 = 1 бит
Пример 2. Игра "Угадай-ка – 4". Некто задумал целое число в интервале от 0 до 3. Наш опыт состоит в угадывании этого числа. На наши вопросы Некто может отвечать лишь "Да" или "Нет". Какое количество информации мы должны получить, чтобы узнать задуманное число, т.е. полностью снять начальную неопределенность? Как правильно построить процесс угадывания?
Исходами в данном случае являются: A1 – "задуман 0", A2 – "задумана 1", A3 – "задумана 2", A4 – "задумана 3". Конечно, предполагается, что вероятности быть задуманными у всех чисел одинаковы. Поскольку n = 4, следовательно, p(Ai)=1/4, log2 p(Ai)= –2 и I = 2 бит. Таким образом, для полного снятия неопределенности опыта (угадывания задуманного числа) нам необходимо 2 бита информации.
Теперь выясним, какие вопросы необходимо задать, чтобы процесс угадывания был оптимальным, т.е. содержал минимальное их число. Здесь удобно воспользоваться так называемым выборочным каскадом:

Таким образом, для решения задачи оказалось достаточно 2-х вопросов независимо от того, какое число было задумано. Совпадение между количеством информации и числом вопросов с бинарными ответами неслучайно.
Количество информации численно равно числу вопросов с равновероятными бинарными вариантами ответов, которые необходимо задать, чтобы полностью снять неопределенность задачи.
В рассмотренном примере два полученных ответа в выборочном каскаде полностью сняли начальную неопределенность. Подобная процедура позволяет определить количество информации в любой задаче, интерпретация которой может быть сведена к парному выбору. Например, определение символа некоторого алфавита, использованного для представления сообщения. Приведенное утверждение перестает быть справедливым в том случае, если каждый из двух возможных ответов имеет разную вероятность – такая ситуация будет рассмотрена позднее.
Легко получить следствие формулы (1.14) для случая, когда все n исходов равновероятны (собственно, именно такие и рассматривались в примерах 1 и 2. В этом случае все
![]()
I = log2n (1.15)
Эта формула была выведена в 1928 г. американским инженером Р.Хартли и носит его имя. Она связывает количество равновероятных состояний (n) и количество информации в сообщении (I), что любое из этих состояний реализовалось. Ее смысл в том, что, если некоторое множество содержит n элементов и x принадлежит данному множеству, то для его выделения (однозначной идентификации) среди прочих требуется количество информации, равное log2n.
Частным случаем применения формулы (1.15) является ситуация, когда n=2k; подставляя это значение в (1.15), очевидно, получим:
I = k бит (1.16)
Именно эта ситуация реализовалась в примерах 1 и 2. Анализируя результаты решения, можно прийти к выводу, что k как раз равно количеству вопросов с бинарными равновероятными ответами, которые определяли количество информации в задачах.
Пример 3. Случайным образом вынимается карта из колоды в 32 карты. Какое количество информации требуется, чтобы угадать, что это за карта? Как построить угадывание?
Для данной ситуации n = 25, значит, k = 5 и, следовательно, I = 5 бит. Последовательность вопросов придумайте самостоятельно.
Пример 4. В некоторой местности имеются две близкорасположенные деревни: A и B. Известно, что жители A всегда говорят правду, а жители B – всегда лгут. Известно также, что жители обеих деревень любят ходить друг к другу в гости, поэтому в каждой из деревень можно встретить жителя соседней деревни. Путешественник, сбившись ночью с пути оказался в одной из двух деревень и, заговорив с первым встречным, захотел выяснить, в какой деревне он находится и откуда его собеседник. Какое минимальное количество вопросов с бинарными ответами требуется задать путешественнику?
Количество возможных комбинаций, очевидно, равно 4 (путешественник в A, собеседник из A; путешественник в A, собеседник из B; и т.д.), т.е. n = 22 и, следовательно значит, k = 2. Последовательность вопросов придумайте самостоятельно.
Попытаемся понять смысл полученных в данном разделе результатов. Необходимо выделить ряд моментов.
1. (1.14) является статистическим
определением понятия "информация",
поскольку в него входят вероятности
возможных исходов опыта. По сути, мы
даем операционное определение новой
величины, т.е. устанавливаем процедуру
(способ) измерения величины. Как отмечалось
ранее, в науке (научном знании) именно
такой метод введения новых терминов
считается предпочтительным, поскольку
то, что не может быть измерено, не может
быть проверено и, следовательно,
заслуживает меньшего доверия. Выражение
(1.13) интерпретировать следующим образом:
если начальная энтропия опыта H1,
а в результате сообщения информации I
энтропия становится равной H2
(очевидно, H1![]() H2),
то
H2),
то
I = H1 – H2,
т.е. информация равна убыли энтропии. В частном случае, если изначально равновероятных исходов было n1, а в результате передачи информации I неопределенность уменьшилась, и число исходов стало n2 (очевидно, n2 n1), то из (1.15) легко получить:
![]()
Таким образом, можно дать следующее определение: Информация – это содержание сообщения, понижающего неопределенность некоторого опыта с неоднозначным исходом; убыль связанной с ним энтропии является количественной мерой информации. В случае равновероятных исходов информация равна логарифму отношения числа возможных исходов до и после (получения сообщения).
2. Как уже было сказано, в статистической механике энтропия характеризует неопределенность, связанную с недостатком информации о состоянии системы. Наибольшей оказывается энтропия у равновесной полностью беспорядочной системы – о ее состоянии наша осведомленность минимальна. Упорядочение системы (наведение какого-то порядка) связано с получением некоторой дополнительной информации и уменьшением энтропии. В теории информации энтропия также отражает неопределенность, однако, это неопределенность иного рода – она связана с незнанием результата опыта с набором случайных возможных исходов. Таким образом, хотя между энтропией в физике и информатике много общего, необходимо сознавать и различие этих понятий. Совершенно очевидно, что мы в дальнейшем понятие энтропии будем использовать в аспекте теории информации.
Следствием аддитивности энтропии независимых опытов оказывается аддитивность информации. Пусть с выбором одного из элементов (xA) множества A, содержащего nA элементов, связано IA = log2 nA информации, а с выбором xB из B с nB элементами информации связано IB = log2 nB и второй выбор никак не связан с первым, то при объединении множеств число возможных состояний (элементов) будет n = nA·nB и для выбора комбинации xAxB потребуется количество информации:
I = log2n = log2 nA· log2 nB = log2 nA + log2 nB = IA + IB
Вернемся к утверждению о том,
что количество информации может быть
измерено числом вопросов с двумя
равновероятными ответами. Означает ли
это, что I должна быть всегда величиной
целой? Из формулы Хартли (1.15), как было
показано, I = k бит (т.е. целому числу
бит) только в случае n = 2k.
А в остальных ситуациях? Например, при
игре "Угадай-ка – 7" (угадать число
от 0 до 6) нужно в выборочном каскаде
задать m
log2
7 = 2,807 < log2 8 = 3, т.е.
необходимо задать три вопроса, поскольку
количество вопросов – это целое число.
Однако представим, что мы одновременно
играем в шесть таких же игр. Тогда
необходимо отгадать одну из возможных
комбинаций, которых всего N = n1
· n2·…·n6 = 76
= 117649 < 217 = 131072.
Следовательно, для угадывания всей
шестизначной комбинации требуется I
= 17 бит информации, т.е. нужно задать
17 вопросов. В среднем на один элемент
(одну игру) приходится 17/3 = 2,833 вопроса,
что близко к значению log27.
Таким образом, величина I, определяемая
по числу ответов, показывает, сколько
в среднем необходимо сделать парных
выборов для установления результата
(полного снятия неопределенности), если
опыт повторить многократно (![]() ).
).
3. Необходимо понимать также, что не всегда с каждым из ответов на вопрос, имеющий только два варианта ответа (будем далее называть такие вопросы бинарными), связан ровно 1 бит информации.
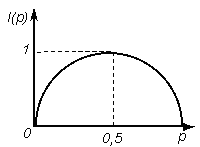
4. Рассмотрим опыт, реализующийся посредством двух случайных событий; поскольку их всего два, очевидно, они являются дополнительными друг другу. Если эти события равновероятны, p1=p2= 1/2, и I = 1 бит, как следует из формулы Хартли и (1.14). Однако, если их вероятности различны: p1 = p, и, согласно p2 = 1 – p, то из (1.14)
I(p) = – p·log2 p – (1 – p)· log2 (1 – p)
Легко показать, что при p![]() 0
и при p
1
функция I(p)
0.
Ситуация может быть проиллюстрирована
графиком, из которого, в частности,
видно, что кривая симметрична относительно
p = 0,5 и достигает максимума при этом
значении. Если теперь считать, что
событие 1 – это утвердительный ответ
на бинарный вопрос, а событие 2 –
отрицательный, то мы приходим к заключению:
0
и при p
1
функция I(p)
0.
Ситуация может быть проиллюстрирована
графиком, из которого, в частности,
видно, что кривая симметрична относительно
p = 0,5 и достигает максимума при этом
значении. Если теперь считать, что
событие 1 – это утвердительный ответ
на бинарный вопрос, а событие 2 –
отрицательный, то мы приходим к заключению:
Ответ на бинарный вопрос может содержать не более 1 бит информации; информация равна 1 бит только для равновероятных ответов; в остальных случаях она меньше 1 бита.
Пример 5. При угадывании результата броска игральной кости задается вопрос "Выпало 6?". Какое количество информации содержит ответ?
p = 1/6 , 1 – p = 5/6, следовательно, из (1.14)
I = – 1/6 · log2 1/6 – 5/6 · log2
5/6
![]() 0,65
бит < 1 бита.
0,65
бит < 1 бита.
Из этого примера видна также ошибочность утверждения, встречающегося в некоторых учебниках информатики, что 1 бит является минимальным количеством информации – никаких оснований для такого утверждения в теории информации нет.
5. Формула (1.14) приводит нас еще к одному выводу. Пусть некоторый опыт имеет два исхода A и B, причем pA = 0,99 , а pB = 0,01. В случае исхода A мы получим количество информации IA= –log20,99=0,0145 бит. В случае исхода B количество информации оказывается равным IB= –log20,01=6,644 бит. Другими словами, больше информации связано с теми исходами, которые менее вероятны. Действительно, то, что наступит именно A, мы почти наверняка знали и до опыта; поэтому реализация такого исхода очень мало добавляет к нашей осведомленности. Наоборот, исход B – весьма редкий; информации с ним связано больше (осуществилось трудно ожидаемое событие). Однако такое большое количество информации мы будем при повторах опыта получать редко, поскольку мала вероятность B. Среднее же количество информации равно I = 0,99·IA + 0,01·IB 0,081 бит.
Нами рассмотрен вероятностный подход к определению количества информации. Он не является единственным. Как будет показано далее, количество информации можно связать с числом знаков в дискретном сообщении – такой способ измерения называется объемным. Можно доказать, что при любом варианте кодирования информации Iвер Iоб.
Объективность информации. При использовании людьми одна и та же информация может иметь различную оценку с точки зрения значимости (важности, ценности). Определяющим в такой оценке оказывается содержание (смысл) сообщения для конкретного потребителя. Однако при решении практических задач технического характера содержание сообщения может не играть роли. Например, задача телеграфной (и любой другой) линии связи является точная и безошибочная передача сообщения без анализа того, насколько ценной для получателя оказывается связанная с ним информация. Техническое устройство не может оценить важности информации – его задача без потерь передать или сохранить информацию. Выше мы определили информацию как результат выбора. Такое определение не зависит от того, кто и каким образом осуществляет выбор, а связанная с ним количественная мера информации – одинаковой для любого потребителя. Следовательно, появляется возможность объективного измерения информации, при этом результат измерения – абсолютен. Это служит предпосылкой для решения технических задач. Нельзя предложить абсолютной и единой для всех меры ценности информации. С точки зрения формальной информации страница из учебника информатики или из романа "Война и мир" и страница, записанная бессмысленными значками, содержат одинаковое количество информации. Количественная сторона информации объективна, смысловая – нет. Однако, жертвуя смысловой (семантической) стороной информации, мы получаем объективные методы измерения ее количества, а также обретаем возможность описывать информационные процессы математическими уравнениями. Это является приближением и в то же время условием применимости законов теории информации к анализу и описанию информационных процессов.
Информация и знание. На бытовом уровне, в науках социальной направленности, например в педагогике "информация" отождествляется с "информированностью", т.е. человеческим знанием, которое, в свою очередь, связано с оценкой смысла информации. В теории информации же, напротив, информация является мерой нашего незнания чего-либо (но что в принципе может произойти); как только это происходит и мы узнаем результат, информация, связанная с данным событием, исчезает. Состоявшееся событие не несет информации, поскольку пропадает его неопределенность (энтропия становится равной нулю), и согласно (1.13) I = 0.
Последние два замечания представляются весьма важными, поскольку недопонимание указанных в них обстоятельств порождает попытки применения законов теории информации в тех сферах, где условия ее применимости не выполнены. Это, в свою очередь, порождает отрицательные результаты, которые служат причиной разочарования в самой теории. Однако любая теория, в том числе и теория информации, справедлива лишь в рамках своих исходных ограничений.
Информация и алфавит.
Рассматривая формы представления информации, мы отметили то обстоятельство, что, хотя естественной для органов чувств человека является аналоговая форма, универсальной все же следует считать дискретную форму представления информации с помощью некоторого набора знаков. В частности, именно таким образом представленная информация обрабатывается компьютером, передается по компьютерным и некоторым иным линиям связи. Сообщение есть последовательность знаков алфавита. При их передаче возникает проблема распознавания знака: каким образом прочитать сообщение, т.е. по полученным сигналам установить исходную последовательность знаков первичного алфавита. В устной речи это достигается использованием различных фонем (основных звуков разного звучания), по которым мы и отличает знаки речи. В письменности это достигается различным начертанием букв и дальнейшим нашим анализом написанного. Как данная задача может решаться техническим устройством, мы рассмотрим позднее. Сейчас для нас важно, что можно реализовать некоторую процедуру (механизм), посредством которой выделить из сообщения тот или иной знак. Но появление конкретного знака (буквы) в конкретном месте сообщения – событие случайное. Следовательно, узнавание (отождествление) знака требует получения некоторой порции информации. Можно связать эту информацию с самим знаком и считать, что знак несет в себе (содержит) некоторое количество информации. Попробуем оценить это количество.
Начнем с самого грубого приближения (будем называть его нулевым, что отражается индексом у получаемых величин) – предположим, что появление всех знаков (букв) алфавита в сообщении равновероятно. Тогда для английского алфавита ne=27 (с учетом пробела как самостоятельного знака); для русского алфавита nr=34. Из формулы Хартли находим:
I0(e)=log227 = 4,755 бит.
I0(r)=log234 = 5,087 бит.
Получается, что в нулевом приближении со знаком русского алфавита в среднем связано больше информации, чем со знаком английского. Например, в русской букве "а" информации больше, чем в "a" английской! Это, безусловно, не означает, что английский язык – язык Шекспира и Диккенса – беднее, чем язык Пушкина и Достоевского. Лингвистическое богатство языка определяется количеством слов и их сочетаний, а это никак не связано с числом букв в алфавите. С точки зрения техники это означает, что сообщения из равного количества символов будет иметь разную длину (и соответственно, время передачи) и большими они окажутся у сообщений на русском языке.
В качестве следующего (первого) приближения, уточняющего исходное, попробуем учесть то обстоятельство, что относительная частота, т.е. вероятность появления различных букв в тексте (или сообщении) различна. Рассмотрим таблицу средних частот букв для русского алфавита, в который включен также знак "пробел" для разделения слов (из книги А.М. и И.М.Ягломов [с.238]); с учетом неразличимости букв "е" и "ë", а также "ь" и "ъ" (так принято в телеграфном кодировании), получим алфавит из 32 знаков со следующими вероятностями их появления в русских текстах:
Таблица 1. Частота появления букв |
|||||||
Буква |
Частота |
Буква |
Частота |
Буква |
Частота |
Буква |
Частота |
пробел |
0,175 |
o |
0,090 |
е, ë |
0,072 |
а |
0,062 |
и |
0,062 |
т |
0,053 |
н |
0,053 |
с |
0,045 |
р |
0,040 |
в |
0,038 |
л |
0,035 |
к |
0,028 |
м |
0,026 |
д |
0,025 |
п |
0,023 |
у |
0,021 |
я |
0,018 |
ы |
0,016 |
з |
0,016 |
ъ, ь |
0,014 |
б |
0,014 |
г |
0,013 |
ч |
0,012 |
й |
0,010 |
х |
0,009 |
ж |
0,007 |
ю |
0,006 |
ш |
0,006 |
ц |
0,004 |
щ |
0,003 |
э |
0,003 |
ф |
0,002 |
Для оценки информации, связанной с выбором одного знака алфавита с учетом неравной вероятности их появления в сообщении (текстах) можно воспользоваться формулой (1.14). Из нее, в частности, следует, что если pi – вероятность (относительная частота) знака номер i данного алфавита из N знаков, то среднее количество информации, приходящейся на один знак, равно:
![]() (1.17)
(1.17)
Это и есть знаменитая формула К.Шеннона, с работы которого "Математическая теория связи" (1948) принято начинать отсчет возраста информатики, как самостоятельной науки. Объективности ради следует заметить, что и в нашей стране практически одновременно с Шенноном велись подобные исследования, например, в том же 1948 г. вышла работа А.Н.Колмогорова "Математическая теория передачи информации".
Применение формулы (1.17) к алфавиту русского языка дает значение средней информации на знак I1(r) = 4,36 бит, а для английского языка I1(e) = 4,04 бит, для французского I1(l) = 3,96 бит, для немецкого I1(d) = 4,10 бит, для испанского I1(s) = 3,98 бит. Как мы видим, и для русского, и для английского языков учет вероятностей появления букв в сообщениях приводит к уменьшению среднего информационного содержания буквы, что, кстати, подтверждает справедливость формулы (1.7). Несовпадение значений средней информации для английского, французского и немецкого языков, основанных на одном алфавите, связано с тем, что частоты появления одинаковых букв в них различаются.
В рассматриваемом приближении по умолчанию предполагается, что вероятность появления любого знака в любом месте сообщения остается одинаковой и не зависит от того, какие знаки или их сочетания предшествуют данному. Такие сообщения называются шенноновскими (или сообщениями без памяти).
Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем, называются шенноновскими, а порождающий их отправитель – шенноновским источником.
Если сообщение является шенноновским, то набор знаков (алфавит) и вероятности их появления в сообщении могут считаться известными заранее. В этом случае, с одной стороны, можно предложить оптимальные способы кодирования, уменьшающие суммарную длину сообщения при передаче по каналу связи. С другой стороны, интерпретация сообщения, представляющего собой последовательность сигналов, сводится к задаче распознавания знака, т.е. выявлению, какой именно знак находится в данном месте сообщения. А такая задача, как мы уже убедились в предыдущем шаге, может быть решена серией парных выборов. При этом количество информации, содержащееся в знаке, служит мерой затрат по его выявлению.
Последующие (второе и далее) приближения при оценке значения информации, приходящейся на знак алфавита, строятся путем учета корреляций, т.е. связей между буквами в словах. Дело в том, что в словах буквы появляются не в любых сочетаниях; это понижает неопределенность угадывания следующей буквы после нескольких, например, в русском языке нет слов, в которых встречается сочетание щц или фъ. И напротив, после некоторых сочетаний можно с большей определенностью, чем чистый случай, судить о появлении следующей буквы, например, после распространенного сочетания пр- всегда следует гласная буква, а их в русском языке 10 и, следовательно, вероятность угадывания следующей буквы 1/10, а не 1/33. В связи с этим примем следующее определение:
Сообщения (а также источники, их порождающие), в которых существуют статистические связи (корреляции) между знаками или их сочетаниями, называются сообщениями (источниками) с памятью или марковскими сообщениями (источниками).
Как указывается в книге Л.Бриллюэна [с.46], учет в английских словах двухбуквенных сочетаний понижает среднюю информацию на знак до значения I2(e)=3,32 бит, учет трехбуквенных – до I3(e)=3,10 бит. Шеннон сумел приблизительно оценить I5(e) 2,1 бит, I8(e) 1,9 бит. Аналогичные исследования для русского языка дают: I2(r) = 3,52 бит; I3(r)= 3,01 бит.
Последовательность I0,
I1, I2...
является убывающей в любом языке.
Экстраполируя ее на учет бесконечного
числа корреляций, можно оценить предельную
информацию на знак в данном языке
![]() ,
которая будет отражать минимальную
неопределенность, связанную с выбором
знака алфавита без учета семантических
особенностей языка, в то время как I0
является другим предельным случаем,
поскольку характеризует наибольшую
информацию, которая может содержаться
в знаке данного алфавита. Шеннон ввел
величину, которую назвал относительной
избыточностью языка:
,
которая будет отражать минимальную
неопределенность, связанную с выбором
знака алфавита без учета семантических
особенностей языка, в то время как I0
является другим предельным случаем,
поскольку характеризует наибольшую
информацию, которая может содержаться
в знаке данного алфавита. Шеннон ввел
величину, которую назвал относительной
избыточностью языка:
![]() (1.18)
(1.18)
Избыточность является мерой бесполезно совершаемых альтернативных выборов при чтении текста. Эта величина показывает, какую долю лишней информации содержат тексты данного языка; лишней в том отношении, что она определяется структурой самого языка и, следовательно, может быть восстановлена без явного указания в буквенном виде.
Исследования Шеннона для
английского языка дали значение
![]() 1,4÷1,5
бит, что по отношению к I0=4,755
бит создает избыточность около 0,68.
Подобные оценки показывают, что и для
других европейских языков, в том числе
русского, избыточность составляет 60 –
70%. Это означает, что в принципе возможно
почти трехкратное (!) сокращение текстов
без ущерба для их содержательной стороны
и выразительности. Например, телеграфные
тексты делаются короче за счет отбрасывания
союзов и предлогов без ущерба для смысла;
в них же используются однозначно
интерпретируемые сокращения "ЗПТ"
и "ТЧК" вместо полных слов (эти
сокращения приходится использовать,
поскольку знаки "." и "," не
входят в телеграфный алфавит). Однако
такое "экономичное" представление
слов снижает разборчивость языка,
уменьшает возможность понимания речи
при наличии шума (а это одна из проблем
передачи информации по реальным линиям
связи), а также исключает возможность
локализации и исправления ошибки
(написания или передачи) при ее
возникновении. Именно избыточность
языка позволяет легко восстановить
текст, даже если он содержит большое
число ошибок или неполон (например, при
отгадывании кроссвордов или при игре
в "Поле чудес"). В этом смысле
избыточность есть определенная страховка
и гарантия разборчивости.
1,4÷1,5
бит, что по отношению к I0=4,755
бит создает избыточность около 0,68.
Подобные оценки показывают, что и для
других европейских языков, в том числе
русского, избыточность составляет 60 –
70%. Это означает, что в принципе возможно
почти трехкратное (!) сокращение текстов
без ущерба для их содержательной стороны
и выразительности. Например, телеграфные
тексты делаются короче за счет отбрасывания
союзов и предлогов без ущерба для смысла;
в них же используются однозначно
интерпретируемые сокращения "ЗПТ"
и "ТЧК" вместо полных слов (эти
сокращения приходится использовать,
поскольку знаки "." и "," не
входят в телеграфный алфавит). Однако
такое "экономичное" представление
слов снижает разборчивость языка,
уменьшает возможность понимания речи
при наличии шума (а это одна из проблем
передачи информации по реальным линиям
связи), а также исключает возможность
локализации и исправления ошибки
(написания или передачи) при ее
возникновении. Именно избыточность
языка позволяет легко восстановить
текст, даже если он содержит большое
число ошибок или неполон (например, при
отгадывании кроссвордов или при игре
в "Поле чудес"). В этом смысле
избыточность есть определенная страховка
и гарантия разборчивости.
На практике учет корреляций в сочетаниях знаков сообщения весьма затруднителен, поскольку требует объемных статистических исследований текстов. Кроме того, корреляционные вероятности зависят от характера текстов и целого ряда иных их особенностей. По этим причинам в дальнейшем мы ограничим себя рассмотрением только шенноновских сообщений, т.е. будем учитывать различную (априорную) вероятность появления знаков в тексте, но не их корреляции.
Понятие и основные задачи теории кодирования.
Теория кодирования информации является одним из разделов теоретической информатики. К основным задачам, решаемым в данном разделе, необходимо отнести следующие:
разработка принципов наиболее экономичного кодирования информации;
согласование параметров передаваемой информации с особенностями канала связи;
разработка приемов, обеспечивающих надежность передачи информации по каналам связи, т.е. отсутствие потерь информации.
Две последние задачи связаны с процессами передачи информации. Первая же задача – кодирование информации – касается не только передачи, но и обработки, и хранения информации, т.е. охватывает широкий круг проблем; частным их решением будет представление информации в компьютере. С обсуждения этих вопросов и начнем освоение теории кодирования.
Основные определения теории кодирования.
Как отмечалось при рассмотрении исходных понятий информатики, для представления дискретной информации используется некоторый алфавит. Однако однозначное соответствие между информацией и алфавитом отсутствует. Другими словами, одна и та же информация может быть представлена посредством различных алфавитов. В связи с такой возможностью возникает проблема перехода от одного алфавита к другому, причем, такое преобразование не должно приводить к потере информации. Условимся называть алфавит, с помощью которого представляется информация до преобразования, первичным; алфавит конечного представления – вторичным.
Введем ряд с определений:
Код – (1) правило, описывающее соответствие знаков или их сочетаний одного алфавита знакам или их сочетаниям другого алфавита; - (2) знаки вторичного алфавита, используемые для представления знаков или их сочетаний первичного алфавита.
Кодирование – перевод информации, представленной посредством первичного алфавита, в последовательность кодов.
Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Примером обратимого кодирования является представление знаков в телеграфном коде и их восстановление после передачи. Примером кодирования необратимого может служить перевод с одного естественного языка на другой – обратный перевод, вообще говоря, не восстанавливает исходного текста. Безусловно, для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применения кода, поэтому в дальнейшем изложении ограничим себя рассмотрением только обратимого кодирования.
Таким образом, кодирование предшествует передаче и хранению информации. При этом, как указывалось ранее, хранение связано с фиксацией некоторого состояния носителя информации, а передача – с изменением состояния с течением времени (т.е. процессом). Эти состояния или сигналы будем называть элементарными сигналами – именно их совокупность и составляет вторичный алфавит.
Математическая постановка задачи кодирования.
Не обсуждая технических сторон передачи и хранения сообщения (т.е. того, каким образом фактически реализованы передача-прием последовательности сигналов или фиксация состояний), попробуем дать математическую постановку задачи кодирования.
Пусть первичный алфавит A содержит N знаков со средней информацией на знак, определенной с учетом вероятностей их появления, I1(A) (нижний индекс отражает то обстоятельство, что рассматривается первое приближение, а верхний индекс в скобках указывает алфавит). Вторичный алфавит B пусть содержит M знаков со средней информационной емкостью I1(A). Пусть также исходное сообщение, представленное в первичном алфавите, содержит n знаков, а закодированное сообщение – m знаков. Если исходное сообщение содержит I(A) информации, а закодированное – I(B), то условие обратимости кодирования, т.е. неисчезновения информации при кодировании, очевидно, может быть записано следующим образом:
I(A) I(B),
смысл которого в том, что операция обратимого кодирования может увеличить количество формальной информации в сообщении, но не может его уменьшить. Однако каждая из величин в данном неравенстве может быть заменена произведением числа знаков на среднюю информационную емкость знака, т.е.:

Отношение m/n, очевидно, характеризует среднее число знаков вторичного алфавита, которое приходится использовать для кодирования одного знака первичного алфавита – будем называть его длиной кода или длиной кодовой цепочки и обозначим K(B) (верхний индекс указывает алфавит кодов).
В частном случае, когда появление любых знаков вторичного алфавита равновероятно, согласно формуле Хартли I1(B)=log2M, и тогда
![]() (1)
(1)
По аналогии с величиной R, характеризующей избыточность языка, можно ввести относительную избыточность кода (Q):
![]() (2)
(2)
Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения. Очевидно, чем меньше Q (т.е. чем ближе она к 0 или, что то же, I(B) ближе к I(A)), тем более выгодным оказывается код и более эффективной операция кодирования. Выгодность кодирования при передаче и хранении – это экономический фактор, поскольку более эффективный код позволяет затратить на передачу сообщения меньше энергии, а также времени и, соответственно, меньше занимать линию связи; при хранении используется меньше площади поверхности (объема) носителя. При этом следует сознавать, что выгодность кода не идентична временнóй выгодности всей цепочки кодирование – передача – декодирование; возможна ситуация, когда за использование эффективного кода при передаче придется расплачиваться тем, что операции кодирования и декодирования будут занимать больше времени и иных ресурсов (например, места в памяти технического устройства, если эти операции производятся с его помощью).
Выражение (1) пока следует воспринимать как соотношение оценочного характера, из которого неясно, в какой степени при кодировании возможно приближение к равенству его правой и левой частей. По этой причине для теории связи важнейшее значение имеют две теоремы, доказанные Шенноном. Первая – ее мы сейчас рассмотрим – затрагивает ситуацию с кодированием при передаче сообщения по линии связи, в которой отсутствуют помехи, искажающие информацию. Вторая теорема относится к реальным линиям связи с помехами.
Первая теорема Шеннона.
Первая теорема Шеннона о передаче информации, которая называется также основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором среднее число знаков кода, приходящихся на один знак кодируемого алфавита, будет сколь угодно близко к отношению средних информаций на знак первичного и вторичного алфавитов.
Используя понятие избыточности кода, можно дать более короткую формулировку теоремы:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
Данные утверждения являются теоремами и, следовательно, должны доказываться, однако доказательства мы опустим. Для нас важно, что теорема открывает принципиальную возможность оптимального кодирования. Однако необходимо сознавать, что из самой теоремы никоим образом не следует, как такое кодирование осуществить практически – для этого должны привлекаться какие-то дополнительные соображения, что и станет предметом нашего последующего обсуждения.
Далее в основном ограничим себя ситуацией, когда M = 2, т.е. для представления кодов в линии связи используется лишь два типа сигналов – с практической точки зрения это наиболее просто реализуемый вариант (например, существование напряжения в проводе (будем называть это импульсом) или его отсутствие (пауза); наличие или отсутствие отверстия на перфокарте или намагниченной области на дискете); подобное кодирование называется двоичным. Знаки двоичного алфавита принято обозначать "0" и "1", но нужно воспринимать их как буквы, а не цифры. Удобство двоичных кодов и в том, что при равных длительностях и вероятностях каждый элементарный сигнал (0 или 1) несет в себе 1 бит информации (log2M = 1); тогда из (1), теоремы Шеннона:
I1(A) K(2)
и первая теорема Шеннона получает следующую интерпретацию:
При отсутствии помех передачи средняя длина двоичного кода может быть сколь угодно близкой к средней информации, приходящейся на знак первичного алфавита.
Применение формулы (2) для двоичного кодирования дает:
![]()
Определение количества переданной информации при двоичном кодировании сводится к простому подсчету числа импульсов (единиц) и пауз (нулей). При этом возникает проблема выделения из потока сигналов (последовательности импульсов и пауз) отдельных кодов. Приемное устройство фиксирует интенсивность и длительность сигналов. Элементарные сигналы (0 и 1) могут иметь одинаковые или разные длительности. Их количество в коде (длина кодовой цепочки), который ставится в соответствие знаку первичного алфавита, также может быть одинаковым (в этом случае код называется равномерным) или разным (неравномерный код). Наконец, коды могут строиться для каждого знака исходного алфавита (алфавитное кодирование) или для их комбинаций (кодирование блоков, слов). В результате при кодировании (алфавитном и словесном) возможны следующие варианты сочетаний:
Таблица 1. Варианты сочетаний |
||
Длительности элементарных сигналов |
Кодировка первичных символов (слов) |
Ситуация |
одинаковые |
равномерная |
(1) |
одинаковые |
неравномерная |
(2) |
разные |
равномерная |
(3) |
разные |
неравномерная |
(4) |
В случае использования неравномерного кодирования или сигналов разной длительности (ситуации (2), (3) и (4)) для отделения кода одного знака от другого между ними необходимо передавать специальный сигнал – временной разделитель (признак конца знака) или применять такие коды, которые оказываются уникальными, т.е. несовпадающими с частями других кодов. При равномерном кодировании одинаковыми по длительности сигналами (ситуация (1)) передачи специального разделителя не требуется, поскольку отделение одного кода от другого производится по общей длительности, которая для всех кодов оказывается одинаковой (или одинаковому числу бит при хранении).
Длительность двоичного
элементарного импульса (![]() )
показывает, сколько времени требуется
для передачи 1 бит информации. Очевидно,
для передачи информации, в среднем
приходящейся на знак первичного алфавита,
необходимо время
)
показывает, сколько времени требуется
для передачи 1 бит информации. Очевидно,
для передачи информации, в среднем
приходящейся на знак первичного алфавита,
необходимо время
![]() .
Таким образом, задачу оптимизации
кодирования можно сформулировать в
иных терминах: построить такую систему
кодирования, чтобы суммарная длительность
кодов при передаче (или суммарное число
кодов при хранении) данного сообщения
была бы наименьшей.
.
Таким образом, задачу оптимизации
кодирования можно сформулировать в
иных терминах: построить такую систему
кодирования, чтобы суммарная длительность
кодов при передаче (или суммарное число
кодов при хранении) данного сообщения
была бы наименьшей.
Алфавитное неравномерное двоичное кодирование; префиксный код; код Хаффмана.
Данный случай относится к варианту (2). При этом как следует из названия, символы некоторого первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться. Длительности элементарных сигналов при этом одинаковы ( 0 = 1 = ). За счет чего можно оптимизировать кодирование в этом случае? Очевидно, суммарная длительность сообщения будет меньше, если применить следующий подход: тем буквам первичного алфавита, которые встречаются чаще, присвоить более короткие по длительности коды, а тем, относительная частота которых меньше – коды более длинные. Но длительность кода – величина дискретная, она кратна длительности сигнала передающего один символ двоичного алфавита. Следовательно, коды букв, вероятность появления которых в сообщении выше, следует строить из возможно меньшего числа элементарных сигналов. Построим кодовую таблицу для букв русского алфавита, основываясь на приведенных ранее вероятностях появления отдельных букв.
Очевидно, возможны различные варианты двоичного кодирования, однако, не все они будут пригодны для практического использования – важно, чтобы закодированное сообщение могло быть однозначно декодировано, т.е. чтобы в последовательности 0 и 1, которая представляет собой многобуквенное кодированное сообщение, всегда можно было бы различить обозначения отдельных букв. Проще всего этого достичь, если коды будут разграничены разделителем – некоторой постоянной комбинацией двоичных знаков. Условимся, что разделителем отдельных кодов букв будет последовательность 00 (признак конца знака), а разделителем слов – 000 (признак конца слова – пробел). Довольно очевидными оказываются следующие правила построения кодов:
код признака конца знака может быть включен в код буквы, поскольку не существует отдельно (т.е. кода всех букв будут заканчиваться 00);
коды букв не должны содержать двух и более нулей подряд в середине (иначе они будут восприниматься как конец знака);
код буквы (кроме пробела) всегда должен начинаться с 1;
разделителю слов (000) всегда предшествует признак конца знака; при этом реализуется последовательность 00000 (т.е. если в конце кода встречается комбинация …000 или …0000, они не воспринимаются как разделитель слов); следовательно, коды букв могут оканчиваться на 0 или 00 (до признака конца знака).
Длительность передачи каждого отдельного кода ti, очевидно, может быть найдена следующим образом: ti = ki • , где ki – количество элементарных сигналов (бит) в коде символа i. В соответствии с приведенными выше правилами получаем следующую таблицу кодов:
Таблица 1. Таблица кодов |
|||||||
Буква |
Код |
pi·103 |
ki |
Буква |
Код |
pi·103 |
ki |
пробел |
000 |
174 |
3 |
я |
1011000 |
18 |
7 |
о |
100 |
90 |
3 |
ы |
1011100 |
16 |
7 |
е |
1000 |
72 |
4 |
з |
1101000 |
16 |
7 |
а |
1100 |
62 |
4 |
ь,ъ |
1101100 |
14 |
7 |
и |
10000 |
62 |
5 |
б |
1110000 |
14 |
7 |
т |
10100 |
53 |
5 |
г |
1110100 |
13 |
7 |
н |
11000 |
53 |
5 |
ч |
1111000 |
12 |
7 |
с |
11100 |
45 |
5 |
й |
1111100 |
10 |
7 |
р |
101000 |
40 |
6 |
х |
10101000 |
9 |
8 |
в |
101100 |
38 |
6 |
ж |
10101100 |
7 |
8 |
л |
110000 |
35 |
6 |
ю |
10110000 |
6 |
8 |
к |
110100 |
28 |
6 |
ш |
10110100 |
6 |
8 |
м |
111000 |
26 |
6 |
ц |
10111000 |
4 |
8 |
д |
111100 |
25 |
6 |
щ |
10111100 |
3 |
8 |
п |
1010000 |
23 |
7 |
э |
11010000 |
3 |
8 |
у |
1010100 |
21 |
7 |
ф |
11010100 |
2 |
8 |
Теперь по формуле можно найти среднюю длину кода K(2) для данного способа кодирования:
![]()
Поскольку для русского языка, I1(r)=4,356 бит, избыточность данного кода, согласно (2), составляет:
Q(r) = 1 - 4,356/4,964 0,122;
это означает, что при данном способе кодирования будет передаваться приблизительно на 12% больше информации, чем содержит исходное сообщение. Аналогичные вычисления для английского языка дают значение K(2) = 4,716, что при I1(e) = 4,036 бит приводят к избыточности кода Q(e) = 0,144.
Рассмотрев один из вариантов двоичного неравномерного кодирования, попробуем найти ответы на следующие вопросы: возможно ли такое кодирование без использования разделителя знаков? Существует ли наиболее оптимальный способ неравномерного двоичного кодирования?
Суть первой проблемы состоит в нахождении такого варианта кодирования сообщения, при котором последующее выделение из него каждого отдельного знака (т.е. декодирование) оказывается однозначным без специальных указателей разделения знаков. Наиболее простыми и употребимыми кодами такого типа являются так называемые префиксные коды, которые удовлетворяют следующему условию (условию Фано):
Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом (префиксом) какого-либо иного более длинного кода.
Например, если имеется код 110, то уже не могут использоваться коды 1, 11, 1101, 110101 и пр. Если условие Фано выполняется, то при прочтении (расшифровке) закодированного сообщения путем сопоставления со списком кодов всегда можно точно указать, где заканчивается один код и начинается другой.
Пример 1. Пусть имеется следующая таблица префиксных кодов:
Таблица 2. Таблица кодов |
|||||
а |
л |
м |
р |
у |
ы |
10 |
010 |
00 |
11 |
0110 |
0111 |
Требуется декодировать сообщение: 00100010000111010101110000110.
Декодирование производится циклическим повторением следующих действий.
Отрезать от текущего сообщения крайний левый символ, присоединить к рабочему кодовому слову.
Сравнить рабочее кодовое слово с кодовой таблицей; если совпадения нет, перейти к (1).
Декодировать рабочее кодовое слово, очистить его.
Проверить, имеются ли еще знаки в сообщении; если "да", перейти к (1).
Применение данного алгоритма дает:

Доведя процедуру до конца, получим сообщение: "мама мыла раму".
Таким образом, использование префиксного кодирования позволяет делать сообщение более коротким, поскольку нет необходимости передавать разделители знаков. Однако условие Фано не устанавливает способа формирования префиксного кода и, в частности, наилучшего из возможных.
Способ оптимального префиксного двоичного кодирования был предложен Д.Хаффманом. Построение кодов Хаффмана мы рассмотрим на следующем примере: пусть имеется первичный алфавит A, состоящий из шести знаков a1, ..., a6 с вероятностями появления в сообщении, соответственно, 0,3; 0,2; 0,2; 0,15; 0,1; 0,05. Создадим новый вспомогательный алфавит A1, объединив два знака с наименьшими вероятностями (a5 и a6) и заменив их одним знаком (например, a(1)); вероятность нового знака будет равна сумме вероятностей тех, что в него вошли, т.е. 0,15; остальные знаки исходного алфавита включим в новый без изменений; общее число знаков в новом алфавите, очевидно, будет на 1 меньше, чем в исходном. Аналогичным образом продолжим создавать новые алфавиты, пока в последнем не останется два знака; ясно, что число таких шагов будет равно N – 2, где N – число знаков исходного алфавита (в нашем случае N = 6, следовательно, необходимо построить 4 вспомогательных алфавита). В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей. Всю процедуру построения представим в виде таблицы:
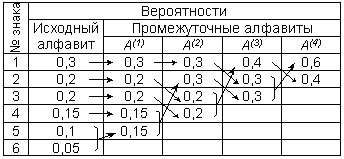
Теперь в обратном направлении поведем процедуру кодирования. Двум знакам последнего алфавита присвоим коды 0 и 1 (которому какой – роли не играет; условимся, что верхний знак будет иметь код 0, а нижний – 1). В нашем примере знак a1(4) алфавита A(4), имеющий вероятность 0,6 , получит код 0, а a2(4) с вероятностью 0,4 – код 1. В алфавите A(3) знак a1(3) с вероятностью 0,4 сохранит свой код (1); коды знаков a2(3) и a3(3), объединенных знаком a1(4) с вероятностью 0,6 , будут уже двузначным: их первой цифрой станет код связанного с ними знака (т.е. 0), а вторая цифра – как условились – у верхнего 0, у нижнего – 1; таким образом, a2(3) будет иметь код 00, а a3(3) – код 01. Полностью процедура кодирования представлена в следующей таблице:

Из самой процедуры построения кодов легко видеть, что они удовлетворяют условию Фано и, следовательно, не требуют разделителя. Средняя длина кода при этом оказывается:
K(2) = 0,3·2+0,2·2+0,2·2+0,15·3+0,1·4+0,05·4 = 2,45.
Для сравнения можно найти I1(A) – она оказывается равной 2,409, что соответствует избыточности кода Q = 0,0169, т.е. менее 2%.
Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является самым экономичным из всех возможных, т.е. ни для какого метода алфавитного кодирования длина кода не может оказаться меньше, чем код Хаффмана.
Применение описанного метода для букв русского алфавита дает следующие коды:
Таблица 3. Таблица кодов русских букв |
|||||||
Буква |
Код |
pi·103 |
ki |
Буква |
Код |
pi·103 |
ki |
пробел |
000 |
174 |
3 |
я |
0011001 |
18 |
6 |
о |
111 |
90 |
3 |
ы |
0101100 |
16 |
6 |
е |
0100 |
72 |
4 |
з |
010111 |
16 |
6 |
а |
0110 |
62 |
4 |
ь,ъ |
100001 |
14 |
6 |
и |
0111 |
62 |
4 |
б |
101100 |
14 |
6 |
т |
1001 |
53 |
4 |
г |
101101 |
13 |
6 |
н |
1010 |
53 |
5 |
ч |
110011 |
12 |
6 |
с |
1101 |
45 |
4 |
й |
0011001 |
10 |
7 |
р |
00101 |
40 |
5 |
х |
1000000 |
9 |
7 |
в |
00111 |
38 |
5 |
ж |
1000001 |
7 |
7 |
л |
01010 |
35 |
5 |
ю |
1100101 |
6 |
7 |
к |
10001 |
28 |
5 |
ш |
00110000 |
6 |
8 |
м |
10111 |
26 |
5 |
ц |
11001000 |
4 |
8 |
д |
11000 |
25 |
5 |
щ |
11001001 |
3 |
8 |
п |
001000 |
23 |
6 |
э |
001100010 |
3 |
9 |
у |
001001 |
21 |
6 |
ф |
001100011 |
2 |
9 |
Средняя длина кода оказывается равной K(2) = 4,395; избыточность кода Q(r) = 0,00887, т.е. менее 1%.
Таким образом, можно заключить, что существует метод построения оптимального неравномерного алфавитного кода. Не следует думать, что он представляет число теоретический интерес. Метод Хаффмана и его модификация – метод адаптивного кодирования (динамическое кодирование Хаффмана) – нашли широчайшее применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах.