

11.3. Генетический алгоритм для генерации правил требования
В целом ряде исследований генетический алгоритм применялся для поиска правил, основанных на макроэкономических моделях для рынка ценных бумаг с целью максимизации среднего дохода на трейд. Существуют эмпирические свидетельства, что дополнительный доход может быть получен посредством методов использования искусственного интеллекта для обработки макроэкономических данных за предшествующий период. Соответствующие правила, полученные применением генетического алгоритма выглядят следующим образом.

«Если ежегодный процент изменений в последовательностях S больше/меньше, чем Р процентов, тогда через L месяцев «купи/продай» согласно SP500 индексу и держи в течение одного месяца». В описанных в литературе экспериментах число изученных макроэкономических временных рядов из Business Conditions Digest было 361, и лаг L изменился от одного до трех месяцев: Р— дискретизировалось на 128 возможных значений, было также использовано два признака больше/меньше и две позиции купить/продать. Таким образом, пространство решений включало 368x3x128x2x2= 554496 возможных комбинаций. Правила купить/продать были подставлены 20-разрядной битовой строкой, организованный следующим образом:

Основной алгоритм характеризуют некоторые аналогии эволюции, проверявшейся в течение 3600 млн. лет «полевых испытаний»!
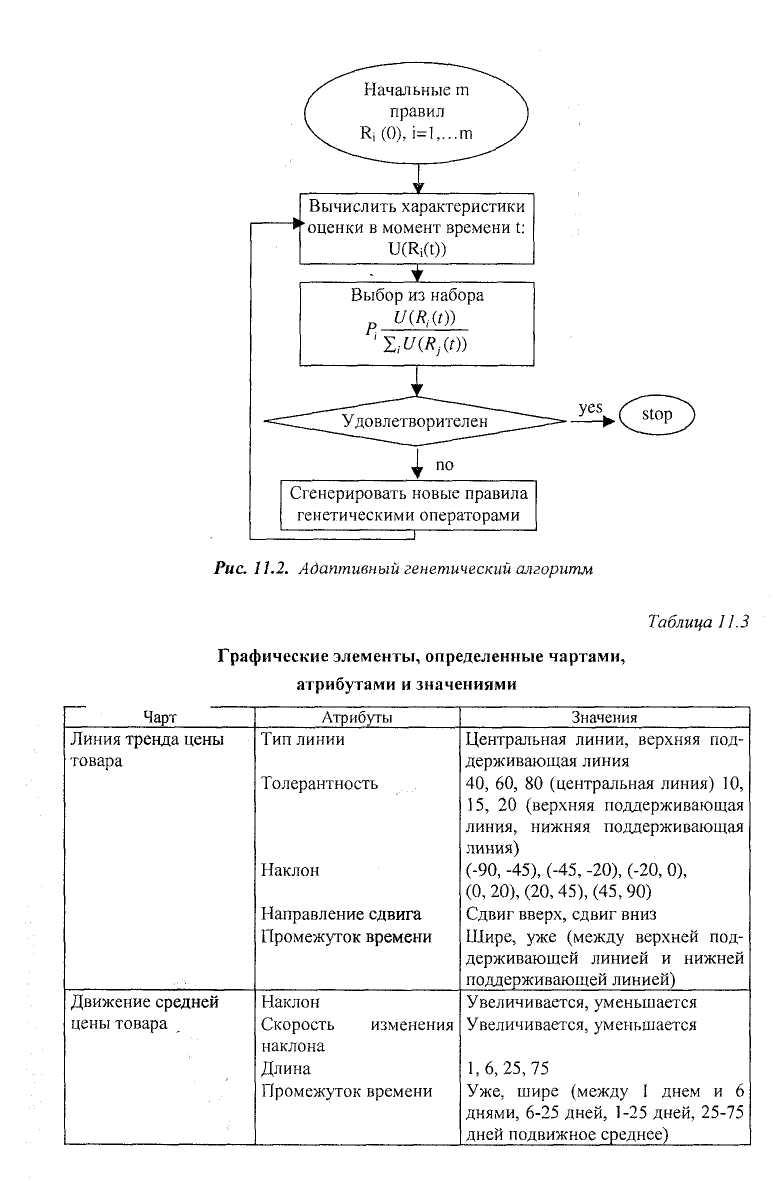
1. Случайным образом создать начальную популяцию из М правил- структур.
2. Вычислить и занести в память для каждого правила показатель эффективности его работы. Если их среднее значение достаточно высокое, то остановить вычисления и выдать эти правила.
3. Для каждого правила подсчитать вероятность его выбора р=е/Е, где е— индивидуальный показатель, а Е — суммарный показатель для всех М правил.
4. Создать следующую популяцию правил в соответствии с вычисленной вероятностью выбора и применяя операторы из генетики.
5. Повторить, начиная со второго шага.
Таким образом, среднее число «потомков» каждого правила в следующем поколении пропорционально измеренному успеху при решении стоящей перед системой задачи: выживают наиболее приспособленные.
Генетическими операторами, используемыми на шаге 4, являются кроссинговер, мутация и инверсия. В результате кроссинговера (или перекреста), например, правила (А, В, С, D) и (а, Ь, с, d) могут в качестве потомков в следующем поколении дать (А, В, С, d) и (а, Ь, с, D).
Основная трудность состоит в том, что для оператора кроссинговера требуется, чтобы правила были цепочками с равной длиной, содержащими независящие от положения компоненты. Это затрудняет создание работоспособного языка описания, и, кроме того, чрезвычайно трудно создать такой язык, который был бы к тому же понятен и людям.
Мутации, которые были включены в алгоритм, чтобы обеспечить возможность создания произвольных описаний, состоят в совершении случайных ошибок при записи правила.
В генетическом алгоритме динамика популяционной генетики имитируется путем организации базы знаний (популяции) структур (существ), которая эволюционирует со временем в соответствии с наблюдаемым поведением (пригодностью) ее структур в их рабочей среде. Каждая структура предъявляется алгоритму как последовательность составляющих частей (генотипов), с которой имеют дело операторы поиска. Конкретная интерпретация этой структуры (например, совокупности значений параметров правила вида «условие—действие» и т. д.) дает единственную точку в пространстве альтернативных решений для рассматриваемой проблемы генотипа, которая затем может быть включена в эволюционный процесс и которой можно приписать меру полезности. Поиск происходит посредством постоянного выбора структур из текущей базы знаний на основе ассоциированных мер полезности, получаемых благодаря интерпретации и применения к ним идеализированных генетических операций, создающих в эволюции новые структуры (потомки).
Главным средством создания новых структур является оператор кроссинговера. Он берет две структуры, случайным образом выбирает точку разрыва на этих структурах и меняет местами последовательности компонент относительно точки разрыва (перекрещивание).
Для привнесения новой информации в базу знаний предусмотрен оператор мутации, который произвольным образом изменяет одну или несколько компонент выбранной структуры.
Третий оператор, инверсия, изменяет характер связей между компонентами структуры. Он берет структуру, случайным образом выбирает на ней 2 точки разрыва и располагает в обратном порядке элементы, попавшие между точками разрыва.