

3.1.3. Масштабируемость Hyper-Threading архитектур
А сейчас проанализируем продемонстрированные особенности масштабируемости Hyper-Threading архитектур -- здесь есть над чем задуматься! Напомню, что с точки зрения маркетинга использование HT процессора как бы удваивает количество доступных CPU, т.е. 1 CPU, HT компьютер должен вести себя как 2 CPU, SMP, а 2 CPU, HT -- как 4 CPU, SMP, а ожидаемая масштабируемость функции start_ders на 2 CPU, SMP и 4 CPU, SMP составляет 0,5 и 0,25 соответственно. Следующая ниже таблица показывает насколько ожидаемая масштабируемость отличается от реальной:
|
numThr |
||||||
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
1 CPU |
0.997 |
0.994 |
0.997 |
0.999 |
1.004 |
1.004 |
1.003 |
1 CPU, HT |
2.810 |
2.802 |
2.806 |
2.790 |
2.826 |
2.818 |
2.800 |
2 CPU, SMP |
1.026 |
1.026 |
1.026 |
1.024 |
1.026 |
1.050 |
1.018 |
2 CPU, HT |
2.008 |
3.376 |
2.536 |
2.620 |
2.596 |
2.588 |
2.544 |
Увы, все очень печально: масштабируемость HT вариантов приблизительно в 2,6-2,8 раз хуже ожидаемой. Данная цифра тем более любопытна, что даже если считать один HT процессор не за два, а один CPU, то полученные значения 1,3-1,4 все равно больше единицы, т.е.
С точки зрения масштабируемости один Hyper-Threading процессор не только хуже двух обычных -- он хуже даже одного!
Любопытно, не так ли?
3.2. Example2.Exe: работа с файлами
Второй пример более приближен к жизни и предназначен для измерения относительной производительности MT приложения, работающего с файлами. Работа с файлами главным образом "упирается" в производительность файловой подсистемы ОС, так что прикладной код, использующий системные вызовы ввода/вывода, вряд ли покажет существенную разницу производительности...
Или все же покажет?!
Как известно, стандартные потоки ввода/вывода C++ работают существенно медленнее потоков ввода/вывода C. Но, к сожалению, даже C-шные потоки FILE не подходят для MT приложений, т.к. все операции над ними обязаны быть thread-safe по умолчанию, а быстрые варианты функций getc() и putc(), не использующие пресловутые mutex-ы, имеют другие имена: getc_unlocked() и putc_unlocked() соответственно. Тем самым, написание кода, одинаково хорошо работающего как в ST, так и в MT окружении становится невозможным.
Главным образом, для решения этой проблемы и был создан класс file, не использующий блокировок:
example2/main.cpp |
#include <memory> #include <vector> #include <stdio.h> #include <time.h> #include <ders/file.hpp> #include <ders/text_buf.hpp> #include <ders/thread.hpp>
using namespace std; using namespace ders;
const int BUF_SIZE=64*1024;
struct MainData { const char* fname; MainData(const char* fn) : fname(fn) {} };
struct ThreadData { MainData* md; int n;
ThreadData(MainData* md_, int n_) : md(md_), n(n_) {} };
void start_std(void* arg) { ThreadData* td=(ThreadData*)arg; auto_ptr<ThreadData> guard(td);
mem_pool mp; file err(mp, fd::err);
FILE* fin=fopen(td->md->fname, "rb"); if (!fin) { err.write(text_buf(mp)+"Can't open "+td->md->fname+'\n'); return; }
sh_text oname=text_buf(mp)+td->md->fname+'.'+td->n; FILE* fout=fopen(oname->c_str(), "wb"); if (!fout) { err.write(text_buf(mp)+"Can't create "+oname+'\n'); fclose(fin); return; }
setvbuf(fin, 0, _IOFBF, BUF_SIZE); setvbuf(fout, 0, _IOFBF, BUF_SIZE);
for (int ch; (ch=fgetc(fin))!=EOF; ) fputc(ch, fout);
fclose(fout); fclose(fin); }
void start_ders(void* arg) { ThreadData* td=(ThreadData*)arg; auto_ptr<ThreadData> guard(td);
mem_pool mp; file err(mp, fd::err);
file fin(mp); if (!fin.open(td->md->fname, file::rdo, 0)) { err.write(text_buf(mp)+"Can't open "+td->md->fname+'\n'); return; }
sh_text oname=text_buf(mp)+td->md->fname+'.'+td->n; file fout(mp); if (!fout.open(oname, file::wro, file::crt|file::trnc)) { err.write(text_buf(mp)+"Can't create "+oname+'\n'); return; }
buf_reader br(mp, fin, BUF_SIZE); buf_writer bw(mp, fout, BUF_SIZE);
for (int ch; (ch=br.read())!=-1; ) bw.write(ch); }
int main(int argc, char** argv) { mem_pool mp; file err(mp, fd::err); file out(mp, fd::out);
if (argc!=4) { m1: err.write("main file num_threads std|ders"); return 1; }
int numThr=atoi(argv[2]); if ( !(numThr>=1 && numThr<=100) ) { err.write("num_threads must be in [1, 100]"); return 1; }
void (*start)(void*); if (strcmp(argv[3], "std")==0) start=start_std; else if (strcmp(argv[3], "ders")==0) start=start_ders; else goto m1;
MainData md(argv[1]);
clock_t c1=clock();
vector<sh_thread> vthr; for (int i=0; i<numThr; i++) vthr.push_back(new_thread(mp, start, new ThreadData(&md, i))); for (int i=0; i<numThr; i++) vthr[i]->join();
clock_t c2=clock(); out.write(text_buf(mp)+numThr+'\t'+int(c2-c1)+'\t'+argv[3]+'\n');
return 0; } |
Пример запускает заданное количество потоков, в каждом из которых создается копия указанного в командной строке файла посредством выбранной функции: start_std() или start_ders(). Потоками используется посимвольное копирование через буфер размера BUF_SIZE.
В таблице представлены усредненные результаты запуска (в секундах) на трех разных компиляторах с файлом десятимегабайтного размера:
1 CPU |
||||||||||
|
numThr |
|
||||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||
1 |
std |
2.02 |
3.98 |
5.91 |
7.94 |
9.85 |
11.89 |
14.00 |
15.81 |
|
ders |
0.74 |
2.06 |
3.64 |
5.14 |
6.72 |
8.81 |
9.40 |
10.96 |
||
std/ders |
2.73 |
1.93 |
1.62 |
1.54 |
1.47 |
1.35 |
1.49 |
1.44 |
||
2 |
std |
1.45 |
2.74 |
4.29 |
5.75 |
7.01 |
8.53 |
9.82 |
11.25 |
|
ders |
0.80 |
1.98 |
3.72 |
5.40 |
7.24 |
8.41 |
10.41 |
11.19 |
||
std/ders |
1.81 |
1.38 |
1.15 |
1.06 |
0.97 |
1.01 |
0.94 |
1.01 |
||
3 |
std |
1.03 |
2.16 |
3.67 |
5.10 |
7.20 |
8.01 |
9.55 |
10.55 |
|
ders |
0.52 |
1.93 |
3.59 |
5.59 |
6.92 |
7.86 |
9.68 |
10.88 |
||
std/ders |
1.98 |
1.12 |
1.02 |
0.91 |
1.04 |
1.02 |
0.99 |
0.97 |
||
2 CPU, SMP |
||||||||||
|
numThr |
|
||||||||
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|||
1 |
std |
2.13 |
4.53 |
5.35 |
7.67 |
8.79 |
10.46 |
10.59 |
11.76 |
|
ders |
0.06 |
0.39 |
0.65 |
0.99 |
1.09 |
1.22 |
1.77 |
1.81 |
||
std/ders |
35.50 |
11.62 |
8.23 |
7.75 |
8.06 |
8.57 |
5.98 |
6.50 |
||
2 |
std |
1.97 |
7.36 |
11.82 |
14.39 |
17.76 |
20.64 |
22.44 |
25.77 |
|
ders |
0.06 |
0.38 |
0.66 |
0.71 |
1.11 |
1.51 |
1.50 |
1.93 |
||
std/ders |
32.83 |
19.37 |
17.91 |
20.27 |
16.00 |
13.67 |
14.96 |
13.35 |
||
3 |
std |
1.75 |
2.35 |
4.36 |
4.94 |
5.39 |
6.19 |
6.97 |
8.14 |
|
ders |
0.14 |
0.34 |
0.96 |
0.64 |
1.29 |
1.47 |
1.48 |
2.08 |
||
std/ders |
12.50 |
6.91 |
4.54 |
7.72 |
4.18 |
4.21 |
4.71 |
3.91 |
||
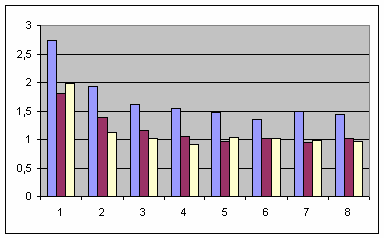
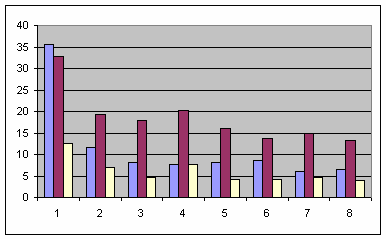
Как можно видеть,
1 CPU. Функция start_ders работает быстрее в 1.4-2.7, 0.9-1.8 и 0.9-2.0 раз для каждого из трех компиляторов соответственно. Вероятно, значения меньше 1.0 (т.е. небольшое замедление, а не ускорение работы) являются следствием ошибок измерения, неизменно возникающих при замерах времени работы приложений, интенсивно работающих с файловой подсистемой.
2 CPU, SMP. В данном случае преимущество start_ders, так скажем, более очевидно: в 6.0-35.5, 13.4-32.9 и 4.2-12.5 раз соответственно!
Во всех случаях наибольший выигрыш производительности получен на единственном рабочем потоке, когда встроенная синхронизация функций getc() и putc() полностью невостребована. А по ходу увеличения количества рабочих потоков выигрыш постепенно уменьшается в силу того, что узким местом масштабируемости является сама файловая подсистема, не поддерживающая эффективного распараллеливания запросов ввода/вывода в силу своего устройства.
Таким образом,
Использование класса ders::file способно ускорить выполнение MT приложений в десятки раз!
Конечно, это не сотни раз предыдущего примера, но, тем не менее, даже подобная "скромная" разница производительности заставляет пристально присмотреться к устройству стандартной библиотеки C++: любопытно, задумывались ли ее проектировщики об эффективности работы в многопоточной среде?
И, в свете всего вышеперечисленного, у нас есть вполне определенный ответ на вопрос "Оправдано ли создание своих собственных классов, предоставляющих альтернативную реализацию давным-давно известных стандартных функций ввода/вывода?": увы, "не мона, а нуна"!