

3.5.6. Пример построения нелинейного уравнения регрессии
В качестве примера рассмотрим данные из табл. 3.4, где указаны объемы производства (xi, 1000т) и фермерская цена (уi долл. за 1т), скорректированная на индекс потребительских цен вишни в США в 1954 - 1969 гг.
Таблица 3.4
Год |
1954 |
1955 |
1956 |
1957 |
1958 |
1959 |
1960 |
1961 |
1962 |
1963 |
1964 |
1965 |
1966 |
1967 |
1968 |
1969 |
xi |
204 |
260 |
168 |
239 |
192 |
218 |
185 |
266 |
276 |
150 |
344 |
248 |
200 |
198 |
228 |
278 |
yi |
267 |
174 |
228 |
208 |
225 |
243 |
227 |
217 |
163 |
345 |
154 |
165 |
299 |
325 |
294 |
188 |
Как правило, зависимость между ценой и объемом производства товара нелинейна. Диаграмма рассеяния для данного примера показана на рис. 3.5. Какой-либо отчетливой зависимости между значениями величин x и y на диаграмме рассеяния не видно. Но о приблизительно линейной или параболической зависимости сказать все же можно. Подкрепим эти рассуждения расчетами.
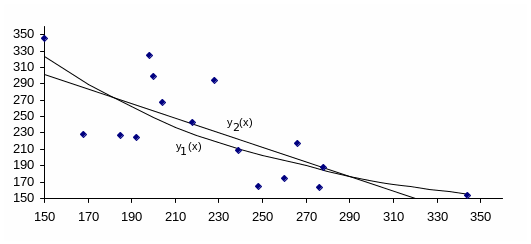
Рис. 3.5
Если вычислить по этим данным выборочный коэффициент корреляции, то получим, что r = -0,738, а это достаточно близко к 1. Ниже мы постараемся обосновать, почему парабола все-таки несколько лучше описывает эти данные, чем прямая. Коэффициенты системы линейных уравнений таковы:
n
= 16; ![]() =
3654;
=
3654; ![]() =
870918;
=
870918; ![]() =
216509904;
=
216509904;
![]() =
560635921000;
=
560635921000; ![]() =
3722;
=
3722; ![]() = 817695;
= 817695;
![]() = 187221051.
= 187221051.
Система для определения коэффициентов a, b, c параболического уравнения регрессии у = ах2 + bx + с получилась такой:
![]()
Решение этой системы:
a = 0,00173; b = -1,723; c = 532,00.
Следовательно, у = 0,00173x2 – 1,723х + 532.
Коэффициент а близок к нулю, это означает, что полученная парабола не слишком отличается от прямой линии.
Линейное уравнение регрессии, полученное по методу наименьших квадратов, таково: у = -0,887х +435,18.
Графики функций y1(x) = -0,00173x2 – 1,723x + 532 и
y2(х) = -0,887х + 435,18 показаны на рис. 3.5.
Если теперь рассчитать суммы квадратов отклонений:
![]() ,
, ![]() ,
,
которые минимизируются при использовании метода наименьших квадратов, то, после округления, S1 = 23953; S2 = 23481. Разница, конечно, невелика, но рассеяние экспериментальных точек вокруг параболы все - таки меньше, чем вокруг прямой.
3.6. Расчет коэффициентов линейного уравнения регрессии по сгруппированным данным
При
большом объеме n
двумерной выборки ее группируют, получая
т.н. корреляционную
таблицу (табл. 3.5).
Каждый из диапазонов значений составляющих
двумерной выборки разбивают на несколько
интервалов, как правило, одинаковой
ширины. Затем подсчитывают частоты
![]() каждого из получившихся прямоугольников
группировки
– число
пар двумерной выборки, попавших в данный
прямоугольник.
каждого из получившихся прямоугольников
группировки
– число
пар двумерной выборки, попавших в данный
прямоугольник.
Обозначения:
k – число интервалов группировки по составляющей x двумерной выборки;
xi – середина i-го интервала группировки по составляющей x;
ni – частота i-го интервала группировки по составляющей х, i = 1,2,..,k; m - число интервалов группировки по составляющей у;
yj – середина j-гo интервала группировки по составляющей y;
lj – частота j-го интервала группировки по составляющей у, j = 1,2,...,m;
nij – частоты прямоугольников группировки;
n – объем двумерной выборки.
Таблица 3.5
Середины интервалов xi |
Середины интервалов yi y1 y2 … yj … ym |
Сумма частот |
x1 |
n11 n12 … n1j … n1m |
n1 |
x2 |
n21 n22 … n2j … n2m |
n2 |
…………….. |
…………….. |
…………….. |
xi |
ni1 ni2 … nij … nim |
ni |
…………….. |
…………….. |
…………….. |
xk |
nk1 nk2 … nkj … nkm |
nk |
Сумма частот |
l1 l2 … lj … lm |
n |
Следующие соотношения очевидны:
![]()
![]()
![]()
Расчеты, выполненные по сгруппированной выборке, отличаются, конечно, от расчетов, выполненных непосредственно по исходным данным. Разница получается вследствие перехода к серединам интервалов. Но она, как правило, невелика, а вычисления по сгруппированной выборке получаются намного проще.