Цилькер Б.Я., Орлов С.А. Организация ЭВМ и систем
.pdf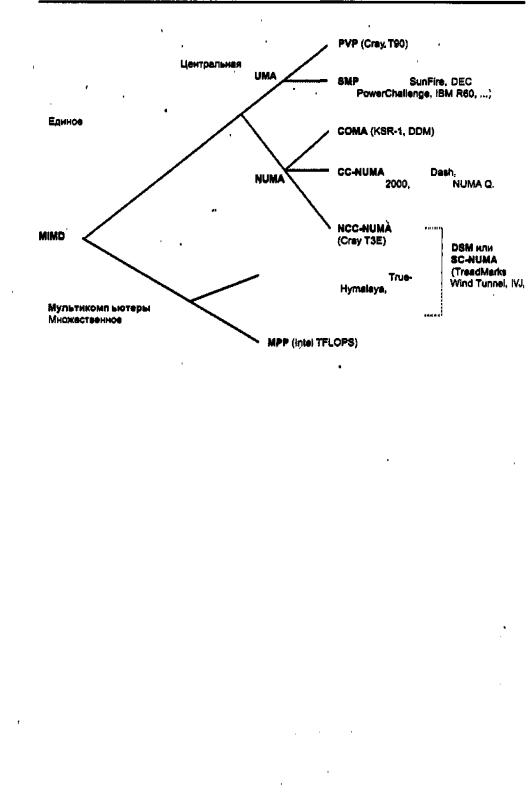

4 9 8 Глава 1 1 . Организация памяти вычислительных систем
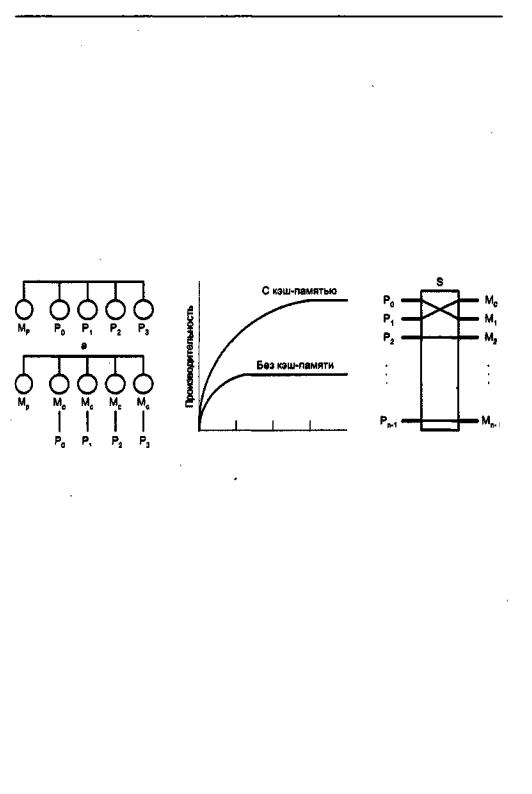
Другим подходом к построению ВС с общей памятью является неоднородный доступ к памяти, обозначаемый как NUMA (Non-Uniform Memory Access). Здесь по-прежнему фигурирует единое адресное пространство, но каждый процессор имеет локальную память. Доступ процессора к собственной Локальной памяти производится напрямую, что намного быстрее, чем доступ к удаленной памяти через коммутатор или сеть. Такая система может быть дополнена глобальной памятью, тогда локальные запоминающие устройства играют роль быстрой кэш-памяти для глобальной памяти. Подобная схема может улучшить производительность ВС, но не в состоянии неограниченно отсрочить выравнивание прямой производитель ности. При наличии у каждого процессора локальной кэш-памяти (рис. 11.3,6) существует высокая вероятность (р > 0,9) того, что нужные команда или данные уже находятся в локальной памяти. Разумная вероятность попадания в локаль ную память существенно уменьшает число обращений процессора к глобальной памяти и, таким образом, ведет к повышению эффективности. Место излома кри вой производительности (верхняя кривая на рис. 11.3, в), соответствующее точке,
вкоторой добавление процессоров еще остается эффективным, теперь перемеща ется в область 20 процессоров, а точка, где кривая становится горизонтальной, -
вобласть 30 процессоров.
В рамках концепции NUMA реализуется несколько различных подходов, обозначаемых аббревиатурами СОМА, CC-NUMA и NCC-NUMA.
В архитектуре только с кэш-памятью (СОМА, Cache Only Memory Archi tecture) локальная память каждого процессора построена как большая кэш-память для быстрого доступа со стороны «своего» процессора [44]. Кэши всех процессо ров в совокупности рассматриваются как глобальная память системы. Собственно глобальная память отсутствует. Принципиальная особенность концепции СОМА выражается в динамике. Здесь данные не привязаны статически к определенному модулю памяти и не имеют уникального адреса, остающегося неизменным в тече ние всего времени существования переменной. В архитектуре СОМА данные пе реносятся в кэш-память того процессора, который последним их запросил, при этом переменная не фиксирована уникальным адресом и в каждый момент времени может размещаться в любой физической ячейке. Перенос данных из одного ло кального кэша в другой не требует участия в этом процессе операционной систе мы, но подразумевает сложную и дорогостоящую аппаратуру управления памя тью. Для организации такого режима используют так называемые каталоги кэшей. Отметим также, что последняя копия элемента данных никогда из кэш-памяти не удаляется.
Поскольку в архитектуре СОМА данные перемещаются в локальную кэш-па мять процессора-владельца, такие ВС в плане производительности обладают су щественным преимуществом над другими архитектурами NUMА. С другой сторо ны, если единственная переменная или две различные переменные, хранящиеся в одной строке одного и того же кэша, требуются двум процессорам, эта строка кэша должна перемещаться между процессорами туда и обратно при каждом дос тупе к данным. Такие эффекты могут зависеть от деталей распределения памяти и приводить к непредсказуемым ситуациям.
Модель кэш-когерентного доступа к неоднородной памяти (CC-NUMA, C a c h e Coherent Non-Uniform Memory Architecture) принципиально отличается от модели

Модели архитектуры памяти вычислительных систем 4 9 9
СОМА. В системе CC-NUMA используется не кэш-память, а обычная физически распределенная память. Не происходит никакого копирования страниц или дан ных между ячейками памяти. Нет никакой программно реализованной передачи сообщений. Существует просто одна карта памяти, с частями, физически связан ными медным кабелем, и «умные» аппаратные средства. Аппаратно реализован ная кэш-когерентность означает, что не требуется какого-либо программного обес печения для сохранения множества копий обновленных данных или их передачи. Со всем этим справляется аппаратный уровень. Доступ к локальным Модулям па мяти в разных узлах системы может производиться одновременно и происходит быстрее, чем к удаленным модулям памяти.
Отличие модели с кэш-некогерентным доступом к неоднородной памяти (NCC-
NUMA, Non-Cache Coherent Non-Uniform Memory Architecture) от CC-NUMA очевидно из названия. Архитектура памяти предполагает единое адресное простран ство, но не обеспечивает согласованности глобальных данных на аппаратном уровне. Управление использованием таких данных полностью возлагается на программное обеспечение (приложения или компиляторы). Несмотря на это обстоятельство, пред ставляющееся недостатком архитектуры, она оказывается весьма полезной при по вышении производительности вычислительных систем с архитектурой памяти типа DSM, рассматриваемой в разделе «Модели архитектур распределенной памяти».
В целом, ВС с общей памятью, построенные по схеме NUMA, называют архи тектурами с виртуалъной общей памятью (virtual shared memory architectures). Данный вид архитектуры, в частности CC-NUMA, в последнее время рассматри вается как самостоятельный и довольно перспективный вид вычислительных сис тем класса MIMD, поэтому такие ВС ниже будут обсуждены более подробно. •
Модели архитектур распределенной памяти
В системе с распределенной памятью каждый процессор обладает собственной памятью и способен адресоваться только к ней. Некоторые авторы называют этот тип систем многомашинными ВС или мульткомпьютерами, подчеркивая тот факт, что блоки, из которых строится система, сами по себе являются небольшими вы числительными системами с процессором и памятью. Модели архитектур с рас пределенной памятью принято обозначать как архитектуры без прямого доступа к удаленной памяти (NORMA, No Remote Memory Access). Такое название следу ет из того факта, что каждый процессор имеет доступ только к своей локальной памяти. Доступ к удаленной памяти (локальной памяти другого процессора) воз можен только путем обмена сообщениями с процессором, которому принадлежит адресуемая память.
Подобная организация характеризуется рядом достоинств. Во-первых, при до ступе к данным не возникает конкуренции за шину или коммутаторы — каждый процессор может полностью использовать полосу пропускания тракта связи с соб ственной локальной памятью. Во-вторых, отсутствие общей шины означает, что нет и связанных с этим ограничений на число процессоров: размер системы огра ничивает только сеть, объединяющая процессоры. В-третьих, снимается проблема когерентности кэш-памяти. Каждый процессор вправе самостоятельно менять свои данные, не заботясь о согласовании копий данных в собственной локальной кэш памяти с кэшами других процессоров.

Мультипроцессорная когерентность кэш-памяти 5 01
Мультипроцессорная когерентность кэш-памяти
Мультипроцессорная система с разделяемой памятью состоит из двух или более независимых процессоров, каждый из которых выполняет либо часть большой программы, либо независимую программу. Все процессоры обращаются к коман дам и данным, хранящимся в общей основной памяти. Поскольку память является обобществленным ресурсом, при обращении к ней между процессорами возника ет соперничество, в результате чего средняя задержка на доступ к памяти увели чивается. Для сокращения такой задержки каждому процессору придается локаль ная кэш-память, которая, обслуживая локальные обращения к памяти, во многих случаях предотвращает необходимость доступа к совместно используемой основ ной памяти. В свою очередь, оснащение каждого процессора локальной кэш-памя-
ть ю приводт к так называемой проблеме когерентности или обеспечения согласо ванности кэш-памяти. Согласно [93, 215], система является когерентной, если каждая операция чтения по какому-либо адресу, выполненная любым из процес соров, возвращает значение, занесенное в ходе последней операции записи по это му адресу, вне зависимости от того, какой из процессоров производил запись по следним.
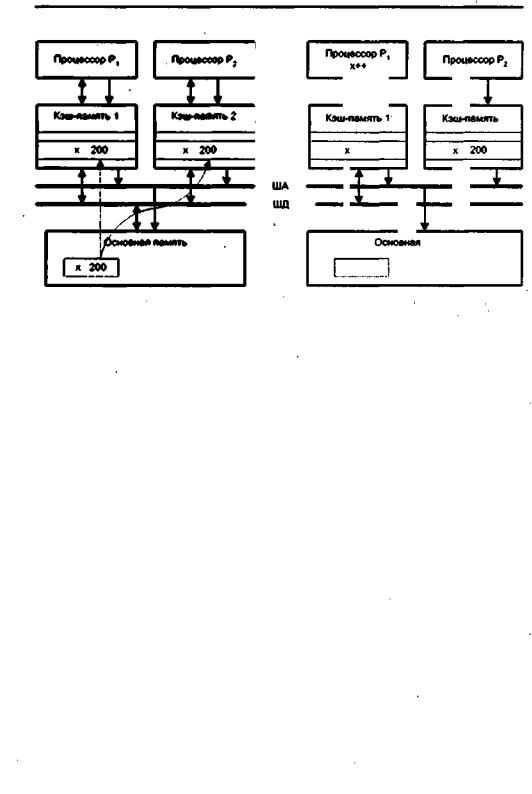
В простейшей форме проблему когерентности кэш-памяти можно пояснить следующим образом (рис 11.5). Пусть два процессора Р1 и Р2 связаны с общей па мятью посредством шины. Сначала обаC процессора читают переменную х. Копии блоков, содержащих эту переменную, пересылаются из основной памяти в локаль ные кэши обоих процессоров (рис. 11.5, а). Далее процессор Р1 выполняет опера цию увеличения значения переменной x на единицу. Так как копия переменной уже находится в кэш-памяти данного процессора, произойдет кэш-попадание и значение х будет изменено только в кэш-памяти 1. Если теперь процессор Р2 вновь выполнит операцию чтения х, то также произойдет кэш-попадание и Р2 получит хранящееся в его кэш-памяти «старое» значение х (рис. 11.5,5).
Поддержание согласованности требует, чтобы при изменении элемента данных одним из процессоров соответствующие изменения были проведены в кэш-памя ти остальных процессоров, где есть копия измененного элемента данных, а также в общей памяти. Схожая проблема возникает, кстати, и в однопроцессорных сиcтемах, где присутствует несколько уровней кэш-памяти. Здесь требуется согласо вать содержимое кэшей разных уровней.
Врешении проблемы когерентности выделяются два подхода: программный
иаппаратный. В некоторых системах применяют стратегии, совмещающие оба подхода.
Программные способы решения проблемы когерентности
Программные приемы решения проблемы когерентности позволяют обойтись без дополнительного оборудования или свести его к минимуму [72]. Задача возлага ется на компилятор и операционную систему. Привлекательность такого подхода в возможности устранения некогерентности еще до этапа выполнения программы,