

28. Применение функций агрегирования, специальные атрибуты в count, скалярные выражения.
Применение функций агрегирования
Запросы могут давать в результате не только группу значений, но и работать по одному полю. Для этого применяются агрегатные функции:
• COUNT определяет количество строк или значений поля, выбранных посредством запроса (и не NULL);
• SUM - арифметическая сумма всех значений поля;
• AVG- среднее значение по выбранному полю;
• MAX, MIN.
Пример:
SELECT SUM (amt) (Имя поля попадает в аргумент)
FROM Orders;
Сумма всех заявок из таблицы Orders. На выходе - единственное значение.
Специальные атрибуты в COUNT (количество)
Когда нужно подсчитать по столбцу, используют DISTINCT (только для различных значений).
SELECT COUNT (DISTINCT snum) FROM Orders;
Для того, чтобы считать целиком строки:
SELECT COUNT (*) FROM Customers;
(и NULL и повторения включаются)
Если мы хотим исключить NULL и сузить до поля, то используется ALL:
SELECT COUNT (ALL rating) FROM Customers;
Подсчитываем исключая NULL, но включая повторения.
Скалярные выражения
До сих пор в аргументах агрегатных функций было одно поле, возможно и выражение:
SELECT MAX (binc + amt) FROM Orders;
Для каждой строки сначала берется сумма двух полей, а потом из всех таких сумм - МАХ.
29. Предложения group by и having.
Предложение GROUP BY
Предложение GROUP BY позволяет определить подлинность значений отдельного поля в терминах другого поля и применять функции агрегирования к полученному подмножеству. Это дает возможность комбинировать поля и агрегатные функции в одном SELECT. Например, предположим, что нужно найти наибольший заказ из тех, что получил каждый из продавцов:
SELECT snum, MAX (amt)
FROM Orders
GROUP BY snum;
При этом результат - несколько строк.
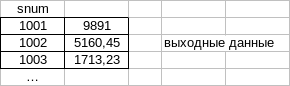
GROUP BY применяет агрегированные функции отдельно к каждой из серии групп, которые определяются общим значением поля (один и тот же snum). Справа - МАХ значение на группу (с номером 1001).
Возможно, применить GROUP BY к нескольким полям:
SELECT snum, odate, MAX (amt)
FROM Orders
GROUP BY snum, odate;
Запрос дает наибольший заказ сделанный каждому продавцу на каждую дату.
Предложение HAVING
Допустим, нам нужно усложнить пример и сказать, что выбираются только покупки, превышающие $ 3000. Т.е. нужно применить WHERE MAX (amt)>3000.00, но WHERE работает с каждой единственной строкой до вычисления функции, а агрегированные функции работают в терминах групп строк и использование WHERE неприемлемо (получим ошибку).
Для фильтрации групп, также как WHERE работает для отдельных строк, применяется специальное предложение HAVING:
SELECT snum, odate, MAX (amt)
FROM Orders
GROUP BY snum, odate
HAVING MAX (amt)>3000.00;
Выводы: HAVING похоже на WHERE, но если WHERE действует на отдельные записи до GROUP BY и функций, то HAVING работает с группами после действия GROUP BY.
Ограничение на агрегированные функции
В ANSI версии SQL недопустима вложенность, т.е. агрегатная функция в качестве аргумента агрегатной функции:
SELECT odate, MAX (SUM(amt))
FROM Orders
GROUP BY odate;