

Реализация абстрактных данных с помощью модуля счетчика
Модуль может быть рассмотрен как введение нового уровня объектов в программу – абстрактного уровня. В абстрактных терминах, модуль содержит новые, высокоуровневые объекты, чем те, что были доступны прежде, и когда эти объекты используются (через процедуры модуля), нет необходимости вникать в низкоуровневые детали.
Исходя из дисциплины доступа к данным в модуле, функции частных значений его процедур могут быть определены полностью из текста модуля безотносительно к данным, определенным вне модуля. Однако, необходимо рассмотреть два различных взгляда – проектировщика модуля и пользователя.
Для работы над модулем, проектировщик нуждается в комментариях, которые описывают действие процедур модуля над его скрытыми данными, которые иногда называются конкретными данными. Поскольку пользователь модуля не может ссылаться на эти данные, для него необходимы комментарии, объясняющие как использовать процедуры модуля в терминах абстрактных данных, реализуемых модулем.
В модуле счетчика комментарии проектировщика будут описывать действие каждой процедуры в терминах Ones, Tens и Hundreds, тогда как пользовательские комментарии раскрывают эффект тех же процедур в терминах абстрактного объекта, названного Counter. Counter не появляется, как другие переменные в состоянии выполнения, потому что он не был описан и не может быть использован напрямую в операторах вызывающей программы. Вместо этого, программист устанавливает значение счетчика через процедуры Start и Bump и обращается к его значению с помощью процедуры Value.
Например, комментарий к вызову Start
{обнулить счетчик}
может быть заменен на более точные комментарии
{конкретный: Ones, Tens, Hundreds := ‘0’, ‘0’, ‘0’ }
{абстрактный: Counter := 0 }
Первый комментарий – одновременное присваивание, которое обобщает действие операторов CF Pascal. Но второй комментарий использует переменную, которая может рассматриваться как целочисленная, не доступная в CF Pascal.
Значение абстрактного объекта может быть сконструировано отображением переменных значений переменных, использованных для представления объекта значению объекта. Это отображение является частью функции представления (representation function), которая ставит в соответствие (конкретные) состояния (абстрактным) состояниям. Функция представления выделяет абстрактное значение из состояния выполнения и скрывает переменные, которые составляют абстрактный объект (который именуется новым идентификатором). Например, в ContingBlanksInText, следующие состояния выполнения могут существовать после вызова Value.
(Абстрактное состояние)
{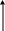 Counter210,
Ch#,
X1002,
X101,
X10}
Counter210,
Ch#,
X1002,
X101,
X10}
функция представления
{Hundreds2, Tens1, Ones0, Ch#, X1002, X101, X10}
(Конкретное состояние)
(INPUT и OUTPUT опущены для экономии места)
Для того, чтобы определить функцию представления формально, будет удобно определить функцию Number, которая ставит в соответствие список символов, натуральному числу в десятичной системе исчисления, которое они представляют. Например:
Number(<’0’, ‘0’, ‘0’>) = 0 (ноль)
Number(<’0’, ‘1’, ‘3’>) = 13 (тринадцать)
Функция представления R для приведенной выше абстракции счетчика может быть записана следующим образом:
R = {(s, t): t такое же как s за исключением того, что оно содержит новый идентификатор Counter и t(Counter) = Number(<Hundreds(s), Tens(s), Ones(s)>)
и t не содержит идентификаторов Hundreds, Tens и Ones}
R отображает три символьных переменных в одну целочисленную.
Конкретная функция частного значения для Value:
V100, V10, V1 := Hundreds, Tens, Ones
Абстрактная функция:
(0 <= Counter <= 999 ->
символьное представление разряда сотен Counter,
символьное представление разряда десятков Counter
символьное представление разряда единиц Counter)
Даже если абстрактная функция частного значения определена только для цифр, нет требования в конкретной функции частного значения, чтобы Hundreds, Tens и Ones были цифрами. Если Value было выполнено до Start, обращение к значениям в Hundreds, Tens и Ones произойдет до инициализации и функция возвратит неизвестное значение.
Сложности в конкретной функции частного значения для Bump возникают не только из арифметики, которая должна быть симулирована, если Ones, Tens и Hundreds цифры, но и обработки случаев, когда она или более этих переменных цифрами не являются.
((‘0’ <= Ones < ‘9’ -> next(Ones)) |
(Ones = ‘9’ AND ‘0’ <= Tens < ‘9’ ->
Ones, Tens := ‘0’, next(Tens)) |
(Ones = ‘9’ AND Tens = ‘9’ AND ‘0’ <= Hundreds < ‘9’ ->
Ones, Tens, Hundreds := ‘0’, ‘0’, next(Hundreds)) |
(Ones = ‘9’ AND Tens = ‘9’ AND Hundreds = ‘9’ -> )) |
(‘0’ > Ones OR Ones > ‘9’ -> )
где next определяется как:
next = {(x, y): x и y – цифры и у следует за x в последовательности 01234567890}
С другой стороны, абстрактный комментарий для Bump вполне компактен.
(0 <= Counter <= 999 -> Counter := Counter + 1) |
(Counter < 0 OR Counter >= 999 -> )
Пример использования модуля очереди
Сортировка; обработка множества данных в заданном порядке; создание списков задач на последовательное выполнение
Методы тестирования ПО
Тестирование программы (совместно с разработкой программы)
Думайте серьезно о вашем плане сборки и о вашей конечной программе. Составьте правильную последовательность программ для получения положительной обратной связи на каждом этапе сборки программы.
Разработайте план тестирования. Создайте программы с временными операторами WRITE для получения выразительных результатов выполнения, несмотря на то, что это не окончательные результаты, необходимые вам.
Для каждого шага вашего плана сборки проведите тестовые испытания, и не забывайте об исключительных ситуациях, даже несмотря на их малую вероятность.
Структурное тестирование
Тестирование программ чтобы иметь уверенность в том, что проектирование и разработка развиваются так, как запланировано, является разумным подходом. Не всегда понятно, какие части проекта следует собирать в первую очередь, какую отладочную информацию распечатывать, самое сложное - какие тестовые данные выбрать для отладки, чтобы иметь возможность контролировать появление ошибок и т.д. Нет гарантии, что тестирование найдет все возможные трудности программы.
Каждый, кто занимался практическим программированием согласится с утверждением Edsger Dijkstra что тестирование позволяет обнаружить присутствие ошибок, а не их отсутствие.
Тем не менее, сильной стороной тестирования является его более или менее механистичная природа, поэтому важно иметь систематический подход к выбору данных для тестирования.
При структурном тестировании данные выбираются исходя из структуры программы. Простейший вариант – таким образом подобрать тестовые данные, чтобы каждое выражение выполнилось хотя бы однажды. Единственный аргумент в пользу такого подхода следующий: если при тестировании выражение не было выполнено ни разу, значит, там могут скрываться ошибки, которые могут проявиться позднее. Обратное не верно, поскольку даже если каждое выражение было выполнено, все равно в коде могут присутствовать ошибки, которые не были выявлены тестами.
При всех его недостатках, структурное тестирование предлагает некий систематический подход к подготовке тестовых данных. Если у программиста есть идеи, что в структуре приложения или какие части кода могут быть источником ошибок и требуют углубленного тестирования, тесты, специально подготовленные для таких случаев, могут быть очень полезны. Когда идеи отсутствуют, структурное тестирование позволяет частично решить проблему.
Существует два основных вида тестирования: функциональное и структурное. При функциональном тестировании программа рассматривается как "черный ящик" (то есть ее текст не используется). Происходит проверка соответствия поведения программы ее внешней спецификации. Критерием полноты тестирования в этом случае является перебор всех возможных значений входных данных, что невыполнимо. Поскольку исчерпывающее функциональное тестирование невозможно, речь может идти о разработки методов, позволяющих подбирать тесты не "вслепую", а с большой вероятностью обнаружения ошибок в программе. При структурном тестировании программа рассматривается как "белый ящик" (т.е. ее текст открыт для пользования). Происходит проверка логики программы. Полным тестированием в этом случае будет такое, которое приведет к перебору всех возможных путей на графе передач управления программы (ее управляющем графе). Если ограничиться перебором только линейных не зависимых путей, то и в этом случае исчерпывающее структурное тестирование практически невозможно, т. к. неясно, как подбирать тесты , чтобы обеспечить "покрытие" всех таких путей. Поэтому при структурном тестировании необходимо использовать другие критерии его полноты, позволяющие достаточно просто контролировать их выполнение, но не дающие гарантии полной проверки логики программы. Но даже если предположить, что удалось достичь полного структурного тестирования некоторой программы, в ней тем не менее могут содержаться ошибки, т.к. 1) программа может не соответствовать своей внешней спецификации, что в частности, может привести к тому, что в ее управляющем графе окажутся пропущенными некоторые необходимые пути ; 2) не будут обнаружены ошибки, появление которых зависит от обрабатываемых данных (т.е. на одних исходных данных программа работает правильно, а на других - с ошибкой). Таким образом, ни структурное, ни функциональное тестирование не может быть исчерпывающим. Чтобы увеличить процент обнаружения ошибок при проведении функционального и структурного тестирования используют средства автоматизации тестирования.