

Кодирование
1) Классификация методов кодирования. Конструктивные методы кодирования источников сообщений.
Под кодированием понимают преобразование сообщений дискретного источника для передачи их по дискретному каналу. Для восстановления принятого сообщения применяется обратная процедура – декодирование. Устройства, осуществляющие кодирование и декодирование – кодер и декодер. Вместе – кодек.
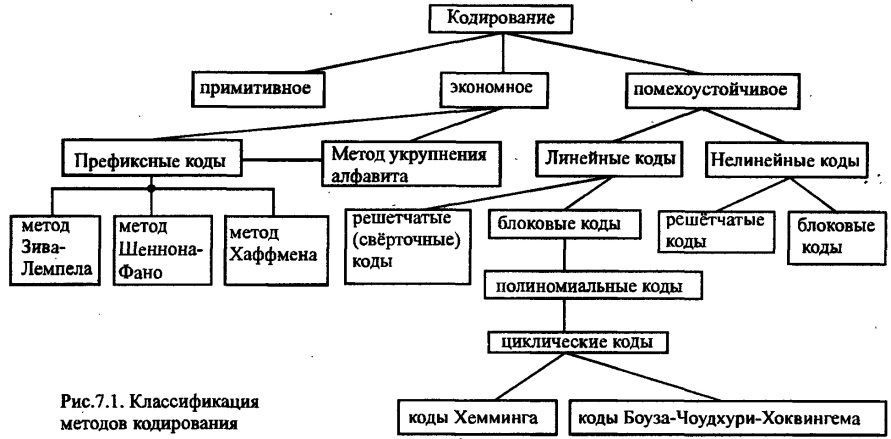
Классификация методов кодирования:
1) примитивное
2) экономное
а) префиксные коды
- метод Зива-Лемпела
- метод Шеннона-Фано
- метод Хаффмена
б) метод укрупнения алфавита
3) помехоустойчивое
а) линейные коды
- решётчатые (свёрточные) коды
- блоковые коды
∙ полиномиальные коды
§циклические коды
- Коды Хемминга
- Коды Боуза-Чоудхури-Хоквингема
б) нелинейные коды
- решётчатые коды
- блоковые коды
Примитивное или безызбыточное кодирование применяется для согласования алфавита источника и алфавита канала. Избыточность дискретного источника, образованного выходом примитивного кодера, равна избыточности источника на входе кодера. Примитивное кодирование используется так же в целях шифрования передаваемой информации и повышения устойчивости работы системы синхронизации.
Экономное кодирование, или сжатие данных, применяется для уменьшения времени передачи информации или требуемого объёма памяти при её хранении. При экономном кодировании избыточность источника, образованного выходом кодера, меньше, чем избыточность источника на входе кодера. Экономное кодирование применяется в ЭВМ.
Помехоустойчивое, или избыточное кодирование применяется для обнаружения и (или) исправления ошибок, возникающих при передаче по дискретному каналу. Отличительное свойство помехоустойчивого кодирования – избыточность источника, образованного выходом кодера, больше, чем избыточного источника на входе кодера. Помехоустойчивое кодирование используется в различных системах связи, при хранении и передаче данных в сетях ЭВМ, в бытовой и профессиональной аудио- и видеотехнике, основанной на цифровой записи.
Конструктивные методы кодирования источников сообщений.
Эффективное, или экономичное кодирование означает достижение минимального значения средней длины кода символа.
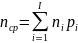
Доказано, что nср не может быть меньше, чем энтропия nср >= H(Z)
Код должен быть неравномерным. Средняя длина неравномерного кода будет минимизироваться тогда, когда с более вероятными сообщениями источника будут сопоставляться более короткие комбинации канальных символов.
У неравномерного кода на приёмной стороне оказываются неизвестными границы этих комбинаций. Декодирование может оказаться неоднозначным. (Если с буквой А сопоставлена комбинация 0, с буквой Б – 1, а с буквой С – 10, то невозможно определить по принятой комбинации 10, передавались ли буква С или пара букв А и Б). Однозначное декодирование будет обеспечено, если ни одно кодовое слово не является началом другого кодового слова. Такие коды называют префиксными.
В телеграфии известна так называемая азбука Морзе. Сокращение nср здесь достигается за счёт назначения часто встречающимися символам коротких кодов (одна “точка” или одно “тире”). Наоборот, редкие символы имеют длинные коды. Противоположность азбуке Морзе представляет код Бодо. Каждый символ кодируется пятью двоичными разрядами (нормальное и примитивное кодирование, длина кода – постоянная величина).
Кодирование по методу Шеннона – Фано – не абсолютно оптимальное, но достаточно эффективное.
Процедура кодирования – циклическая.
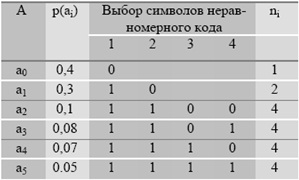
1. Символы аi упорядочиваются по убыванию частоты – вероятности pi(аi).
2. Множество А разбивается на 2 группы символов, так, что бы общие вероятности в этих группах были как можно ближе.
3. В коды символов первой группы записывается 0, в коды второй группы – 1.
После этого действия 2 и 3 повторяются. Т.е. далее следует новое деление в каждой группе, и т.д. до тех пор, пока очередные группы не окажутся односимвольными.
Кодирование по методу Хаффмена гарантирует оптимум для заданного множества {pi}
Процедура кодирования циклическая и более сложная, чем у Шеннона-Фано.
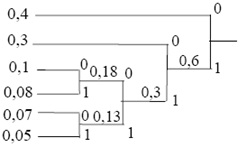
1. Символы zi упорядочиваются по убыванию вероятности pi
2. Два последних символа объединяются в группу-пару, соотверствующую вспомогательному символу с суммарной вероятностью. Если суммируемые вероятности представляют исходные значения pi, это специально отмечается («*»). Здесь – конец формирования кода соответствующего символа.
Далее пп. 1 и 2 повторяются. При этом в общем случае происходит переупорядочивание вероятностей pi. В конце концов суммарная вероятность достигает значения 1 и процесс заканчивается.
Если источник не имеет памяти, то P(ai, aj)=P(ai)P(aj).
Если же исходный источник имеет память, то, P(a1, a2)!=P(a2 , a1), что будет учтено при последующем оптимальном префиксном кодировании для нового источника с укрупнённым алфавитом. При такой схеме кодирования остаётся неучтённой статистическая зависимость между укрупнёнными сообщениями. Поэтому алфавит необходимо укрупнять до тех пор, пока избыточность, вызванная статистическими связями между укрупнёнными сообщениями, не станет достаточно малой. Часто о некотором избыточном источнике известен лишь его алфавит А, но не известно распределение вероятностей последовательностей символов этого источника.
Метод сжатия Зива-Лемпела, применяемый в ЭВМ для архивирования файлов.
Последовательность символов источника разбивается на кратчайшие различимые цепочки, которые не встречались раньше, а затем эти цепочки кодируются равномерным кодом.

Фактически для сжатия файлов используется модифицированный алгоритм, называемый алгоритмом сжатия Зива-Лемпела-Велча.