

Алгоритм обучения anfis
Если параметры предпосылок фиксированы, то выход всей сети является линейной комбинацией параметров заключений. В символах этот выход может быть записан в виде
 (7)
(7)
![]() (8)
(8)
![]() (9)
(9)
и
он представляет линейную комбинацию
параметров заключений
![]() (i=1,2;
j=0,1,2).
Гибридный алгоритм настраивает параметры
заключений
при прямом распространении сигнала
и параметры предпосылок
(i=1,2;
j=0,1,2).
Гибридный алгоритм настраивает параметры
заключений
при прямом распространении сигнала
и параметры предпосылок
{ai, bi, ci} при обратном распространении сигнала. При прямом распространении сеть передает входные сигналы в прямом направлении до слоя 4, в котором параметры заключений идентифицируются с помощью метода наименьших квадратов или путем псевдоинверсии матрицы. При обратном распространении сигнал ошибки передается в обратном направлении, и параметры предпосылок обновляются с помощью метода обратного распространения ошибки.
В связи с тем, что обновления параметров предпосылок и заключений происходят раздельно, в гибридных обучающих алгоритмах можно ускорить процесс вычислений путем использования различных вариантов
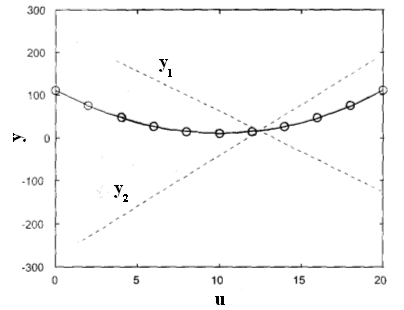
Рис. 2
градиентных методов или других методах оптимизации для настройки параметров предпосылок.
Пример (ANFIS). Посмотрим, как сеть может аппроксимировать нелинейную функцию. Рис. 2 показывает изображение множества данных и результирующую интерполирующую кривую. Одиннадцать точек данных (кружки на рисунке) были предъявлены сети ANFIS. В начале были
Рис. 2
выбраны параметры двух гауссовских функций принадлежности (рис. 3, слева). Они занимали весь универсум входа с 50 процентным перекрытием между собой. Другим выбором начального шага проектирования был выбор числа правил, т. е. двух правил. В результате обучения эти правила приняли следующий вид,
Если u есть A1 то y1 = -18,75u + 249,1, (10)
Если u есть A2 то y2 = 23,55u – 276,7. (11)
Правой стороне правил соответствуют две прямые линии, также нарисованные на рис. 2, одна из которых имеет положительный, а другая отрицательный наклон. Интерполирующая кривая является результатом нелинейной комбинации этих двух прямых. Вес значений прямых линий в каждой точке интерполяционной кривой определяется видом функций принадлежности входа (рис. 3, справа), который они приняли после обучения.
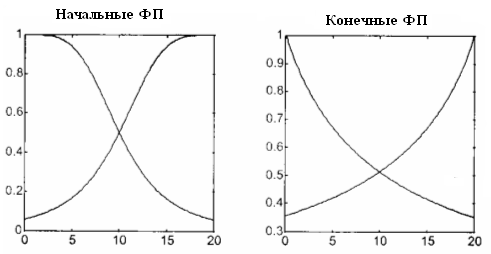
Рис. 3
Одиннадцать точек данных были предъявлены сети 100 раз и каждый раз алгоритм обучения ANFIS обновлял параметры предпосылок, что определило форму и положение двух функций принадлежности, и параметры заключений, что в свою очередь определило наклон и постоянные двух прямых линий, описываемых уравнениями в правой части правил. Начальные значения коэффициентов для этих уравнений были взяты равными нулю.
Генетические алгоритмы
Проблема использования для обучения сети алгоритма обратного распространения ошибки и оптимизации по методу наименьших квадратов состоит в том, что их применение может быть причиной останова оптимизационного процесса в точках локального минимума нелинейной целевой функции (критерия качества сети). Дело в том, что упомянутые методы основаны на вычислениях производных и являются градиентными методами. Генетические алгоритмы − естественный отбор самого подходящего (выживает наиболее приспособленный!) − не требуют вычисления производных и являются стохастическими оптимизационными методами, поэтому менее склонны к останову оптимизационного процесса в локальных минимумах. Эти алгоритмы могут быть использованы для оптимизации, как структуры, так и параметров в нейронных сетях. Специальная область их применения связана с определением параметров нечетких функций принадлежности.
Генетические алгоритмы имитируют естественную эволюцию популяций. Суть этих алгоритмов такова. В начале генерируют возможные различные решения, используя генератор случайных чисел. Затем происходит тестирование (оценка) этих возможных решений с точки зрения поставленной задачи оптимизации, т.е. определяется, насколько хорошее решение они обеспечивают. После чего часть лучших решений отбирается, а другие отсеваются (выживает наиболее приспособленный). Затем отобранные решения подвергаются процессам репродукции (размножения), скрещивания и мутации, чтобы создать новую генерацию (поколение, потомство) возможных решений, которая, как ожидаемо, будет более подходящей, чем предыдущая генерация. Наконец, создание и оценивание новых генераций продолжатся до тех пор, пока последующие поколения не будут давать более подходящих решений. Такой алгоритм поиска решений из широкого спектра возможных решений оказывается предпочтительнее с точки зрения окончательных результатов, чем обычно используемые алгоритмы. Платой является большой объем вычислений. Рассмотрим составные части генетического алгоритма.