

4. Дискретизация аналоговых сигналов. Ошибки дискретизации.
Основной причиной преобразования аналоговой информации в дискретную форму стало невозможность улучшения качества передачи данных в аналоговой форме. Поэтому на смену аналоговой техники передачи пришла цифровая техника. В этой технике используется дискретная модуляция исходных, непрерывных во времени аналоговых процессов. Рассматриваемый принцип импульсно кодовой модуляции применяют в телефонии. В этом случае дискретизация происходит как по времени, так и по амплитуде. Амплитуда исходной непрерывной функции измеряется через заданный период времени, за счёт этого происходит дискретизация по времени, затем каждый замер представляется в виде двоичного числа, определённой разрядности, что означает дискретизацию по значению. Устройство, которое выполняет эту функцию, называется АЦП. После чего замеры передаются по линиям связи в виде 0 и 1. При этом применяется те же методы кодирования, что и при изначально дискретной информации. На принимающей стороне коды преобразуются в исходный последовательности, а ЦАП производит декодирование в аналоговый сигнал.
Дискретная модуляция основана на теории отображения Найквиста. В соответствии с этой теорией аналоговая непрерывная функция, переданная в виде последовательности ей дискретных значений, может быть точно восстановлена, если частота её дискретизации была в 2 и более раз выше частоты самой высокой гармоники спектра её функции. В том случае, если это условие не выполняется, то восстановленная функция будет существенно отличаться от исходной.
Ошибка интерполяции равна разности исходного задержанного процесса и восстановленного процесса, причем задержка выбирается такой, чтобы ошибка была минимальной.
∆инт(t) = x(t - tопт) - xв(t).
В системах с обратной связью задержка восстановленного сигнала нежелательна. Она может привести не только к увеличению ошибок моделирования, но и к потере устойчивости модели. В этом случае ошибка определяется как:
∆полн(t) = x(t) - xв(t)
и называется полной ошибкой.
Так как ошибки зависят от времени, то для их числовой оценки используется среднеквадратическая ошибка, усредненная за время Т, в течение которого измеряется ошибка.
5. Эффективное кодирование, назначения, способы реализации, основные ограничения.
Этот вид кодирования используется для уменьшения объемов информации на носителе - сигнале.
Для кодирования символов исходного алфавита используют двоичные коды переменной длины: чем больше частота символа, тем короче его код. Эффективность кода определяется средним числом двоичных разрядов для кодирования одного символа – lср по формуле

где k – число символов исходного алфавита;
ns – число двоичных разрядов для кодирования символа s;
fs – частота символа s; причем

При эффективном кодировании существует предел сжатия, ниже которого не «спускается» ни один метод эффективного кодирования - иначе будет потеряна информация. Этот параметр определяется предельным значением двоичных разрядов возможного эффективного кода – lпр:
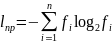
где n – мощность кодируемого алфавита,
fi – частота i-го символа кодируемого алфавита.
Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмена. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды.
Метод Хаффмена построения эффективного кода реализуется в два этапа: сворачивание кода и разворачивание кода.
1. Сворачивание кода.
Формируют начальную последовательность символов источника информации путём упорядочивания по неубыванию вероятностей их появления на выходе источника. Последние два символа последовательности объединяют в один с вероятностью появления на выходе источника информации, равной сумме вероятностей появления каждого из этих символов. Эту операцию повторяют итеративно до тех пор, пока в последовательности не останется только лишь два символа.
2. Разворачивание кода.
Одному символу приписываем код 0, а другому 1. Каждый символ разбивается на две последовательности в порядке, обратном порядку сворачивания кода. Эту операцию повторяют итеративно для каждой из полученных двух последовательностей до тех пор, пока имеется последовательность, состоящая более чем из одного символа. При этом кодовая комбинация каждой дочерней последовательности получается путём приписывания к кодовой комбинации родительской последовательности символа 0 или 1 справа.