

Автоматы с магазинной памятью.
МП-автомат – это конечный автомат, снабженный дополнительным стеков (магазином) для хранения промежуточной информации потенциально бесконечного объема
МПА=<S,S0,F,∑,Г, б>
S – множество внутренних состояний автомата
F – множество допускающих состояний
S0 – начальное состояние автомата
∑ - конечный алфавит выходных символов
Г – конечный алфавит магазина
Б – функция переходов
Рекурсивные обходы деревьев.
Рекурсивный обход «»в глубину»
Void VisitNode (TreeNode node)
{ foreach(TreeNode childNode in node.Childs)
{VisitNode(child);}
ApplySemanticRules(node);
}
Синтаксически управляемая трансляция не задает порядка вычисления атрибутов. Пригоден любой порядок, который определяет атрибуты а после всех атрибутов от которых зависит а.
Автоматные грамматики.
Грамматики типа 3 (регулярные языки) – грамматики, с правилами вида Аa; ABa; A. Имеют линейные по времени методы распознавания.
П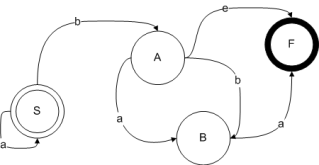 ример:
ример:
SaS |bA
AaB|
BbA|a
Семантические деревья.
Я вляется
«сжатым» деревом разбора, в котором
операторы размещены во внутренних
узлах, а операнды оператора представлены
дочерними ветвями узла. Проверяется
наличие семантических ошибок в исходной
программе и накапливается информация
о типах для стадии генерации кода
вляется
«сжатым» деревом разбора, в котором
операторы размещены во внутренних
узлах, а операнды оператора представлены
дочерними ветвями узла. Проверяется
наличие семантических ошибок в исходной
программе и накапливается информация
о типах для стадии генерации кода
Связь синтаксических деревьев и генерация кода. Пример (трансляция в p-code).
Обзор стратегий синтаксического анализа.
Нисходящая стратегия: восстановление цепочки вывода корня к листьям. Находим те продукции, которые нужно использовать для подстановки вместо каждого нетерминала, стоящего в узлах синтаксического дерева, правых частей этих продукций
Восходящая стратегия: начиная от терминальной строки найти т.н. связку – правую часть продукции грамматики, которую нужно заменить нетерминалом (левой частью продукции) для получения нового узла синтаксического дерева.
Универсальные методы разбора (алгорит Кока-Ягнерса-Касами, алгоритм Эрли)
Языки (определение).
Языком L над словарем v называется произвольное множество цепочек над этим словарем, т.е. L€ V*. Операции: объединения, пересечения, дополнения, конкатенации.
V={a,b}, V*={e,a,b,aa,ab,ba,bb,…}
Определение токенов. Регулярные языки.
Базис:
Константы ξ и 0 являются регулярными выражениями определяющие языки L(ξ)= {ξ} и L(0)=0
Если α – произвольный символ, то а – регулярное выражение, определяющее язык L(a)={a}
Если E и F – регулярные выражения, то E+F, EF. E*, (E) – регулярные выражения
Теория Ноама Хомского.
Объяснение механизмов понимания человеком смысла фраз естественного языка. Основная идея: структура текста определяет смысл предложения
Лексические ошибки.
Ошибкой лексического анализа является невозможность распознать лексему по заданному возможному шаблону
Роль синтаксического анализатора.
Задачей синтаксического анализатора является: по заданной терминальной цепочке восстановить ее вывод из начального символа по грамматике
Операции над языками.
Операции: объединение, пересечение, дополнение, конкатенация (L1L2={αβ|α€L1, β€L2})
Замыкание Клини L*=L0UL1UL2U….
Позитивное замыкание языка L+=L*-{ξ}
Определение ε-НКА.
A=<Q,∑,(сигма)<q0,F>
Q – множество состояний
∑ - множество входных символов
q0- начальное состояние
F, подмножество Q- множество допускающих состояний
(сигма)- функция переходов
Моделирование ε-НКА. Пример в псевдокоде.
Bool NFA()
{ S=EClosure(s0);
C=getnextchar();
While (c!=eof)
{s=EClosure(move(S,c));
c=getnrxtchar();
}
Return (SΩF!=0);
}
Пример трансляции (генерации кода).
Генератор промежуточного кода:
T1:=intToReal(60)
T2:=id3*T1
T3:=id2+T2
Id1:=T3
Оптимизация кода:
T1:=id3*60.0
Id1:+id2+T1
Генератор кода:
Movf r1,id3
Mulf r1,60.0
Movf r2, id2
Addf r1,r2
Movf id1,r2
Роль лексического анализатора. Токены. Шаблоны. Лексемы.
Задача: чтение символов исходного текста программы и выдача последовательности токенов.
Удаление комментариев и не несущих смысловой нагрузки пробелов (табуляции и т.п.) из строки исходного кода.
Согласование сообщений об ошибках компиляции и текста исходной программы
Реализация макросов и директив препроцессора
Токен |
Лексема |
Шаблон |
Const |
Const |
Const |
If |
If |
If |
Relation |
<,>,<=,>=,=<,<> |
< или <= или >= или… |
Id |
Pi,count,p2 |
Буква за которой следуют буквы и цифры |
Num |
3,14 , 0, -1 |
Любая числовая константа |
Literal |
‘this is a text’ |
Любые символы между кавычками, исключая сами кавычки |
Стратегии обработки ошибок синтаксического анализа.
Режим паники
Уровень фразы
Продукции ошибок
Глобальная коррекция
Построение ДКА из ε-НКА.
Строим таблицу переходов Dtran дляD. Каждое сотояние ДКА является множеством состояний НКА, Dtrat строится так, чтобы D «параллельно» моделировал все возможные перемещения N по входной строке.
Устранение левой рекурсии.
Вход: А->Aα |β
Правило:
A->βA’
A’->αA’ | ξ
Атрибутные грамматики. Пример (управление мобильным роботом).
Это расширение контекстно-свободной грамматики Хомского, где каждому символу (терминальному и нетерминальному) порождающей КС-грамматики может быть приписано конечное множество семантических параметров – атрибутов, которые принимают некоторые значения.
Пример:
Seq->seq instr | begib
Instr -> east | north | west | south
Begin west south east east noth noth
№ |
Продукция |
Семантическое правило |
1 |
Seq->begin |
Seq.x=0 Seq.y=0 |
2 |
Seq->seq1instr |
Seq.x=seq1.x+instr.dx Seq.y=seq1.y+instr.dy |
3 |
Instr->east |
Instr.dx=1 Instr.dy=0 |
4 |
Instr->west |
Instr.dx=-1 Instr.dy=0 |
5 |
… |
.. |
6 |
… |
.. |
Правила преобразования регулярного выражения в автомат.
Любой язык, определяемый регулярным выражением, можно задать некоторым конечным автоматом.
Построение -НКА, обладающего свойствами:
имеет ровно одно допускающее состояние.
нет дуг, ведущих в начальное состояние.
нет дуг, выходящих из допускающего состояния.
Построение деревьев вывода цепочек.
Корень дерева всегда помечен начальным нетерминальным символом грамматики.
Каждый внутренний узел помечен каким-либо нетерменальным символом
Листья дерева содержат терминальные узлы
Моделирование ДКА. Пример на алгоритмическом языке.
Bool DFA()
{s=s0;
c=getnextchar();
while (c!=eof)
{s=move(s,c);
C=getnextchar();
}
Return(s€F);
}
Классы грамматик Хомского. Краткий обзор.