

Построение графиков
По данным из таблицы требуется построить зависимости времени выполнения от сложности задачи для равномерно и сбалансировано распределенной нагрузки.
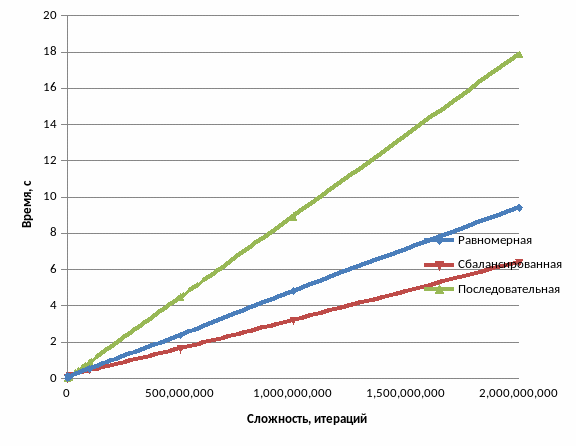
Рисунок 2.15. График времени выполнения вычислений.
Полученные данные и построенные на их основании графики наглядно демонстрируют эффект от применения распараллеливания. Также видно, что в связи с тем, что один из узлов намного производительнее другого, балансировка смогла существенно улучшить временные показатели вычислений.
На следующем графике (Рисунок 2.16) показана зависимость времени вычисления от числа параллельных процессов при одинаковой сложности задачи. Очевидно, что когда число процессов превышает число ядер, накладные расходы на обмен данными между процессами ухудшают временные показатели. При определённых условиях увеличение числа процессов может сделать параллельный алгоритм по скорости хуже последовательного.

Рисунок 2.16. Время выполнения программы сложностью 1М итераций
Лабораторная работа №2
Подготовка рабочего места для выполнения лабораторной работы №2
Перед выполнением лабораторной работы №2 требуется получить доступ к кластеру, запросив его у администратора. Возможно выполнение лабораторной работы всей группой от имени одного пользователя. После получения имени и пароля для доступа через протокол SSH и загрузки свободно распространяемых программ PuTTY, WinSCP, не требующих установки на рабочей станции, можно приступить к работе.
Описание хода лабораторной работы №2 Подключение к кластеру миит т-4700
Доступ к кластеру осуществляется через протоколы SSH, SFTP. Для этого можно воспользоваться PuTTY, WinSCP и другими клиентами. В данном описании будет использоваться WinSCP. Требуется запустить WinSCP.exe и создать новую сессию. В открывшемся окне ввести данные о подключении: название хоста, номер порта, имя пользователя и пароль, как показано на рисунке 2.17.
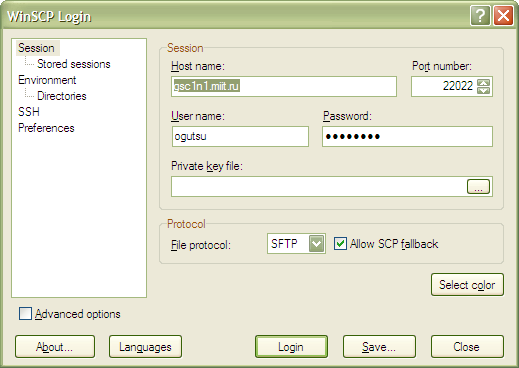
Рисунок 2.17. Скриншот программы WinSCP.
Компиляция программы
Для компиляции mpi-программы на linux-кластере используется программа-компилятор. В mpich есть компиляторы для языков C, C++, Fortran. Чтобы откомпилировать программу написанную на языке C++, требуется, после того как файл с исходником перенесён в папку пользователя с помощью WinSCP, послать через терминал команду общего вида:
<утилита-компилятор> -o <исполняемый файл MPI-программы> <исходный файл MPI-программы>
В нашем случае необходимо выполнить следующую команду:
ogutsu@gsc1n1:~> /share/mpi/mvapich2-1.2p1-pgi/bin/mpicxx -o /mnt/scratch/home/ogutsu/cpi.mpi /mnt/scratch/home/ogutsu/pi.c
Где, mpicxx – утилита-компилятор для C++, после ключа -o следует путь к исполняемому файлу /mnt/scratch/home/ogutsu/cpi.mpi, который будет сформирован в результате компиляции, и после пробела указан путь к исходному коду MPI-программы /mnt/scratch/home/ogutsu/pi.c.
Листинг программы mpi-программы
#include "mpi.h"
#include <stdio.h>
#include <math.h>
double f(double);
double f(double a)
{
return (4.0 / (1.0 + a*a));
}
int main(int argc,char *argv[])
{
int done = 0, n=1000000000, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
double startwtime = 0.0, endwtime;
int namelen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
MPI_Get_processor_name(processor_name,&namelen);
if (myid == 0) {
fflush(stdout);
if (n==0) {
fprintf( stdout, "No number entered; quitting\n" );
n = 0;
}
startwtime = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0)
done = 1;
else {
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) {
x = h * ((double)i - 0.5);
sum += f(x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0) {
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
endwtime = MPI_Wtime();
printf("wall clock time = %f\n", endwtime-startwtime);
fflush( stdout );
}
}
MPI_Finalize();
return 0;
}