

Конструктор декартова произведения “n” типов. Пример спецификации. Селекторы как функции. Селекторы как виртуальные атрибуты.
Алгебраический тип данных — размеченное объединение декартовых произведений множеств или, другими словами, размеченная сумма прямых произведений множеств.
Тип конструктора типа Ai, являющегося декартовым произведением типов Ai1, Ai2, … × Ain, определяется формулой:
#constructor Ai = Ai1 → (Ai2 → … (Ain → A) … ), |
то есть конструктор одного декартова произведения принимает на вход значения «оборачиваемых» типов (тех, которые помещаются в контейнер), а возвращает значение целевого, своего алгебраического типа данных.
Спецификация рекурсивных типов данных: пример «Бинарное дерево».
Данные
Описание типа данных может содержать ссылку на саму себя. Подобные структуры используются при описании списков и графов. Рекурсивная структура данных зачастую обуславливает применение рекурсии для обработки этих данных.
Бинарное
(двоичное) дерево (binary tree) - это
упорядоченное дерево, каждая вершина
которого имеет не более двух поддеревьев,
причем для каждого узла выполняется
правило: в левом поддереве содержатся
только ключи, имеющие значения, меньшие,
чем значение данного узла, а в правом
поддереве содержатся только ключи,
имеющие значения, большие, чем значение
данного узла.
Бинарное дерево
является рекурсивной структурой,
поскольку каждое его поддерево само
является бинарным деревом и, следовательно,
каждый его узел в свою очередь является
корнем дерева.
Узел дерева, не
имеющий потомков, называется листом.
Схематичное
изображение бинарного дерева:
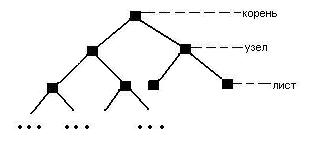 Бинарное
дерево может представлять собой пустое
множество.
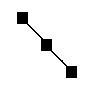
Бинарное дерево может
выродиться в список:
Бинарное
дерево может представлять собой пустое
множество.
Бинарное дерево может
выродиться в список:
<дерево> ::= ( <данные> <дерево> <дерево> ) | nil .
Задание функций на типах данных («союз», «соединение списков», «сортировка» и т.Д.). Примеры.
Тип данных — фундаментальное понятие теории программирования. Тип данных определяет множество значений, набор операций, которые можно применять к таким значениям и, возможно, способ реализации хранения значений и выполнения операций. Любые данные, которыми оперируют программы, относятся к определённым типам.
Концепция типа данных появилась в языках программирования высокого уровня как естественное отражение того факта, что обрабатываемые программой данные могут иметь различные множества допустимых значений, храниться в памяти компьютера различным образом, занимать различные объёмы памяти и обрабатываться с помощью различных команд процессора.
В языках семейства Си существует специальная разновидность типов данных, называемая смесью (union) (союз). Фактически, смесь - это запись с вариантами, но без явно поддерживаемого дискриминанта. По нашему мнению, решение о применении такого "облегченного" механизма было принято потому, что использование явно задаваемого дискриминанта в языках линии Паскаль все равно является необязательным, а раз так, то при желании можно просто включить дополнительное поле, значение которого будет характеризовать применимый вариант. Приведенный выше пример можно было бы переписать на языке Си следующим образом:
struct person { char lname[10], fname[10];
integer birthday;
enum { single, married } marstatus;
enum { male, female } sex;
union {
struct { float weight;
integer bearded } male;
integer female[3];
} pers;
}
Списки могут создаваться в программе путем последовательного
присоединения элементов.
Линейный однонаправленный список — это структура данных, состоящая из элементов одного типа, связанных между собой.
В информатике линейный список обычно определяется как абстрактный тип данных(АТД), формализующий понятие упорядоченной коллекции данных.
На практике линейные списки обычно реализуются при помощи массивов и связных списков. Иногда термин «список» неформально используется также как синоним понятия «связный список».
Упорядоченные списки А и В длин М и N сливаются в один упорядоченный список С длины М+N, если каждый элемент из А и В входит в С точно один раз. Так, слияние списков А=<6,17,23,39,47> и В=<19,25,38,60> из 5 и 4 элементов дает в качестве результата список С=<6,17,19,23,25,38,39,47,60> из 9 элементов.
Для слияния списков А и В список С сначала полагается пустым, а затем к нему последовательно приписывается первый узел из А или В, оказавшийся меньшим и отсутствующий в С.
Алгоритм сортировки — это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов упорядочения два:
Внутренняя сортировка оперирует массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно упорядочиваются на том же месте без дополнительных затрат.
В современных архитектурах персональных компьютеров широко применяется подкачка и кэширование памяти. Алгоритм сортировки должен хорошо сочетаться с применяемыми алгоритмами кэширования и подкачки.
Внешняя сортировка оперирует запоминающими устройствами большого объёма, но с доступом не произвольным, а последовательным (упорядочение файлов), т. е. в данный момент мы 'видим' только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам упорядочения, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью.
Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим.
Объём данных не позволяет им разместиться в ОЗУ.