

Лекция № 6 (.12) Классификация параллельных компьютеров и систем Классификация Флинна
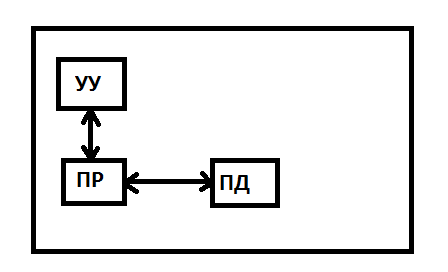
SISP – одиночный поток команд и одиночный поток данных. ПД – память данных. Внешнее подключение идет через УУ.
 м
м
Это классическая машина Фон - неймановского типа. Все команды обрабатываются последовательно друг за другом и каждая команда выполняет одну скалярную операцию.
SIMD - одиночный поток команд и множественный поток данных.
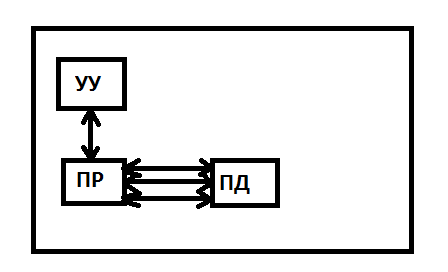
Для этой структуры в отличии от предыдущей могут задаваться векторные команды. Это позволяет выполнять одну операцию сразу над многими данными. Например сложение векторов.
MISD – множественный поток команд и одиночный поток данных
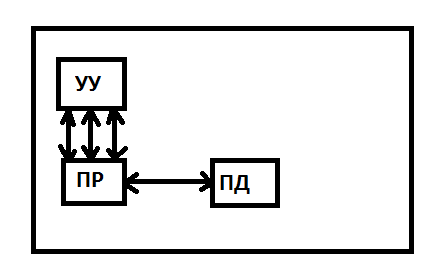
В такой структуре должно использоваться множество процессоров, обрабатывающих один и тот же поток данных.
MIMD - множественный поток команд и множественный поток данных
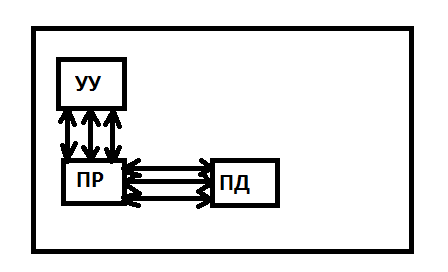
В данном случае работает несколько процессоров, каждый со своим потоком данных и команд.
Классификация Хокни
Поскольку класс MIMD широк , то Хоккни разработал следующую классификацию
MIMD:
С общей памятью
С распределенной памятью (эти два вида переключаемые)
Конвейерные
Сети
Регулярные решетки
Гиперкубы
Иерархические структуры
Изменяющая конфигурацию
Классификация Фекта
Вычислительные системы характеризуются на основе двух простых характеристик.
n – число бит в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций (практически совпадает с длиной машинного слова)
m – число слов, обрабатываемых одновременно в данной вычислительной системе
P=n*m.
P – максимальная степень параллелизма вычислительной системы.
Достоинства: введение единой числовой метрики для всех типов компьютеров. Это позволяет сравнить компьютеры между собой.
Недостаток: не раскрывается архитектура компьютера.
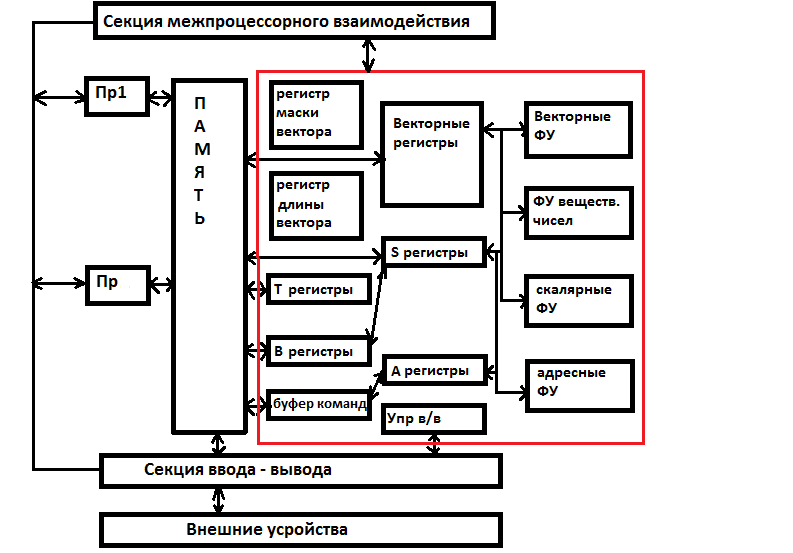
Векторно – конвейерные компьютеры
Супер-компьютер Cray 90 выпущен в 90-е годы и содержит все характерные особенности компьютеров данного класса. Он содержит 16 процессоров, работающих с общей областью памяти. Время такта 4,1 наносекунды. Все процессоры одинаковы и равноправны ко всем ресурсам: памяти, устройствам ввода-вывода и секциям межпроцессорного взаимодействия. Процессоры могут выполнять независимые программы, либо вместе выполнять одну программу.
Лекция № 7 (12.04.12)
Структура Оперативной памяти
ОП разделена всеми процессорами и секциями ввода/вывода. Каждое слово состоит из 80-ти разрядов. 64 для данных и 16 для коррекции ошибок (чаще всего используют код Хемминга). Для ускорения выборки вся память разделена на блоки, которые могут работать одновременно. Каждый процессор имеет доступ к ОП через 4 порта. Порт имеет пропускную способность – 2 слова за такт. Один из портов связан с секцией ввода/вывода и еще один выделен на операцию записи. Память расслоена на 1024 блока. Блок на 8 секций. Секция на 8 подсекций. Каждая подсекция на 16 блоков. Последовательные адреса идут с чередованием по каждому из этих параметров. При одновременном обращении к одной и той же секции возникает конфликт, который разрешается за один такт. В этом случае один из запросов продолжает обрабатываться, а другой просто блокируется на один такт. Если происходит обращение к одной и той же подсекции, то время конфликта может быть до 6 тактов.
Секции ввода/вывода
Имеется 3 типа каналов ввода/вывода.

High-Speed(HISP) – 200Мбайт/с
Very High – Speed(VHISP) – 1800 Мбайт/с
Секция межпроцессорного взаимодействия
Осуществляет передачу данных и управляющей информации между процессорами для синхронизации их совместной работы. Секция содержит разделяемые регистры и семафоры, объединенные в одинаковые группы – кластеры. Каждый кластер состоит из 8-ми 32-х разрядных адресных регистров (SB), 8-ми 64-х разрядных скалярных регистров (ST), 32-х однобитовых семафоров. Число кластеров зависит от конфигурации компьютера.
Регистровая структура процессоров.
Основные регистры:
А – адресные.
S – скалярные
V – векторные
Промежуточные регистры B и T играющие роль промежуточного хранилища между памятью и основными регистрами. Имеется 8 адресных регистров и 64 промежуточных регистра (B). Адресные регистры используются для хранения и вычисления адресов, указания величины сдвигов, числа итераций и т.д. Их длина 32 разряда. 8 скалярных регистров, и 64 регистра T. Промежуточные по 64 разряда. Они используются для хранения аргументов и результатов скалярной арифметики. Но могут содержать операнды для векторных команд. 8 векторных регистров, каждый из которых может содержать до 128-ми 64-х разрядных слов. Для поддержки выполнения векторных команд предусмотрено 2 дополнительных регистра VL и VM. Регистр длины вектора VL содержит реальную длину векторов, хранящихся в векторных регистрах и участвующих в векторной операции (8 разрядов его длины). Регистр маски вектора VM состоит из 128-ми разрядов и позволяет выполнить векторную операцию только над некоторыми компонентами векторов. 1 – операция выполняется, 0- не выполняется.
Функциональные устройства Cray C 90
Все функциональны устройства (ФУ) Cray C 90 конвейерные. Число ступеней у них различно, но каждая ступень срабатывает за 1 такт. Все ФУ независимы и могут работать одновременно друг с другом.
ФУ делятся на 4 группы:
адресные
скалярные
векторные
для операций над вещественными числами.
2 адресных ФУ предназначены для сложения, вычитания, умножения 32-х разрядных чисел.
4 скалярных ФУ для целочисленного сложения, вычитания, логических поразрядных операций, выполнения операций сдвига и нахождения числа нулей до первой единицы в слове.
Они оперируют с 64-х разрядными данными и предназначены только для выполнения скалярных команд.
Векторные ФУ. Их может быть от 5 до 7. Осуществляют операции целочисленного сложения и вычитания, сдвига, логические поразрядные операции, нахождение числа нулей, до первой единицы в слове, умножение битовых матриц. Некоторые из них могут быть продублированы. Используются только для выполнения векторных команд.
3 ФУ для вещественной арифметики. Работают с 64-х разрядными числами в форме с плавающей точкой. Выполняют сложение, вычитание, умножение, нахождение обратной величины числа. Выполняют как векторные, так и скалярные команды.
Выполнение векторных операции
Особенности таких операций:
Все конвейеры во всех векторных устройствах и устройствах для вещественной арифметики продублированы. Элементы векторов с честными номерами поступают на конвейер с номером 0, а нечетные на конвейер 1. Результаты с конвейера 0 записываются в четные ячейки, а с конвейера 1 – в нечетный. В результате полной загрузки ФУ выдает на каждом такте 2 результата.
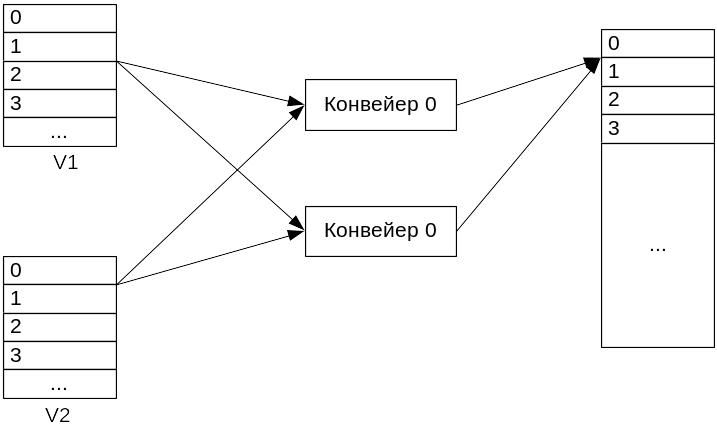
В скалярных операциях ФУ для вещественной арифметики используется только конвейер ноль. Архитектура Cray С 90, позволяет использовать регистр результатов одной векторной операции в качестве входного регистра для последующей векторной операции. Подобная ситуация называется зацепление векторных операций. Это позволяет увеличить скорость обработки данных. Пусть необходимо выполнить операцию вида: Ai=Bi+Ci*d, i(0,n). Имеется конвейерное ФУ сложения и умножения L1 и L2 ступеней. Если сначала будет выполнена операция умножения, а затем сложения, то операция будет реализована за (L1+n-1)+(L2+n-1) тактов. Если для этой операции использовать зацепление, то по сути получается конвейер длиной L1+L2, время выполнения операции сократится до (L1+L2+n-1).
Секция управления процессором
Команды выбираются ОП блоками и заполняются в буфера команд, откуда они выбираются для исполнения.
Пиковая производительность
Если нас интересует скорость выполнения операций над вещественными числами, то необходимо максимально загрузить устройство умножения и сложения. Для получения максимальной производительности их надо использовать в режиме зацепления, т.к. каждое устройство использует 2 внутренних конвейера, то система из 2-х устройств будет выдавать 4 результат за 1 такт. Время такта 4,1 наносекунды, поэтому пиковая производительность составит примерно 10^9 операций в секунду, т.е 1 ГФлопс. Для 16 процессоров получим 16 ГФлопс.
Реальная производительность Cray C 90
Чтобы писать эффективные программы, нужно изучить те факторы, которые снижают производительность в Cray C 90 при работе с реальными программами. Компьютер обладает векторно-конвейерной архитектурой, и основной выигрыш будет при использовании векторного режима обработки. Если весь фрагмент программы удается заменить векторными командами, то говорят об полной векторизации. В противном случае используется частичная векторизация или невозможность векторизации фрагмента вовсе. Простой фрагмент векторизуемого фрагмент на C.
for (i=0; i<n; i++)
C[i]=A[i]+B[i];
Для данного фрагмента компилятор сгенерирует следующую последовательность векторных команд: загрузка векторов А и В из памяти в векторные регистры. Векторная операция сложения. Запись содержимого векторного регистра в память. Для векторизации фрагмента программы необходимо выполнение 2-х условий: наличие векторов-аргументов, над всем элементами векторов должны выполняться одинаковые независимые операции, для которых существуют векторные команды в системе команд компьютера. Под вектором будем понимать упорядоченный набор однотипных данных, все элементы которого размещены в памяти компьютера с одинаковым смещением относительно друг друга. Простейший пример – одномерные массивы.