

Глава 4
ИНФОРМАЦИОННЫЕ КРОСС-ТЕХНОЛОГИИ
К данному классу отнесены технологии пользователя, ориентированные на следующие (или аналогичные) виды преобразования информации:
распознавания символов:
звук—текст:
текст—звук;
автоматический перевод.
4.1. Оптическое распознавание символов (ocr)
Когда страница текста отсканирована в ПК, она представлена в виде состоящего из пикселей растрового изображения. Такой формат не воспринимается компьютером как текст, а как изображение текста и текстовые редакторы не способны к обработке подобных изображений. Чтобы превратить группы пикселей в доступные для редактирования символы и слова, изображение должно пройти сложный процесс, известный как оптическое распознавание символов (optical character recognition — OCR).
В то время как переход от символьной информации к графической (растровой) достаточно элементарен и без труда осуществляется, например при выводе текста на экран или печать, обратный переход (от печатного текста к текстовому файлу в машинном коде) весьма затруднителен. Именно в связи с этим для ввода информации в ЭВМ исстари использовались перфоленты, перфокарты и др. промежуточные носители, а не исходные «бумажные» документы, что было бы гораздо удобнее. ■ В защиту» перфокарт скажем здесь, что наиболее «продвинутые» устройства перфорации делали надпечатку на карте для проверки ее содержания.
Первые шаги в области оптического распознавания символов были предприняты в конце 50-х гг. XX в. Принципы распознавания, заложенные в то время, используются в большинстве систем OCR: сравнить изображение с имеющимися эталонами и выбрать наиболее подходящий.
В середине 70-х гг. была предложена технология для ввода информации в ЭВМ. заключающаяся в следующем:
исходный документ печатается на бланке с помощью пишущей машинки, оборудованной стилизованным шрифтом (каждый символ комбинируется из ограниченного числа вертикальных, горизонтальных, наклонных черточек, подобно тому, как это делаем мы и сейчас, нанося на почтовый конверт цифры индекса):
полученный «машинный документ» считывается оптоэлек- трическим устройством (собственно OCR), которое кодирует каждый символ и определяет его позицию на листе;
информация переносится в память ЭВМ, образуя электронный образ документа или документ во внутреннем представлении.
Очевидно, что по сравнению с перфолентами (перфокартами) OCR-документ лучше хотя бы тем. что он без особого труда может быть прочитан и проверен человеком и, вообще, представляет собой «твердую копию» соответствующего введенного документа. Было разработано несколько модификаций подобных шрифтов, разной степени «удобочитаемости» (OCR A, OCR В и пр., рис. 4.1).
OCR А 123 OCR В 123
а б
Рис. 4.1. Стилизованные шрифты: а - OCR А; 6— OCR В
Очевидно также, что считывающее устройство представляет собой сканер, хотя и специализированный (считывание стилизованных символов), но интеллектуальный (распознавание их).
OCR-технология в данном виде просуществовала недолго и в настоящее время приобрела следующий вид:
считывание исходного документа осуществляется универсальным сканером, осуществляющим создание растрового образа и запись его в оперативную память и/или в файл;
• функции распознавания полностью возлагаются на программные продукты, которые, естественно, получили название OCR-software. Исследования в этом направлении качались в конце 1950-х гг.. и с тех пор технологии непрерывно совершенствовались. В 1970-х гг. и в начале 1980-х гг. программное обеспечение оптического распознавания символов все еще обладало очень ограниченными возможностями и могло работать только с некоторыми типами и размерами шрифтов. В настоящее время программное обеспечение оптического распознавания символов намного более интеллектуально и может распознать фактически все шрифты, даже при невысоком качестве изображения документа.
Основные методы оптического распознавания
Рис.
4.2. Различные подходя к распознаванию
символов: а — сравнение с образцом; б
— выделение признаков

ко с непропорциональными шрифтами (подобно Courier), где символы в тексте хорошо отделены друг от друга. Сложные документы с различными шрифтами оказываются уже вне возможностей таких программ.
Выделение признаков было следующим шагом в развитии оптического распознавания символов. При этом распознавание символов основывается на идентификации их универсальных особенностей, чтобы сделать распознавание символов независимым от шрифтов. Если бы все символы могли быть идентифицированы, используя правила, по которым элементы букв (например, окружности и линии) присоединяются друг к другу, то индивидуальные символы могли быть описаны независимо от их шрифта. Например: символ «а» может быть представлен как состоящий из окружности в центре снизу, прямой линии справа и дуги окружности сверху в центре (рис. 4.2, б). Если отсканированный символ имеет эти особенности, он может быть правильно идентифицирован как символ «а» программой оптического распознавания.
Выделение признаков было шагом вперед сравнительно с соответствием матриц, но практические результаты оказались весьма чувствительными к качеству печати. Дополнительные пометки на странице или пятна на бумаге существенно снижали точность обработки. Устранение такого «шума» само по себе стало целой областью исследований, пытающейся определить, какие биты печати не являются частью индивидуальных символов. Если шум идентифицирован, достоверные символьные фрагменты могут тогда быть объединены в наиболее вероятные формы символа.
Некоторые программы сначала используют сопоставление с образцом и/или метод выделения признаков для того, чтобы распознать столько символов, сколько возможно, а затем уточняют результат, используя грамматическую проверку правильности написания для восстановления нераспознанных символов. Например, если программа оптического распознавания символов неспособна распознать символ «е» в слове «th~ir», программа проверки грамматики может решить, что отсутствующий символ — «е».
Современные технологии оптического распознавания намного совершеннее, чем более ранние методы. Вместо того чтобы только идентифицировать индивидуальные символы, современные методы способны идентифицировать целые слова. Эту технологию, предложенную Caere, называют прогнозирующим оптическим распознаванием слов (Predictive Optical Word Recognition — POWR).
Используя более высокие уровни контекстного анализа, метод POWR способен устранить проблемы, вызванные шумом. Компьютер анализирует тысячи или миллионы различных способов, которыми точки изображения могут быть собраны в символы слова. Каждой возможной интерпретации приписывается некоторая вероятность, после чего используются нейронные сети и прогнозирующие методы моделирования, заимствованные от исследований в области искусственного интеллекта. Они предполагают использование «экспертов» — алгоритмов, разработанных специалистами в различных областях распознавания символов. Один «эксперт» может знать многое о начертаниях шрифта, другой — о словарной информации, третий — об ухудшении качества от «зашумленности» и пр. На каждой стадии исследования привлекается новый набор «экспертов» с учетом близости их «областей знаний* к специфической ситуации и статистики успеха в подобных ситуациях.
Окончательный итог — то. что система POWR способна идентифицировать слова способом, который близко напоминает человеческое визуальное распознавание. Практически, методика значительно улучшает точность распознавания слов во всех типах документа. Все возможные интерпретации слова оцениваются, комбинируя все источники доказательства, от информации пикселя нижнего уровня до контекстных особенностей высокого уровня, в результате чего выбирается самая вероятная интерпретация.
Технологии Finereader
Хотя системы оптического распознавания символов существовали в течение долгого времени, их выгоды только сейчас начали по достоинству оценивать. Первые разработки были чрезвычайно дорогостоящими (в терминах программного обеспечения и оборудования), неточны и трудны для использования. За несколько последних лет системы оптического распознавания полностью преобразились. Современное программное обеспечение распознавания символов очень удобно в использовании, обладает высокой точностью и находится на пути к распространению на все виды рабочих сред в массовом масштабе.
Типичным представителем данного семейства программ является ABBYY FineReader, технологический процесс которого включает следующие шаги (рис. 4.3):
сканирование исходного документа (страницы):
разметку областей (ручную или автоматическую), требующих различные виды обработки (страницы разворота книги, таблицы, рисунки, колонки текста и пр.);
распознавание — создание и вывод на экран текстового файла (с вставленными рисунками и таблицами, если это необходимо);
контроль правильности (ручной, автоматический, полуавтоматический);
вывод информации в выходной файл в заданном формате (.DOC или .RTF для Word, .XSL для Excel и пр.).
Данные, полученные на каждом этапе (изображение, текстовый файл), сохраняются под «обшей вывеской» пакета (страни-
Я поток СОНЫТТ- Н II ЕГО •
При рассмотрит! случат с дискретным» состояниями н : ся встречаться с так называсмь Потоком событий назь родных событий, следующих од ря, случайные моменты времен Поимепями mofvt быть: ^ z
| ПОТОК (.опит и Г| П!-'0< тгишип поток
И Lto ( LiQHL ГВ\
)!*> j f жи Usjsa
Рис. 4.3. Пример рабочего экрана Finereader: 7 — панель управления и настроек: 2 — перечень отсканированных пакетов; 3 — текущее изображение: 4 — размеченное изображение: 5 — распознанный текст
цы с номером), что позволяет в любой момент вернуться и повторить разметку, распознавание и пр.
Если нет необходимости сохранять цветовую информацию оригинала документа (например, для последующей обработки системами оптического распознавания символов), изображение лучше всего сканировать в режиме grayscale (полутоновое изображение). При этом файл будет занимать одну треть объема сравнительно со сканированием в цвете RGB. Можно использовать также режим штриховой графики (line art), однако при этом часто теряются подробности, существенные для точности последующего процесса распознавания символов.
Рассмотрим основные принципы функционирования программного продукта.
Принципы IPA (целостности, целенаправленности, адаптивности). Пользователь помещает документ в сканер, нажимает кнопку, и через небольшое время в компьютер поступает электронное изображение, «фотография» страницы. На ней присутствуют все особенности оригинала, вплоть до мельчайших подробностей. Это изображение содержит всю необходимую для OCR-системы информацию об исходном документе.
Принцип целостности (integrity), согласно которому объект рассматривается как целое, состоящее из связанных частей. Связь частей выражается в пространственных отношениях между ними, и сами части получают толкование только в составе предполагаемого целого, т. е. в рамках гипотезы об объекте.
Принцип целенаправленности (purposeful ness): любая интерпретация данных преследует определенную цель. Согласно этому принципу, распознавание представляет собой процесс выдвижения гипотез о целом объекте и целенаправленной их проверки.
Принцип адаптивности (ad а р t ab i 1 i t у) подразумевает способность системы к самообучению. Полученная при распознавании информация упорядочивается, сохраняется и используется впоследствии при решении аналогичных задач. Преимущество самообучающихся систем заключается в способности «спрямлять» путь логических рассуждений, опираясь на ранее накопленные знания.
Вместо полных названий этих принципов часто употребляют аббревиатуру IPA, составленную из первых букв соответствующих английских слов. Преимущества системы распознавания, работающей в соответствии с принципами IPA, очевидны — именно они способны обеспечить максимально гибкое и осмысленное поведение системы.
Например, на этапе распознавания символов изображение, согласно принципу целостности, будет интерпретировано как некий объект, только если на нем присутствуют все структурные части этого объекта, и эти части находятся в соответствующих отношениях. Иначе говоря. FineReader не пытается принимать решение, перебирая тысячи эталонов в поисках наиболее подходящего. Вместо этого выдвигается ряд гипотез относительно того, на что похоже обнаруженное изображение, затем каждая гипотеза целенаправленно проверяется. Допуская, что найденный объект может быть буквой «А». FineReader будет искать именно те особенности, которые должны быть у изображения этой буквы. Как и следует поступать, исходя из принципа целенаправленности. Причем проверять, верна ли выдвинутая гипотеза, система будет, опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Многоуровневый анализ документа (MDA)
Подлежащий распознаванию документ часто выглядит заметно сложнее, чем белая страница с черным текстом. Иллюстрации, таблицы, колонтитулы, фоновые изображения — эти элементы, все чаше применяемые для оформления, усложняют структуру страницы. Для того чтобы корректно воспроизводить в электронном виде такие документы, все современные OCR-программы начинают распознавание именно с анализа структуры. Как правило, при этом выделяют несколько иерархически организованных логических уровней. Объект наивысшего уровня только один — собственно страница, на следующей ступени иерархии располагаются таблица и текстовый блок, и так далее (рис. 4.4).
Любой высокоуровневый объект может быть представлен как набор объектов более низкого уровня: буквы образуют слово, слова — строки и т. д. Поэтому анализ всегда начинается в направлении сверху вниз. Программа делит страницу на объекты, их, в свою очередь, — на объекты низших уровней, и так далее, вплоть до символов. Когда символы выделены и распознаны,
Рис.
4.4. Многоуровневая структура документа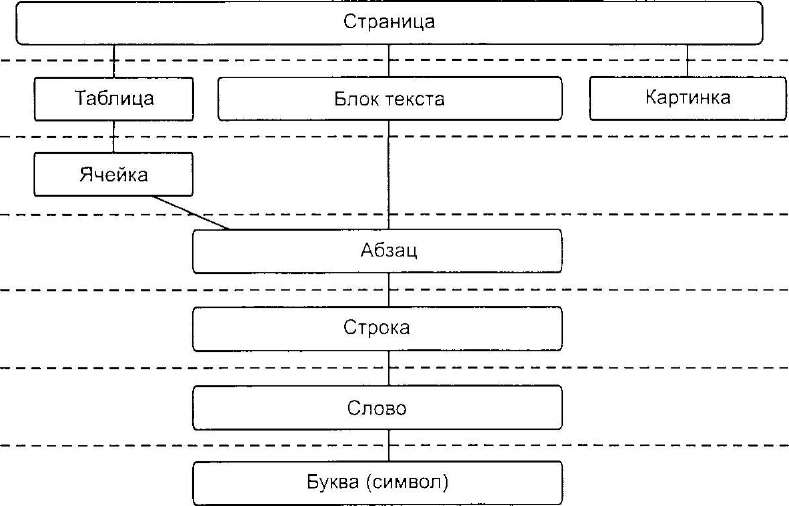
начинается обратный процесс — «сборка» объектов высших уровней, который завершается формированием целой страницы. Такая процедура называется многоуровневым анализом документа, или MDA (multilevel document analysis).
Очевидно, что программа, допустившая ошибку при распознавании объекта высокого уровня (например, перепутавшая абзац текста с иллюстрацией), почти не имеет шансов корректно завершить процедуру — итоговый электронный документ будет искажен. Риск столкнуться с подобной ситуацией существовал бы и для FineReader, однако он ведет анализ документа несколько иначе.
Во-первых, объекты любого уровня FineReader распознает в соответствии с принципа м и I Р А. В первую очередь выдвигаются гипотезы относительно типов обнаруженных объектов, затем они целенаправленно проверяются. При этом система учитывает найденные ранее особенности данного документа, а также сохраняет вновь поступающую информацию (обучается).
Допустим, все объекты текущего уровня распознаны. FineReader переходит к детальному анализу одного из них, определенного, к примеру, как текстовый блок. Предположим, вдруг оказывается, что результаты анализа этого блока крайне неубедительны; не удается выделить ни абзацы, ни строки. Повторный анализ позволяет внести коррективы: да, это текст, но наложенный на фоновое изображение. После дополнительной обработки распознавание будет продолжено — и уже без ошибок.
Описанная ситуация наглядно иллюстрирует вторую важную особенность используемого в системе FineReader алгоритма MDA: на всех этапах многоуровневого анализа существует возможность обратной связи — результаты анализа на одном из нижних уровней всегда могут повлиять на действия с объектами более высоких уровней. Наличие обратной связи в процедуре MDA дает возможность резко понизить вероятность грубых ошибок, связанных с неверным распознаванием объектов более высоких уровней.
Распознавание любого документа производится поэтапно, с помощью процедуры многоуровневого анализа документа (MDA). Деление страницы на объекты низших уровней, вплоть до отдельных символов, распознавание этих символов и «сборку» электронного документа FineReader проводит, опираясь на принципы целостности, целенаправленности и адаптивности (IPA) (рис. 4.5).
Процедуры Уровень Процедуры
10.
Сохранение документа
Документ
1.
Выделение текстовых блоков
9.
«Сборка» документа
Блок
текста, таблица
2.
Выделение строк
8.
«Сборка» строк
Строка
3.
Деление на слова
7.
Структурирование гипотез
Слово
4.
Деление на символы
6.
Создание моделей слова
Символ
5.
Распознование символов
Рис.
4.5.
Схема работы многоуровневого анализа
документов
Распознавание от уровня «страница» до уровня «слово»
На первом этапе распознавания система структурирует страницу, выделяет на ней текстовые блоки. Как мы знаем, современные документы часто содержат всевозможные элементы дизайна:
иллюстрации, колонтитулы, цветной фон или фоновые изображения, и т. д. Основная задача на данном этапе состоит в том, чтобы отделить текст от иллюстраций и «подложенных» текстур.
Все современные системы распознавания начинают процесс «знакомства» с создания черно-белого изображения документа. При этом подлежащее анализу изображение чаще всего цветное или полутоновое (т. е. состоящее из разных оттенков серого цвета, подобно картинке на экране черно-белого телевизора). Любая OCR-система прежде всего преобразует такое изображение в монохромное, состоящее только из черных и белых точек. Процесс преобразования называется бинаризацией, он всегда предшествует летальной обработке распознаваемой страницы.
Блок текста, состоящий из строк, должен иметь характерную линейчатую структуру. Разделив этот блок на строки, можем приступать к выделению слов. Однако на практике столь простые варианты встречаются нечасто. Возьмите любой документ, где строки текста наложены на цветной фон. и представьте, как будет выглядеть эта страница в черно-белом варианте. Вокруг каждого символа обнаружатся десятки и сотни «лишних» точек, оставшихся от фона. Работая с таким «загрязненным» текстом, большинство OCR-программ не сможет уверенно распознавать символы, поскольку лишние точки будут искажать очертания букв и даже границы строк, приводя к ошибкам.
FineReader не пытается решать задачу бинаризации «в лоб». Принцип целенаправленности диктует иной подход к обнаружению строк в текстовом блоке или слов в строке: они должны быть где-то здесь, надо только суметь их узнать. Для повышения качества поиска FineReader использует процедуры интеллектуальной фильтрации фоновых текстур (рис. 4.6, а) и адаптивной бинаризации (рис. 4.6, б). Первая позволяет уверенно отделять строки текста от сколь угодно сложного фона, вторая — гибко выбирать оптимальные для данного участка параметры бинаризации. Естественно, к этим процедурам система прибегает не всегда, а лишь в тех случаях, когда предварительный анализ указывает на подобную необходимость. В каждом конкретном случае FineReader выбирает подходящий «инструмент», опираясь на информацию, накопленную в процессе анализа документа.
Например, идет анализ строки. Система занята поиском объектов уровня «слово». На первый взгляд, проще всего разделить
![]()
welcome
Sl^jf welcome
w clconu*
\N I U M I I It
Hi
Hi
a![]()
![]()
Рис. 4.6. Технологии распознавания: а — пример работы интеллектуальной фильтрации фоновых структур; б — уровни бинаризации
строку на слова по найденным пробелам. Однако первичный анализ показывает, что в конце строки пробелы попадаются заметно чаше, чем в начале. Процедура адаптивной бинаризации исследует яркость фона и насыщенность черного цвета на протяжении всей строки и подбирает оптимальные параметры бинаризации для каждого фрагмента по отдельности. В результате оказывается, что часть символов в конце строки получилась слишком светлой и могла бы быть «потеряна» при обработке обычной OCR-программой, но в результате применения адаптивной бинаризации все слова будут выделены точно. При неправильном выборе параметров бинаризации слово окажется «нечитаемым».
Уровни «слово» и «символ». Распознаватели символов ( классификаторы)
Разделив строку на отдельные слова, FineReader приступает к обработке символов. Разделение слов на символы и собственно распознавание букв, как и все остальные механизмы многоуровневого анализа документа, реализованы в виде составных частей единой процедуры. Это позволяет в полной мере использовать преимущества принципов IPA. Выделенные изображения символов поступают на рассмотрение механизмов распознавания букв, называемых классификаторами.
В системе ABBYY FineReader применяются следующие типы классификаторов: растровый, контурный, приз
наковый, структурный, п р и з н а к о в о - д и ф ф е р е н - циальный и с т р у к т у р н о - д и ф ф е р е н ц и а л ь н ы й.
Растровый классификатор. Классификатор сравнивает символ с набором эталонов, поочередно накладывая изображения друг на друга. Эталонами в данном случае выступают специально подготовленные изображения; каждое из них объединяет в себе очертания множества вариантов написания того или иного символа. Гипотезы выдвигаются в зависимости от того, с какими эталонами точнее совпало изображение буквы. Сами эталоны строятся методом наложения друг на друга большого количества одних и тех же букв в разных вариантах начертания (рис. 4.7, а).
Контурный классификатор. Представляет собой разновидность признакового классификатора. От вышеописанного отличается тем, что признаки вычисляются не по полному изображению символа, а по его контуру (рис. 4.7, о). Этот быстродействующий классификатор предназначен для распознавания текста, набранного декоративными шрифтами (например, стилизованного под готический, старорусский стиль и т. п.).
Признаковый классификатор. Аналогичен растровому (выдвигает гипотезы, исходя из степени совпадения параметров символа с эталонными значениями). Оперирует определенными числовыми признаками, такими, например, как длина периметра, количество черных точек в разных областях или вдоль различных направлений и т. п. (рис. 4.7, в). Весьма популярен у разработчиков OCR-систем. В определенных условиях способен работать почти так же быстро, как растровый. Точность работы признакового классификатора во многом зависит от качества признаков, выбранных для каждого символа. Под качеством признаков в данном случае понимается их способность максимально точно, но без избыточной информации охарактеризовать начертание буквы.
Структурный классификатор. Первоначально был создан и использовался для распознавания рукописного текста, однако в последнее время применяется и для обработки печатных документов. Этот классификатор проводит структурный анатиз символа, раскладывая последний на элементарные составляющие (отрезки, дуги, окружности, точки) и формируя точную схему анализируемого знака (рис. 4.7, г).
Затем полученная схема (структурное описание буквы) сравнивается с эталоном. Этот классификатор работает медленнее
КАЛAAAАЛАААAAAАА в АААПAAAAААААПЛАА
ААААаааааааааааА
б

1
120.7S0
1,112
0,081
5,187
2
1.000
1.008
0.008
0.013
3
242.750
11.140
-6.001
0.039
ч
ю.ооо
0.3SS
0,051
4.150
5
-24.ООО
-0,
244
-0.001
0.089
е
0.003
0.000
0.5
8?
11
.345
j
г.еэо
0.088
0.013
1,318
)
s
1S2.2S0
0.059
-0.332
22,545
3
е.
60s
0.080
0.080
0.000
IS
-128.750
-0.831
-0.338
23.014
ИТОГО
= 6S
">
й Сзоб.
член - е.ess
rz:::::::::
ПроТОКОИ
СЫЧИСПения ПриОНЗКОО:
■
:::::::::
РезуПЫйТЫ; Выёр&кзди вариант: й
в
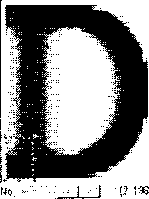

Рис. 4.7. Распознавание символов: а — растровые эталоны буквы «А»; б — контурные эталонов буквы «А»: в — изображение буквы для признакового классификатора, определяющего определенные признаки (например, количество серого в какой-либо точке буквы); г — пример обучения структурного классификатора (заметен «скелет» буквы «А»); д — пример работы признаково-дифференциального классификатора. Чтобы верно выбрать одну из похожих букв («D» и «О»), классификатор вычисляет признак (наклон линии в ключевой зоне); е — пример работы структурно-дифференциального классификатора — чтобы выбрать одну из похожих букв (сочетание «Л» и «А»), сравнивается структура букв, обращая особое внимание на внешний профиль
растрового и признакового, но отличается высокой точностью. Более того, он способен «мысленно» восстанавливать не пропечатанные или залитые символы.
Признаков!)-дифференциальный классификатор. Предназначен для различения похожих друг на друга объектов, таких, например, как буква «т» и сочетание «гп». Принципиальное отличие этого классификатора от описанных выше заключается в том, что он не анализирует все изображение. Дифференциальный классификатор обращается только к тем частям объекта, где может находиться ключ к правильному ответу. В случае с «ш» и «гп» ключом служит наличие и ширина разрыва в месте касания предполагаемых букв. Признаково-дифференциатьный классификатор используется во многих системах распознавания символов (рис. 4.7, д).
Структурно-дифференциальный классификатор. Аналогичен структурному; был разработан и первоначально применялся для обработки рукописных текстов. Как и признаково-дифференци- альный, этот классификатор решает задачи различения похожих объектов, но работает на порядок точнее (за счет анализа структуры) и способен «узнавать» искаженные знаки (рис. 4.7, е).
В самых общих чертах процесс обработки символа выглядит так: растровый и признаковый классификаторы анализируют изображение и выдвигают несколько гипотез относительно того, какая буква им представлена. Следует заметить, что при выдвижении каждой гипотезе присваивается определенная оценка (так называемый вес гипотезы). В результате работы растрового и признакового классификаторов система получает список гипотез, отсортированный по весу (т. е. по степени уверенности).
Затем, в соответствии с принципами IPA, FineReader приступает к целенаправленной проверке имеющихся гипотез с помощью дифференциального признакового классификатора. В тех случаях, когда требуется различить два похожих символа (например, «I» и «1»), к анализу подключается дифференциальный структурный классификатор. В самых трудных ситуациях задействуют структурный классификатор. Построив полную схему распознаваемого знака и проанализировав ее на предмет наличия ключевых элементов структуры, этот классификатор изменяет веса гипотез в соответствии с результатами своей работы.
С уровня «символ» до уровня «слово». Структурирование гипотез
На каждом логическом уровне документа выдвигается ряд гипотез. Каждая из них на следующем уровне порождает еще несколько предположений. Поэтому при распознавании букв FineReader оперирует множеством гипотез, учитывающих возможные варианты деления строки на слова, слова на буквы, и т. д. Для быстрого и точного принятия решений система объединяет гипотезы в многоуровневые структуры — модели. Существуют следующие типы моделей слова: словарное слово, несловарное слово (для каждого из поддерживаемых языков распознавания построены соответствующие разновидности), e-mail или URL, цифры с префиксом или суффиксом, регулярное выражение и т. д. В результате структурирования количество подлежащих проверке гипотез сильно сокращается, так что последующая проверка происходит максимально быстро и эффективно.
Рассмотрим процесс структурирования на примере слова «turn» (рис. 4.8). Предположим, при разделении слова на символы было выдвинуто две гипотезы: первая соответствует прочтению «turn», вторая — «turn». Классификаторы, обработав символы, в свою очередь предложили для каждой буквы обоих слов некоторый ряд гипотез. Последние, как мы помним, обычно сортируются по весу. Следующий шаг кажется очевидным — теперь надо выбрать гипотезы с максимальным весом. Однако далеко не всегда наиболее вероятная гипотеза в итоге оказывается истинной. Лучший способ принять правильное решение — пе-
turn
шиши
Модель 1 [Т| [u] [~r"j [~п"|
Введение 3