

16. Синтаксические диаграммы
- графическое представление синтаксиса языка программирования. Синтаксические диаграммы соответствуют расширенной форме Бэкуса-Наура и используются при описании языка программирования.
Популяризировал синтаксические диаграммы создатель языка Pascal H. Вирт, и поэтому их часто называют синтаксическими диаграммами Вирта. На синтаксических диаграммах используются два вида четырехугольников – с прямыми и скругленными углами (иногда их заменяют кружками или овалами). В прямоугольники заключаются элементы языка, значение которых должно быть определено (так называемые нетерминальные символы). В четырехугольниках со скругленными углами (или кружках, овалах) размещаются так называемые терминальные (базовые) символы, или иероглифы языка, значение которых в определении не нуждается. Направление движения по диаграмме при раскрытии структуры понятия, записанного при входе в диаграмму, указывают стрелки.
Чтобы получить правильные грамматические конструкции языка, используя синтаксические диаграммы, нужно идти по путям, указанным стрелками, от одного четырехугольника к другому до тех пор, пока не встретится выход. Там, где предусмотрено более одного направления движения, можно выбирать любое. Если по пути встречается ссылка к другой синтаксической диаграмме, то следует войти в эту новую диаграмму, пройти по ней, выйти из нее и возвратиться на старое место в первоначальной диаграмме. Если по пути движения встречается точка, то это означает, что данный путь характерен только для Turbo Pascal и является расширением стандарта языка. Варианты представления синтаксических конструкций языка программирования методом BNF или методом синтаксических диаграмм являются тождественными.
17. Лексический анализатор
Лексический анализ (ЛА) – это первый этап процесса компиляции, на котором символы, составляющие исходную программу, группируются в отдельные минимальные единицы текста, несущие смысловую нагрузку – лексемы.
Задача лексического анализа - выделить лексемы и преобразовать их к виду, удобному для последующей обработки. ЛА необязательный этап компиляции, но желательный по следующим причинам:
1) замена идентификаторов, констант, ограничителей и служебных слов лексемами делает программу более удобной для дальнейшей обработки;
2) ЛА уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии;
3) если будет изменена кодировка в исходном представлении программы, то это отразится только на ЛА.
В процедурных языках лексемы обычно делятся на классы:
служебные слова;
ограничители;
числа;
идентификаторы.
Каждую лексему можно представить парой чисел вида (n, k), где n – номер таблицы лексем, k - номер лексемы в таблице. Тогда входными данными ЛА будет текст транслируемой программы на входном языке, а выходными - последовательность лексем в числовом представлении.
Таблицы идентификаторов и чисел формируются в ходе лексического анализа.
Анализ текста исходной программы проводится путем разбора по регулярным грамматикам и опирается на способ разбора по конечному автомату, снабженному дополнительными пометками-действиями. Для удобства разбора вводится дополнительное состояние автомата ER, попадание в которое соответствует появлению ошибки в алгоритме разбора. Переход по дуге, не помеченной ни одним символом, осуществляется по любому другому символу, кроме тех, которыми помечены все другие дуги, выходящие из данного состояния.
Выделяются методы непрямого и прямого лексического анализа.
Непрямой лексический анализ, или лексический анализ с возвратами, заключается в последовательной проверке версий о классах лексем. Если проверка текущей версии не подтверждается, то происходит откат назад по цепочке символов и осуществляется проверка следующей версии.
Непрямой лексический анализатор состоит из отдельных автоматов, каждый из которых распознает одну заданную лексему. Все автоматы имеют одинаковую структуру и отличаются только внутренними состояниями, что связано с различием распознаваемых лексем.
Прямой лексический анализ позволяет определить значение лексемы без откатов назад по цепочке символов. Прямой лексический анализатор строится на основе одного детерминированного автомата, объединяющего множество автоматов, распознающих отдельные лексемы. Такой автомат на каждом шаге читает один входной символ и переходит в следующее состояние, приближающее его к распознаванию текущей лексемы или формированию ошибки. Для лексем, имеющих одинаковые подцепочки, автомат имеет общие фрагменты, реализующие единое множество состояний. Отличающиеся части реализуются своими фрагментами.
Обычно лексический анализатор строится в два этапа:
1) построение конечного автомата с действиями для распознавания и формирования внутреннего представления лексем;
2) написание по конечному автомату с действиями функции сканирования текста исходной программы.
Рассмотрим реализацию данной методики на примере ЛА для числовых констант.
18. Синтаксический анализатор
синтакси́ческий ана́лиз (па́рсинг) — это процесс сопоставления линейной последовательности лексем (слов, токенов) языка с его формальной грамматикой. Результатом обычно является дерево разбора (синтаксическое дерево). Обычно применяется совместно с лексическим анализом. Синтаксический анализатор (парсер) — это программа или часть программы, выполняющая синтаксический анализ.
Пример разбора выражения в дерево
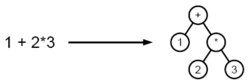
При парсинге исходный текст преобразуется в структуру данных, обычно — в дерево, которое отражает синтаксическую структуру входной последовательности и хорошо подходит для дальнейшей обработки.
Как правило, результатом синтаксического анализа является синтаксическая структура предложения, представленная либо в виде дерева зависимостей, либо в виде дерева составляющих, либо в виде некоторой комбинации первого и второго способов представления.
Всё что угодно, имеющее «синтаксис», поддается автоматическому анализу.
Типы алгоритмов:
Нисходящий парсер (англ. top-down parser) — продукции грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов.
- LL-анализатор
Восходящий парсер (англ. bottom-up parser) — продукции восстанавливаются из правых частей, начиная с токенов и кончая стартовым символом.
- LR-анализатор
- GLR-парсер
Восстановление после ошибок:
Простейший способ реагирования на некорректную входную цепочку лексем — завершить синтаксический анализ и вывести сообщение об ошибке. Однако часто оказывается полезным найти за одну попытку синтаксического анализа как можно больше ошибок. Именно так ведут себя трансляторы большинства распространённых языков программирования.
Таким образом перед обработчиком ошибок синтаксического анализатора стоят следующие задачи:
он должен ясно и точно сообщать о наличии ошибок;
он должен обеспечивать быстрое восстановление после ошибки, чтобы продолжать поиск других ошибок;
он не должен существенно замедлять обработку корректной входной цепочки.
Часть программы, выполняющая чтение и анализ выражения, называется синтаксическим анализатором выражений. Это — наиболее важная подсистема интерпретатора.
Синтаксические анализаторы, управляемые таблицей, в общем случае обладают большим быстродействием, чем другие синтаксические анализаторы, однако процесс их создания очень трудоемкий.