

Руководство пользователя по сигнальным процессорам Sharc
.pdfDMA 6
Рис. 6.12. Временные диаграммы сигналов  /
/ 
Замечания:
♦Время установки  должно быть таким, чтобы ADSP 2106x обнаружил сигнал в том же цикле. Запросы DMA могут устанавливаться асинхронно с CLKIN.
должно быть таким, чтобы ADSP 2106x обнаружил сигнал в том же цикле. Запросы DMA могут устанавливаться асинхронно с CLKIN.
♦ управляет DATA47 0, если ADSP 2106x принимает данные.
управляет DATA47 0, если ADSP 2106x принимает данные.  фиксирует DATA47 0, если ADSP 2106x передает данные.
фиксирует DATA47 0, если ADSP 2106x передает данные.
6.5. Производительность DMA
В этом разделе рассматривается общая производительность DMA, когда несколько каналов DMA пытаются обратиться к внутренней или внешней памяти в одном цикле.
DMA к внутренней памяти
При обращении к внутренней памяти ADSP 2106x выполняется арбитраж каналов DMA. Контроллер DMA определяет, какому каналу разрешен доступ к внутренней шине I/O и, следовательно, какой канал будет записывать данные во внутреннюю память или считывать из нее (риоритет каналов DMA описан в табл. 6.13 в разделе «Определение приоритетов каналов DMA» в этой главе).
Каждая передача по DMA занимает один цикл, даже когда различным каналам DMA разрешается доступ в следующих друг за другом циклах, т. е. нет общих потерь производительности при переключении между каналами. Поэтому
221
6 DMA
четыре канала DMA линк портов, каждый из которых передает по одному байту за цикл, будут иметь такую же скорость передачи, как один канал DMA внешнего порта, передающий данные во внутреннюю память за один цикл. При любой комбинации передач (через линк порты, последовательные порты и внешний порт) скорость передачи одинакова и равна максимальной.
DMA к внешней памяти
При передаче по DMA между внутренней памятью ADSP 2106x и внешней памятью обращение к последней может иметь одно или более состояний ожидания. Однако состояния ожидания для внешней памяти не снижают общую скорость внутренних передач по DMA, если другие каналы имеют данные, готовые к пересылке. Другими словами, внутренняя шина данных I/O не будет задерживаться невыполненной внешней передачей.
Когда данные будут передаваться из внутренней памяти во внешнюю, то данные из внутренней памяти сначала помещаются в буфер ЕРВх внешнего порта контроллером DMA, а затем обращение внешней памяти начинается независимо (аналогично для DMA из внешней памяти во внутреннюю; внутренние запросы DMA не будут сделаны, пока данных внешней памяти нет в буфере ЕРВх). В обоих случаях генератор внешнего адреса DMA (регистры параметров EI и ЕМ) обеспечивает внешний адрес, пока не будет закончена передача данных. Генераторы внутреннего и внешнего адреса канала DMA разделены и функционируют независимо.
Когда происходят передачи по DMA между внешним устройством и внешней памятью (режим EXTERN), никаких внутренних ресурсов ADSP 2106x не используется и на производительность внутреннего DMA эти передачи не влияют.
6.6. 2-D DMA
В этом разделе описаны изменения, которые происходят, когда ADSP 21060 или ADSP 21062 установлен для работы в режиме передачи по DMA двумерных массивов данных (2 D DMA) (заметьте, что в ASDP 21061 нет 2 D DMA). Режим 2 D DMA разрешается битом L2DDMA в регистре управления и битом D2DMA в регистрах SRCTL0 и SRCTL1.
6.6.1. Организация каналов для 2-D DMA
В режиме 2 D DMA адресация двумерного массива может выполняться для буферов линк портов и последовательных портов. Каналы DMA 0 5 поддерживают 2 D режим. Буферы 4 и 5 линк портов (каналы DMA 6 и 7) не поддерживают 2 D DMA. В табл. 6.16 показаны регистры, отвечающие за режим
222
DMA 6
2 D DMA, и их отображение в регистры каналов DMA. Здесь рассматривается адресация двумерного массива в порядке старшинства строк.
2 D функция |
Регистр канала DMA |
Индекс (адрес) |
IIx |
Приращение Х |
IMx |
Счетчик Х |
Cx |
Указатель следующего набора параметров |
CPx |
Приращение Y |
DBx |
Счетчик Y |
GPx |
Начальный счетчик Х |
DAx (не часть цепочки; загружается из Сх) |
Таблица 6.16. Регистры, отвечающих за 2-D режим
В табл. 6.16 номер канала DMA – х — отличается от стандартной нумерации последовательных портов и линк портов следующим образом:
Передача через буфер линк портов использует 5 |
канал DMA |
|
Прием через буфер линк портов |
использует 4 |
канал DMA |
Передача через SPORT |
использует 3 |
или 1 канал DMA |
Прием через SPORT |
использует 2 |
или 0 канал DMA |
Индексный регистр (II) загружается первым адресом в массиве данных и обеспечивает текущий адрес путем вычитания приращения Х после каждой передачи. Регистр приращения Х (IM) содержит смещение, прибавляемое к текущему адресу, чтобы указать на следующий элемент в строке Х (следующий столбец). Регистр начального счетчика Х (DA) содержит число элементов данных в строке Х. Это число используется для перезагрузки регистра счетчика Х, когда его содержимое уменьшается до нуля. Регистр счетчика Х (С) содержит число элементов данных, оставшихся в текущей строке. Первоначально он имеет то же самое значение, что и начальный счетчик Х. Счетчик декрементируется после каждой передачи.
Регистр приращения Y (DB) содержит смещение, прибавляемое к текущему адресу, чтобы указать на следующий элемент по Y (первая позиция в следующей строке). Когда содержимое регистра счетчика Х достигает нуля, содержимое этого регистра приращения прибавляется к текущему адресу в следующем цикле и регистр счетчика Y декрементируется. Величина DB должна быть равна длине строки минус длина столбца, так как оба приращения (Х и Y) производятся при смене строки. Заметим, что для смены строки требуется два цикла DMA.
Регистр счетчика Y сначала содержит число элементов данных по Y (число строк). Он уменьшается каждый раз, как только содержимое регистра счетчика Х достигает нуля. Когда содержимое счетчика Y достигнет нуля, передача по DМA
223
6 DMA
блока выполнена. Регистр указателя следующего набора параметров (СР) указывает на начало буфера во внутренней памяти, содержащий следующий набор параметров DMA.
Контроллер DMA и линк порты взаимодействуют посредством тех же самых внутренних сигналов квитирования – запрос/предоставление, – которые используются другими портами I/O. Приемный буфер линк портов использует канал 4, передающий буфер линк портов – канал 5 (более подробно см. в главе Линк порты этого руководства). Контроллер DMA и последовательные порты также взаимодействуют посредством тех же самых внутренних сигналов квитирования – запрос/предоставление, – которые используются другими портами I/O (более подробно см. в главе Последовательные порты).
6.6.2. Работа DMA в 2-D режиме
Передача по DMA двумерных массивов происходит следующим образом:
Первый цикл:
♦Выводится текущий адрес, хранящийся в регистре II, и начинается цикл DMA.
♦В том же цикле величина приращения Х, хранящаяся в регистре IM, прибавляется к текущему адресу в регистре II.
♦Декрементируется счетчик Х в регистре С.
♦Если содержимое счетчика Х уменьшилось до нуля, выполняется второй
цикл.
Второй цикл:
♦В счетчик Х регистра С записывается значение из регистра DA.
♦Величина приращения Y в регистре DB прибавляется к текущему адресу в II.
♦Декрементируется счетчик Y в регистре GP.
♦Если содержимое счетчика Y достигло нуля, последовательность DMA закончена и канал становится неактивным, пока снова не будет записан указатель следующего набора параметров.
Ключевым моментом последовательности 2 D DMA (или любой последовательности DMA) является то, что первая передача по DMA начинается до того, как модифицируется адрес. Это означает, что DMA не может быть запрещен установкой счетчиков Х или Y в ноль. Чтобы сделать передачу по DMA одномерного массива в 2 D режиме, счетчик Y должен быть инициализирован единицей.
Когда содержимое счетчика Х становится равным нулю, а содержимое счетчика Y не ноль, счетчик Х должен быть перезагружен его начальным значением. Регистр С функционирует как рабочий регистр счетчика. Регистр DA содержит начальное значение счета. С загружается из DA, чтобы восстановить счет. Регистр DA записывается автоматически при записи в регистр С.
224

Многопроцессорная система 7
7
7.1. Обзор
ADSP 2106x имеет такие функциональные характеристики, которые позволяют создавать многопроцессорные системы. Эти характеристики включают: встроенный арбитраж шины и возможность обращения в многопроцессорной системе к внутренней памяти и регистрам устройства ввода вывода (IOP, Input Output Processor) других ADSP 2106x. ADSP 2106x также способен блокировать шину для выполнения неделимой последовательности чтение модификация запись для семафоров.
Вмногопроцессорной системе с несколькими ADSP 2106x, совместно использующими внешнюю шину, любой из процессоров может стать ведущим. Ведущий процессор берет на себя управление шиной, которая включает сигналы
DATA47 0, ADDR31 0 и линии управления. На рис. 7.1 показана многопроцессорная система.
Втабл. 7.1 приведены выводы, соединяющие процессоры SHARC:
DATA47 0 ADDR31 0
ACK
PAGE
ADRCLK
 *
*  *
*
REDY* |
* |
CLKIN |
* если используется хост интерфейс.
** если используется приоритетный доступ ядра.
Таблица 7.1. Выводы, соединяющие процессоры в кластерную многопроцессорную систему
Внутренняя память и регистры IOP всех ADSP 2106x в системе называются
пространством памяти многопроцессорной системы. Пространство памяти
225

7 Многопроцессорная система
многопроцессорной системы отображается в общее адресное пространство каждого ADSP 2106x.
Если ADSP 2106x становится ведущим, то он может выполнять прямые считывание и запись во внутреннюю память любого другого (ведомого) ADSP 2106x. Он может также считывать и записывать содержимое любого из регистров IOP ведомых процессоров, включая буферы данных FIFO внешнего порта. Ведущий ADSP 2106x может выполнять запись в регистры IOP ведомого для настройки прямого доступа в память (DMA) или для посылки векторного прерывания.
Термины, используемые в этой главе, определены ниже:
Внешняя шина |
выводы DATA47 0, ADDR31 0, |
, |
, |
, |
, |
|
(external bus) |
||||||
|
|
|
|
|
ADRCLK, PAGE, 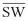 , ACK и
, ACK и  .
.
Многопроцессорная система (multiprocessor system)
Пространство памяти многопроцессорной системы (multiprocessor memory space)
Регистр устройства ввода вывода (регистр IOP)
Ведомый или режим ведомого (bus slave or slave mode)
Прямое чтение и прямая запись (direct reads & writes)
Передача одного слова данных (single word data transfer)
система, состоящая из группы ADSP 2106х, которая может не иметь хост процессора. ADSP 2106х соединяются через внешнюю шину и/или через линк порты.
часть карты памяти, которая объединяет внутреннюю память и регистры IOP каждого ADSP 2106х в многопроцессорной системе; это адресное пространство отображается в объединенное адресное пространство ADSP 2106х.
любой из регистров управления, состояния и буферы данных устройства ввода вывода ADSP 2106х.
ADSP 2106х может быть ведомым по отношению к другому ADSP 2106х или хост процессору.
прямой доступ к внутренней памяти или к регистрам IOP ADSP 2106х, осуществляемый другим ADSP 2106х или хост процессором.
чтение и запись буферов EPBх внешнего порта, выполняющиеся извне ведущим или изнутри ядром ведомого ADSP 2106х; это происходит, когда DMA запрещен в регистрах управления DMACx.
226

Многопроцессорная система 7 |
Рис. 7.1. Многопроцессорная система ADSP-2106x |
227
7 Многопроцессорная система
Цикл передачи шины |
цикл, в котором управление внешней шиной переходит |
(BTC – bus transition |
от одного ADSP 2106х к другому (в многопроцессорной |
cycle) |
системе). |
Буферы FIFO |
EPB0, EPB1, EPB2 и EPB3 – регистры IOP, которые |
внешнего порта |
используются для передачи данных с использованием |
|
DMA через внешний порт и передачи одного слова |
|
данных (из других ADSP 2106х или из хост |
|
процессора); эти буферы состоят из 6 ячеек, |
|
образующих FIFO. |
Регистры управления |
регистры управления DMA для буферов ЕРВх |
DMACx |
внешнего порта DMAC6, DMAC7, DMAC8, DMAC9 |
|
(соответствующие буферам ЕРВ0, ЕРВ1, ЕРВ2, ЕРВ3). |
|
См. главу DMA или приложение Регистры управления/ |
|
состояния. |
7.2. Архитектура многопроцессорной системы
Вмногопроцессорных системах обычно используют одну из двух схем связи между процессорами. В первой схеме реализуется соединение «точка к точке». В другой связь с совместно используемой глобальной памятью осуществляется по общей параллельной шине.
ВADSP 2106x SHARC обеспечивается реализация соединения «точка к точке» через шесть линк портов. Многопроцессорная система, связь в которой реализуется по совместно используемой параллельной шине, называется
кластерной многопроцессорной системой. Характеристики кластерной многопроцессорной системы ADSP 2106x описаны в этой главе, а соединение «точка к точке» описано в главе Линк порты этого руководства.
При создании многопроцессорной системы нужно решить две проблемы, связанные с непроизводительными затратами при межпроцессорном взаимодействии и ограниченной полосой пропускания данных. Архитектура ADSP 2106x SHARC позволяет решить эти проблемы несколькими способами (см. далее описание трех основных типов многопроцессорной системы).
7.2.1. Потоковая многопроцессорная система
Потоковая многопроцессорная система лучше всего подходит для приложений, требующих широкого диапазона вычислительных возможностей, однако она
228

Многопроцессорная система 7
обладает ограниченной гибкостью. Программисты разбивают свой алгоритм на части, которые выполняются друг за другом в отдельных процессорах, образующих конвейер; при этом данные передаются от процессора к процессору (см. рис. 7.2).
ADSP-2106x |
ADSP-2106x |
ADSP-2106x |
ДАННЫЕ |
|
|
|
|
|
|
|
|
|
|
линк- |
линк- |
|
линк- |
линк- |
|
|
линк- |
линк- |
||
|
|
|
|
|
||||||
|
|
порт |
порт |
|
порт |
порт |
|
|
порт |
порт |
|
|
|
|
|
|
|
|
|
|
|
Рис. 7.2. Потоковая многопроцессорная система
ADSP 2106x SHARC идеально подходит для потоковых многопроцессорных приложений, потому что он устраняет необходимость в буферах данных между процессорами и внешней памятью. Обычно внутренняя память SHARC достаточно большая, чтобы содержать код и данные для большинства приложений, использующих эту схему соединения. Для всех потоковых систем требуются несколько процессоров SHARC и сигналы для соединения их по схеме «точка к точке». Такой подход дает существенную экономию места на плате, снижает сложность и стоимость системы.
7.2.2 Кластерная многопроцессорная система
Кластерная многопроцессорная система лучше всего подходит для приложений, где требуется достаточная гибкость. Это особенно актуально, когда система должна выполнять множество различных задач, причем некоторые из них могут выполняться одновременно. Конфигурация кластерной многопроцессорной системы показана на рис. 7.3. Процессоры SHARC также имеют хост интерфейс, который позволяет кластеру легко взаимодействовать с хост процессором или с другим кластером.
Кластерные многопроцессорные системы содержат множество процессоров SHARC, соединенных параллельной шиной, которая позволяет осуществлять межпроцессорное обращение к внутренней памяти, расположенной на кристалле, а также обращение к совместно используемой глобальной памяти. В обычном кластере до шести процессоров SHARC и хост процессор могут управлять шиной. Расположенная на кристалле логика арбитража шины позволяет этим процессорам совместно использовать одну шину. Другое
229

7 Многопроцессорная система
Рис. 7.3. Кластерная многопроцессорная система
свойство процессоров SHARC помогает устранить необходимость в любых дополнительных аппаратных средствах при конфигурации кластерных многопроцессорных систем. В системах этого типа часто не используются ни локальная, ни глобальная внешняя память.
В ADSP 2106x поддерживаются две схемы приоритетов – фиксированные и вращающиеся приоритеты, а также блокировка шины, ограничение времени использования шины и приостановление фоновых передач по DMA обращением ядра процессора. Логика арбитража шины позволяет осуществлять передачу управления шиной c одним непроизводительным циклом. Запросы шины генерируются всякий раз, когда процессор обращается по внешнему адресу. Из за того, что каждый процессор контролирует все запросы шины и применяет одну и ту же логику определения приоритета запросов, каждый процессор может независимо определить, кто будет следующим ведущим. Так как в процессор встроены возможности совместного использования шины, проектировщикам не нужно разрабатывать собственную логику совместного использования шины и синхронизации.
Когда процессор получает управление шиной, он может обращаться не только к внешней памяти, но и к внутренней памяти и регистрам IOP всех других
230