

5. Системи штучного інтелекту
5. Розпізнавання образів
Вода на свой вкус (вступление)… Дальше… Базовий принцип: Будь-який об`єкт у природі - унікальний; унікальні об`єкти - типізовані. В природі не існує двох об’єктів, для яких співпадають абсолютно всі ознаки, і це теоретично дозволяє здійснювати ідентифікацію.
Опять Вода: поняття ознак, класифікація обєктів за ознаками, навчання, правила розпізнавання, навчальної вибірки, контрприкладу.
Задача розпізнання без учителя (кластерного аналізу). Класи попередньо не задаються; система повинна сама розділити відомі їй об’єкти на класи.
Зразок у розумінні "класу" визначається як деяка сукупність об’єктів, що мають спільні властивості, або певні спільні ознаки. Більш формально: об’єкти, для яких виконується відношення еквівалентності, або у крайньому разі відношення толерантності, у своїй сукупності складають образ.
Відношення еквівалентності = симетричності+рефлексивності+транзитивності. Відношення толерантності = симетричність+рефлексивність. Більш природним, ніж через відношення толерантності, видається визначення зразку (класу) у рамках теорії нечітких множин.
Системи розпізнавання: розробка системи розпізнавання та власне розпізнавання. 2) Власне розпізнавання - в три етапи: отримання первинної інформації; виділення ознак; класифікація. 1) Розробка системи розпізнавання: формування навчальної вибірки; вибір інформативної множини ознак; навчання.
Прості спеціалізовані методи розпізнавання: співставлення з еталоном, зондів, маркування, квазитопологічного розпізнання. Ці методи вимагають детального вивчення об’єктів, що розпізнаються. Навчання фактично відсутнє, і об’єкти, які розпізнаються, мало змінюються.
Два класи сучасних методів розпізнавання: 1) статистичні (дискримінантні) та 2) структурні (або синтаксичні, або лінгвістичні). Вибір методу розпізнавання істотно залежить від апріорної інформації про об’єкти, що розпізнаються.
1) Статистичні методи розпізнавання. Типова постановока задачі: Заданий певний набір класів K1, … , KM. Для кожного класу заданий деякий набір його представників. Потрібно для будь-якого об’єкту визначити, до якого класу він відноситься. Кожний об’єкт характеризується певним набором ознак, тобто відображається на деяку точку простору ознак. Цей набір ознак є фіксованим та спільним для всіх об’єктів.
Навчальній вибірці відповідає матриця даних Y=(yij; i =1,…,q; j = 1, … , n+1). Тут q - загальна кількість представників усіх класів, n - кількість ознак (розмірність простору ознак) yin+1 - клас, до якого відноситься i- й об’єкт. Будь - якому об’єктові відповідає вектор даних x = (x j; j = 1,…,n). При цьому природно визначити відстань у просторі ознак, яка являтиме собою мірило схожості об’єктів.
Статистичні методи явно або неявно спираються на гіпотезу компактності. Вважається, що класові відповідає компактна множина точок у деякому просторі ознак. Різні типи ознак: дихотомічні (ознака може бути присутня або відсутня; наприклад - є крила або немає крил); номінальні (наприклад, колір: червоний, синій, зелений і т.п.); порядкові (наприклад, "великий" - "середній" - "маленький"); кількісні. Метрики для кількісних ознак: евклідова відстань та зважена євклідова відстань. Для некількісних: відстані Хеммінга, Кендала, Юла, Рассела і Рао та ін.
"Первинні дані" можуть бути дуже різної природи. Обмежимося розпізнаванням неперервних сигналів та зображень. Типова схема розпізнавання таких об’єктів у загальних рисах відповідає раніше описаній схемі і включає до себе датчики, блок попередньої обробки, блок класифікатора і пам’ять. Первинні дані збираються за допомогою спеціалізованих датчиків. Стандартним прийомом є дискретизація, або цифрування.
Теорема
Котельникова (теорема Шеннона, теорема
відліків) (про частоту дискретизації):
Н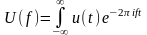 ехай
для функції u(t) визначене перетворення
Фур’є, і спектр цієї функціїї неперервний
та обмежений смугою частот від 0 до
F. Тоді функція повністю визначається
своїми дискретами, взятими через
інтервали часу t
=1 / (2F). Перетворення Фур’є U(f)
функції u(t) визначається за формулою
:
ехай
для функції u(t) визначене перетворення
Фур’є, і спектр цієї функціїї неперервний
та обмежений смугою частот від 0 до
F. Тоді функція повністю визначається
своїми дискретами, взятими через
інтервали часу t
=1 / (2F). Перетворення Фур’є U(f)
функції u(t) визначається за формулою
:
До класичних методів виділення ознак належать глобальні перетворення: лінійні або нелінійні. До таких перетворень відносяться перетворення Фур"є, Уолша, Хоара. Ознаки - спектральні коефіцієнти відповідних рядів => різке скорочення розмір. простору ознак ("стиск даних").
Попередньою обробкою є також зменшення шумів (фільтри Калмана, Вінера) Статистичні методи розпізнавання: а)імовірнісні та б)детерміністські.
а)Ймовірнісні методи. Матриця даних - набір реалізації деякого випадкового процесу. Класичним є байєсівській підхід. Iдея: мiнiмiзацiя ризику, пов’язаного з помилковим рiшенням. (Його можна розрахувати, якщо відомі умовні густини розподілу векторів ознак за умови, що об’єкт належить до певного класу.)
б)Детерміністський підхід: розподіл простору ознак на ділянки, які відповідають класам, відбувається на основі безпосереднього аналізу відстаней між об’єктами (точками цього простору). Класичним є правило найближчого сусіда. Об’єкт відноситься системою розпізнавання до того класу, до якого належить його найближчий сусід з навчальної вибірки.
2)Структурно-синтаксичні(лінгвістичні)методи розпізнавання розглядають структуру об’єктів та звязки між їх елементами. Декомпозиція здійснюється до атомарних елементів. Кожний клас описується деякою формальною мовою. Тоді набір атомарних елементів – це алфавіт цієї мови, а представники класу - це фразами, або речення цієї мови. Правила формування фраз з атомарних елементів складають граматику мови. Мова, породжена граматикою - це сукупність всіх ланцюгів, що складаються лише з основних символів на основі послідовного застосування правил граматики до початкового символа.
Типова система синтаксичного розпізнавання образів складається з трьох блоків: попередньої обробки; представлення об’єкта, метою якого є виділення атомарних елементів та відношень між ними; синтаксичного аналізу.
Основною задачею блоку представлення об’єкта є опис об’єкта деякою фразою, тобто деяким ланцюжком, що складається з атомарних елементів. Синтаксичний аналіз полягає у граматичному розборі фраз (зверху вниз та знизу вгору).
Традиційні граматики для утворення фраз використовують ланцюгову операцію конкатенації. Для опису складних зображень є більш складні граматики: графові граматики, мова опису зображень PDL, веб-граматики, плекс-граматики, ін.
Відомими є метод потенціальних функцій, метод групового урахування аргументів, метод припустимих перетворень, логічні методи розпізнавання. Останні традиційно відносяться до структурних методів. В їх основі лежить представлення відповіді про належність об’єкта до певного класу як логічної функції від його ознак. Ознаки при цьому є булевими. Класифікація при такому підході аналогічна логічному виведенню в експертних системах.