

Задача медицинской диагностики как задача распознавания образов
При решении практических задач анализа медицинских и биологических наблюдений для последующего принятия решения о диагностике и прогнозировании состояния исследователю приходится иметь дело с совокупностью одновременно зафиксированных на объекте исследования количественных и качественных признаков (x1,x2, …,xp). Абсолютное большинство этих признаков подвержено некоторому неконтролируемому разбросу при переходе от одного объекта наблюдения к другому, при изменении состояния одного и того же объекта и т.д. Так, например, исследуя однородные (по возрастному и национальному составу) группы пациентов с целью оценки воздействия на них некоторым лекарственным препаратом, т.е. ,подразумевая подx1 ,например, частоту сердечного ритма, подx2-систолическое давление, подx3 -диастолическое давление и т.д., нетрудно убедиться, что при переходе от одного пациента к другому каждый из признаков имеет некоторый неконтролируемый разброс. Однако для каждого заболевания на однородной группе объектов это варьирование признаков, как правило, подчиняется некоторым общим тенденциям и закономерностям как в смысле пределов, так и в смысле зависимости варьирования.
В общем случае постановку задач сбора
и накопления медико-биологических
данных для последующего принятия решений
можно представить в виде схемы (рис.6.2).
3десь осьJотражает
последовательность накопления информации
о признакахxj
.Ось I отражает
накопление объектов исследованияfi(может быть один и тот же объект в
различных состояниях). Осьtхарактеризует возможность изменения
и накопления объектов множества F во
времени, т.е. учитывает динамические
особенности данных объектов исследования.
В этом случае совокупность наблюдаемых
величин (объектов и признаков)
![]() может
быть представлена в виде матрицы
таблицы экспериментальных данных
(ТЭД), что позволяет наметить решение
основных задач, возникающих при
диагностике и прогнозировании
состояния:
может
быть представлена в виде матрицы
таблицы экспериментальных данных
(ТЭД), что позволяет наметить решение
основных задач, возникающих при
диагностике и прогнозировании
состояния:
Снижение размерности исходного пространства признаков;
Разбиение исходных данных на однородные группы;
Классификация исходных данных;
Принятие решения;
Отображение полученных данных.
Структурный подход к обработке экспериментальных данных
Основные трудности при обработке экспериментальных данных связаны, прежде всего, с необходимостью установить достоверность тех или иных априорных предположений, принятых исследователями и используемых в том или ином виде в математических моделях, на которых основываются алгоритмы обработки данных.
Именно желание приблизить различные статистические методы анализа данных к исследователю породило огромное количество частных схем решения задач обработки. В тоже время для обоснованного выбора одной схемы при решении конкретной задачи требуются уже знания профессионала в области обработки данных, которыми чаще всего не

Обладает исследователь в предметной области (медик).
В настоящее время методы обработки экспериментальных данных используются все более широким кругом ученых и специалистов, работающих в разных областях науки и техники. В силу различной специфики исследований в этих областях данные экспериментов (испытаний, наблюдений) существуют в различных формах, отличаясь как по уровню формализации (описание на естественном языке, измерение при помощи приборов), так и по способу представления (графический, текстовой, числовой…).
При автоматизации научных исследований данные, прежде всего, должны отражать существующую модель предметной (исследуемой) области реального мира. Очевидно, в этом случае структура изучаемого явления должна найти свое отражение в структуре данных, для того чтобы по ней можно было делать выводы о закономерностях, присущих реальности. Отметим, что если структура данных (СД) адекватно отражает предметную область реального мира, то на ее основе возможно решение многих исследуемых проблем и, наоборот, если данным навязана конкретная, узкая структура, то они могут быть вообще непригодны для анализа. Так, предположив, например, нормальность распределения некоторой характеристики (т. е. ограничив СД заранее нормальным законом), можно прийти к неверным выводам по всему комплексу изучаемых вопросов, если исходное предположение о законе распределения было неверно (такая проблема возникла, например, при обработке психодиагностических данных).
Таким образом, встает задача выявления и исследования структуры анализируемых данных. Мы под СД будем понимать (поскольку анализируются не только количественные, но и качественные, описательные характеристики объектов множества Е) совокупность описаний объектов и отношений между этими описаниями. Будем считать, что характеристики, которыми описываются объекты Е, т. е. множество признаков в ТЭД, адекватно отражают существо решаемой задачи. Тогда исследование СД сводится к анализу пространственной структуры множества точек — образов объектов Е в П - пространстве, поскольку отношения между объектами Е реализуются через значения признаков — координат объектов в Пp.
Как правило, целью анализа СД является построение математической модели исследуемого явления в виде функционального, статистического или иного описания. Такая модель позволяет заменить экспериментальные данные как способ представления явления на некоторый более общий закон, из которого исходные данные вытекают уже как частный случай. Следовательно, СД можно рассматривать как пространственное выражение закономерностей, которые эти данные представляют, или, иначе, как представление данных в виде некоторого описания, характеризующего расположение объектов Е в П - пространстве.
Поскольку исследуемое явление может описываться несколькими различными моделями, анализ СД содержит, как правило, два необходимых этапа.
Разбиение множества объектов Е на непересекающиеся классы S1, …Sk, каждый из которых соответствует определенной модели исследуемого явления или одной части исследуемого явления. Эта задача решается, как правило, методами автоматической классификации или распознавания образов.
Поиск законов, описывающих поведение объектов каждого из классов S1, …Sk. Эта задача может решаться самыми разнообразными методами: например, при помощи регрессионного, факторного анализов; интерполяции, аппроксимации; методов снижения размерности и т. д.
Отметим, что вследствие естественной иерархичности структуры явлений реального мира иерархической же структурой зачастую обладают и экспериментальные данные, поэтому указанные этапы анализа СД могут повторяться для выявления собственных структур множеств S1, …Sk и т. д.
Рассмотрим более подробно первый этап анализа СД. На нем для получения разбиения Е следует применить некоторый математический метод (алгоритм) Н. Выбор метода уже сам по себе накладывает на данные в пространстве описания некоторую структуру (например, метрику), которая может в принципе исказить исходную СД. Различные методы классификации (распознавания) могут давать в результате различные разбиения Е на классы, поэтому встает задача обоснованного выбора либо метода классификации, либо одного из полученных разбиений. Здесь большую роль могут сыграть априорные знания исследователя и его профессиональный опыт. Они оказываются, как правило, полезными при анализе разбиения Е при помощи различных математических методов.
Введем подмножества Аi
![]()
как субъективную оценку исследователем количества частейlобъемом |Аi|, на которое должно быть классифицировано множество Е. Далее введем подмножества Sk, k=1,…, т, где т —объективное количество частей объемом |Sk|, на которое может быть классифицировано множество Е с помощью некоторого набора математических правил Н при заданном пространстве описания.
Определение. Под классом будем понимать объединение объектов исследования в подмножество Skс помощью того или иного выбранного метода. В общем случае состав и количество классов могут изменяться в зависимости от метода обработки, т. е. от выбора решающего правила.
Определение. Под образом Аiбудем понимать объединение объектов множества Е вlгрупп, соответствующих субъективной оценке исследователя.
Таким образом, здесь появляется возможность учета целевой установки, или, более точно, целевой функции исследователя, которую определим как проблему согласования классификации Skс ее полезностью с точки зрения «учителя» без каких-либо априорных добавлений к исходной совокупности сведений.
Итак, основным математическим аспектом решения, исходя из определений, является поиск допустимого алгоритма (системы алгоритмов) при согласованииAi и Sk.
Для уяснения ролиAi, рассмотрим варианты возможной взаимосвязи междуAiи Sk:
образы разделяются полностью:
![]()
![]()
![]() ,
,
![]() ,
приi
j;
,
приi
j;
образы имеют области пересечения:
![]()
![]()
![]() ,
приi
j;
,
приi
j;
Первая ситуация возникает в следующих случаях:
![]() (6.1)
(6.1)
![]() (6.2)
(6.2)
Более сложная вторая ситуация отражается соотношением
![]() (6.3)
(6.3)
Случай (6.1) соответствует частному случаю, когда правило принятия решения удовлетворяет исследователя и на основе выбранного математического аппарата обеспечивает взаимно однозначную связь между классами и образами.
Случай (6.2) является более сложным вариантом, показывающим необходимость компоновки образа из различных классов. Этот случай указывает на всегда имеющуюся возможность введения аппроксимаций высшего порядка, которые в принципе могут отражать собой более глубокую дифференциацию данных, чем это необходимо для конкретной задачи. Смысловая интерпретация классов, составляющих конкретный образ, является обязательным этапом серьезного исследования.
Случай (6.3) является наиболее общим. Он представляет собой ситуацию, когда окончательное решение задачи обработки данных возможно только при введении исследователем дополнительных сведений или, что не всегда принимается во внимание, корректировки своих субъективных представлений о сущности искомого результатаAi.. Именно этот вариант наиболее типичен для обработки экспериментальных данных и обосновывает необходимость введения какой-либо формы диалогового режима.
Дадим графическую интерпретацию приведенных ситуаций. На рис. 6.3, а представлен случай (6.1). В приведенном примере m=l=4. Следовательно, Ai=Sk.
Более сложная ситуация (6.2) иллюстрируется рис. 6.3, б. В этом случае l=2,m=4. Следовательно, вниманию исследователя должны быть представлены следующие варианты:
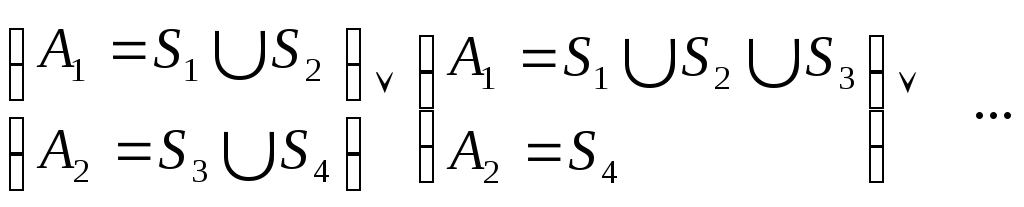 т.д.
т.д.
Случай (6.3) может быть интерпретирован следующим образом (рис. 6.3, в): математический аппарат Н и априорная информация исследователя Аiне согласованы между собой. Следовательно, надо либо изменить пространство описания Пp, либо искать другие решающие правила Н, либо исследовать физический смысл полученного группирования и внести коррективы в априорное предположение исследователя об образе Аi.

Отметим, что такое разнообразие альтернатив исследования является в какой-то мере учетом поискового характера решений в исследовательском процессе, приводящего к необходимости постановки управляемого эксперимента. Грубейшей ошибкой следует считать восприятие как догмы результатов работы какого-либо алгоритма классификации без творческого осмысления специалистом полученных результатов.
Выделение классов, т. е. объединение объектов Е в возможно более однородные группы, в общем случае состоит в определении семейства частей (подмножеств) Skмножества Е, образующих покрытие этого множества. Задача состоит в том, чтобы из всех возможных покрытий множества Е выбрать такое, которое окажется наиболее согласованным с информацией исследователя о допустимых разбиенияхаi.
Разобьем множество Е из N элементов на т подмножествS1, … ,Smтак, что
![]()
Рассматривая выбор из возможных разбиений как комбинаторную задачу, отметим, что задание образов Аiили правил Н можно интерпретировать как сужение комбинаторного перебора.
Итак, если возникает задача: сколько элементов, принадлежащих конечному множеству, обладает некоторым свойством или некоторой совокупностью свойств, то это задача пересчета. Если же при этом требуется список элементов, обладающих этим свойством (или свойствами), то приходим к задаче перечисления. Однако при большом числе элементов (объектов) множества Е решение задачи перечисления прямым комбинаторным методом приводит к большому объему вычислений. Поэтому-то на практике так часто и решают задачу структуризации. В этом случае вместо соответствующего перечисления отдельных объектов выделяются подмножества Skи правила вхождения элементов (объектов) множества Е в Skс помощью какого-либо соотношения (критерия Н).
Интерпретация структуризации как экономного описания экспериментальных данных позволяет ввести ограничение сверху, т. е. исключить из рассмотрения слишком «мелкие» разбиения. При этом появляется возможность априорного ограничения числа подмножеств, или, иными словами, выделения максимального числа покрытий множества Е, внутри которого возможен комбинаторный выбор.
Практически приходим к оптимизационной задаче — нахождению минимального числа т классов Skмножества Е при условии максимальной «плотности»Sk. Под плотностью Skпонимается отношение числа объектов, принадлежащих выделенному подмножеству, к объему, который оно занимает в пространстве описания:
 (6.4)
(6.4)
Тогда задача выявления СД может быть представлена как выбор таких разбиений {P*} множества Е, при котором получаем минимальное число классов максимальной плотностиk. Свяжем с каждым допустимым разбиениемPiвеличину средней плотности
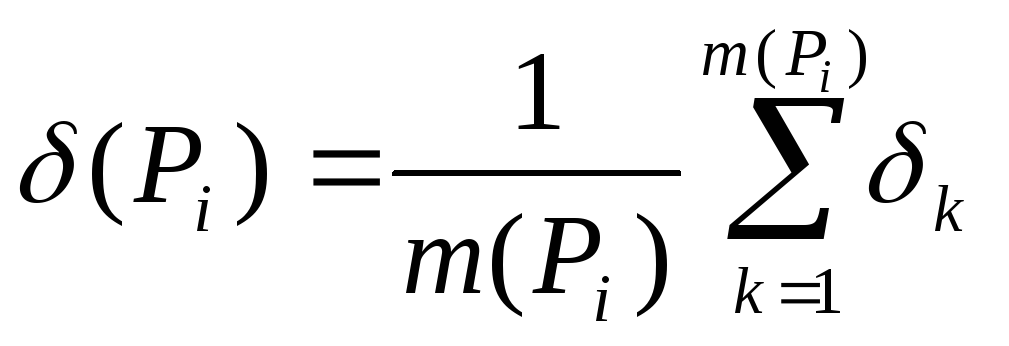
В этом случае разбиения {P*} можно искать, например, как одновременно удовлетворяющие условиям:
![]() (6.5)
(6.5)
![]() (6.6)
(6.6)
Выражения (6.5), (6.6) позволяют еще более сузить перебор. Описанный комбинаторный принцип структуризации дает возможность проводить сопоставительный анализ между отдельными объектами, составляющими образыAi, и классы Sk, что является необходимым условием организации диалогового режима при создании интерактивной системы обработки данных. Теоретико-множественный подход к решению задач структуризации и упорядочения объектов, использующий в своей основе принципы комбинаторной геометрии, позволяет ввести и использовать в качестве критерия упорядочения Skвеличину условной «плотности»k. Отсюда следует теоретико-множественная интерпретация задачи упорядочения и классификации как взаимно однозначного отображения множества объектов исследования Е во множество допустимых решений V, которое определяется в пространстве R1. Такое определение дает возможность визуального восприятия объектов Е, заданных в многомерном пространстве описания, т. е. ЕVR1.
Следует заметить, что в любых схемах принятия решения всегда имеет место сведение многокритериального (многопараметрического) описания задачи к однопараметрическому, так как пространство R1 — числовая шкала — обладает естественным и однозначным отношением порядка.
По сути дела, вся проблема заключается в том, по какой математической схеме реализуется подобная редукция. Так, например, в задачах распознавания образов байесовское решающее правило для определения принадлежности вектора х(1), ..., х(p)к одному из двух образов А1, А2описывается выражением:
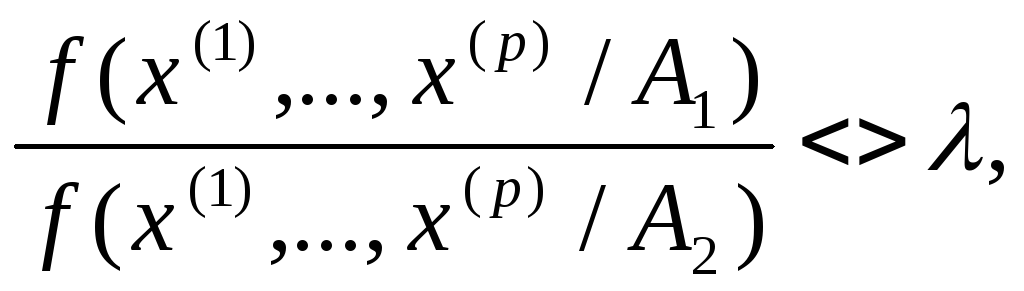
гдеf(•) — условная функция плотности распределения образа;R1— пороговое значение, равное отношению априорных вероятностей появления объектов образовA2и А1, т. е. окончательное решение принимается в одномерном пространстве.
На рис. 6.4, а изображен случай распознавания образов, т. е. некоторый результат отображения ЕVR1, когда все объектыA1отображаются, к примеру, в левую часть, а все прочие — в правую. На рис. 6.4, б рассматривается случай автоматической классификации, когда решение о группировании принимается по какому-либо критерию, так или иначе связанному с оценкой критерия «плотности»и установления порога отсечки0. Именно необходимость выбора значения порога отсечки0или0’и определяет возможную неоднозначность решения задачи классификации. Приведенная на рис. 6.4, а, б условная интерпретация задач распознавания и классификации показывает роль субъективной классификации, задаваемой «учителем» в виде зон принятия решения на R1, а выбор порога0— роль. На рис. 6.4, в показана условная интерпретация задачи функционального упорядочения, возникающей, например, при оптимизации на равномерной сетке вПр. здесь=F ((х(1), . . ., х(p)), где F — оптимизируемая функция;: ПpR1 — функция отображения.
формального математического критерия.

Приведенная выше интерпретация позволяет анализировать с единых позиций различные математические схемы обработки данных, исследуя свойства подобных отображений и ограничения их применения.