

Трехзначная логика
3Vl(three-valued logical)
T-true
F-false
U-unknown
|
AND |
F |
T |
U |
|
F |
F |
F |
F |
|
T |
F |
T |
U |
|
U |
F |
U |
U |
|
OR |
F |
T |
U |
|
F |
F |
T |
U |
|
T |
T |
T |
T |
|
U |
U |
T |
U |
|
NOT |
F |
T |
U |
|
|
T |
F |
U |
NULL значение не равно самому себе
NULL= NULL=U
Неверно что NULL значение равно самому себе NOT NULL=U
Ситуации, когда возможно появление неизвестных или неполных данных, разработчик имеет на выбор два варианта:
Ограничиться обычными значениями типов данных и не использовать NULL значение. Вместо неизвестных данных либо вводить значение ноль или значение специального вида. На пользователя в этом случае ложиться ответственность за правильную трактовку таких данных.
Полагает использование NULL значение вместо неизвестных данных. Основной проблемой является использование трехзначной логики при оперировании с данными, которые могут содержать NULL значения. При неаккуратном формулировании запросов даже самые простые запросы могут давать неправильные результаты (ответы).
Индексирование
Под индексом понимают средство ускорения поиска записей в таблице, а так же других операций использующих поиск (сортировка, модификация, удаление, исключение).
Индекс исполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. Варианты решения проблемы организации физического доступа информации зависит:
от вида содержимого в поле ключа индексного файла,
от типа используемых ссылок на запись основной таблицы,
от метода поиска записей.
В поле ключа индексного файла хранятся значения ключевых полей индексированной таблицы или свертка ключа (хеш-код).
Преимущества хранения хеш-кодасостоят в том, что длина свертка независимо от длины исходного значения ключа всегда имеет постоянную и малую величину, что снижает время для операций поиска данных.
Недостатком хешированияявляется то, что необходимо выполнять операцию свертки:
это требует дополнительного времени
могут возникнуть коллизии
Коллизии– это когда свертка дает одинаковый хеш-код для различных значений ключа.
На практике чаще всего используются два метода поиска последовательный и бинарный. Индексация таблиц проводиться с применением двух схем:
одноуровневой
двухуровневой
Одноуровневая схема.
В индексном файле хранятся короткие записи, имеющие по два поля:
поле значения старшего ключа, адресуемого блока
поле адреса начала этого блока
В каждом блоке записи располагаются в порядке возрастания значения ключа или свертки. Старшим ключом каждого блока является ключ его последней записи.


Алгоритм поиска для данной схемы состоит из трех шагов:
образование свертки значения ключевого поля для искомой записи
поиск в индексном файле записи о блоке, значение 1-го поля которого больше полученной свертки
последовательный просмотр записей блока до совпадения сверток искомой записи и записи блока. В случае коллизии сверток ищется запись, значение ключа которой совпадает со значением ключа исходной записи.
Недостаток: хранение ключей или сверток записей вместе с самими записями – это приводит к увеличению времени поиска из-за большой длины просмотра.
Двухуровневая схема.
В этой схеме индекс основной таблицы распределен по совокупности файлов: одному файлу главного индекса и множеству файлов с блоками ключей.


Открытое хеширование.
Организация данных при открытом хешировании:
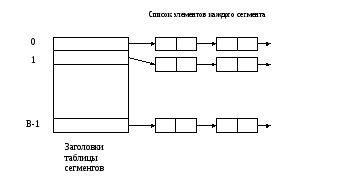

Основная идея:потенциальное множество разбивается на конечное число классов.
Классы нумеруется от 0 до B-1. ДляBклассов строится хеш-функцияhтакая, что для любого элементаxисходного множестваh(x) є [0,B-1] (целочисленное значение),т.е. которое соответствует классу, которому принадлежит элемент х.
Элемент xназываютключом,h(x)– хеш-кодом,x(свертка ), классы называютсегментами.
Массив называемый таблицей сегментови проиндексированный номерами сегментов содержит заголовки дляBсписков элементxii-го списка - это элемент исходного множества, для которогоh(x) =i.
Если исходное множество состоит из n элементов, то средняя длина списков будет равна n/B.
Не всегда ясно как выбрать хеш-функцию так, чтобы она, примерно наполовину, распределила элементы исходного множества по всем сегментам.
Пример простой хеш-функции:
function h(x: nametype) : …B-1;
var
i, sum, integer
begin
sum:=1 to 10 do
sum:=sum+ord(x[i])
h:= sum mod B
end;
nametype=array [1…10] of char