

4. Главные компоненты в задачах классификации
а) Общие идеи использования главных компонент в задачах классификации. Дуализм в постановке задачи. Очевидно, возможность геометрической интерпретации и возможность наглядного представления исследуемых наблюдений Х’i = (xi(1), ... , xi(p) ) (i=l,2, ... , п) существенно облегчает решение задач по их классификации, и в частности проведение таких этапов, как предварительный анализ классифицируемых наблюдений, выбор метрики, выбор начальных приближении для неизвестного числа классов k, для системы эталонных множеств Е, наконец, для самого искомого разбиения S.
Так, например, одного взгляда на рис. 4.3, на котором изображены проекции тридцати одного (п=31) восемнадцатимерного наблюдения (р = 18) на плоскость первых двух главных компонент (построенных по исходным 18 признакам x(1), x(2),…, x(18)), достаточно, чтобы обнаружить четкое распадение исследуемой совокупности наблюдений на 3 класса2.

Рис. 4.3. Расположение проекций 18-мерных наблюдений на плоскость первых двух главных компонент y(1), y(2)
А попробовал бы исследователь уловить это распадение непосредственно в исходном восемнадцатимерном пространстве X!
Источником нашего оптимизма в отношении результатов использования такого проектирования исследуемых многомерных наблюдений на плоскость являются, как легко сообразить, геометрические экстремальные свойства главных компонент, в частности вышеупомянутые свойства 1 — 3, в соответствии с которыми проектирование исходной совокупности наблюдений в пространство меньшей размерности, «натянутое» на р' первых главных компонент (р' < р), наименее искажает ее геометрическую конфигурацию.
Перед тем как перейти к некоторым конкретным примерам применения главных компонент в задачах классификации обратим внимание читателя на возможную двойственность (дуализм) в интерпретации многомерного наблюдения Х’i = (xi(1), ... , xi(p) ) вообще, и в постановке задачи при эксплуатации метода главных компонент в частности.
Действительно, если в матрице наблюдений

рассматривать в качестве наблюдения столбцы Xi, то классифицируемыми объектами (в количестве п штук) будут объекты, на каждом из которых было замерено по р признаков x(1), x(2),…, x(p), так или иначе характеризующих его состояние. Если же в качестве «наблюдения» рассматривать строки X*’v = (x1(v), ... , xn(v) ) этой матрицы, то классифицируемыми объектами будут уже сами признаки (в количестве р штук), рассматриваемые, соответственно, в n-мерном пространстве X*.
Очевидно, задачи классификации в одном (X) и в другом (Х*) пространстве преследуют совершенно разные цели. Относительно целей классификации в пространстве Х мы уже говорили- Что же касается классификации в пространстве X* (т. е. классификации самих признаков) то наличие небольшого (сравнительно с р) числа однородных групп признаков позволяет сделать вывод о близости (коррелированности, взаимном дублировании) признаков, входящих в одну группу, и, в конечном счете, существенно снизить размерность исходного факторного пространства X, оставив, например, для дальнейшего рассмотрения лишь но одному представителю от каждой такой группы.
Замечание о необходимости нормировки в пространстве X*. Классифицируя признаки, необходимо помнить, что два признака X*v и X*m естественно считать близкими не только в случае сравнительной малости расстояния (X*v и X*m) (евклидового типа) между ними, но и в случае их достаточно простой взаимной зависимости, например X*v =c X*m, где с — некоторый скалярный множитель. Для того чтобы это оказалось учтенным при проектировании «наблюдений» X*1, X*2, …, X*p в пространство меньшей размерности с помощью метода главных компонент, необходимо предварительно (до применения метода) соответствующим образом пронормировать исходные данные в пространстве X*, например, переходя к «наблюдениям»
![]()
где
 —
среднее арифметическое
v-го
признака, подсчитанное по п
исходным наблюдениям.
—
среднее арифметическое
v-го
признака, подсчитанное по п
исходным наблюдениям.
И, наконец, в целях большего удобства технического представления результатов исследования (графиков, таблиц и т. п.) помимо необходимой нормировки иногда еще дополнительно центрируют рассматриваемые наблюдения X*v, т. е. переходят, в конечном счете, к наблюдениям
![]() ,
,
где
![]() —среднее арифметическое (центр
тяжести) наблюденийX*1,
X*2,
…, X*p.
—среднее арифметическое (центр
тяжести) наблюденийX*1,
X*2,
…, X*p.
В дальнейшем мы, как правило, будем предполагать вспомогательные операции нормировки и центрирования в пространстве X* выполненными, но в целях упрощения обозначений, будем опускать две верхние волнистые черточки при записи соответствующих пронормированных и процентрированных наблюдений.
б) Применение главных компонент при анализе структуры семейного потребления. В процессе исследований по проблеме «Типология потребителей и потребления» нами решалась следующая частная задача. Объект исследований — семья. Набор измеряемых на каждом «объекте» признаков — удельные характеристики потребления (в расчете на одного члена семьи в единицу времени) по различным статьям расходов (табл. 4.1), — всего в количестве 31 штуки (р = 31)3. На первом этапе исследований была отобрана так называемая «контрольная» выборка семей небольшого объема (п=106).
Таблица 4.1
|
Признак |
Содержание признака |
Признак |
Содержание признака |
|
Сумма, затрачиваемая на (в руб. в удельном исчислении) |
Сумма, затрачиваемая на (в руб. в удельном исчислении) | ||
|
x (1) x (2)
x (3) x (4) x (5) x (6) x (7)
x (8) x (9) x (10) x (11) x (12) x (13) x (14) x (15) x (16) x (17) x (18) x (19) x (20)
|
ткани готовую одежду (без меховой) меховую одежду трикотаж обувь книги, газеты музыкальные инструмен-ты спорт хобби мебель хлебобулочные изделия овощи мясные продукты рыбные продукты жиры яйца сахар кондитерские изделия общественное питание (включая расходы временно выехавших членов семьи) |
x (21)
x (22) x (23) x (24)
x (25)
x (26)
x (27)
x (28)
x (29)
x (30) x (31) |
культурно-просветительные мероприятия транспорт услуги почты и телеграфа жилищно-коммунальные расходы продукты растительного происхождения продукты животного происхождения услуги (включая x (21) и x (24), плюс бытовые и т.п.) общественное питание (исключая расходы временно выехавших членов семьи) все продовольственные товары алкогольные напитки все промышленные товары |
Результаты
проектирования тридцати одного
106-мерного наблюдения
X*’v
= (x1(v),
... , x106(v)
), v
=
1, 2, ..., 31 —
на плоскость первых двух главных
компонент (![]() )
представлены на рис.
4.4. Читатель,
по-видимому, согласится с нами, что если
разбить исследуемые признаки на пять
условных классов так, как это сделано
на рис.4.4,
то это даст
пищу для достаточно естественного
)
представлены на рис.
4.4. Читатель,
по-видимому, согласится с нами, что если
разбить исследуемые признаки на пять
условных классов так, как это сделано
на рис.4.4,
то это даст
пищу для достаточно естественного

Рис.
4.4. Расположение проекций 106-мерных
наблюдений (из двойственного пространства
X*)
на плоскость двух главных компонент
(![]() ).
Исследование взаимосвязей между
признаками, характеризующими структуру
и объем семейного потребления.
).
Исследование взаимосвязей между
признаками, характеризующими структуру
и объем семейного потребления.
содержательного анализа взаимосвязей, существующих между исследуемыми признаками (лишь «расходы на кондитерские изделия» x(19) дали, вряд ли поддающиеся содержательной интерпретации результаты проектирования: они оказались почему-то в классе, объединяющем в себе расходы на услуги и на наиболее необходимые промышленные товары).
в) Применение главных компонент при анализе производительности труда рабочих. Различные показатели производительности труда Z' = (z(1), z(2), …, z(m)) характеризуют, как известно, отношение реально произведенной продукции к затратам труда на ее производство. Задача изучения зависимости показателей производительности труда от набора регулируемых (и нерегулируемых) признаков X' = (x(1), x(2), …, x(p)), характеризующих технический и организационный уровень производства, личные качества рабочих, социально-демографические условия их жизни, постоянно (и правомерно) привлекает к себе пристальное внимание исследователей.
Однако среди различных возможных подходов к решению этой задачи мы бы выделили следующие две схемы исследования.
Схема 1.
Разбиение исследуемой совокупности рабочих на однородные группы в пространстве объединенных признаков (X', Z'), например, с помощью главных компонент, построенных по набору признаков x(1), x(2), …, x(p), z(1), z(2), …, z(m).
Статистическое исследование зависимостей типа Z = fi (X), произведенное отдельно внутри каждой однородной группы, выявленной на первом этапе (i — номер группы, внутри которой анализируется искомая зависимость).
Схема 2.
1) Разбиение исследуемой совокупности рабочих на однородные группы в пространстве признаков-аргументов X, например, с помощью главных компонент, построенных но набору признаков x(1), x(2), …, x(p).
2)
Расщепление вектора признаков-аргументов
X'=
(x(1),
x(2),
…, x(p))
на два подвектора: подвектор X(1)’
= (x(1),
x(2),
…, x(q))
признаков
(как правило, труднорегулируемых),
описывающих технический и организационный
уровень производства (q
< р),
и подвектор X(2)’
=
(x(q+1),
x(q+2),
…, x(p))
признаков (регулируемых), описывающих
социально-демографические условия
труда. Затем разбиение исследуемой
совокупности рабочих на однородные
группы
![]() в
подпространствеХ(1)
«нерегулируемых»
признаков,
а также
на однородные группы
в
подпространствеХ(1)
«нерегулируемых»
признаков,
а также
на однородные группы
![]() в
подпространстве Х(2)
«регулируемых» признаков.
в
подпространстве Х(2)
«регулируемых» признаков.
Статистическое исследование зависимостей типа
![]() (
j=1,2,…,k1)
(
j=1,2,…,k1)
и
![]() (
l=1,2,…,k2),
(
l=1,2,…,k2),
произведенное отдельно внутри каждой однородной группы подпространства x(1) (при аргументах X(2)) и подпространства Х(2) (при аргументах Х(1)). Здесь
![]()
означает
векторную функцию от (р
— q)
переменных x(q+1),
x(q+2),
…, x(p),
описывающую зависимость
Z от Х(2)
при условии, что значения «нерегулируемых»
аргументов x(1),
x(2),
…, x(q)
принадлежат
области Х(1).
Аналогично определяется векторная
функция ![]() .
.
Ниже приводятся результаты статистического анализа исходных данных по 100 работницам-ткачихам ( n = 100) льнокомбината «Красная текстильщица» г. Нерехта Костромской области, составляющим более 80% всей численности ткачих комбината4. Эти результаты можно рассматривать как фрагменты осуществления этапов 1 и 2 в вышеописанных схемах исследования.
Обозначение и содержание восемнадцати исследуемых признаков (р = 18) приведены в табл. 4.2.
Таблица 4.2
|
Признак |
Содержание признака |
Признак |
Содержание признака | |
|
Показатели эффективности труда: |
Ассортимент вырабатываемой продукции (в качестве сырья): | |||
|
z(1)
z(2)
z(3) |
Условно-натуральный показа-тель часовой выработки рабо-чего места (в метро-уточинах) Выполнение нормы-выработки (в процентах) заработная плата (в руб.) |
x(6) x(7)
x(8) |
номер уточной пряжи число обрывов нитей остова на 1000 м одиночной нити сортность ткани | |
|
Показатели состояния и степени использования оборудования: |
Показатели специализации рабочих мест: | |||
|
x(1)
x(2)
x(3) x(4)
x(5) |
производительность ткац-кого станка (в метро-уточин в час) скорость ткацкого станка (ударов в мин.) ширина суровой ткани (метров) простой оборудования (в процентах) межремонтный цикл (месяцев) |
x(9) |
количество артикулов, вырабатываемых на рабочем месте | |
|
Показатели социально-демографических условий: | ||||
|
x(10)
x(11) x(12) x(13)
x(14)
x(15)
|
трудовой стаж по специальности (лет) возраст (лет) образование (классов) число несовершеннолетних детей в семье среднедушевой доход семьи среднедушевой размер жилой площади (кв. м) | |||
Расщепление вектора признаков-аргументов Х на два подвектора носит, очевидно, условный характер и зависит как от конкретных условий производства, так и от конкретных целей исследования. В нашем случае в подвектор Х(1) были включены первые 9 компонент вектора X.
Учитывая разнородный физический смысл единиц измерения исследуемых восемнадцати признаков, до применения метода главных компонент все эти признаки были пронормированы с помощью своих выборочных среднеквадратических отклонений s, т. е. был осуществлен переход к новым (безразмерным) признакам

где
![]()
![]() ,
,
а
![]() (u=z(i)
или
u=x(i)),
(u=z(i)
или
u=x(i)),
Проекция исследуемых ста (n = 100) восемнадцатимерных (р = 18) наблюдений на плоскость первых двух главных компонент y(1)(X, Z) и y(2)(X, Z) построенных по всем рассматриваемым признакам, представлена на рис. 4.5.
Анализ нагрузок исходных признаков на первые две главные компоненты так же, как и тщательное рассмотрение рис. 4.5, позволяет интерпретировать первую главную компоненту у(1) как агрегированую характеристику эффективности и организационно-технических условий труда ткачих, тогда как вторая компонента у(2) характеризует различия между ткачихами, связанные с социально-демографическими и, в первую очередь, с возрастными особенностями (на первые две компоненты, как выяснилось, приходится 63,1% общей суммарной дисперсии признаков). Действительно, вверху по оси у(2) резко выделяется группа молодежи. Ниже оси у(1) расположена основная масса ткачих среднего и старшего возрастов. Ось в свою очередь делит каждую из этих групп па отдельные подгруппы в зависимости or производственных условий н уровня выработки. Как среди молодежи, так и среди работниц старших возрастов слева выделяются ткачихи, находящиеся в более слой-.ных условиях и имеющие низкую выработку (затушеванные геометрические фигуры). Но если среди ткачих старших возрастов работницы с низкой выработкой составляют всего 14%, то среди молодежи их более 30%.

Рис. 4.5 Результаты исследования типологических групп рабочих, имеющих сходные производственные и социальные условия.
Таким образом, примерно треть молодежи имеет низкую выработку. Это связано с тем, что молодые ткачихи работают в более сложных производственных условиях- В то же время основная группа молодежи (45%), которая поставлена в более благоприятные производственные условия, имеет высокую выработку. В первой же группе только 19% ткачих старших возрастов имеют высокую выработку.
На рис. 4.6 представлено расположение тех же ста наблюдений (ткачих) в плоскости первых двух главных компонент y(1)(X(1)) и y(2)( X(1)) , построенных по подвектору признаков Х(1) (рис. 4.6, а), и в плоскости первых двух компонент y(1)(X(2)) и y(2)( X(2)), построенных по подвектору социально-демографических признаков X(2) (рис. 4.6, б).
На обоих рисунках обозначено весьма четкое разделение исследуемых наблюдений на группы. Остановимся несколько подробнее на анализе рис. 4.6 б. Mы видим, по первой главной компоненте y(1)(X(2)) вся совокупность наблюдений делится на две группы, одна из которых (21 человек), как выяснилось, молодежь со стажем 5 лет, характеризующаяся чрезвычайно близкими значениями всех семи социально-демографических показателей — возраст, количество детей и т.д.
Вторая группа — ткачихи с большим стажем работы, гораздо более сильно отличающиеся друг от друга по значениям признаков x(i) (i= 10, 11, ..., 15).
Сами компоненты y(1)(X(2)) и y(2)( X(2)) имеют довольно естественную интерпретацию. Первая главная компонента y(1) имеет большие нагрузки для признаков, характеризующих возраст, стаж
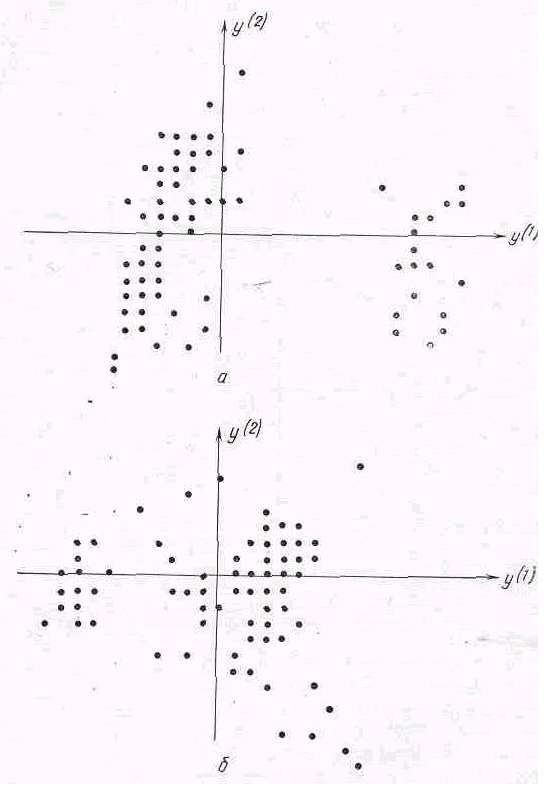
Рис. 4.6.Исследование типологических групп рабочих, имеющих сходные условия организационной и технической оснащенности производства: а) расположение проекций 9-мерныхнаблюденийХi(1) (i=1,2, …,100) на плоскость первых двух главных компонентy(1)(X(1)), y(2)( X(1)); б)расположение проекций шестимерных наблюденийХi(2) (i=1,2, …,100) на плоскость первых двух главных компонентy(1)(X(2)), y(2)( X(2))
(общий и на данном предприятии) и количество детей, а также образование ткачихи. Последний признак имеет знак, противоположный знаку первых четырех из упомянутых выше признаков, вследствие того, что средний уровень образования возрос за последнее время, и поэтому ткачихи старших возрастов имеют преимущественно 8-классное образование, а недавно поступившие на работу ткачихи — в среднем 10-классное образование. Вторая главная компонента y(2) дифференцирует ткачих по материально-жилищным условиям, которые зависят в основном от числа нетрудоспособных членов семьи, в данном случае — от числа детей, так как сравнительно большие нагрузки на эту компоненту имеют признаки x(13), x(14) и x(15).
Из распределения ткачих на плоскости этих двух компонент видно, что на второй компоненте существенные отличия наблюдаются только среди ткачих старших возрастов, в то время как молодые ткачихи близки друг к другу по этой характеристике. Это расположение является естественным следствием более разнообразных жизненных условий, в которых живут ткачихи старших возрастов, по сравнению с молодежью, потому что большинство молодых ткачих живет в общежитии, не имеет еще семьи и детей.
Заметим в заключение, что весьма интересный пример применения главных компонент, в прямой и двойственной постановках задачи, связанный со статистической обработкой экспертных оценок, применительно к задаче классификации картин абстрактной живописи, читатель найдет в [17].