

МЕТОДЫ СНИЖЕНИЯ РАЗМЕРНОСТИ
В настоящей главе мы остановимся на некоторых линейных методах сокращения размерности факторного пространства, т. е. пространства исследуемых признаков Во многих исследовательских работах исходное число р рассматриваемых, т. е. замеряемых на исследуемых объектах, признаков довольно велико, но тем не менее эти измерения следует обработать и осмыслить. Для наглядности картины, простоты интерпретации и упрощения счета очень часто необходимо представить каждое из наблюдений в виде набора чисел, состоящего из существенно меньшего (чем р) количества признаков. При этом оставшиеся признаки могут либо выбираться из числа исходных, либо определяться но какому-либо правилу по совокупности исходных признаков, например как линейные комбинации последних. При формировании новой системы признаков к последним предъявляются разного рода требования, такие, как наибольшая информативность с точки зрения правильного разбиения наблюдений на классы, взаимная некоррелированность, наименьшее искажение внутренней и внешней геометрической структуры множества исходных наблюдении и т. п. В зависимости от варианта формальной конкретизации этих требований мы будем приходить к тому или иному алгоритму снижения размерности.
§ 1. Meтод главных компонент
Главные компоненты представляют собой новое множество исследуемых признаков
y(1), y(2), …,y(n)
каждый из которых получен в результате некоторой линейной комбинации, непосредственно измеренных на объектах, исходных признаков x(1), x(2), …,x(n). Полученные в результате такого преобразования новые признаки y(1), y(2), …,y(n) обладают рядом удобных статистических свойств. В частности они упорядочены но степени рассеяния в изучаемой совокупности объектов; первый признак обладает наибольшей степенью рассеяния, т. е. наибольшей дисперсией.
Действительно, во многих задачах обработки многомерных наблюдений и, в частности, в задачах классификации исследователя интересуют в первую очередь лишь те признаки, которые обнаруживают наибольшую изменчивость (наибольший разброс) при переходе от одного объекта к другому. Так, например, при классификации «семей-потребителей» с целью выявления типологии потребления многие из замеряемых по каждой из семей признаков, таких, как душевое потребление хлеба, масла, мыла и некоторых других основных статей, вряд ли будут обнаруживать существенное различие, следовательно, не сыграют почти никакой роли в процедуре обоснованного разбиения совокупности исследуемых семей на различные типы потребителей.
С другой стороны, не обязательно для описания состояния объекта использовать какие-то из исходных, непосредственно замеренных на нем признаков. Так, например, для определения специфики фигуры человека при покупке одежды достаточно назвать значения одного из двух признаков (размер-рост), являющихся какими-то производными от измерений ряда параметров фигуры. При этом мы, конечно, теряем какую-то долю информации (портной измеряет пять-шесть признаков на своем клиенте!), как бы огрубляя (агрегируя) получающиеся при этом классы. Однако, как показали исследования, к вполне удовлетворительной классификации людей с точки зрения специфики их фигуры приводится система, использующая три признака, каждый из которых является некоторой комбинацией от большего числа непосредственно замеряемых на объекте параметров.
Для пояснения сущности того линейного преобразования исходной системы признаков, которое приводит к так называемым главным компонентам, рассмотрим его геометрическую интерпретацию на примере двумерной системы наблюдений (xi(1), xi(2)), i = 1, 2, ... п, извлеченной из нормальной генеральной совокупности со средним значением а = (a(1) , a(2)) и ковариационной матрицей
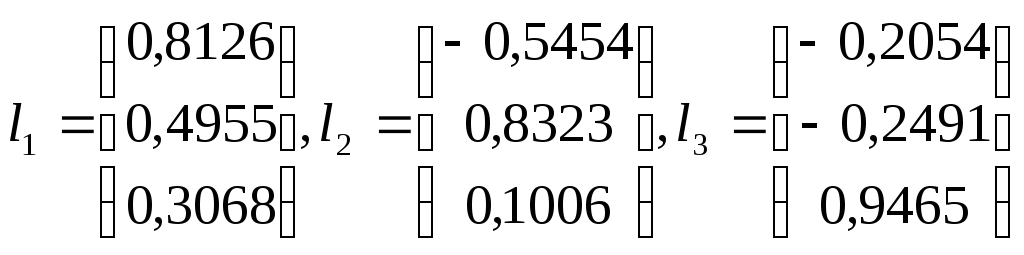
Здесь
![]() и
и ![]() —
дисперсии
компонент, соответственно х(1)
и х(2),
a
r
— коэффициент
корреляции между ними. Геометрически
это означает, что точки (xi(1),
xi(2))
будут располагаться примерно в очертаниях
эллипсоидов рассеивания вида (см. рис-
4.1 а)
—
дисперсии
компонент, соответственно х(1)
и х(2),
a
r
— коэффициент
корреляции между ними. Геометрически
это означает, что точки (xi(1),
xi(2))
будут располагаться примерно в очертаниях
эллипсоидов рассеивания вида (см. рис-
4.1 а)

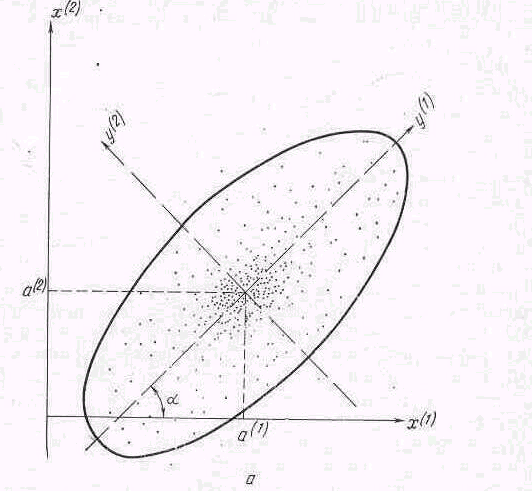
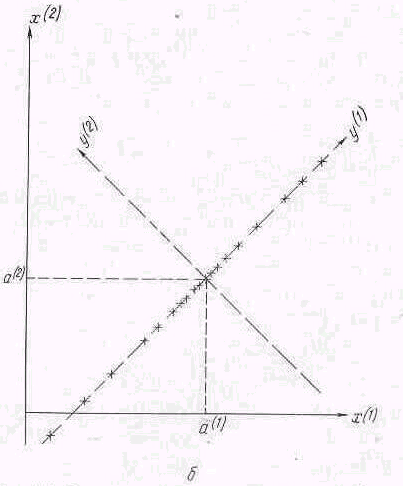
Рис. 4.1,Эллипс рассеивания исследуемых наблюдений и направление координатных осей главных компонент(y(1), y(2)): а) умеренный разброс точек;
б) отсутствие разброса точекв направлении второй главной компоненты (вырожденный случай)
В этом случае для изучения (x(1), x(2)) удобно перейти к новым координатам (y(1), y(2)) с помощью преобразования:
![]()
где
![]()
После
этого преобразования точки (y(1),
y(2))
также будут распределены нормально,
но компонента y(1)
уже не будет зависеть от y(1).
Кроме того, если выбрать направления
так, что D
y(1)
![]() D
y(2),
то геометрически это будет означать
следующее: сначала производится перенос
начала координат в точку (a(1),
a(1)),
а затем оси поворачиваются на угол
D
y(2),
то геометрически это будет означать
следующее: сначала производится перенос
начала координат в точку (a(1),
a(1)),
а затем оси поворачиваются на угол
![]() так, чтобы осьy(1)
шла вдоль
главной оси эллипсоида рассеивания
(рис. 4.1а). Чем ближе
так, чтобы осьy(1)
шла вдоль
главной оси эллипсоида рассеивания
(рис. 4.1а). Чем ближе
![]() к единице, тем теснее группируются
наблюдения около главной оси эллипсоида
рассеивания (т.е. около новой оси
y(1))
и тем менее значащим для исследователя
является разброс точек в направлении
оси y(2),
а следовательно, и сама эта координата.
В предельном случае
к единице, тем теснее группируются
наблюдения около главной оси эллипсоида
рассеивания (т.е. около новой оси
y(1))
и тем менее значащим для исследователя
является разброс точек в направлении
оси y(2),
а следовательно, и сама эта координата.
В предельном случае
![]() =1,
исследуемые наблюдения в координатах
(y(1),
y(2))
вообще не отличаются по координате
y(2)
(см. рис.
4.16).
=1,
исследуемые наблюдения в координатах
(y(1),
y(2))
вообще не отличаются по координате
y(2)
(см. рис.
4.16).