

2. Экстремальные свойства главных компонент. Их интерпретация
а) Свойство наименьшей ошибки «автопрогноза» или наилучшей самовоспроизводимости. Можно показать [27], [29], 128], что с помощью первых р' главных компонент y(1), y(2), …,y(p’) (р'<. р) исходных признаков x(1), x(2),…, x(p) достигается наилучший прогноз этих признаков среди всех прогнозов, которые можно построить с помощью р' линейных комбинаций набора из р произвольных признаков.
Поясним и уточним сказанное. Пусть мы хотим заменить исходный исследуемый p-мерный вектор наблюдений Х на вектор Y = (y(1), y(2), …,y(p’)) меньшей размерности р', в котором каждая из компонент являлась бы линейной комбинацией р исходных (или каких-либо других, вспомогательных) признаков, теряя при этом не слишком много информации. Информативность нового вектора Y зависит от того, в какой степени р' введенных линейных комбинации дают возможность «реконструировать» р исходных (измеряемых на объектах) признаков. Естественно полагать, что ошибка прогноза Х по У (обозначим ее ) будет определяться так называемой остаточной дисперсионной матрицей вектора Х при вычитании из него наилучшего прогноза по У, т.е. матрицей = (ij), где
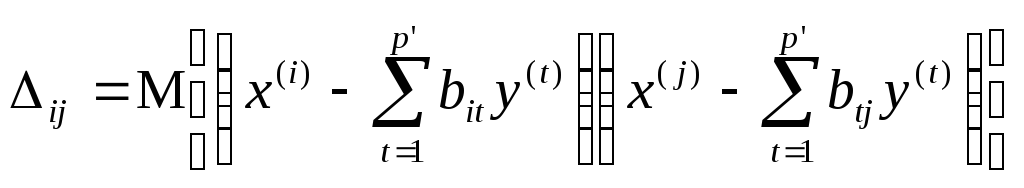 .
.
Здесь
![]() —
наилучший, в смысле метода наименьших
квадратов, прогноз x(i)
по компонентам y(1),
y(2),
…,y(p’),
т. е.
=f(),
где
f()
—некоторая
функция (качества предсказания) от
элементов остаточной дисперсионной
матрицы .
—
наилучший, в смысле метода наименьших
квадратов, прогноз x(i)
по компонентам y(1),
y(2),
…,y(p’),
т. е.
=f(),
где
f()
—некоторая
функция (качества предсказания) от
элементов остаточной дисперсионной
матрицы .
Рао [29] решал задачу наилучшего прогноза Х только в классе р' линейных комбинаций от исходных признаков x(1), x(2),…, x(p) и рассмотрел естественные меры ошибки прогноза, такие, как
f () = tr() = 11 + 22 + … + pp (4.13)
и
![]() (4.14)
(4.14)
tr
()
и
![]() называются
соответственно следом
и евклидовой
нормой матрицы
.
Он показал, что функции
(4.13) и
(4.14)
одновременно достигают минимума тогда
и только тогда, когда в качестве y(1),
y(2),
…,y(p’)
выбраны первые р'
главных компонент вектора
X, причем
величина ошибки прогноза
явным образом выражается через последние
р—р'
собственных чисел p’+1,…,
p
исходной ковариационной матрицы
или через последние р
— р'
собственных чисел p’+1,…,
p
выборочной ковариационной матрицы
называются
соответственно следом
и евклидовой
нормой матрицы
.
Он показал, что функции
(4.13) и
(4.14)
одновременно достигают минимума тогда
и только тогда, когда в качестве y(1),
y(2),
…,y(p’)
выбраны первые р'
главных компонент вектора
X, причем
величина ошибки прогноза
явным образом выражается через последние
р—р'
собственных чисел p’+1,…,
p
исходной ковариационной матрицы
или через последние р
— р'
собственных чисел p’+1,…,
p
выборочной ковариационной матрицы ![]() ,
построенной по наблюдениям X1,
Х2,
..., Хn.
В частности,
,
построенной по наблюдениям X1,
Х2,
..., Хn.
В частности,
при
![]() ;
;
при
![]() .
.
В работах [27] — [28] эта схема обобщена на случай произвольных предсказывающих признаков z(1),…, z(p) и более широкого класса функций f() и показано, что min f() достигается тогда и только тогда, когда в качестве исходных предсказывающих признаков z(1),…, z(p) берутся сами исследуемые (измеряемые) признаки x(1), x(2),…, x(p), а в качестве р' линейных комбинаций (предикторов) y(1), y(2), …,y(p’)от них выбраны первые р' главных компонент вектора X. При этом величина ошибки прогноза , как и прежде, определяется лишь р—р' последними собственными значениями p’+1,…, p исходной ковариационной матрицы .
В
эту схему укладывается, в частности,
случай
![]() , в котором,
кстати,
, в котором,
кстати, ![]()
Поясним идею описания (прогноза) исходных признаков x(1), x(2),…, x(p) помощью меньшего чем p числа их линейных комбинаций на примере 1.
В этом примере, как мы видели, р = 3. Зададимся целью снизить размерность исходного факторного пространства до единицы (р' = 1), т.е. описать все три признака с помощью одной линейной комбинации от них.
В соответствии с описанным выше экстремальным свойством «автопрогноза» главных компонент возьмем в качестве этой единственной линейной комбинации первую главную компоненту, т. e, переменную
y(1)=0,81x(1)+0,50x(2)+0,31x(3).
Метод наименьших квадратов приводит к следующему правилу вычисления неизвестных коэффициентов bi1 [1, с. 125].
![]()
Подставляя в эту формулу значения cov (x(i), x(j)), взятые из ковариационной матрицы (см. стр. 141), получаем
x(1)=b11 y(1)+(1)=0,805 y(1)+(1),
x(2)=b21 y(1)+(2)=0,493 y(1)+(2),
x(1)=b31 y(1)+(3)=0,310 y(1)+(3),
где
(i)
— случайные
(остаточные) ошибки прогноза исходных
компонент ![]() по первой главной компоненте y(1).
по первой главной компоненте y(1).
Если в качестве относительной ошибки прогноза исходного признака x(i) по первой главной компоненте y(1) рассмотреть величину i =(D(i)/Dx(i))·100%, то несложные подсчеты дают
1 = 1%, 2 = 2% и 3 = 4%.
Суммарная характеристика относительной ошибки прогноза признаков x(1), x(2) и x(3) по y(1) (в соответствии с вышеописанным) может быть подсчитана по формуле
сум.
отн. =
![]() .
.
6} Свойства наименьшего искажения геометрической структуры исходных точек (наблюдений) при их проектировании в пространство меныией размерности р', «натянутое» на р' первых главных компонент. Всякий переход к меньшему числу (p') новых переменных, y(1), y(2), …,y(p’), осуществляемый с помощью линейного преобразования (матрицы) С = (cij), - I = 1,2, …, j= 1,2, ...,p, т.е.
![]()
или в матричной записи
Y =СХ (4.15)
нам удобнее будет рассматривать теперь как проекцию исследуемых наблюдений X1, X2, ..., Xn из исходного факторного пространства Х в некоторое подпространство меньшей размерности Yр'.
Геометрическая интерпретация сформулированных выше экстремальных свойств «автопрогноза» (самовоспроизводимости) главных компонент позволяет получить следующие интересные факты.
Свойство 1. Сумма квадратов расстояний от исходных точек-наблюдений X1, Х2, ..., Хn до пространства, натянутого на первые р' главных компонент, наименьшая относительно всех других подпространств размерности р', полученных с помощью произвольного линейного преобразования исходных координат.
Это
свойство станет понятным (в свете
вышеописанного экстремального
свойства «автопрогноза»), если напомнить,
что сумма квадратов расстояний от
исходных точек до подпространства,
натянутого на р'
первых
главных компонент, есть не что иное, как
умноженная на п
(общее число наблюдений) суммарная
дисперсия остаточных компонент (ошибок
прогноза) (1),
(2),
..., (p),
следовательно, эта сумма квадратов
равна п(![]() ).
Наглядным пояснением этого свойства
может служить рис. 4.1а, на котором ось
y(1)
соответствует подпространству, натянутому
на первую главную компоненту (т.
e. р
=
2 и р'
=
1), а сумма
квадратов расстояний до этого
подпространства есть сумма
перпендикуляров, опущенных из точек,
изображающих наблюдения
Xi=
).
Наглядным пояснением этого свойства
может служить рис. 4.1а, на котором ось
y(1)
соответствует подпространству, натянутому
на первую главную компоненту (т.
e. р
=
2 и р'
=
1), а сумма
квадратов расстояний до этого
подпространства есть сумма
перпендикуляров, опущенных из точек,
изображающих наблюдения
Xi=![]() ,
на эту ось (сама ось y(1)
может
быть интерпретирована в данном случае
как линия ортогональной регрессии x(2)
по x(1)),
см.
[1, с.
127].
,
на эту ось (сама ось y(1)
может
быть интерпретирована в данном случае
как линия ортогональной регрессии x(2)
по x(1)),
см.
[1, с.
127].
Свойство 2. Среди всех подпространств заданной размерности р' (р'<р), полученных из исследуемого факторного пространства Х с помощью произвольного линейного преобразования исходных координат x(1), x(2),…, x(p), в подпространстве, натянутом на первые р' главных компонент, наименее искажается сумма квадратов расстояний между всевозможными парами рассматриваемых точек-наблюдений.
Поясним это свойство. Пусть Yp' (С) — подпространство размерности р', натянутое на координаты y(1), y(2), …,y(p’), получаемые из исходных координат x(1), x(2),…, x(p) с помощью произвольного линейного преобразования (4.15), а Y1, Y2, …, Yn — проекции исходных наблюдений Х1, ..., Хn, в подпространство Yp’ (С), т.е. запись исходных наблюдений в координатах подпространства Yp’ (С).
Введем в рассмотрение величины

выражающие суммы квадратов расстояний между всевозможными парами имеющихся у нас наблюдений соответственно в исходном пространстве Х и в подпространстве Yp' (С).
Из простых геометрических соображений очевидно, что всегда
Mp’ Mp при р'<р.
Рассматривая в качестве меры искажения суммы квадратов попарных взаимных расстояний между точками-наблюдениями величину
Мp – Мp’(С),
можно показать (см. [29]), что
![]() где
Lp'
— матрица
размера р' x
р, строками
которой являются первые р'
собственных векторов
l1’,
l2’,
…, lp'’
исходной ковариационной матрицы
(т.е.
подпространство Yp’
(Lp’)
является подпространством, натянутым
иа первые р'
главных компонент вектора наблюдений
X).
где
Lp'
— матрица
размера р' x
р, строками
которой являются первые р'
собственных векторов
l1’,
l2’,
…, lp'’
исходной ковариационной матрицы
(т.е.
подпространство Yp’
(Lp’)
является подпространством, натянутым
иа первые р'
главных компонент вектора наблюдений
X).
Свойство 3. Среди всех подпространств заданной размерности p' (p' < p), полученных из исследуемого факторного пространства Х с помощью произвольного линейного преобразования исходных координат x(1), x(2),…, x(p), в пространстве, натянутом на первые р' главных компонент, наименее искажаются расстояния от рассматриваемых точек-наблюдений до их общего «центра тяжести», а также углы между прямыми, соединяющими всевозможные пары точек-наблюдений с их общим «центром тяжести».
Поясним
это свойство. Рассмотрим матрицу G
размера (р
х п)
«центрированных»
наблюдений
![]() .
Здесь, как и прежде,
.
Здесь, как и прежде,
![]() —исходные
наблюдения, а
—исходные
наблюдения, а![]() —
среднее арифметическое по всем наблюдениям
i-го
признака, т.е.
—
среднее арифметическое по всем наблюдениям
i-го
признака, т.е.
 .
.
Введем в рассмотрение матрицу размера (п Х п)
H – G’G = (hiq), i, q = 1, 2,..., n.
Нетрудно установить геометрический смысл элементов этой матрицы:
![]() –
–
это
квадрат расстояния от точки-наблюдения
![]() до общего «центра тяжести»
до общего «центра тяжести»
![]() ,
а
,
а
![]() –
–
величина,
пропорциональная косинусу угла между
прямыми, соединяющими точки Хq
и
Xj
с центром
тяжести
![]() .
.
Если рассмотреть, кроме того, матрицу G(С) наблюдений Y1, …, Yn, являющихся проекциями исходных (центрированных) наблюдений X1, …, Хn в подпространство Yp’(С) и соответствующую ей матрицу Н (С) = G' (C)G (С), то оказывается, что
![]()
![]() ,
,
где
под
![]() понимается, как обычно, евклидова норма
матрицыA,
а Lp’
соответствует ранее введенным
обозначениям.
понимается, как обычно, евклидова норма
матрицыA,
а Lp’
соответствует ранее введенным
обозначениям.
Кстати, из описанного выше следует, что естественной мерой относительного искажения геометрической структуры исходной совокупности наблюдений при их проектировании в пространство меньшей размерности, натянутое на первые р' главных компонент, является величина
 ,
,
либо величина
 .
.
При
неизвестной истинной ковариационной
матрице
ее собственные значения ![]() следует заменить собственными значениями
следует заменить собственными значениями
![]() выборочной ковариационной матрицы
2 и
соответственно снабдить «крышками»
сверху характеристики x
и
степени искажения геометрической
структуры исследуемой совокупности
наблюдений,
выборочной ковариационной матрицы
2 и
соответственно снабдить «крышками»
сверху характеристики x
и
степени искажения геометрической
структуры исследуемой совокупности
наблюдений,