

3. Статистические свойства выборочных главных компонент; статистическая проверка некоторых гипотез
Смысл математико-статистических методов, как известно, состоит в том, чтобы по некоторой части исследуемой генеральной совокупности (т. е. по выборке, или, что то же, — по ограниченному ряду наблюдений X1, Х2, ..., Хn ) выносить обоснованные суждения о ее свойствах в целом.
Применительно
к нашей задаче нас, в первую очередь,
будет интересовать, как сильно
свойства и характеристики выборочных
главных компонент могут отличаться от
соответствующих свойств и характеристик
главных компонент всей генеральной
совокупности, и, в частности,. как эта
мера отличия зависит от объема выборочной
совокупности (n),
но которой эти выборочные главные
компоненты были построены. Так, например,
для изучения природы внутренних связей
между характеристиками различных
статей семейного бюджета потребления
и для выявления небольшого числа наиболее
существенных в этом смысле показателей
исследователь может обследовать какое-то
количество
(n)
семей и по
полученным результатам наблюдения X1,
Х2,
..., Хn
построить главные компоненты
![]() .
Однако, увеличивая объем выборки п,
т.е. добавляя к нашим наблюдениям
результаты наблюдения по дополнительно
обследованным семьям, естественно
ожидать, что пересчет главных компонент
с учетом
добавленных наблюдений,
вообще говоря, изменит (хотя, быть может,
и незначительно) ранее полученные
значения интересующих нас характеристик:
.
Однако, увеличивая объем выборки п,
т.е. добавляя к нашим наблюдениям
результаты наблюдения по дополнительно
обследованным семьям, естественно
ожидать, что пересчет главных компонент
с учетом
добавленных наблюдений,
вообще говоря, изменит (хотя, быть может,
и незначительно) ранее полученные
значения интересующих нас характеристик:
![]() (i
= 1. 2, .... р)
и т.п. В то же время существует, по-видимому,
такое (столь большое) n,
дальнейшее увеличение которого уже не
будет практически приводить к
изменению основных характеристик
главных компонент (другими словами,
мы вправе ожидать, что главные компоненты
выборок достаточно большого объема
практически совпадают с главными
компонентами всей генеральной
совокупности).
(i
= 1. 2, .... р)
и т.п. В то же время существует, по-видимому,
такое (столь большое) n,
дальнейшее увеличение которого уже не
будет практически приводить к
изменению основных характеристик
главных компонент (другими словами,
мы вправе ожидать, что главные компоненты
выборок достаточно большого объема
практически совпадают с главными
компонентами всей генеральной
совокупности).
Выяснению
некоторых вопросов, связанных с. оценкой
близости различных выборочных (![]() )
и теоретических (
)
и теоретических (![]() )
характеристик главных компонент, и
посвящен настоящий пункт. При этом,
приведенные ниже результаты исследований
неизменно опираются на допущение
нормальности исследуемой генеральной
совокупности и взаимной независимости
извлеченных из нее наблюдений. Как и
прежде под X1,
Х2,
..., Хn
мы будем
понимать центрированные наблюдения,
которые, строго говоря, даже при
независимых исходных наблюдениях уже
не будут независимыми. Однако при
достаточно больших п
мы можем пренебречь этим эффектом
нарушения независимости. Таким образом,
Xi
N
(,
),
i
=
1,2, ..., п
(как следует из предыдущего, вектор
средних значений а
= М Х
определяет лишь точку в р-мерном
пространстве, в которую переносится
начало координат при переходе к главным
компонентам, и мы с самого начала будем
считать этот перенос уже осуществленным).
)
характеристик главных компонент, и
посвящен настоящий пункт. При этом,
приведенные ниже результаты исследований
неизменно опираются на допущение
нормальности исследуемой генеральной
совокупности и взаимной независимости
извлеченных из нее наблюдений. Как и
прежде под X1,
Х2,
..., Хn
мы будем
понимать центрированные наблюдения,
которые, строго говоря, даже при
независимых исходных наблюдениях уже
не будут независимыми. Однако при
достаточно больших п
мы можем пренебречь этим эффектом
нарушения независимости. Таким образом,
Xi
N
(,
),
i
=
1,2, ..., п
(как следует из предыдущего, вектор
средних значений а
= М Х
определяет лишь точку в р-мерном
пространстве, в которую переносится
начало координат при переходе к главным
компонентам, и мы с самого начала будем
считать этот перенос уже осуществленным).
а)
Вспомогательные
факты, относящиеся к свойствам выборочных
характеристик главных компонент
[2],
[26], [14], [15],
[20],
[21], [4]. Если
все характеристические корни ![]() ковариационной
матрицы
различны, что и имеет место в большинстве
приложений анализа главных компонент,
то справедливо следующее:
ковариационной
матрицы
различны, что и имеет место в большинстве
приложений анализа главных компонент,
то справедливо следующее:
— характеристические
корни ![]() и соответствующие
им собственные векторы
и соответствующие
им собственные векторы ![]() выборочной
ковариационной матрицы
являются оценками максимального
правдоподобия для соответствующих
теоретических характеристик (соответственно
выборочной
ковариационной матрицы
являются оценками максимального
правдоподобия для соответствующих
теоретических характеристик (соответственно
![]() и
и ![]() )
и обладают всеми хорошими свойствами
этих оценок (состоятельность,
асимптотическая эффективность).
Следовательно, выборочные главные
компоненты
)
и обладают всеми хорошими свойствами
этих оценок (состоятельность,
асимптотическая эффективность).
Следовательно, выборочные главные
компоненты
![]() (i
= 1,
2,...,
р)
(i
= 1,
2,...,
р)
можно
интерпретировать как оценки главных
компонент
y(i)
всей генеральной совокупности. Если
среди характеристических корней
![]() встречаются равные между собой, то
оценки максимального правдоподобия
для
встречаются равные между собой, то
оценки максимального правдоподобия
для
![]() и
и ![]() определяются
иначе. Аналогичные результаты имеют
место и при оценке характеристических
корней и соответствующих им собственных
векторов корреляционной матрицы;
определяются
иначе. Аналогичные результаты имеют
место и при оценке характеристических
корней и соответствующих им собственных
векторов корреляционной матрицы;
— величины
![]() (i
= 1,
2,..., р)
(i
= 1,
2,..., р)
асимптотически
(по п
) нормальны
со средним значением
0 и с
дисперсией, равной
2![]() ,
и независимы от других выборочных
характеристических корней;
,
и независимы от других выборочных
характеристических корней;
— вектор
![]() (i
= 1,
2,..., р)
(i
= 1,
2,..., р)
асимптотически (по п ) подчиняется многомерному нормальному распределению с вектором средних значений 0 и с ковариационной матрицей
![]()
Заметим,
что этот результат имеет место для
всякого ![]() отличного от всех остальных
характеристических корней, каждый из
которых может иметь произвольную
кратность;
отличного от всех остальных
характеристических корней, каждый из
которых может иметь произвольную
кратность;
—выборочный
характеристический корень
![]() распределен асимптотически (по п
)
независимо от компонент соответствующего
ему собственного вектора
распределен асимптотически (по п
)
независимо от компонент соответствующего
ему собственного вектора ![]() ( i
=
1, 2, ..., р);
( i
=
1, 2, ..., р);
—ковариация
между r-й
компонентой выборочного собственного
вектора
![]() и q-й
компонентой выборочного собственного
вектора
и q-й
компонентой выборочного собственного
вектора
![]() ,
равна
,
равна
![]()
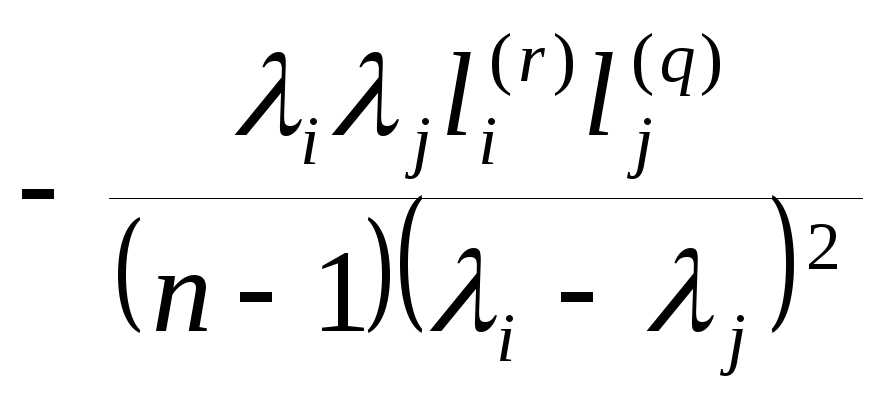 .
.
Следующий факт [4] относится к весьма специфической ситуации, характеризуемой так называемым «эффектом большой размерности», когда, несмотря на достаточно большой объем выборки п, поведение выборочных характеристик обнаруживает неожиданные особенности из-за соизмеримо (с п) большого значения размерности р; при этом для вывода этого факта не требуется нормальности исходных наблюдений;
— если компоненты х(i) вектора наблюдений Х взаимно независимы и пронормированы таким образом, что M х(i) = 0 и D х(i) = 1, причем существуют все моменты М (х(i))v, и если объем выборки п и размерность р одновременно достаточно велики, причем
![]() (0
c
),
(0
c
),
то
распределение случайно выбранного из
последовательности ![]() характеристического корня «слабо
сходится»1
к некоторому предельному распределению
(сосредоточенному на конечном отрезке),
моменты которого задаются формулой.
характеристического корня «слабо
сходится»1
к некоторому предельному распределению
(сосредоточенному на конечном отрезке),
моменты которого задаются формулой.
![]() ,
(v=l,
2…)
,
(v=l,
2…)
так
что
![]() и т. д. Здесьс—некоторая
постоянная величина, причем
0
c
<
).
и т. д. Здесьс—некоторая
постоянная величина, причем
0
c
<
).
Заметим, что примером подобного соотношения между объемом выборки и размерностью может служить задача, описанная в § 1 главы V, в которой п = 74, а р = 32 (так что (p/n) = 0,43).
В заключение приведем два факта, относящихся к ситуациям, в которых компоненты нормального вектора наблюдений Х взаимно независимы:
— пусть
ХN(a,),
где ковариационная матрица имеет
диагональный вид, т. е. cov
(x(i),
x(j))
= 0
при i
j,
i,
j
= 1,
2, …, p.
И пусть
![]() — определитель
выборочной корреляционной матрицы,
построенной по наблюдениям (Х1,
..., Хn).
Тогда при достаточно больших
n
(п
)
статистика критерия отношения
правдоподобия для проверки гипотезы
о диагональном виде
может быть определена в виде
— определитель
выборочной корреляционной матрицы,
построенной по наблюдениям (Х1,
..., Хn).
Тогда при достаточно больших
n
(п
)
статистика критерия отношения
правдоподобия для проверки гипотезы
о диагональном виде
может быть определена в виде
![]() ,
,
а для функции распределения справедливо приближенное соотношение
![]()
при относительной ошибке, не превосходящей сотых долей процента;
— пусть наблюдения Xj извлечены из так называемой сферической р-мерной нормальной совокупности N (a, 2J), т. е. компоненты каждого из векторов Xj взаимно независимы и имеют одинаковые дисперсии Dxj(i) равные 2. Тогда ковариационная матрица = 2J имеет единственный корень (кратности р), оценкой максимального правдоподобия для которого является величина
![]() (4.16)
(4.16)
причем величина 2 распределена по закону 2 (р (n — 1)).
Статистика критерия отношения правдоподобия для проверки гипотезы о сферичности распределения исследуемого вектора наблюдений имеет вид
 ,
,
при достаточно больших n (п )
![]()
и относительной ошибке данного приближенного соотношения, не превосходящей сотых долей процента.
б) Применения свойств выборочных характеристик главных компонент. Опишем некоторые методы построения разного рода интервальных оценок для интересующих нас неизвестных характеристик главных компонент и статистической проверки гипотез, относящихся к этим характеристикам:
- интервальная оценка (доверительный
интервал) для i-гo
характеристического корня i.
Она получается (при больших n)
с учетом асимптотической нормальности
статистики![]() .
А именно:
.
А именно:
 , (4.17)
, (4.17)
где
данное неравенство справедливо с
вероятностью 1 —
(величиной
заранее задаемся), а![]() —
—
![]() -ная
точка стандартного нормального
распределения (находится из таблиц).
-ная
точка стандартного нормального
распределения (находится из таблиц).
Возвращаясь
к примеру
1, по формуле
(4.17), находим
95%-ный (
=
0,05)
доверительный интервал для наименьшего
характеристического корня 3
по его выборочному значению 3
=
2,86. В этом
случае п
=
24,
![]() =1,96,
так что
1,81 < 3
< 6,78.
=1,96,
так что
1,81 < 3
< 6,78.
Возможно обобщение асимптотического (по п ) доверительного интервала на случай кратных, т.е. повторяющихся корней. Если r — кратность корня i, то 100 (1 — ) — процентный доверительный интервал для неизвестного значения i задается неравенством
 , (4.18)
, (4.18)
где
![]() .
.
Однако откуда мы можем знать, что неизвестный характеристический корень i имеет кратность и, в частности, кратность, равную r? Этот вопрос может быть решен с помощью следующего критерия, предложенного в [15];
проверка гипотезы о равенстве нескольких (а именно r) характеристических корней: i = i+1 = ... = i+r-1. Очевидно, альтернативой к этой гипотезе является утверждение, что не все корни среди i, i+1, ..., i+r-1 равны между собой. Оказывается, в предположении справедливости проверяемой гипотезы статистика
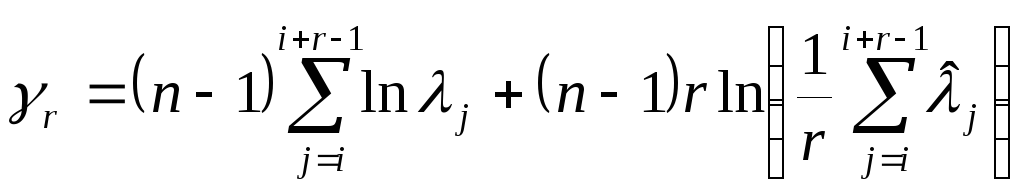 (4.19)
(4.19)
распределена (асимптотически по п ) по закону 2 с (r(r+1)/2) — 1 степенью свободы. Поэтому гипотеза i = i+1 = ... = i+r-1 отвергается (с вероятностью ошибиться, равной ), если
![]() ,
,
где 2(m) —100 %-ная точка 2-распределения с т степенями свободы.
Заметим, что особый интерес может представить специальный случай i = р — r + 1, т. е. проверка гипотезы о равенстве последних r собственных значений , что будет означать независимость и сферичность r последних признаков исследуемого вектора наблюдений.
Возвратимся к примеру 1. Тот факт, что оценка второго собственного значения (2 = 6,50) попадает в доверительный интервал для 3 (см. выше), приводит нас к мысли, что, возможно, 2=3. Проверим эту гипотезу. В нашем случае n = 24, р = 3, i = 2, r = 2, так что
![]() .
.
А
поскольку
![]() (2)
= 5,99 и,
следовательно,
(2)
= 5,99 и,
следовательно,
![]() <
<![]() (2),
(2),
то
гипотезу 2=3
следует принять. Но тогда нужно пересчитать
доверительный интервал для 2
с учетом его кратности (в соответствии
с
(4.18)).
Несложные подсчеты (при
=
0,05 и,
соответственно,
![]() =u0,025
= 1,96)
дают:
2,62
2
6,21,
=u0,025
= 1,96)
дают:
2,62
2
6,21,
где последнее неравенство будет справедливо в среднем в 95 случаях из 100;
— проверка гипотезы о независимости признаков x(1), x(2),…, x(p), являющихся компонентами вектора наблюдений X. Такая проверка нужна для установления целесообразности применения метода главных компонент: ведь, если признаки являются взаимно независимыми, то переход к главным компонентам сведется по существу лишь к упорядочиванию исходных признаков по принципу убывания их дисперсий. Воспользуемся статистикой критерия отношения правдоподобия для проверки гипотезы о диагональном виде ковариационной матрицы с целью проверки независимости компонент вектора наблюдений в следующем примере.
Пример 2 [2]. Исследовалось время, затрачиваемое работниками швейной фабрики па выполнение различных элементов операции глаженья одежды. Операцию глаженья можно разделить на следующие шесть элементов:
1) одежда размещается на гладильной доске (x(1));
2) разглаживаются короткие швы (x(2));
3) одежда перекладывается на гладильной доске (x(3));
4) разглаживаются длинные швы на три четверти (x(4));
5) разглаживаются остатки длинных швов (x(5));
6) одежду вешают на вешалку (x(6)).
В этом случае Хv представляет собой вектор измерения над v-м индивидуумом. Компонента x(i)—это время, затраченное на выполнение i-го элемента операции, n = 76. Данные (время в секундах) обработаны, получены выборочные вектор среднего значения и ковариационная матрица

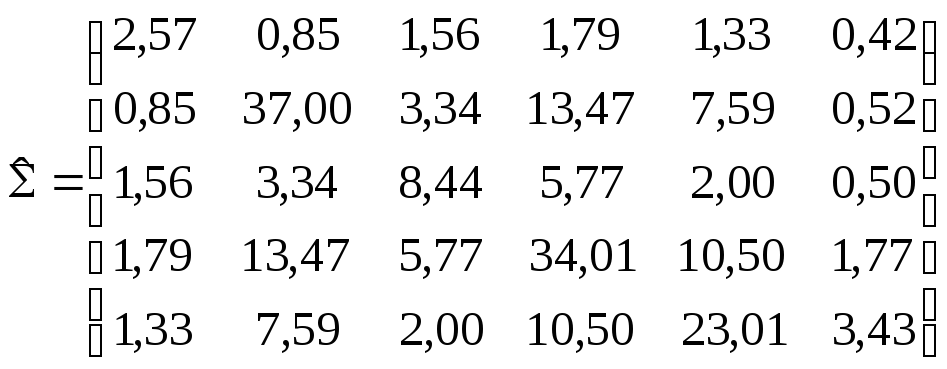 .
.
Выборочные стандартные отклонения равны (1,604; 6,041; 2,903; 5,832; 4,798; 2,141). Выборочная корреляционная матрица R = (rij) имеет вид:
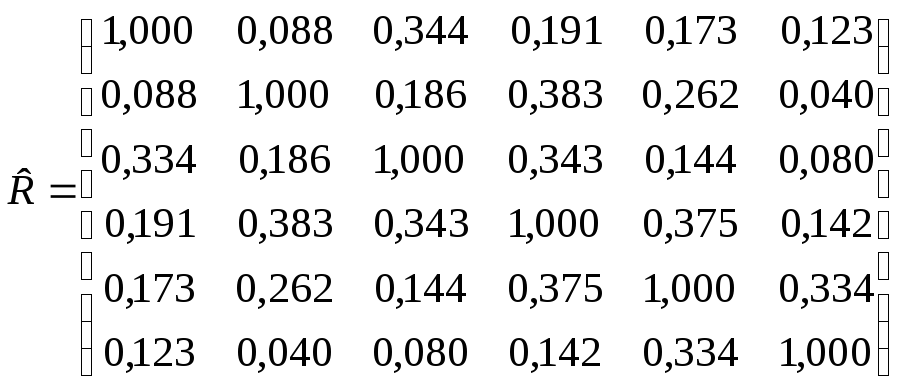
Для исследователей представляет интерес проверка гипотезы о взаимной независимости шести случайных величин. Часто при изучении затрат времени предлагается новая операция, в которой элементы комбинируются иным способом. В новой операции некоторые элементы могут повторяться по нескольку раз, а некоторые могут быть выброшены. Если оказываются независимыми величины, обозначающие время, затрачиваемое на различные элементы операции, то естественно считать, что и в новой операции они останутся независимыми. Тогда распределение затрат времени на новую операцию можно будет оцепить, пользуясь средними значениями и дисперсиями, вычисленными для остальных элементов. Кроме того, нас интересует возможность выделения небольшого количества вспомогательных признаков (двух-трех), с помощью которых мы могли бы производить некоторую содержательную классификацию исследуемых работников (в том или ином смысле).
В
этой задаче отношение правдоподобия
V
равно
![]() =
0,472. Так
как объем выборки велик, то можно
пользоваться теорией асимптотических
разложений.
=
0,472. Так
как объем выборки велик, то можно
пользоваться теорией асимптотических
разложений.
В
нашем случае
![]() ,
а р (р
— 1)/2
= 15. Задавшись
уровнем значимости критерия
= 0,01
(вероятность ошибочно отвергнуть
проверяемую гипотезу), находим (из
таблиц) величину 1%-ной точки 2-распределения
с
15 степенями
свободы:
,
а р (р
— 1)/2
= 15. Задавшись
уровнем значимости критерия
= 0,01
(вероятность ошибочно отвергнуть
проверяемую гипотезу), находим (из
таблиц) величину 1%-ной точки 2-распределения
с
15 степенями
свободы:
![]() (15)
= 30,6.
Поскольку
>
(15)
= 30,6.
Поскольку
>![]() (15),
то гипотезу
следует отвергнуть, т.е. приходим к
выводу, что значения затрат времени на
различные элементы операции нельзя
считать независимыми;
(15),
то гипотезу
следует отвергнуть, т.е. приходим к
выводу, что значения затрат времени на
различные элементы операции нельзя
считать независимыми;
—статистическая проверка некоторых предположений (гипотез) относительно собственных векторов li , ковариационной матрицы исследуемых признаков (i = 1, 2, ..., р). Пусть у нас есть основания предполагать, что «нагрузки» всех признаков на первую главную компоненту равны между собой (факт симметричной зависимости первой главной компоненты от исходных признаков), т. е.
![]() ,
,
или,
напротив, что некоторые из признаков,
скажем x(p-1)
и x(p),
вообще не влияют на первую главную
компоненту (т. е. l1(p-1)
=
l1p
= 0),
в то время как остальные р
—
2 признака
влияют на нее симметрично, т.е.
![]() и т.д.
и т.д.
Для
решения подобных вопросов можно
использовать статистический критерий
равенства
i-го
собственного вектора неизвестной
ковариационной матрицы некоторому
заранее заданному вектору
![]() .
В [15] показано, что гипотеза
li
=
.
В [15] показано, что гипотеза
li
=
![]() должна быть отвергнута (с вероятностью
ошибиться, т. е. с уровнем значимости
критерия, приблизительно равной а),
если окажется, что
должна быть отвергнута (с вероятностью
ошибиться, т. е. с уровнем значимости
критерия, приблизительно равной а),
если окажется, что
![]() ,
,
где
подразумевается, что характеристический
корень
![]() ,
оценка которого
,
оценка которого![]() участвует
в выражении для критической статистики,
имеет кратность, равную единице, а
все остальные величины соответствуют
ранее введенным обозначениям;
участвует
в выражении для критической статистики,
имеет кратность, равную единице, а
все остальные величины соответствуют
ранее введенным обозначениям;
— проверка
гипотезы о равнокоррелированности всех
р
исходных признаков, т. е. гипотезы rij
= r(0),
где rij
— парный
коэффициент корреляции между признаком
х(i)
и признаком x(j)
[26]. Эта
гипотеза означает, что последние р
—
1
характеристических корней корреляционной
матрицы равны между собой. Кроме того,
постулируемый здесь специальный вид
корреляционной матрицы допускает
простые явные выражения в виде решений
соответствующих характеристических
уравнений ( 1
= 1+ (p-1)r0,
2
=…=p
= 1- r0,
y(1)=
(x(1)+
x(2)+…+
x(p)/![]() и
т.д. [26,
с. 244]).
и
т.д. [26,
с. 244]).
Оказывается, гипотезу rij = r(0) следует отвергнуть (с вероятностью ошибиться, приблизительно равной ), если
 ,
,
где
![]() —
выборочные парные коэффициенты корреляции
между х(i)
и х(j),
подсчитанные по наблюдениям X1,
Х2,
.... Хn,
а
—
выборочные парные коэффициенты корреляции
между х(i)
и х(j),
подсчитанные по наблюдениям X1,
Х2,
.... Хn,
а
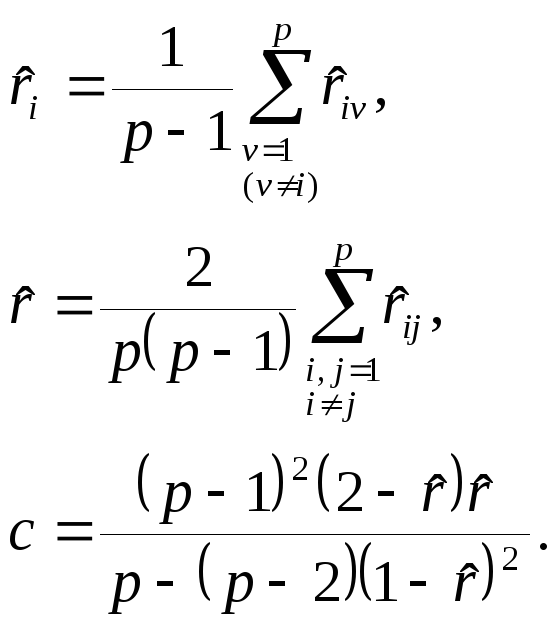
Кстати, в нашем примере 1 корреляционная матрица

Несложные подсчеты дают:
![]() =0,9733,
=0,9733,
![]() =0,9698,
=0,9698,![]() =
0,9691,
=
0,9691,![]() =0,9707
так что в конечном счете
=0,9707
так что в конечном счете ![]() =
0,825.
=
0,825.
Задавшись
уровнем значимости
= 0,05 и
отыскав по таблицам
![]() (2)
=
5,99, приходим
к выводу, что гипотеза о равнокоррелированности
всех трех исходных признаков может быть
признана непротиворечащей имеющимся
у нас результатам наблюдения.
(2)
=
5,99, приходим
к выводу, что гипотеза о равнокоррелированности
всех трех исходных признаков может быть
признана непротиворечащей имеющимся
у нас результатам наблюдения.