

Empiryczny rozkład cechy
Określenie empirycznego rozkładu cechy polega na przyporządkowaniu uszeregowanym rosnąco wartościom, przyjmowanym przez tę cechę, odpowiednio zdefiniowanych częstości ich występowania.
Dane indywidualne - są to dane informujące, jaką wartość cechy ma każda jednostka badanej zbiorowości. Oznaczać je będziemy symbolem xi, i = 1, 2,..., n. gdzie n jest liczebnością badanej zbiorowości.
Jeśli jest to cecha skokowa, to poszczególne wartości cechy mogą mieć taką samą wartość. Możliwe jest zatem pewne pogrupowanie obserwacji.
Załóżmy więc, że cecha przyjmuje k wartości xi, i = 1, 2,...,k (1<k<n). Przyjmijmy, że wartości te są uporządkowane tak, aby xmin= x1< x2<...., xk= xmax, gdzie xmin oraz xmax oznaczają odpowiednio najmniejszą i największą wartość cechy.
Liczbę jednostek, dla których cecha przyjmuje wartość xi oznaczać będziemy symbolem ni, przy czym
 .
.
Niekiedy zamiast liczebności ni, stosuje się częstotliwości jako: wi= ni/n, (i=1,...,k), oznaczające udział jednostek w ogólnej liczebności.
Jeśli poszczególnym wartościom xi cechy przyporządkowane zostaną liczebności ni , to w ten sposób określony zostanie rozkład empiryczny, a uporządkowane odpowiednio obserwacje będą miały charakter danych pogrupowanych.
Tablica prezentująca uporządkowane i pogrupowane dane nazywana jest potocznie szeregiem rozdzielczym.
W przypadku cechy ciągłej określanie rozkładu odbywa się przez przyporządkowanie liczebności (częstości) odpowiednim przedziałom wartości cechy, a nie konkretnym jej wartościom. Takie przedziały nazywamy przedziałami klasowymi.
Różnicę między górną i dolną granicą i-tego przedziału klasowego nazywa się rozpiętością przedziału (i oznacza się przez , gdy te wielkości są równe, lub przez hi, gdy nie są równe).
Przyjmuje się zwykle, że k, tj. liczba grup (klas), nie powinno być mniejsze niż 5 i większe od 20.
Empiryczny rozkład cechy może być prezentowany za pomocą liczebności (częstości) skumulowanych. Taki sposób przedstawiania rozkładu empirycznego wiąże się z pojęciem dystrybuanty empirycznej i jest szczególnie użyteczny przy wyznaczaniu tzw. pozycyjnych charakterystyk rozkładu.
Liczebność skumulowaną n(xi) dla wartości cechy xi oblicza się jako
 .
.
Przy budowie empirycznego rozkładu cechy ciągłej należy pamiętać o:
przedziałach klasowych [(xdi,,xgi) , gdzie xdi oznacza dolną granicę przedziału, a xgi – górną granicę przedziału i]
wielkości przedziału (Δ lub hi – gdy są nierówne)
zamknięciu przedziału pierwszego (tj. wyznaczenie xd1) oraz przedziału ostatniego (tj. wyznaczenie xgk)
wyznaczeniu środka przedziału (
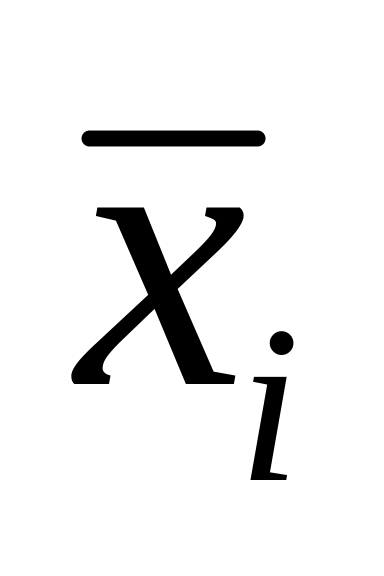 )
)liczebnościach (ni) lub częstościach (wi) przedziału
skumulowanych liczebnościach (n(xi)) lub skumulowanych częstościach (w(xi)) przedziału.
Tabl. Robocza. Rozkłady pracowników wg wysokości płacy miesięcznej
-
Nr grupy
i
Grupy
płacowe
[xdi, xgi)
Średnia
płaca w grupie i
xi
Liczba
pracowników
ni
Częstości
pracowników
wi
Skumulowane
częstości

1
400 -800
600
67
0,054
0,054
2
800-1200
1000
169
0,135
0,189
3
1200-1600
1400
286
0,229
0,418
4
1600-2000
1800
358
0,286
0,704
5
2000-2400
2200
175
0,140
0,844
6
2400-2800
2600
141
0,113
0,957
7
2800 -3200
3000
54
0,043
1,000
Ogółem
x
x
1250
1,000
x
Z powyższej tablicy obliczamy następujące parametry:
Przeciętną płacę:
![]()
Wariancję płacy:
![]()
Odchylenie standardowe
płacy:
![]()
Współczynnik zmienności:
![]() ,
a w procentach 44,6%.
,
a w procentach 44,6%.
Frakcja elementów wyróżnionych, np. frakcja pracowników o płacy do 1600 zł:
 ,
a w procentach 41,8%.
,
a w procentach 41,8%.
W dalszej części wykładu będziemy często prowadzili wnioskowanie odnośnie następujących parametrów z próby:
przeciętnej (
 - dla zmiennej ciągłej)
- dla zmiennej ciągłej)frakcji elementów wyróżnionych (p - dla zmiennej dyskretnej)
wariancji (s2)
odchylenia standardowego (s)
współczynnika zmienności (v)
W podanych podręcznika można znaleźć różne oznaczenia, dlatego należy przede wszystkim zorientować się co dane oznaczenie reprezentuje.