

эконометрия
1.Основы математической статистики
1.1 Одномерные величины
1.1.1 Дискретные случайные величины. Формулы для матожидания, дисперсии и стандартного отклонения. Коэффициент вариации.
Описание дискретной случайной
величины в теории вероятностей начинается
со следующего допущения: пусть у нас
есть дискретная случайная величина X,
{xi}
– список ее возможных значений, а {рi}
– список соответствующих
им вероятностей, т.е. значение xi
наблюдается в опытах с вероятностью
рi.
Как подобные характеристики могут быть
обнаружены в реальности? Мы можем
провести серию опытов по измерению
значений величины X
и зафиксировать, что значение случайной
величины Х с номером i
наступило ni
раз в серии из N
опытов. При этом теория вероятностей
гласит, что если общее
число испытаний будет стремиться к ,
то частота
![]() появления значения xi
будет стремиться к рi.1
появления значения xi
будет стремиться к рi.1
Однако в реальности мы ведь никогда не можем произвести бесконечное количество опытов, да еще в идеально одинаковых условиях, и это первое несовпадение модели, которую предлагает нам теория вероятностей, с реальными задачами. Первое, но далеко не последнее – беда в том, что чаще всего с дискретными случайными величинами мы встречаемся в ситуациях, которые выглядят в принципе не так.
Пусть, например, наша случайная величина – рост призывника очередного призыва в г. Киеве, выраженный в сантиметрах. Тут в принципе невозможно поставить бесконечное число опытов. В лучшем случае мы можем измерить рост всех киевских юношей призывного возраста. Совокупность всех объектов исследования (в нашем примере – всех киевских юношей призывного возраста) называется генеральной совокупностью. И мы можем получить сведения обо всех объектах генеральной совокупности – это в лучшем случае, как максимум.
Однако чаще всего не происходит
и этого – полное исследование генеральной
совокупности потребовало бы слишком
больших денег и заняло бы слишком много
времени. Поэтому обычно идут по пути
выборочного исследования. Выбирается
некоторое количество представителей
из всей совокупности объектов исследования
(производится выборка),
замеры осуществляются только по этой
группе (получаем выборочные данные) и
по данным выборки оцениваются
все параметры генеральной совокупности.
Так, выборочное среднее
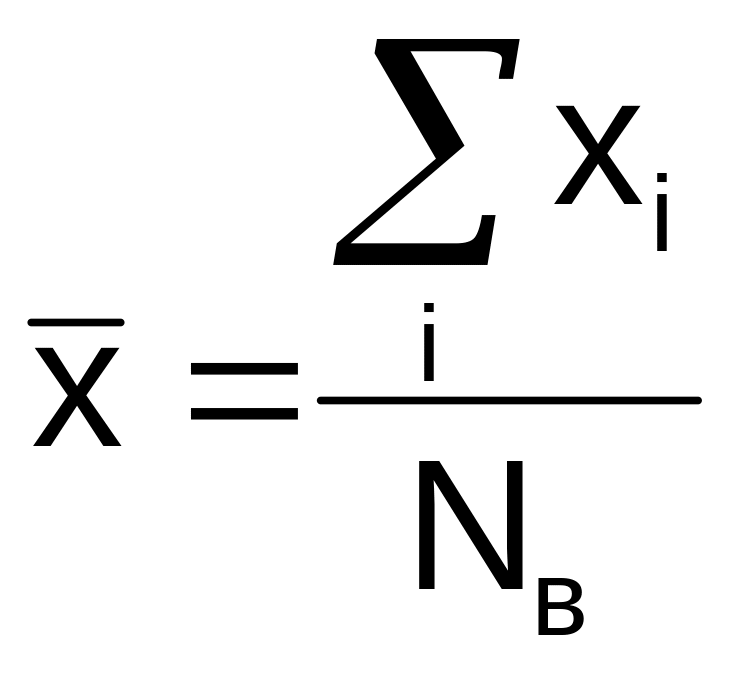 , где Nв
есть объем выборки, будет рассматриваться
в дальнейшем как оценка
генерального среднего µ. Отметим, что
в такой ситуации индекс i
указывает не номер
одного значения из списка возможных
значений (как в модели теории вероятностей),
а просто номер опыта (номер элемента,
номер варианты2).
При этом, конечно, некоторые значения
будут повторяться, но на первом этапе
нам это никак не помешает – в дальнейшем
при вычислении выборочных характеристик
мы будем использовать индекс i
как номер опыта (номер объекта).
, где Nв
есть объем выборки, будет рассматриваться
в дальнейшем как оценка
генерального среднего µ. Отметим, что
в такой ситуации индекс i
указывает не номер
одного значения из списка возможных
значений (как в модели теории вероятностей),
а просто номер опыта (номер элемента,
номер варианты2).
При этом, конечно, некоторые значения
будут повторяться, но на первом этапе
нам это никак не помешает – в дальнейшем
при вычислении выборочных характеристик
мы будем использовать индекс i
как номер опыта (номер объекта).
Строго говоря, такие понятия теории вероятностей, как матожидание, дисперсия и т.п. в данной ситуации теряют смысл – мы не можем точно получить значения вероятностей рi, а значит и величины основных характеристик вычислить не можем, поскольку для их вычисления вероятности рi должны быть известны. Но мы в дальнейшем не будем делать различия между теоретическими величинами и величинами, вычисленными для генеральной совокупности. Предполагается, что совокупности достаточно большие, и значения характеристик для них с достаточной точностью можно считать соответствующими представлениям теории вероятностей.
Итак, пусть у нас есть дискретная случайная величина, представленная таблицей значений, причем эта таблица представляет не выборку, а всю генеральную совокупность. Тогда основные характеристики этой величины, а именно: матожидание (генеральное среднее) µ, дисперсию D и стандартное (среднеквадратичное) отклонение σ для генеральной совокупности могут быть вычислены по следующим формулам:
![]() (1.1)
(1.1)
Здесь N означает количество всех доступных наблюдению значений дискретной случайной величины (объём генеральной совокупности).
При такой постановке задачи
генеральное среднее
![]() и матожидание µ
просто совпадают.
и матожидание µ
просто совпадают.
Отметим, что стандартное (среднеквадратичное) отклонение как и дисперсия представляет собой характеристику рассеяния, т.е. характеризует «размазанность» случайной величины вокруг матожидания. Однако применение стандартного отклонения в большинстве случаев предпочтительнее, т.к. σ имеет ту же размерность что и сама величина х, и ее матожидание (генеральное среднее) µ, тогда как дисперсия имеет размерность равную квадрату размерности самой случайной величины Х – как следствие стандартное отклонение σ можно сравнить по величине со средним µ, а вот дисперсию со средним значением сравнить нельзя.
Поэтому знание стандартного отклонения не только позволяет лучше представить себе общую картину распределения величины х, но и позволяет производить математические операции с величинами х и σ, например, при вычислении доверительных интервалов (см. далее).
Для оценки формы кривой распределения желательно иметь безразмерную характеристику рассеяния, такой характеристикой обычно служит коэффициент вариации.
Коэффициент вариации – отношение стандартного отклонения к матожиданию (или к среднему), иногда в процентах
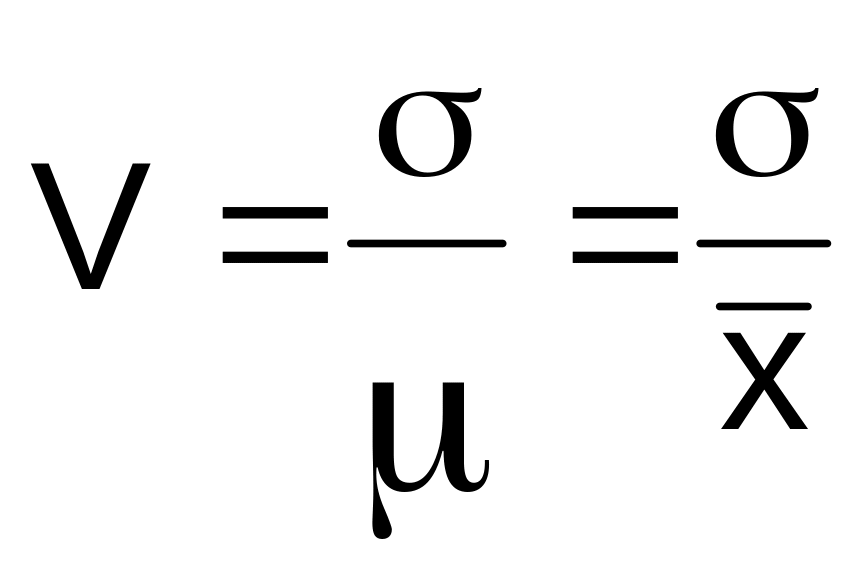 (1.2)
(1.2)
1.1.2 Выборка и генеральная совокупность. Типы выборок.
Как указано выше, чаще всего мы не располагаем всеми данными о генеральной совокупности, поэтому и основные характеристики генеральной совокупности мы точно вычислить не можем. Обычная процедура состоит в том, что мы осуществляем выборку некоторых объектов из генеральной совокупности и на основании выборочных данных получаем в результате не сами значения характеристик генеральной совокупности, а их оценки. Разумеется, точность наших оценок зависит от сделанной выборки, причем важен не только объем выборки, но и ее характер.
По характеру выборки делятся на механические, случайные и представительные.
Механическая (систематическая) выборка: выборка, основанная на нумерации. При этом все элементы генеральной совокупности нумеруются, после чего в выборку включаются все элементы, с номерами, кратными некоторому числу (каждый пятый, двадцатый, сотый и т.п.).
Например: по римскому обычаю армию, которая бежала с поля боя, бросив оружие, полководец мог подвергнуть децимации. Солдат, бросивших оружие, выстраивали и рассчитывали по десяткам, каждый десятый делал шаг вперед, и тех, на кого выпал жребий, казнили перед строем.3
Механическая выборка применяется редко, т.к. она непредставительна и к тому же содержит скрытую опасность резонансов, особенно, применительно к временнЫм рядам. Например, если мы, анализируя трудовую дисциплину, будем учитывать данные каждого седьмого дня, мы получим данные по одному дню недели. А в разные дни недели показатели трудовой дисциплины различны. Этот простой пример дан как иллюстрация, но он наглядно демонстрирует опасности механической выборки.
Противоположностью механической выборки является представительная (типическая, репрезентативная, квотная) выборка. При таком способе построения выборки мы заранее определяем список параметров, влияющих на те признаки, которые мы собираемся исследовать. Например, если мы проводим маркетинговое исследование, то главными признаками обычно являются возраст, пол, уровень доходов, социальный статус. Каждый из этих признаков мы ранжируем, т.е. разбиваем на группы (например по уровню доходов разбиваем на три группы, по возрасту на 4, по полу на две и по социальному статусу на 3). Тогда вся генеральная совокупность по этим параметрам разобьется на 3×4×2×3 = 72 группы. Выборка является представительной (квотной), если доля каждой из этих 72-х групп в выборке (квота) соответствует их доле в генеральной совокупности.
Заметим, что полного соответствия обычно добиться не удается, для его достижения потребовались бы выборки очень большого объема, а также очень развитые и сложно организованные корреспондентские сети у служб, организующих выборку. Эффект, порожденный неполной представительностью выборки, называется дизайн-эффектом, и именно дизайн-эффект очень часто является определяющим фактором в общей величине ошибки, допущенной при социологическом исследовании. В отчетах солидных социологических фирм помимо ошибки, связанной с ограниченным объемом выборки, указывается и ошибка, вызванная дизайн-эффектом. Объединение нескольких социологических служб при проведении опросов связано более всего со стремлением преодолеть перекосы в собственной корреспондентской сети и тем самым уменьшить дизайн-эффект.
В США одним из наиболее известных исторических примеров решающего влияния дизайн-эффекта (эффекта нерепрезентативной выборки) считается случай, происшедший во время президентских выборов в 1936 году. Журнал «Литрери Дайджест», успешно прогнозировавший события нескольких предшествующих выборов, ошибся в своих предсказаниях, разослав десять миллионов пробных бюллетеней своим подписчикам, а также людям, указанных в телефонных книгах всей страны, и людям из регистрационных списков автомобилей. В 25 % вернувшихся бюллетеней (почти 2,5 миллиона) голоса были распределены следующим образом:
57 % отдавали предпочтение кандидату-республиканцу Альфу Лэндону
40 % выбрали действующего в то время президента-демократа Франклина Рузвельта
На действительных же выборах, как известно, победил Рузвельт, набрав более 60 % голосов. Ошибка «Литрери Дайджест» заключалась в следующем: желая увеличить репрезентативность выборки, — а им было известно, что большинство их подписчиков считают себя республиканцами, — они расширили выборку за счёт людей, выбранных из телефонных книг и регистрационных списков. Однако они не учли современных им реалий и в действительности набрали ещё больше республиканцев: во время Великой депрессии обладать телефонами и автомобилями могли себе позволить в основном представители среднего и верхнего класса (то есть большинство республиканцев, а не демократов) /Википедия/
Случайная (вероятностная) выборка: из полного списка генеральной совокупности выбираются заданное количество элементов с использованием какой-либо процедуры рандомизации4, например присваивая всем номера, а номера отбирая с помощью генератора случайных чисел. Эта выборка не гарантирует репрезентативности результата, но зато эффекты резонанса, возможные в случае механической выборки, тут наблюдаются редко. Используется для выборок сравнительно небольшого объема и вообще для получения быстрых и недорогих результатов, а также в ситуациях, когда нет выраженных характеристик элементов генеральной совокупности, значимо влияющих на результат, либо таких характеристик очень много и можно рассчитывать на их взаимогашение при случайном характере выборки.