

Новосибирский государственный технический университет
Кафедра программных систем и баз данных
Отчет по научно-исследовательской практике
Выполнила: Фельдман М.Л.
Группа: ПММ-61
Научный руководитель: Неделько В.М.
Новосибирск
2012
Введение
Проблема переноса информации с твердых носителей в электронный вид является очень актуальной. Наибольший интерес с практической точки зрения представляет перевод бумажных носителей в текстовые электронные документы, поскольку именно в таком виде документы занимают намного меньше места и наиболее удобны для обработки.
Для таких преобразований используют алгоритмы распознавания текста, позволяющие преобразовать предварительно отсканированный документ в текстовый.
Процесс распознавания текста можно разделить на следующие этапы:
Предварительная обработка изображения
Сегментирование
Сегментирование изображения на строки
Сегментирование строк на слова и символы
Распознавание отдельных символов
В данной работе рассматриваются все этапы сегментирования – сегментирование на строки, и последующее сегментирование на слова и отдельные символы.
Если изображение хорошего качества, без шумов и помех, и строки расположены строго горизонтально, то сегментирование текстовых линий – тривиальная задача, которую можно решить одним из существующих методов – например, по гистограммам яркости. Если же изображение отсканировано неровно, и текстовые линии имеют произвольный угол наклона, то задача становится сложнее.
Выделение текстовых линий требует предварительного выявления угла наклона текста с точностью +-1-1.5°.
Обзор современного состояния проблемы
В данный момент существует множество алгоритмов распознавания печатного текста, и множество программных продуктов, реализующих эти алгоритмы. Самым известным и популярным коммерческим продуктом является Fine Reader. Также для распознавания текста предназначены программы OmniPage, TypeReader и т.д. Не смотря на множество существующих приложений, ни одно из них не дает идеального распознавания. Точное распознавание латинских символов в печатном тексте в настоящее время возможно только если доступны чёткие изображения, такие как сканированные печатные документы. Точность при такой постановке задачи превышает 99%, абсолютная точность может быть достигнута только путем последующего редактирования человеком. Поэтому до тех пор, пока точность распознавания текстов не приблизится к 100%, проблема будет оставаться актуальной. К тому же программные продукты в основном предназначены для распознавания отсканированных изображений довольно хорошего качества, если же изображения были плохого качества (как правило, это старые изображения), или были сфотографированы при недостаточном освещении, или были значительно повернуты относительно сканирующей области, то точность распознавания становится еще ниже.
Постановка задачи и математическая модель
Для сегментирования текстовых линий необходимо найти сначала угол наклона текстовых линий относительно изображения. В работе рассмотрены 2 метода. По сути 2-й метод является модификацией первого.
Рассмотрим первый метод:
Для выделения текстовых строк проводится пара горизонтальных линий, называемых контрольными линиями, на маленьком расстоянии друг от друга. Затем определяются точки, в которых контрольные линии пересекают строки (Рис. 1)
.
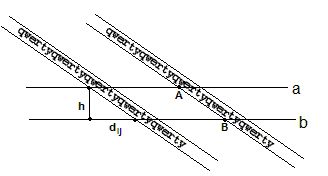
Рис. 1 Выделение точек пересечения контрольных линий с текстовыми строками. а и b – контрольные линии, h – расстояние между ними
Точки пересечения контрольных линий с текстовыми строками определяются с помощью функции кумулятивной вариации.
Функция кумулятивной вариации для каждой точки определяется рекурсивно, как сумма кумулятивной вариации в предыдущей точке и модуля разности яркостей текущего пикселя с предыдущем. Для первого пикселя в строке значение функции равно нулю. Синими и красными линиями выделены границы строк. На этом слайде можно увидеть, что функция похожа, но на первом изображении чуть-чуть сдвинута вниз, это произошло за счет того, что строки текста находятся под наклоном, и первая контрольная линия пересекает строки раньше, чем вторая.
Пример функции кумулятивной вариации для соседних текстовых линий изображен на рисунке 2.
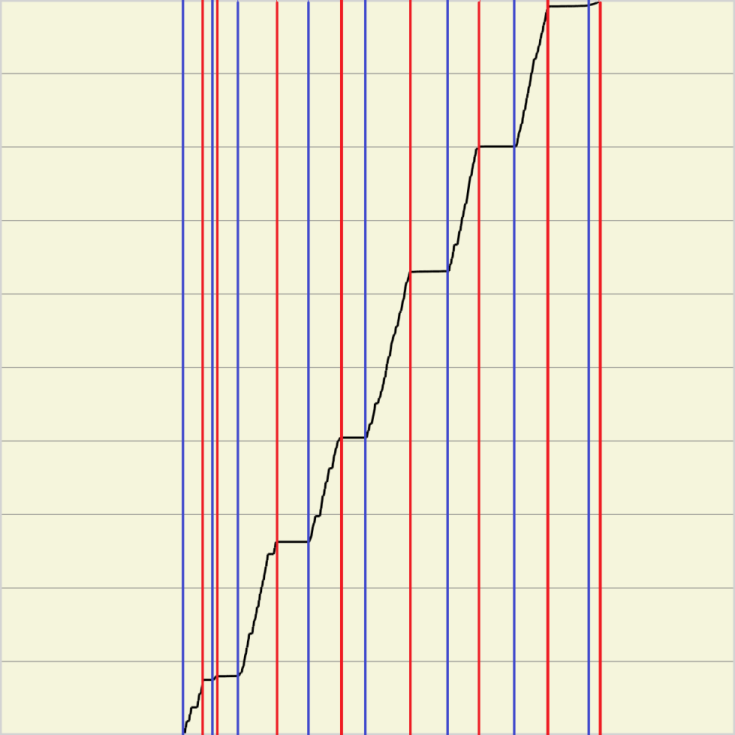
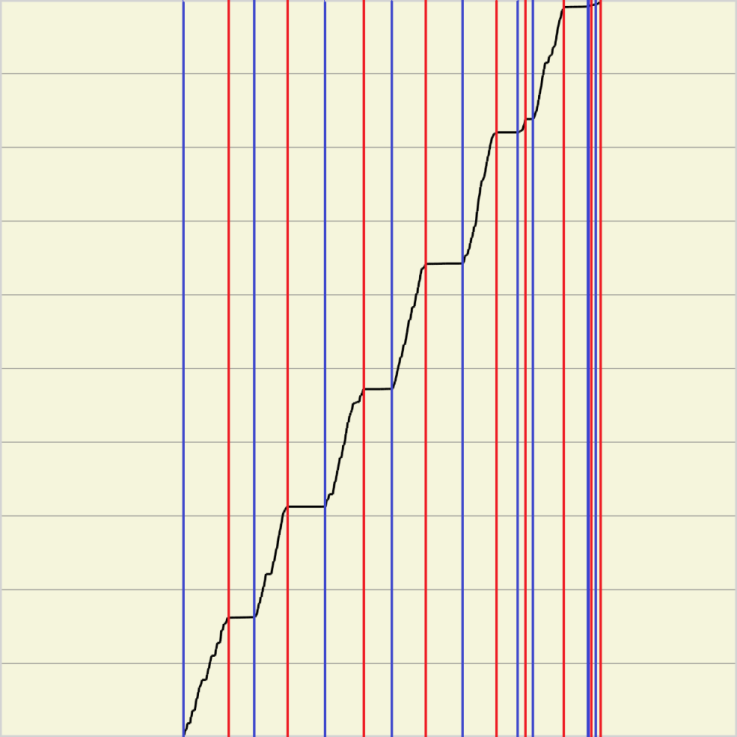
Рис.2 Функции кумулятивной вариации для 2-х проведенных рядом контрольных линий.
Для определения границ строк построим численную производную от функции кумулятивной вариации по формуле центральной разности (1)
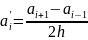 ,
,
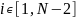 (1)
(1)
где i
– номер элемента (порядковый номер
пикселя), N – ширина
изображения в пикселях,
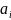 – значение функции кумулятивной
вариации, h – интервал
между переменными
– значение функции кумулятивной
вариации, h – интервал
между переменными
Для определения производной в крайней левой и правой точках используем левую и правую разность соответственно (2), (3)
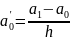 (2)
(2)
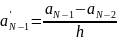 (3)
(3)
Полученные значения можно интерпретировать как изменение яркости в текущей точке. Именно по этим значениям и находятся границы линий по формуле (4)
 (4)
(4)
Где n
– кол-во пикселей в строке,
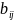 – яркость, i
– номер текущего пикселя в строке, j
– номер строки.
– яркость, i
– номер текущего пикселя в строке, j
– номер строки.
В формулах (5), (6) предоставлены условия, по которым определяется начало и конец строки на данных, полученных в результате построения гистограммы.
 (5)
(5)
(6)
Где s_im – средняя яркость всего изображения, skan_size – величина сканируемой области (это параметр определяется эмпирически).
На рисунке 3 представлена функция изменения яркости, где вертикальными линиями обозначены найденные начало и конец строки.
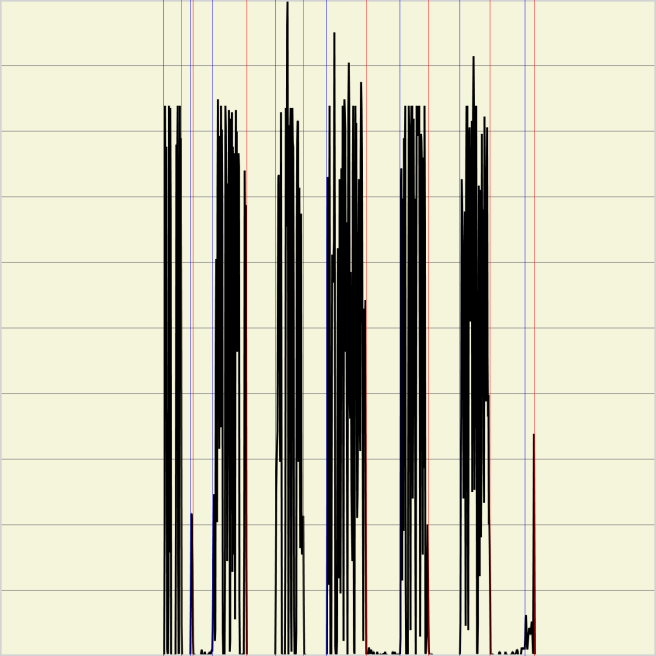
Рис.3 Функция изменения яркости
По разности координат, в которых контрольные линии пересекли одни и те же строки, можно определить угол наклона строк согласно формуле (7).

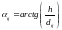 (7)
(7)
Где j – номер пересеченной текстовой строки в контрольной линии, i – номер контрольной линии.
Пара или одна из контрольных линий может попасть между строк, и тогда найденное значение угла окажется некорректным, поэтому для получения адекватного значения угла необходимо использовать множество пар контрольных линий, и, исходя из полученной информации, определить угол согласно формуле (8). Количество пар на странице определяется экспериментально. В исследованиях использовалось число пар N=100, так как при дальнейшем увеличении N точность нахождения угла не возрастала. Вместо среднего значения взята медиана, как более робастная оценка, устойчивая к выбросам, которые происходят, если контрольные линии пересекают разное количество строк.
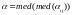 (8)
(8)
После проведения вышеизложенных операций, точность угла составляет +-2-3 градуса. При необходимости точность расчета угла может быть увеличена.
Результатом работы алгоритма на основе разработанного метода, являются координаты углов строк (каждая выделенная строка заключается в прямоугольник, из которого впоследствии будут выделены слова и отдельные символы).
Рассмотрим теперь 2-й метод:
Если в первом методе мы рисовали множество пар контрольных линий, для каждой пары определяли угол, и затем его усредняли, то в этом методе мы сразу рисуем множество контрольных линий (как на рисунке 4), и угол ищем таким образом, чтобы он соответствовал всем контрольным линиям.
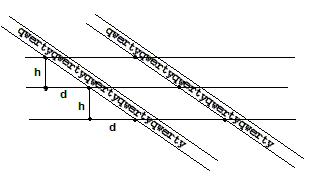
Рис. 4 Контрольные линии
Как было рассмотрено ранее, в первом методе, функции кумулятивной вариации для соседних контрольных линий будут похожи, но сдвинуты относительно друг друга, поскольку из за угла наклона контрольные линии пересекают строку в разных точках, причем сдвиг однозначно определяется углом. В данном методе мы будем подбирать искомый угол таким образом, чтобы для каждой пары контрольных линий при сдвиге, определяемом найденным углом, мера различия была минимальна. Под мерой различия будем понимать сумму модулей разностей функций в каждой точке согласно формуле (9)
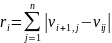 (9)
(9)
где i
– номер 1-й контрольной линии, j
– номер пикселя в строке,
 – значение функции кумулятивной
вариации, n
– кол-во пикселей в строке
– значение функции кумулятивной
вариации, n
– кол-во пикселей в строке
Общая мера различия вычисляется согласно формуле (10).
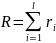 (10)
(10)
Где l+1- кол-во контрольных линий на странице
Теоретически, если бы текстовая линия была равномерна по всей своей длине, то функция кумулятивной вариации была бы одинакова на соседних контрольных линиях, с учетом горизонтального сдвига, который однозначно определяется углом. Сдвиг из угла наклона высчитывается по формуле, обратной формуле (7) согласно формуле (11).
 (11)
(11)
Где h – расстояние между контрольными линиями, α – предполагаемый угол
На практике, из-за того, что соседние контрольные линии могут очень по разному пересекать строку (например, одна слегка задела букву, а вторая пересекла ее несколько раз), функции кумулятивной вариации довольно значительно отличаются, причем отличия встречаются слишком часто, чтобы их можно было списать на выбросы. В результате из-за значительного вертикального сдвига мера различия на функции кумулятивной вариации получается слишком большой. На рисунке 5 пример, как выглядит функция кумулятивной вариации, и как сильно она может отличаться на соседних линиях даже при сдвиге, высчитанном из истинного угла наклона.
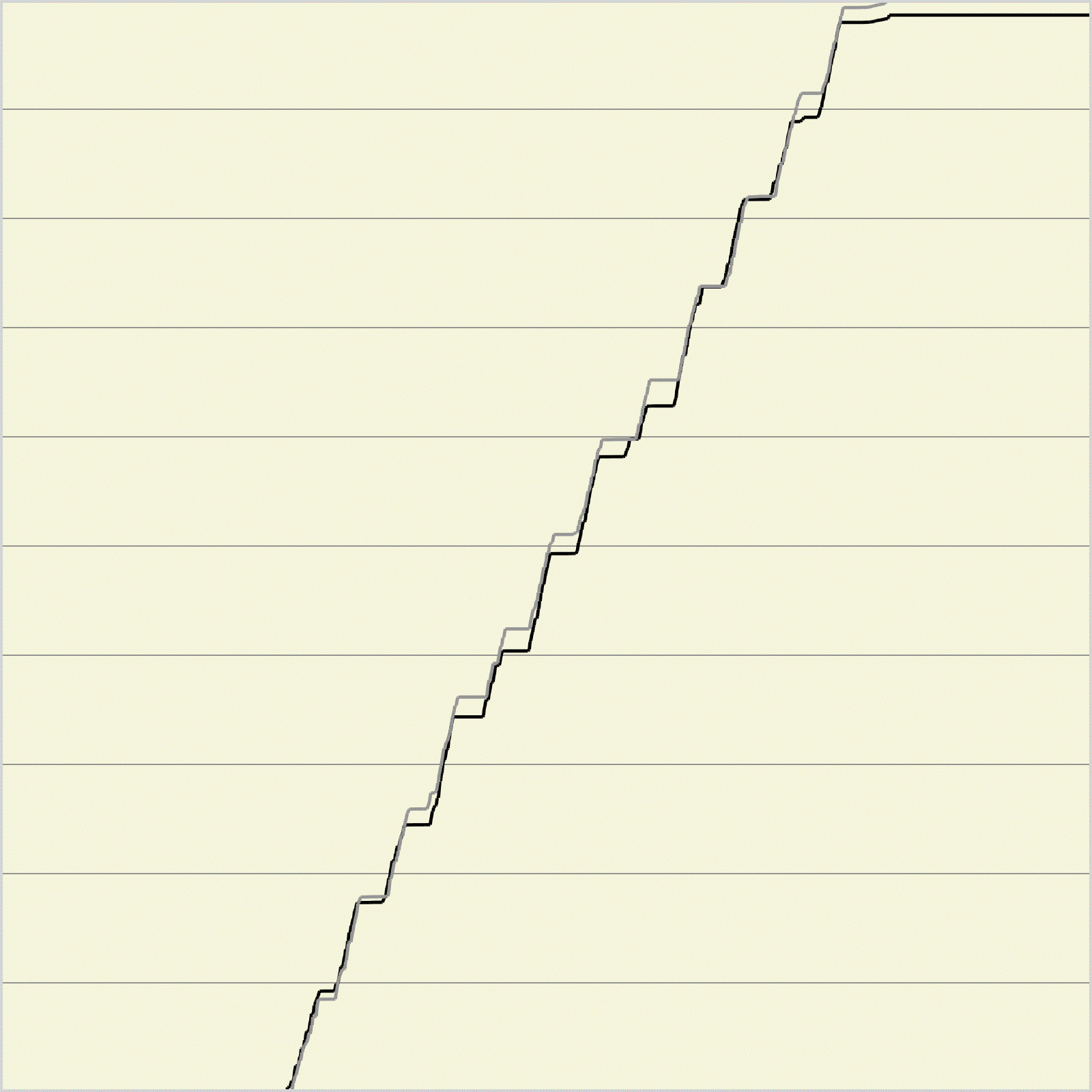

Рис. 5 Функции кумулятивной вариации для истинного угла 20 градусов для разных контрольных линий
Для того чтобы «приблизить» линии кумулятивной вариации друг в другу воспользуемся линейными преобразованиями, которые «подтянут» по вертикали линии одну к другой. Не нарушая общности, будем считать, что первая линия кумулятивной вариации (то есть та, которая соответствует верхней контрольной линии) неподвижна, и «подтягивать» будем вторую. Точки, которые будут задавать, на каких участках необходимо применить линейные преобразования, назовем контрольными.
В качестве первой контрольной точки можно взять 0, поскольку в этой точке значение обеих функций всегда будет одинаковым и равным 0. Процедура линейных преобразований будет состоять в следующем:
1)задаем максимальное количество линейных преобразований
2)выбираем очередную контрольную точку: берем точку, в которой разность между линиями максимальна
3) «подтягиваем» в этой точке значение функции кумулятивной вариации (то есть приравниваем значение 2-й линии к первой)
4)пересчитываем значение всех точек линии, находящихся между предыдущей контрольной точкой и текущей, и от текущей до следующей.
5)добавляем новую точку в упорядоченный список контрольных точек. Если кол-во итераций не превысило максимальное кол-во преобразований, переходим на пункт 2.
Проблемой является выбор максимального количества преобразований, поскольку если преобразований сделать слишком много, то даже для неверно найденного угла линии станут почти идентичными. На рисунках 6,7 изображены графики зависимости меры различия от количества линейных преобразований. На рисунках можно увидеть, что при слишком большом количестве преобразований мера различия практически не отличается, несмотря на то, что углы отличаются значительно.

Рис. 6 График зависимости меры различия от количества линейных преобразований для истинного угла 20 градусов

Рис. 7 График зависимости меры различия от количества линейных преобразований для истинного угла 10 градусов
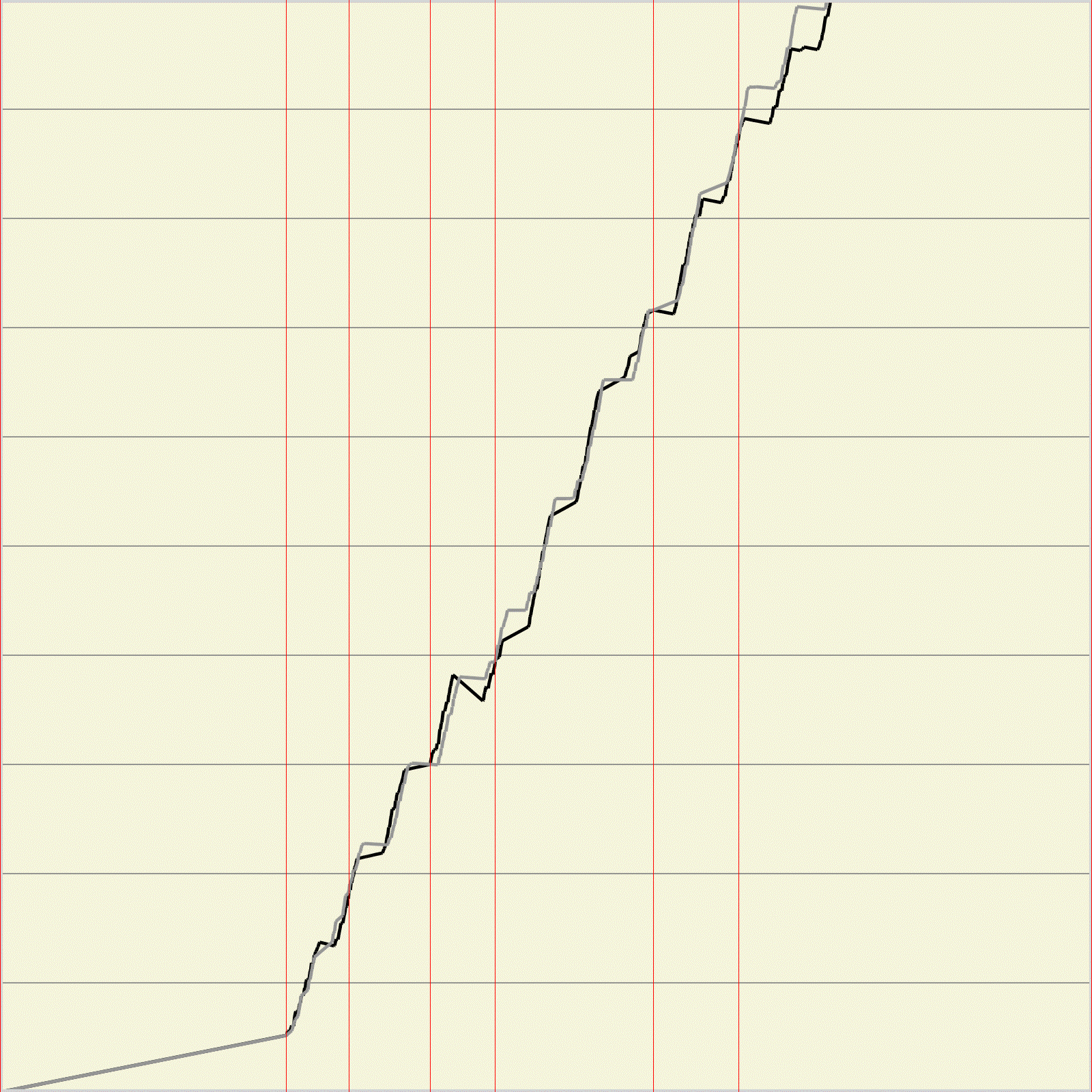
На рисунках 8 и 9 изображены пары функций кумулятивной вариации для правильно и неправильно заданных углов. Можно заметить, что если угол задан правильно, то уже при малом количестве линейные преобразований линии становятся похожими. После большого количества преобразований функции кумулятивной вариации если угол задан неверно, то наблюдается тенденция «вытягивания» линии в прямую, если же угол задан верно, то ступенчатый вид функции остается.
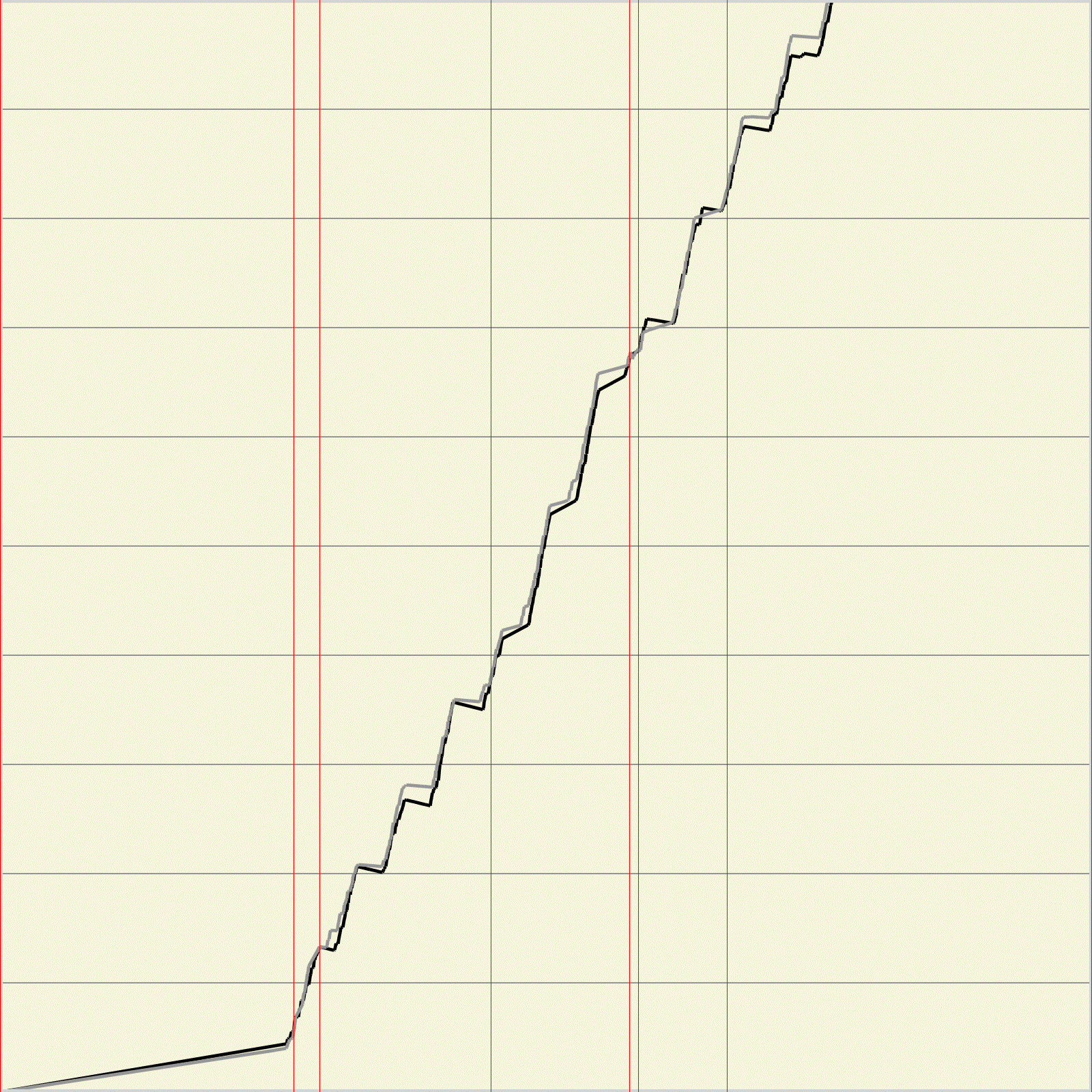
а б
Рис.8 Функции кумулятивной вариации при количестве линейных преобразований 5. а – верно заданный угол угол 20 градусов, б – неверно заданный угол 40 градусов


а б
Рис.9 Функции кумулятивной вариации при количестве линейных преобразований 15. а – верно заданный угол угол 20 градусов, б – неверно заданный угол 40 градусов
Для нахождения оптимальной меры различия можно взять значение функции кумулятивной вариации после определенного количества линейных преобразований, а можно учитывать несколько значений в каком-то интервале количества преобразований.
Для поиска оптимального угла используется процедура минимизации меры различия. Предположим, что функция меры различия от угла унимодальная, с одним минимумом. Тогда для поиска минимума угла можно применить метод золотого сечения.
Сравнение методов:
После определения угла первым методом, точность найденного угла составляет +-3-5 градусов, этого недостаточно для сегментирования, поэтому приходится дополнительно применять процедуру уточнения угла, что значительно увеличивает время нахождения угла. После применения процедуры точность достигает +-1-1.5 градуса, что является достаточным для сегментирования. После применения 2-го метода мы сразу получаем достаточную точность +-1, но при применении метода на малых углах (до 5 градусов), возможно неверное нахождение угла, поскольку если истинный угол мал, функция зависимости меры различия от угла перестает быть унимодальной. Таким образом 2-й метод является более удобным для определения угла, но в данный момент нуждается в доработках.