

Определение ошибки выборки
Ошибка выборки — это объективно возникающее расхождение между характеристиками выборки и генеральной совокупности. Она зависит от ряда факторов: степени вариации изучаемого признака, численности выборки, методом отбора единиц в выборочную совокупность, принятого уровня достоверности результата исследования.
Определение ошибки выборочной средней.
При случайном повторном отборе средняя ошибкавыборочной средней рассчитывается по формуле:
![]()
где
![]() — средняя ошибка выборочной средней;
— средняя ошибка выборочной средней;
![]() —
дисперсия выборочной совокупности;
—
дисперсия выборочной совокупности;
n — численность выборки.
При бесповторном отборе она рассчитывается по формуле:
![]()
где N — численность генеральной совокупности.
Определение ошибки выборочной доли.
При повторном отборе средняя ошибка выборочной доли рассчитывается по формуле:
![]()
где
![]() — выборочная доля единиц, обладающих
изучаемым признаком;
— выборочная доля единиц, обладающих
изучаемым признаком;![]() — число единиц, обладающих изучаемым
признаком;
— число единиц, обладающих изучаемым
признаком;![]() — численность выборки.
— численность выборки.
При бесповторном способе отбора средняя ошибка выборочной доли определяется по формулам:
![]()
Предельная ошибка выборки
![]() связана со средней ошибкой выборки
связана со средней ошибкой выборки![]() отношением:
отношением:![]()
При этом t как коэффициент кратности средней ошибки выборки зависит от значения вероятности Р, с которой гарантируется величина предельной ошибки выборки.
Предельная ошибка выборки при бесповторном отборе определяется по следующим формулам:
![]()
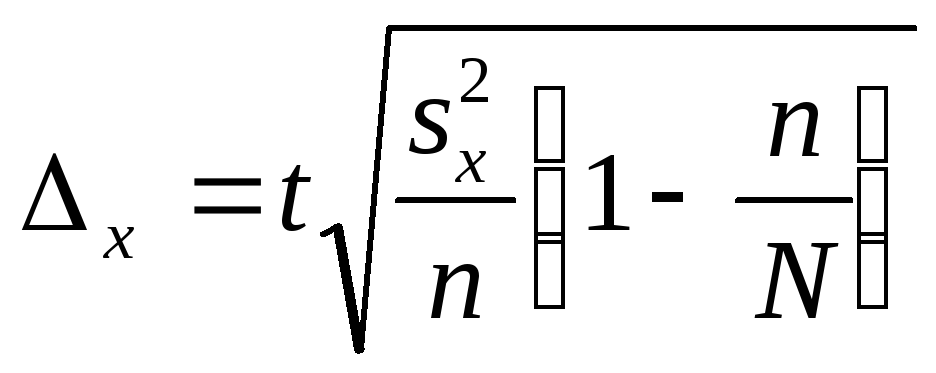
Предельная ошибка выборки при повторном отборе определяется по формуле:
![]()
![]()
18. Расчет необходимой численности выборки, обеспечивающей с определенной вероятностью заданную точность наблюдения.
Смотри 17 ответ.
Трудовые и материальные затраты на проведение выборки напрямую зависят
от ее численности, поэтому чрезвычайно важно до оптимума сохранить
численность выборки, так чтобы не утратить ее точность.
Поиск оптимальной численности выборки удобно осуществлять на основе
формул средней и предельной ошибок. Из формулы средней ошибки случайного
повторного отбора видно, что величина средней ошибки обратно
пропорциональна квадратному корню из численности выборки ([pic]). Чтобы
сократить среднюю ошибку в 2 раза, нужно численность выборки увеличить в 4
раза. Используя формулу предельной ошибки выборки [pic] можно найти
численность [pic]. Это оптимальная численность выборки для случайного
повторного отбора.
Пример: Для определения среднего размера банковского вклада сроком на
91 день необходимо провести повторный отбор из совокупности в 2500
договоров. Какое количество договоров необходимо отобрать, чтобы с
вероятностью 0,954 предельная ошибка выборки не превысила 25 руб.
N=2500
p=0,954
(=25 руб.
n-?
(2=8900
Расчет численности выборки основывается на статистическом подходе обработки данных и за ним стоит множество вычислений, но для простоты, ниже мы представим формулу, следуя которой можно достичь хороших результатов.

n – Количество элементов в выборке.
t – Определяется по таблице значений функции F(t), при условии известной исследователю доверительной вероятности. Практически всегда не больше 3.

p – Доля брака в генеральной совокупности.
q – Доля качественной продукции в генеральной совокупности.
Если соотношение брака и качественной продукции не известно, то положим p=0,5 и q=0,5 .
Δ – Заданная точность.
Пример 1. Пусть необходимо определить объем выборки, которая позволила бы оценить долю брака в партии продукции (10000 единиц) с точностью до 2% при доверительной вероятности P = 0,95. То есть, если истинная доля брака составляет k%, то с вероятностью 0,95 мы хотим получить долю брака k’% лежащую в интервале k% + 2% < k’% < k% - 2%.
Численность выборки может быть определена по формуле
![]()
Где при неизвестных p и q положим их равными 0,5. Δ = 0,02, значение t определяется по таблице (смотрите ниже), по заданной доверительной вероятности и равно 2.
Таблица значений функции Лапласа:

![]()
Однако это число можно и уменьшить, например используя дополнительную информацию. Допустим нам известно приблизительное значение p=0,1, тогда q=1-p=0,9 и используя эти цифры получаем:
![]()
Каким способом следует выбирать данные?
Для того чтобы посредством выборки как можно лучше оценить генеральную совокупность, выборка должна иметь каждое свойство генеральной совокупности. Выборка называется репрезентативной, если каждое свойство в выборке и в генеральной совокупности имеет одинаковые частоты.
Выборка имеет больше шансов быть репрезентативной, если она построена таким образом, что (1) каждые объект генеральной совокупности имеет одинаковую вероятность быть отобранным и (2) объекты отбираются независимо друг от друга.
Есть несколько методов извлечения выборки: применение таблиц случайных чисел, метод перемешивания генеральной совокупности, стратифицированная случайная выборка, систематическая выборка. Ниже мы рассмотрим первые два из этих методов.
1. Применение таблицы случайных чисел.
Одним из способов извлечения случайной выборки является применение таблицы случайных чисел.
Определение: Таблица случайных чисел – это набор цифр такой, что вероятность возникновения любой цифры от 0 до 9 одна и та же. 2057 0762 1429 8535 9029 9745 3458 5023 3502 2436
6435 2646 0295 6177 2755 3080 3275 0521 6623 1133
3278 0500 7573 7426 3188 0187 7707 3047 4901 3519
7888 6411 1631 6981 1972 4269 0022 3860 1580 6751
4022 6540 7804 5528 4690 3586 9839 6641 0404 0735
0888 3504 2651 9051 5764 7155 6489 2660 3341 8784
…
19. Ряды динамики: понятие, виды (моментные, интервальные). Показатели ряда динамики.